工业视觉识别技术初探——deepSeek著
目录
1.1 深度学习框架:PyTorch与TensorFlow的江湖地位
1.3 工业专用框架:Halcon、VisionPro与国产方案的博弈
1.4 部署与加速框架:ONNX、TensorRT、OpenVINO的工程价值
2.1 工业场景为何偏爱“Halcon + 深度学习 + 工控机”?

第一部分:计算机视觉框架全景——从基础到生态的完整图谱
1.1 深度学习框架:PyTorch与TensorFlow的江湖地位
计算机视觉的底层核心是深度学习框架,它们提供了自动微分、GPU加速、张量计算等基础能力,是整个视觉生态的基石。
PyTorch由Meta(原Facebook)发起,现隶属于Linux基金会,采用BSD 3-Clause协议,允许无限制的商业使用和修改。其核心优势在于动态计算图(Define-by-Run),使得模型调试极为直观,开发者可以在运行时逐行打印张量形状、查看梯度流动,这在研究与算法原型验证阶段是巨大的生产力提升。PyTorch的生态极为完善,HuggingFace、TIMM、Detectron2等主流库均优先支持。在学术界,PyTorch占据绝对主导地位;在工业界的研究部门,它也是首选框架。
TensorFlow由Google主导,2.x版本后默认启用Eager Execution(动态图),在易用性上与PyTorch的差距大幅缩小。TensorFlow的生态优势在于部署端——TensorFlow Serving、TensorFlow Lite、TensorFlow.js构成了从服务器到移动端到浏览器的完整部署链路。其Keras高级API封装简洁,非常适合初学者快速搭建模型。在工业界生产环境中,TensorFlow仍占据大量份额,尤其是需要跨平台部署的场景。
JAX是Google开发的又一力作,结合了NumPy的易用性和XLA(加速线性代数)的编译优化能力。JAX支持自动微分、即时编译(JIT)和向量化,在生成式AI和高性能计算领域快速崛起。虽然目前生态不如前两者丰富,但在需要极致性能的科研场景中越来越受欢迎。
选型建议:学术研究、算法快速迭代、复杂模型实验选PyTorch;需要稳定部署到移动端或浏览器、团队熟悉Keras选TensorFlow;追求极致性能、从事生成式AI或科学计算选JAX。
1.2 高级视觉算法库:站在巨人的肩上
基于上述框架,衍生出大量高级算法库,极大地降低了开发门槛,使开发者无需从零复现论文即可构建工业级应用。
TIMM(PyTorch Image Models):如果说只推荐一个图像模型库,那就是它。TIMM汇集了几乎所有预训练的图像分类模型(ResNet、EfficientNet、ViT、Swin Transformer等),以及数据增强、优化器实现。它是图像建模的基石,无论是做分类、检测还是分割,TIMM都能提供高质量的骨干网络。
MMDetection(OpenMMLab):由香港中文大学-商汤科技联合实验室开源,是目前最全面的目标检测、实例分割框架。它不仅是代码库,更是一个完整的体系——覆盖检测、分类、分割、姿态估计、3D视觉等多个领域,模块化设计使得用户可以像搭积木一样组合不同组件。MMDetection支持超过50种主流算法,代码质量高,文档完善。
Detectron2:Meta开源的下一代目标检测平台,基于PyTorch重写。其代码质量极高,模块化设计优雅,适合需要深度定制算法逻辑的研究者。Detectron2在Facebook内部广泛应用于图像分割、关键点检测等任务,工业级稳定性有保障。
Hugging Face Transformers:虽然是NLP起家,但现在是视觉Transformer(ViT)、多模态模型(CLIP、BLIP、Grounding DINO)的事实标准。如果你想使用开源的视觉-语言大模型,这个库是首选。它提供了统一的API接口,数千个预训练模型一键加载,极大地简化了多模态应用的开发。
OpenCV:计算机视觉领域的“瑞士军刀”。功能覆盖从最基本的图像读取、滤波、几何变换,到传统的特征提取(SIFT/ORB)、目标跟踪,甚至深度学习的推理接口。OpenCV支持C++、Python、Java等多种语言,在工业自动化领域,它通常用于图像预处理(灰度化、滤波、ROI裁剪)、相机标定、传统特征提取等环节。新版本(4.5.0+)采用Apache 2.0协议,提供了明确的专利授权,对商业应用更加友好。
Pillow(PIL):Python最基础的图像处理库。虽然功能比OpenCV简单,但在深度学习数据加载中经常被用来做最简单的图像打开和缩放操作,因为它比OpenCV更轻量,且与Python原生环境兼容性更好。
1.3 工业专用框架:Halcon、VisionPro与国产方案的博弈
在工业自动化领域,纯开源方案往往难以满足稳定性、精度和交付周期的要求,因此商业专用算法平台成为主流。这些平台的特点是:成熟稳定、算法经过大量工业场景验证、提供图形化开发环境、技术支持完善。
