Improving the Scaling Laws of Synthetic Data with Deliberate Practice
核心灵感源自人类学习中的 “刻意练习” 原则,提出了一种名为DP(Deliberate Practice for Synthetic Data Generation) 的新型框架。该框架通过动态生成具有挑战性和信息价值的合成数据,解决了传统合成数据训练中 “规模扩大但性能收益递减” 的核心痛点,在不依赖真实训练数据的前提下,显著提升了样本效率和模型泛化能力,在 ImageNet-100 和 ImageNet-1k 等数据集上实现了 SOTA 性能。
一、研究背景与问题提出
1. 合成数据的潜力与现有痛点
文本到图像(T2I)生成模型的发展为视觉识别任务提供了近乎无限的合成训练数据,成为昂贵真实数据集的理想替代方案。但现有合成数据训练存在两大核心问题:
- 收益递减:单纯增加合成数据规模会导致性能提升遵循幂律停滞,大量生成样本冗余或过于简单,无法有效促进模型学习(Fan et al., 2024; Tian et al., 2024a);
- 低效剪枝:现有解决方案通过 “生成大规模数据集后剪枝无信息样本” 提升效率,但该方式计算成本极高 —— 大量生成样本被丢弃,造成资源浪费;
- 静态训练局限:多数模型依赖预收集的静态数据集训练,无法动态适配自身学习弱点,与人类 “针对性练习” 的高效学习模式相悖。
2. 核心研究目标
在无真实训练数据的场景下,设计一种高效、动态的合成数据生成框架,通过直接生成 “高信息价值、高挑战性” 的样本,替代 “生成后剪枝” 的低效模式,优化合成数据的缩放定律(Scaling Laws),实现 “以更少数据、更低计算成本达成更优性能”。
二、核心贡献
论文的四大核心贡献为合成数据训练的效率提升提供了关键突破:
- 提出DP 框架:基于人类刻意练习原则,动态生成挑战性合成数据 —— 仅在模型验证性能停滞时补充高信息样本,避免冗余数据浪费;
- 理论验证:通过随机矩阵理论(RMT) 分析,从理论上证明 “优先训练高信息样本” 能优化缩放定律,降低测试误差;
- 熵引导采样机制:提出熵引导采样方法,可近似直接从 “剪枝后的高信息分布” 中生成样本,比传统 “生成 - 剪枝” 模式计算效率高 5 倍;
- 实证优势:在 ImageNet-100/1k 上实现显著性能提升 ——ImageNet-100 上样本量减少 3.4 倍、迭代次数减少 6 倍;ImageNet-1k 上样本量减少 8 倍、迭代次数减少 30%,且在分布外(OOD)数据集上表现优于真实数据训练模型。
三、DP 框架整体设计
DP 框架的核心是 **“动态反馈循环”**:在扩散模型(生成器)和下游分类器(学习者)之间建立持续交互,让合成数据生成始终适配模型当前的学习状态,确保训练聚焦于 “模型尚未掌握的挑战性样本”。框架流程如图 1 所示,具体包含三大核心模块,对应 Algorithm 1 的完整流程: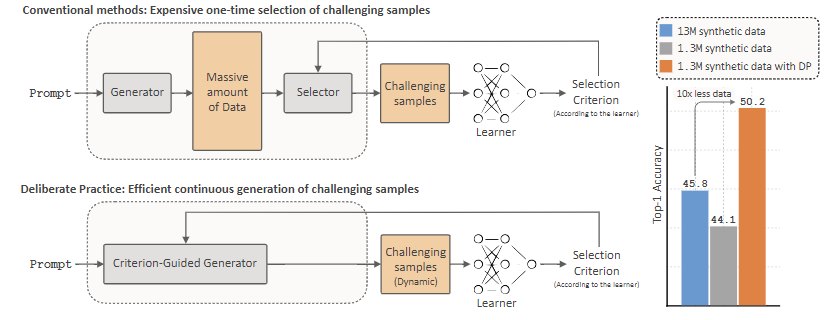
3.1 核心模块与流程
- 初始合成数据生成:通过预训练文本到图像模型(LDM-1.5)生成初始合成数据集D0tr(含 N 个样本),分类器fϕ以 “学习率预热” 方式启动训练;
- 性能监测与耐心机制:每间隔 τ 次迭代评估分类器在真实验证集Dval上的性能。若连续Tmax次评估无性能提升(触发 “耐心阈值”),则启动新数据生成;
- 熵引导高信息样本生成:利用当前分类器的预测熵(H(fϕ(x0)))指导扩散模型生成 P 个新样本Dnew—— 熵越高表示样本对模型越具挑战性,通过修改扩散模型的分数函数实现定向生成;
- 动态数据集扩充与训练续跑:将新生成的高信息样本加入训练集(Dk+1tr=Dktr∪Dnew),分类器以恒定学习率继续训练,直至进入 “冷却阶段”(学习率衰减,停止生成新数据)。
3.2 关键设计理念
- 动态适配:“硬样本” 定义随训练进程更新 —— 模型初期难以掌握的样本,训练后期可能变为 “易样本”,DP 通过持续反馈确保生成的样本始终匹配模型当前弱点;
- 无真实数据依赖:全程仅使用真实数据作为验证集(评估性能),训练数据完全由合成生成,解决真实数据稀缺或标注昂贵的问题;
- 效率优先:直接生成高信息样本,避免 “大规模生成 + 剪枝” 的资源浪费,兼顾性能与计算成本。
