优化 | LLM 入门:ChatGPT 背后的原理(上)

讲座标题:Deep Dive into LLMs like ChatGPT
视频作者:Andrej Karpathy
原作链接:https://www.youtube.com/watch?v=7xTGNNLPyMI&ab_channel=AndrejKarpathy
编者按
近年来,大模型技术迅猛发展,已成为人工智能领域最受关注的研究方向之一。从科研机构到科技公司,从程序员到普通用户,越来越多的人开始使用 ChatGPT 等大语言模型进行翻译、编程、学习与创作。一年前,Andrej Karpathy 在油管上发布了视频《Deep Dive into LLMs like ChatGPT》,用清晰直观的方式解释了 ChatGPT 背后的数学结构与工程逻辑。本文将用通俗易懂的文字对这场讲座前半部分的内容进行概括。
如何才能得到一个好用的 ChatGPT 模型?
本文将基于 Andrej Karpathy 的讲座,介绍预训练(Pretraining)与后训练(Post-Training)的基本内容。
一、预训练(Pretraining)
数据的获取与处理
想要训练 ChatGPT,就先得从互联网的公开资源中获得足够多的文本信息。
这一步我们可以自行完成,或直接使用公开的数据集。实际上,无论使用哪种途径,本质上对数据筛选和处理的思路是类似的。下面以 CommonCrawl (CC) 为例,展示这个过程。
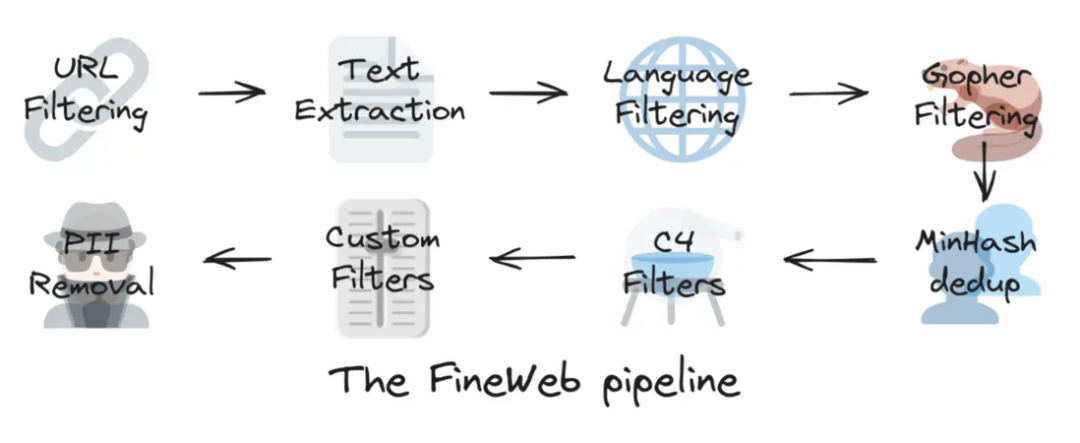
在 CommonCrawl 的执行流程中,筛选的第一步是 URL 过滤,旨在排除一些特定网站的 URL(例如含有恶意软件安装的网站、垃圾广告网站等)。对于剩下的网站,CommonCrawl 会把网页中优质的文本部分提取出来,它们需要继续经历各种类型的过滤。例如,根据不同公司的特定需要,只有使用特定语种(如中文、英文等)的文本会被留下;地址、电话等个人身份信息(PII, Personally Identifiable Information)也不能出现在最终的数据集里。
经过上述处理之后,来自不同网站的内容被直接连接在一起,可看作一行超长的文字。我们由此获得了高质量的文本信息。我们对文本信息进行分词(tokenization)处理。这个过程可看作是查询一种特别的字典,将特定的字符串转化为对应的数字 id,即词元。以 GPT-4 为例,这本字典中一共有 100277 个词元。