Halcon(MVTec):工业视觉的“黄金标准”。它不只是一个库,而是一套完整的开发环境,拥有极其丰富的传统图像处理算子(超过2000个)和先进的3D视觉、深度学习工具。Halcon的优势在于:精度极高(亚像素级),标定工具非常强大(支持各种相机模型、手眼标定),文档完善(超过10000页的帮助文档),稳定性非常好。它尤其适合精密测量、3D定位、缺陷检测等场景。代价是价格昂贵(按运行时长或功能模块收费),且生成的代码需要购买运行版授权才能部署到产线。
VisionPro(Cognex/康耐视):北美和高端制造业的常见选择。核心优势是拥有专利的PatMax定位算法(业界公认最强),图形化编程(拖拽式),无需写代码即可搭建视觉流程。VisionPro在定位引导、装配验证场景下表现极为稳定,与康耐视自家硬件(相机、镜头、光源)无缝集成,售后支持强大。适合汽车制造、电子装配、包装检测等标准化产线。
国产替代方案:近年来国产方案快速崛起,代表企业包括:
-
海康机器人:从30万到1.51亿像素工业相机全覆盖,VM算法软件平台构建视觉应用生态,3D视觉方案在仓储自动化市占率达35%。特点是硬件覆盖广、性价比高、本地服务好。
-
奥普特(OPT):从光源起家,全球市占率超20%,多光谱光源方案可将新能源电池缺陷识别率提升至99.9%。在特定光源和成像环节拥有核心技术壁垒。
-
凌云光:VisionWare算法库迭代至6.2版本,深耕3C电子、新型显示等高精度检测,在消费电子和印刷检测领域积累深厚。
-
阿丘科技:AIDI工业AI视觉平台支持零代码拖拽式模型训练,专利小样本学习算法仅需10-50张缺陷图片即可生成高精度检测模型。解决数据稀缺痛点能力强。
-
思谋科技:聚焦0.1μm级半导体晶圆缺陷检测,Few-Shot Learning技术实现10张样本训练高精度模型。在半导体等高端制造领域技术壁垒高。
-
梅卡曼德:AI+3D视觉引导,机器人引导系统实现±0.05mm定位精度,在汽车焊接、电子组装中广泛应用。是3D视觉引导领域的“独角兽”。
-
迁移科技:自研DLP和激光机械振镜3D相机,光栅结构光方案对各种材质生成高质量点云,上下料、拆码垛、定位装配场景表现优异。
1.4 部署与加速框架:ONNX、TensorRT、OpenVINO的工程价值
模型训练完成后的部署,是工业落地的关键一环。工业产线对实时性有苛刻要求(通常单件检测<200ms),同时工控机算力有限,因此部署优化至关重要。
ONNX(Open Neural Network Exchange):作为模型格式的中间件,打破了框架壁垒。你可以将PyTorch模型导出为ONNX格式,然后转换为TensorRT或OpenVINO。ONNX的生态极为丰富,几乎所有推理框架都支持。
TensorRT:NVIDIA出品的高性能深度学习推理SDK。如果你使用NVIDIA GPU进行部署,TensorRT是必经之路。它通过层融合(将Conv+BN+ReLU合并)、精度校准(FP16/INT8量化)、内核自动调优(根据GPU架构选择最优实现)等手段,可实现3-10倍的加速。在工业场景中,TensorRT通常与NVIDIA Jetson边缘计算平台配合,用于机器人、无人机等嵌入式设备。
OpenVINO:Intel推出的推理加速框架,专为Intel CPU、集成显卡、VPU优化。在工控机没有独立GPU的场景下,OpenVINO是首选。它支持从TensorFlow、PyTorch、ONNX等多种格式转换,并提供模型优化器进行静态图分析和算子融合。
NCNN:腾讯开源的轻量级神经网络推理框架,专为手机端CPU/GPU优化,在移动端部署领域非常流行。特点是轻量、无依赖、跨平台(Android、iOS、Linux、Windows)。
TFLite:TensorFlow针对移动端和嵌入式设备的解决方案,支持Android、iOS、嵌入式Linux,并提供硬件加速(通过GPU、DSP、NPU委托)。
部署策略建议:工业工控机有NVIDIA显卡选TensorRT;只有Intel CPU选OpenVINO;嵌入式设备(Jetson)选TensorRT;手机/平板选NCNN或TFLite;跨平台统一格式选ONNX。
1.5 开源生态的合规性:商用无忧
在商用项目中,协议合规至关重要。以下是主要框架的协议分析:
| 框架 | 协议 | 商用限制 | 专利授权 |
|---|---|---|---|
| PyTorch | BSD 3-Clause | 无限制,可闭源修改 | 无明确专利授权 |
| TensorFlow | Apache 2.0 | 无限制 | 明确授予专利许可 |
| OpenCV (≥4.5.0) | Apache 2.0 | 无限制 | 明确授予专利许可 |
| OpenCV (<4.4) | BSD | 无限制 | 无明确专利授权 |
| TensorRT | NVIDIA专有 | 免费使用,不可逆向工程 | 仅限NVIDIA硬件 |
| Halcon | 商业授权 | 需购买运行时授权 | 商业许可 |
结论:PyTorch和OpenCV可放心用于任何商业产品;TensorRT可免费使用但需遵守许可条款(不可逆向工程,不可用于关键应用如自动驾驶的免责声明需注意);Halcon/VisionPro等商业软件需购买授权。
第二部分:工业自动化视觉系统的深度实践
2.1 工业场景为何偏爱“Halcon + 深度学习 + 工控机”?