四、方法论细节
4.1 问题形式化定义
- 目标:训练分类器fϕ:X→Y(X为图像输入,Y为类别标签),仅使用合成数据,最大化其在真实验证集上的泛化性能;
- 输入:预定义类别标签集Y、预训练生成模型gθ(支持类别条件采样x∼gθ(y))、真实验证集Dval(无真实训练集Dtr=∅);
- 核心约束:用最少的合成样本实现最优泛化,需设计 “筛选 / 生成高信息样本” 的原则性机制。
4.2 熵引导的高信息样本生成
为实现 “直接生成高信息样本”,论文基于扩散模型的数学特性,通过修改分数函数引导采样方向,核心步骤如下:
- 扩散模型采样修正:传统扩散模型从分布P采样,DP 目标是直接从 “剪枝后的高信息分布Q” 采样。根据 Girsanov 定理,通过在反向 SDE 中加入修正项∇logπ(x,t),可将采样分布从P偏向Q,其中π(x,t)为 “样本信息价值权重函数”;
- 信息价值量化:预测熵:权重函数π由分类器的预测熵定义:logπ∝H(fϕ(x0))=−∑y∈Yfϕ(y∣x0)logfϕ(y∣x0)—— 熵越高,样本对模型越具挑战性,信息价值越高;
- 高效采样实现:基于 DDIM(去噪扩散隐式模型),利用中间采样步骤的x^0,t(最终去噪样本的近似)廉价计算熵,通过修改分数函数实现高熵样本定向生成:ϵ~θ(t)(xt,y)=ϵθ(t)(xt,y)+ω∇xtH(fϕ(x^0,t))其中ω控制熵引导的强度(ω=0时退化为普通采样)。
4.3 理论分析:高信息样本优化缩放定律
论文通过随机矩阵理论(RMT)分析高维线性分类器的测试误差,证明 “优先训练高信息样本” 能显著优化缩放定律,核心结论如下:
- 理想场景设定:假设训练数据服从x∼N(0,Σ),标签由y=sign(w0⊤x)生成(w0为真实标签函数),分类器通过最小化带正则的平方损失训练;
- 关键结论(Theorem 1):在高维比例缩放场景下(d,n→∞,d/n→ϕ),测试误差满足:Etest(w^)→arccos(∣m0∣/ν0)/π其中m0和ν0由样本选择策略、数据规模等参数决定。理论表明:选择 “决策边界附近的高信息样本”(类似 DP 的熵引导策略)能降低测试误差,减少达到相同性能所需的样本量(图 3);
- 自适应选择的必要性:“硬样本” 的定义随模型训练动态变化,若采样方向ws不随分类器w^更新,会导致 “采样硬样本与模型真实弱点错位”,DP 的动态反馈机制恰好解决此问题。
五、实验设计与结果
5.1 实验设置
- 数据集:
- 主数据集:ImageNet-100(100 类,5k 验证集)、ImageNet-1k(1k 类,50k 验证集)—— 真实训练集作为 “留出测试集” 评估泛化;
- OOD 数据集:ImageNet-V2、ImageNet-Sketch、ImageNet-R、ImageNet-A,评估分布外鲁棒性;
- 模型与参数:
- 生成器:LDM-1.5(经对比实验验证为最优 T2I 模型);
- 分类器:Vision Transformer(ViT-B);
- 关键超参数:ω=0.05(熵引导强度)、λ=3(分类器无指导系数)、初始样本量N=130k、每次新增样本量P=130k、耐心阈值Tmax(增量调整);
- 基线方法:Static(静态合成数据集训练)、Prior Work(Sarıyıldız et al., 2023; Fan et al., 2024)、真实数据训练模型。
5.2 核心实验结果
(1)缩放定律优化(图 4)
- ImageNet-100:DP 仅用 400k 样本即可达到 Static 方法 300 万样本的性能(数据量减少 7.5 倍);
- ImageNet-1k:DP 用 640k 样本即可超越 Static 方法 1300 万样本的性能(数据量减少 20 倍);
- 结论:DP 的缩放曲线更陡峭,证明其样本效率远超静态合成数据方法。
(2)与现有方法对比(Table 1)
表格
| 任务 | 方法 | 迭代次数 | 数据量 | ImageNet 验证集准确率 | OOD 提升(ImageNet-R) |
|---|---|---|---|---|---|
| ImageNet-100 | Prior Work(Sarıyıldız et al.) | 635k | 6.5M | 73.3 | - |