实际上,每个词元未必对应一个或多个完整的单词。感兴趣的同学可访问网站 https://tiktokenizer.vercel.app/,查看不同模型下任意输入语句对应的词元 (token) 组合。
Transformer 模型的训练
在得到了超长的词元序列之后,我们用它来进行模型的训练。
模型会通过设置滑动窗口的长度截取合适的文本范围。每次截取的内容被用作模型的输入,用来计算各词元作为下一个词出现的概率。在下图中,Andrej 对于滑动窗口长度等于 4,总词元个数为 100277 的情形进行了展示。
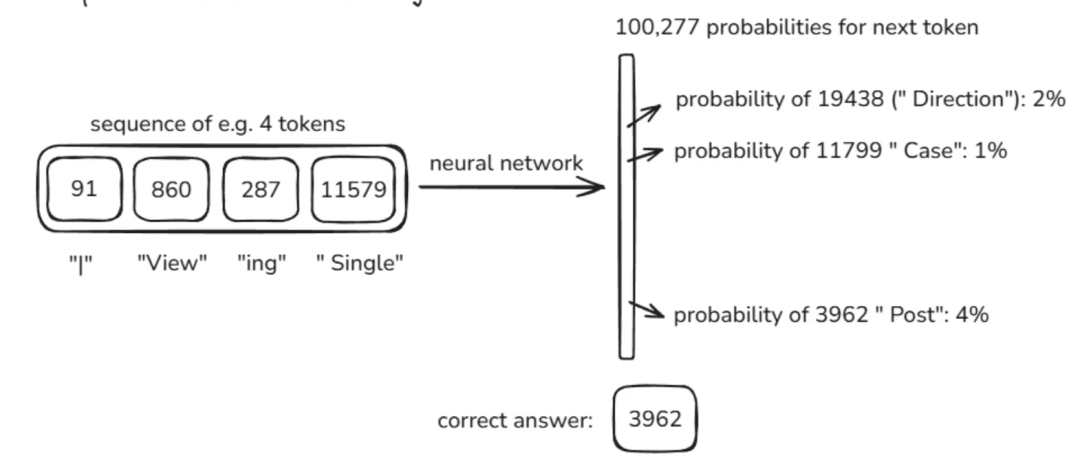
关于模型结构的细节,更多内容可参考网站 https://bbycroft.net/llm. 我们可以注意到,模型最后一层往往为 Softmax 函数,这使得模型最终的输出为一个 100277 维的向量,其中每个元素均在 [0,1] 之间,且求和等于 1。
对于训练数据集而言,我们知道当前序列真正的下一个词元是什么。利用这一信息,我们可以不断更新神经网络中参数的值,从而使得损失函数值逐渐减小,对应模型的预测能力越发准确。
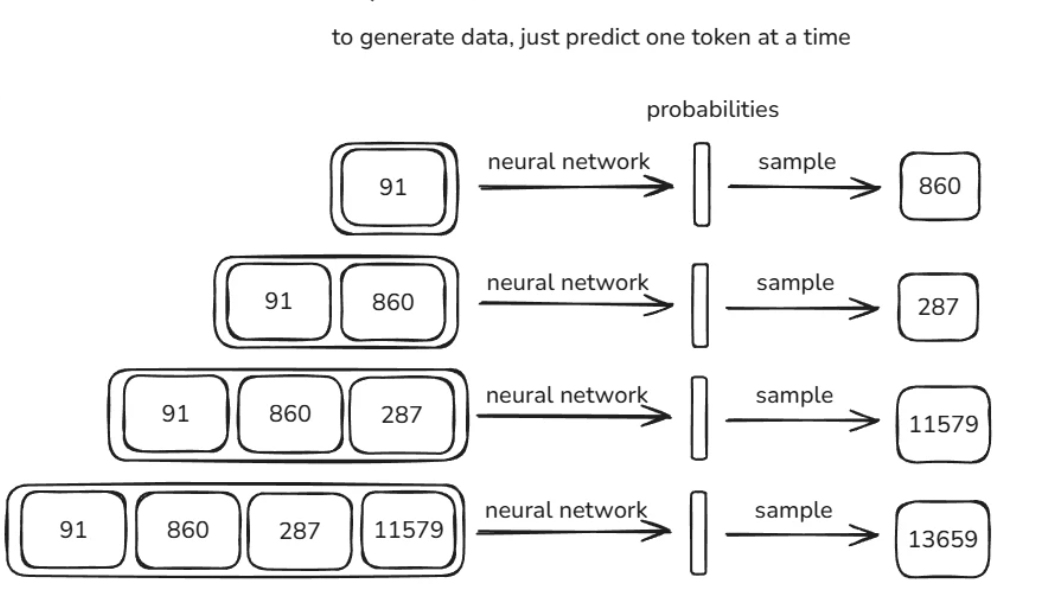
对于经过一定训练的模型,我们可以让其进行推理(inference),从而检查它的训练效果。我们选择一个词元作为输入,让模型预测各词元接在其后面的概率。对于当前得到的概率分布,我们再进行一次随机采样,从而确定第二个词元(在下图中,即为 860)。接着,我们将第一、二个词元作为输入,让模型继续预测各词元接在其后面的概率。以此类推,我们最终可以得到一个随机生成的词元序列。通过该词元序列对应文本序列的流畅、合理程度,我们可以大致判断目前训练的进展。
二、后训练(Post-Training)
从续写到回答问题
经过上述训练过程之后,我们得到了一个基础模型(Base-model)。这个模型已经学到了现实世界的各类知识,训练好的神经网络参数可看作是它对这些知识的记忆。其中 GPT-2 中大约有 16 亿个参数,而 Llama 中参数的数量可达到 4050 亿。
然而,目前的模型更像是一种续写工具。对于用户输入的语句,模型每次只是根据所得的概率分布随机生成一个续写的文本。对于用户输入的提问,基础模型并没有进行回答的意识。

