Re-ranking Reasoning Context with Tree Search Makes Large Vision-Language Models Stronger
核心提出了一种名为RCTS的多模态检索增强生成(RAG)框架,通过构建含推理上下文的知识库和树搜索重排序方法,解决了大视觉语言模型(LVLMs)在视觉问答(VQA)中存在的幻觉问题、指令失准、检索知识响应不稳定等痛点,在多个推理 / 非推理 VQA 数据集上实现了 SOTA 性能,显著优于零样本、上下文学习(ICL)和基础 RAG 方法。
一、研究背景与问题提出
1. 现有 LVLMs 的能力与痛点
大视觉语言模型(LVLMs)凭借多模态处理和上下文学习(ICL)能力,在 VQA 任务中表现突出,且多模态 RAG 技术通过检索外部知识库补充信息,有效降低了模型生成错误内容的概率。但现有方法仍存在核心问题:
- 幻觉问题:一是生成与现实事实不符的内容,二是生成与用户指令 / 问题错位的不稳定响应(指令失准);
- 知识库缺陷:现有知识库仅包含视觉问答对,无详细推理过程,模型难以捕捉底层逻辑模式;
- 检索样本问题:检索的样本因 ICL 固有局限性和查询多样性,无法持续带来正向效果,且缺乏有效的重排序策略筛选高相关样本;
- 人工标注局限性:ICL 中手动构建少样本示例对可扩展性差,无法适配多样化的用户查询。
2. 核心研究方向
针对指令失准这一核心痛点,论文将研究聚焦于两个关键方向:
- 构建含推理上下文的知识库,优化生成过程并助力 ICL;
- 对检索样本进行策略性重排序,优先选择适配的样本,提升响应生成的效率和准确性。
二、核心贡献
论文的三大核心贡献为后续 LVLMs 的 VQA 性能提升提供了全新的框架和方法:
- 提出RCTS 多模态 RAG 框架:通过构建含推理上下文的综合知识库 + 高相关上下文重排序,显著增强 LVLMs 的 VQA 能力;
- 设计自动化推理上下文生成机制:基于 VQA 对实现知识库的推理上下文构建,并提出带启发式奖励的蒙特卡洛树搜索(MCTS-HR) 方法,对检索样本进行重排序;
- 大规模实验验证:在多个推理 / 非推理 VQA 数据集上实现性能大幅提升,证明了推理上下文和树搜索重排序机制的有效性。
三、RCTS 框架整体设计
RCTS 框架为无训练式多模态 RAG 框架,整体包含三大核心组件,框架流程如图 2 所示,核心目标是让 LVLMs 从 “仅知晓答案(known)” 升级为 “理解推理过程(know-how reasoning)”,最终输出更精准、一致的 VQA 响应。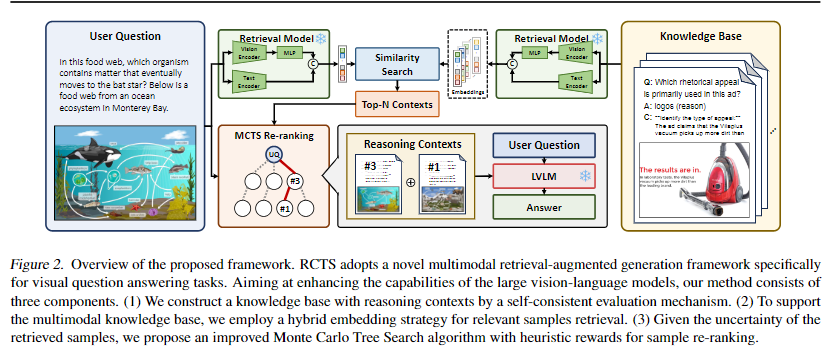
- 基于自洽评估机制构建含推理上下文的知识库;
- 采用混合嵌入策略实现多模态知识库的相关样本检索;
- 提出带启发式奖励的改进 MCTS 算法对检索样本进行重排序。
整体流程:用户问题经混合嵌入检索得到 Top-N 样本,再通过 MCTS-HR 重排序得到 Top-K 含推理上下文的样本,与用户问题拼接后输入 LVLMs,最终生成答案。
四、方法论细节
3.1 问题定义
- 知识库:定义为包含 M 个视觉问答对的集合DKB={xi}i=1M,每个样本xi=(Ii,Qi,Ai,Ci),其中Ii为图像、Qi为问题、Ai为参考答案、Ci为推理上下文;
- 核心目标:根据用户查询(Iu,Qu)从知识库中检索 K 个相关样本Xret,通过 LVLMs 模型G生成预测答案yˉ∼G([Iu;Qu;Xret]),让yˉ尽可能贴近真实答案,且框架可通过扩展知识库自适应多领域。
3.2 基于自洽评估的推理上下文生成
为解决现有知识库无推理过程的问题,论文借鉴 Auto-CoT 思想,设计自动化推理上下文生成 + 验证流程(图 3),核心是利用 LVLMs 的自洽机制生成候选推理上下文,并通过相互答案预测验证筛选最优解,步骤如下:
- 生成候选推理上下文:对知识库中的每个 VQA 对(Qkb,Akb),由 LVLMs 生成Nc个候选推理上下文{Ci}i=1Nc;
- 预测答案并评分:将问题Qkb与每个候选Ci拼接,生成Np个预测答案,与真实答案Akb对比得到预测分数{Scorei}i=1Nc;
- 筛选最优上下文:选择得分最高的候选推理上下文作为该 VQA 对的关联Ci,纳入知识库。
3.3 基于混合嵌入的知识检索
为充分利用多模态信息(图像 + 文本问题),避免单一模态检索的信息丢失,采用混合嵌入检索策略,步骤如下:
- 模态嵌入:分别用文本编码器FL和图像编码器FI将用户问题的文本Qu和图像Iu编码为同维度d的嵌入向量ETu和EIu;