| ImageNet-100 | DP(本文) | 100k | 1.9M | 74.3 | +0.2(超真实数据) |
| ImageNet-1k | Prior Work(Fan et al.) | 315k | 64M | 42.9 | - |
| ImageNet-1k | DP(本文) | 200k | 6.5M | 54.1 | +15%(超真实数据) |
关键结论:DP 在样本量减少 8-34 倍、迭代次数减少 30%-84% 的情况下,性能显著超越现有合成数据方法,且在 OOD 数据集上表现优于真实数据训练模型。
(3)DP 与剪枝方法的效率对比(图 5)
- 两种方案:① Oversampling+Pruning(生成 2.4M 样本,筛选 130k 高熵样本);② DP 直接生成 130k 高熵样本;
- 结果:两种方案性能趋势一致,但 DP 的计算成本仅为前者的 1/5—— 生成单张高熵样本的时间虽比普通采样长 1.82 倍,但避免了大规模生成的冗余成本,整体效率更优。
(4)硬样本的动态演化(图 6)
- 跟踪 “新增硬样本” 的分类误差:样本刚加入时误差最高,随训练推进逐渐降低;
- 关键发现:部分样本在加入训练集前,误差已低于 “加入时”—— 证明 “硬样本” 是动态的,静态剪枝方法无法适配这种变化,而 DP 的动态生成机制能精准捕捉模型实时弱点。
5.3 消融实验(Table 3)
验证 DP 核心组件的必要性:
- 熵引导(ω>0):ω=0.05时验证集准确率达 68.04%,ω=0(无熵引导)时降至 61.58%,证明高信息样本生成的核心作用;
- 耐心机制(增量Tmax):增量耐心机制(68.04%)优于固定耐心机制(67.22%),避免数据集过大时样本遍历不足;
- 采样策略:新样本加权采样(68.01%)与均匀采样(68.04%)性能接近,证明 DP 生成的样本质量稳定,无需额外加权。
六、相关工作与局限性
6.1 相关工作对比
表格
| 研究方向 | 核心思路 | 与 DP 的区别 |
|---|---|---|
| 静态合成数据训练 | 一次性生成大规模合成数据 | 无动态反馈,样本冗余,收益递减 |
| 合成数据剪枝 | 生成后筛选高信息样本 | 计算效率低,无法适配硬样本动态变化 |
| 主动学习 / 持续学习 | 迭代选择 / 更新训练数据 | 依赖真实数据或标注,未聚焦合成数据生成优化 |
| 自对弈微调 | 生成递增难度的样本训练 | 多用于 LLM,未结合扩散模型与熵引导采样 |
6.2 局限性
- 知识库依赖:DP 的性能依赖生成模型能否生成 “与真实分布对齐的高信息样本”,若生成模型存在偏差,可能导致性能上限;
- 计算开销权衡:虽比 “生成 - 剪枝” 高效,但熵引导采样比普通采样耗时更长,需在性能与速度间进一步优化;
- 超参数敏感:耐心阈值Tmax、熵引导强度ω等参数需根据数据集调整,缺乏自适应调整机制。
七、影响与结论
7.1 结论
DP 框架通过 “刻意练习” 启发的动态反馈机制,突破了合成数据训练的收益递减瓶颈 —— 通过熵引导直接生成高信息样本,让模型始终聚焦于挑战性任务,实现了 “更少数据、更低计算、更优性能” 的目标。理论分析与实证结果均证明,高信息样本优先训练能显著优化合成数据的缩放定律,为无真实数据场景下的视觉识别任务提供了高效解决方案。
7.2 影响声明
- 降低训练成本:减少合成数据量和迭代次数,降低大规模模型训练的计算与环境成本;
- 拓展应用场景:在低资源地区、隐私敏感领域(无法获取真实数据),DP 可提供高质量合成训练数据;
- 推动自适应学习:为动态数据生成与模型训练的融合提供新思路,助力更接近人类学习模式的 AI 系统发展。
八、附录补充细节
- 生成模型选择:对比 LDM-1.4/1.5/2.1/XL,LDM-1.5 因生成多样性更高,在分类任务上表现最优(验证集准确率 59.24%);
- 中间采样可视化:DDIM 的x^0,t虽模糊,但已能捕捉颜色、形状等关键特征,足以支撑熵引导采样(图 8);
- 超参数细节:学习率调度采用 Warmup-Stable-Decay,使用 Mixup/CutMix 数据增强,AdamW 优化器(ImageNet-100 学习率 0.003,ImageNet-1k 学习率 0.0016)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)