为了解决这一问题,我们需要构建对话数据集,用于对当前模型进行后训练(Post-Training)。对话数据集的文本内容过去往往通过人工撰写来获得,现在也可以利用 LLM 来帮助创建。

同时我们添加新的词元来表示 <im_start>, <im_sep>, <im_end> 等内容,使得模型能够学到当前对话的结构。
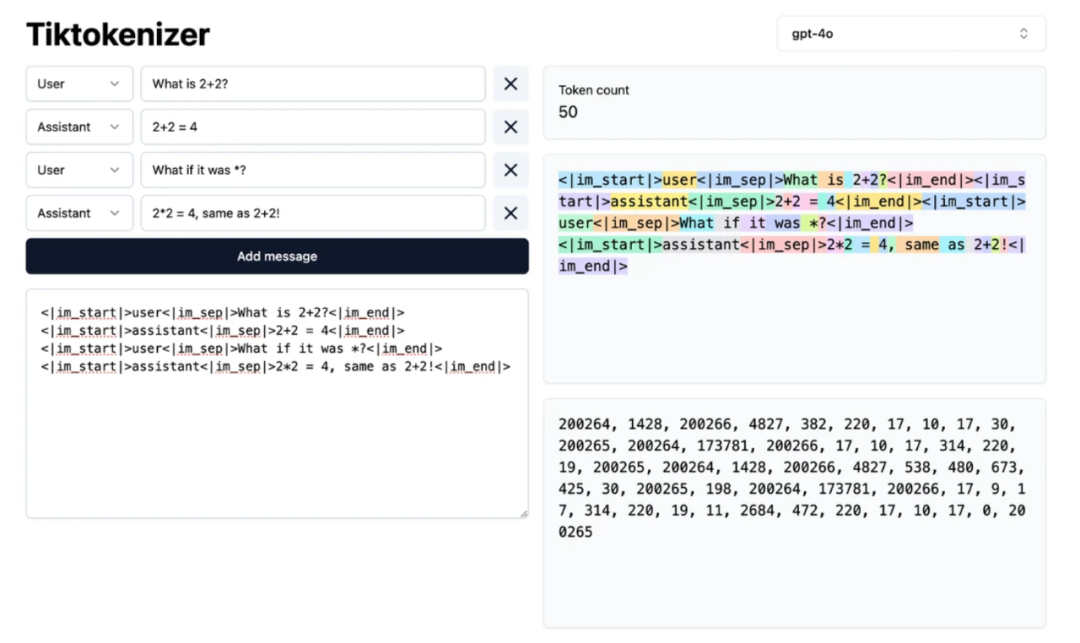
由于模型举一反三的能力很强,加上后训练使用的数据集相比预训练阶段要小得多,后训练很快就可以完成。
如何避免 ChatGPT 胡乱回答
幻觉(Hallucination)是 LLM 中经常出现的一个问题。对于不清楚的问题,模型有时会捏造出完全不正确的回答。为了解决这个问题,我们需要在训练中对其进行矫正。
LLM 本身可用于帮助完成这项工作,提高回答的准确性。我们摘取一段文本,通过已有的成熟 LLM 生成文本相关的几个问题和对应答案。接着我们反复对当前模型进行提问,并将模型的回答与标准答案进行比较(这一步可通过另一个成熟的 LLM 完成)。如果对于同一个问题的多次提问,当前模型总是给出错误答案,那么我们将构建新的训练数据,要求模型在遇到该提问时回答自己并不知道这个问题的答案。通过这些新的训练样本,我们对众多神经网络参数中的一部分实现了微调,它们能够捕捉到当前模型不清楚答案的状态,并顺势调整最终词元的概率分布。
另一种解决的方法是允许 ChatGPT 直接通过互联网查阅问题的答案。在 Andrej 所提的例子中,我们可以定义新的词元 <SEARCH_START> 和 <SEARCH_END>,从而让 ChatGPT 在发现自己不知道问题答案的情形下,发送对应的查询(以下图为例,即为 <SEARCH_START> Who is Orson Kovacs? <SEARCH_END>)。在发送查询之后,模型将会停止生成语句,转而在一个新窗口中与 Bing 等搜索引擎进行对话,获取对应的文本后再回到与用户的对话中,做出最终的回答。

以上是讲座的前半部分。后半部分的总结很快也会在公众号上更新。感兴趣的同学可访问 https://www.youtube.com/watch?v=7xTGNNLPyMI&ab_channel=AndrejKarpathy 观看原视频。另外,B 站上也有含中文字幕的版本,方便大家学习。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)