- 混合嵌入拼接:将文本和图像的 token 级嵌入拼接,得到用户查询的混合嵌入Eu=[ETu,EIu];
- 知识库嵌入一致性:对知识库中的样本,剔除答案仅保留图像和文本问题,用相同方法生成混合嵌入集合EKB={[ETi,EIi]}i=1M;
- 相关性计算与检索:计算Eu与EKB中每个样本的相关性分数r(Eu,Ei)=∑j=1lumaxk=1liEujEik⊤,按分数选取 Top-N 相关样本作为后续重排序的候选。
3.4 基于带启发式奖励的树搜索的重排序(MCTS-HR)
这是论文的核心创新点,将样本重排序转化为序列决策问题,借鉴蒙特卡洛树搜索(MCTS)的探索 - 利用平衡能力,设计 MCTS-HR 对检索的 Top-N 样本重排序,筛选出最适配的 Top-K 样本,核心包含树搜索流程、动作构建与选择、启发式奖励设计、奖励反向传播四部分。
(1)MCTS-HR 整体流程
遵循标准 MCTS 的 “初始化 - 扩展 - 模拟 - 评估 - 反向传播” 循环,直至满足终止条件(最大模拟次数 / 早停):
- 树初始化:用用户问题的零样本响应初始化根节点;
- 节点扩展:基于节点访问次数N(a)和节点值Q(a),贪心选择未完全扩展的节点进行扩展;
- 动作选择:从检索样本构建的动作空间中采样动作,作为扩展节点;
- 分支模拟:达到最大树深度 K 时,将分支中的动作与用户问题拼接为 K-shot 提示,生成响应;
- 奖励评估:通过启发式奖励函数R评估响应,得到奖励值Q;
- 反向传播:将奖励值回传至父节点和祖先节点,更新树的价值信息;
- UCT 更新:更新所有节点的树置信上界(UCT),指导下一轮探索。
(2)动作构建与选择
- 动作空间:将检索的 Top-N 样本作为候选动作A={[x1,s1],[x2,s2],...,[xN,sN]},其中si为样本与用户查询的归一化相似度;
- 动作采样:设已选动作集合为C,有效动作空间为Avalid=A∖C,基于相似度的概率分布P(ai)=∑j,aj∈Avalidsjsi采样动作,直至达到最大深度 K。
(3)自洽 + 互启发式奖励设计
摒弃传统 MCTS 直接用语言模型作为奖励函数的方式,设计双启发式奖励,通过上下文一致性保证评分的可靠性和公平性,最终奖励为两者的加权和:
- 自洽启发式奖励(QS):评估模型基于推理上下文生成答案的一致性。将用户问题与预测的推理上下文拼接,生成Ns个答案,若这些答案与原预测答案一致,则奖励高,公式为:QS,i=Ns1∑n=1NsR(A~i(n),A~i)其中R为基于规则的评估器,A~i为原预测答案,A~i(n)为新生成答案。
- 互启发式奖励(QM):评估推理上下文对其他相关问题的正向迁移能力。从动作空间中选取Nm个样本作为参考问题,将用户问题 + 预测响应作为上下文,生成参考问题的答案,若与参考问题的真实答案一致,则奖励高,公式为:QM,i=Nm1∑n=1NmR(A~i(n),Aigt(n))
- 最终奖励:Qi=α⋅QS,i+(1−α)⋅QM,i,其中α为权重参数,控制两者的重要性,默认设为 0.2。
(4)奖励反向传播
当子节点的奖励值变化时,父节点p的奖励值Q(p)按以下公式更新,既考虑所有子节点的答案可靠性,也兼顾最优子节点的奖励值:Q′(p)=21(N(p)+1Q(p)⋅N(p)+Q(c)+maxi∈Children(p)Q(i))其中N(p)为父节点访问次数,Q(c)为变化的子节点奖励值,Children(p)为父节点的子节点集合。
五、实验设计与结果
4.1 实验数据集
论文在3 个推理型 VQA 数据集和2 个非推理型 VQA 数据集上开展实验,将数据集分为知识库(训练 / 验证集) 和评估集(测试 / 开发集),且两者无重复样本,数据集统计如下:
表格
| 评估集 | 规模 | 知识库 | 规模 | 数据集类型 |
|---|---|---|---|---|
| ScienceQA test | 4241 | ScienceQA trainval | 16967 | 推理型(中小学科学) |
| MMMU-Dev | 150 | MMMU-Val | 900 | 推理型(大学多学科) |
| MathV testmini | 304 | MathV test | 2736 | 推理型(多模态数学) |
| VizWiz val | 4319 | VizWiz train | 20523 | 非推理型(盲人日常视觉问答) |
| VSR-MC test | 1181 | VSR-MC trainval | 4440 | 非推理型(视觉空间推理) |
4.2 实验设置
- 实验模型:选用不同规模 / 类型的主流 LVLMs,包括 Qwen2-VL(2B/7B)、InternVL-2(8B),7B 以上模型采用 AWQ 4 位量化部署;
- 编码器:文本编码器用冻结的 BERT-base,图像编码器用 ViT-L+2 层 MLP(均来自 PreFLMR);
- 超参数:推理上下文生成Nc=Np=10,奖励评估Ns=Nm=5,MCTS-HR 最大树深度K=3、初始检索样本N=20、树最大宽度 3、最大模拟次数P=10、奖励权重α=0.2。
4.3 主实验结果
(1)推理型 VQA 数据集(Table 2)
RCTS 在所有推理数据集和 LVLMs 上均实现显著性能提升,核心结论:
- 相比零样本:Qwen2-VL(2B)在 ScienceQA 上提升 11.81%,MathV 上提升 3.29%;
- 相比 ICL(随机检索):平均提升 3%,证明语义感知的样本选择 + 推理上下文的有效性;
- 相比 Vanilla-RAG(顶级检索):所有模型上均提升超 3%(Qwen2-VL 7B 提升 4.2%,InternVL-2 8B 提升 3.9%),验证 MCTS-HR 重排序和推理上下文的协同作用。
(2)非推理型 VQA 数据集(Table 3)
非推理数据集因答案简短,仅引入知识库未加推理上下文,RCTS 仍实现稳定提升:Qwen2-VL(7B)在 VizWiz 上提升 1.61%,VSR-MC 上提升 3.05%,证明框架的通用性和鲁棒性。
4.4 消融实验
为验证 RCTS 各核心组件的有效性,开展多组消融实验,核心结果如下:
(1)核心组件消融(Table 4)
推理上下文(Rea. Con.)和 MCTS-HR 单独使用均能带来正向性能提升,两者结合时性能最优,证明二者为互补增强关系;MMMU 数据集提升有限(+3.33%),原因是其问题领域覆盖广,知识库中相似样本不足。
(2)奖励策略消融(Fig.5 (a))
混合奖励(自洽 + 互启发) 在所有数据集上的性能均优于单一自洽奖励或单一互启发奖励,验证了双启发式奖励设计的合理性。
(3)模拟次数(Rollouts)消融(Fig.5 (b))
随模拟次数增加,模型性能呈稳步提升后趋于平稳的趋势,最终选择P=10,平衡计算开销和性能。
(4)奖励权重α消融(Table 5)
默认值α=0.2时模型在各数据集上综合性能最优,说明互启发式奖励(1−α) 对推理上下文的评估更重要。
4.5 补充分析
(1)推理上下文的可靠性(Table 6)
评估 “问题 + 推理上下文” 生成真实答案的准确率,结果显示:Qwen2-VL(7B)在 ScienceQA 上达 100%,即使是复杂的 MathV/MMMU,准确率也超 96%,证明自洽评估机制生成的推理上下文精准且全面。
(2)定性分析(Fig.6)
对比 Vanilla-RAG 和 RCTS:Vanilla-RAG 检索的样本适配性差,即使有推理上下文也输出错误答案;RCTS 通过 MCTS-HR 重排序筛选出高适配样本,结合推理上下文输出更可靠的答案,直观体现了重排序的价值。
六、讨论、局限性与影响
6.1 关键讨论
RCTS 的核心价值在于让 LVLMs 从 “知其然” 到 “知其所以然”:通过推理上下文让模型理解 VQA 的底层逻辑,通过 MCTS-HR 重排序让模型选择最适配的推理示例,最终解决了指令失准和检索样本不稳定的核心问题。
6.2 局限性
- 知识库依赖性:RCTS 的性能依赖于知识库中是否存在有帮助的样本,若知识库覆盖不足,性能会受影响;
- 计算开销:MCTS-HR 的树搜索和多轮生成带来了额外的计算开销,性能提升与计算成本的权衡仍需进一步研究。
6.3 影响声明
RCTS 为多模态 VQA 的发展提供了全新框架,其创新点在多个领域具有重要应用价值:
- 实际应用:可落地于自主系统、教育技术、AI 决策支持系统等需要复杂多模态 VQA 的场景;
- 技术价值:自动化推理上下文生成和启发式树搜索重排序,让 AI 系统能更好地处理复杂现实场景,提升 AI 的可信任度和可用性;
- 领域革新:在医疗、教育、城市规划等依赖多模态 AI 的领域具有变革潜力,推动 AI 向更透明、可解释、认知对齐的方向发展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 19
19 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)