在真实的工业产线上,视觉系统的核心诉求是稳定、精度、速度、易维护。因此,典型的方案组合是:
-
高精度测量/定位:采用Halcon或VisionPro,利用其成熟的标定、亚像素边缘提取、几何拟合算子,保证微米级重复精度。Halcon的亚像素边缘提取算法可在物理分辨率限制下达到0.01像素的重复精度。
-
复杂缺陷检测/分类:采用PyTorch训练深度学习模型(如YOLOv8、U-Net),然后转换为TensorRT或OpenVINO部署在工控机上,兼顾精度与速度。
-
图像预处理/后处理:使用OpenCV进行ROI裁剪、滤波、形态学操作,与深度学习模型无缝衔接。
这种“传统+深度”融合的模式,既能利用深度学习的泛化能力,又能发挥传统算法的确定性、可解释性和速度优势,是当前工业视觉的主流技术路线。其工程价值在于:
-
可靠性:传统算法处理90%的“标准”情况,深度学习处理10%的“疑难”情况,整体系统稳定性高
-
可调试:当系统出现误判时,可以分别检查传统算法环节和深度学习环节,定位问题
-
成本可控:传统算法对算力要求低,深度学习模型只需处理小ROI,整体算力需求降低
2.2 相机选型的深度剖析
工业相机选型直接影响成像质量,从而决定算法上限。以下是关键参数的详细分析:
分辨率:根据检测精度和视野确定。公式为:像素分辨率 = 视野尺寸(mm) ÷ 该方向像素数。最小可检测特征通常需要覆盖4个像素。例如,检测0.1mm缺陷,视野100mm,则需要像素分辨率 ≤ 0.1/4 = 0.025mm/像素,因此像素数 ≥ 100/0.025 = 4000像素(约1200万像素)。常见工业分辨率:500万(2592×1944)、1200万(4000×3000)、2000万(5472×3648)。
快门类型:这是动态场景最容易踩坑的地方。全局快门所有像素同时曝光,适合运动物体检测;卷帘快门逐行曝光,拍摄运动物体会产生“果冻效应”(图像倾斜/拉伸)。在高速流水线、机械臂抓取等动态场景,必须选全局快门。
帧率:需匹配产线节拍。例如,产线速度1m/s,每个产品拍照时间窗口0.1秒,则相机需支持≥10fps。通常工业场景要求≥30fps,高速场景可能要求120fps甚至更高。
接口:GigE(千兆网口)是工业主流,支持PoE供电,传输距离100米,抗干扰能力强;USB 3.0带宽高但距离短(5米),适合PC直连;CameraLink带宽极高但成本高;10GigE正在普及。
色彩:黑白相机比彩色相机灵敏度高(约3倍),适合亮度对比为主的检测;彩色相机用于颜色差异相关的缺陷(如色差、印刷颜色偏差)。
环境适应性:IP防护等级(IP65/IP67防尘防水)、宽温工作(-40℃~70℃)、抗振动(10g RMS)、抗电磁干扰(符合GJB 151B)。
品牌推荐:国产(海康、大恒)性价比高,进口(Basler、FLIR)稳定可靠。
2.3 打光设计的工程艺术
工业视觉圈有句老话:“打光打好了,项目成功一半。”打光的目标是突出目标特征、抑制背景干扰、保证图像稳定性。常用光源类型及选型指南:
| 光源类型 | 原理 | 适用场景 | 注意事项 |
|---|---|---|---|
| 环形光源 | LED环形阵列,正向照明 | 表面划痕、字符识别 | 均匀性好,但金属表面可能产生亮点 |
| 背光源 | 从背面照明,突出轮廓 | 尺寸测量、外形检测 | 需要工件透光或边缘明显 |
| 同轴光源 | 光线与镜头同轴,消除反光 | 高反光表面、玻璃 | 适合平整表面,但亮度较低 |
| 条形光源 | 线性照明,侧向打光 | 凸起/凹陷缺陷、边缘提取 | 角度可调,适合特定方向特征 |
| 穹顶光源 | 漫反射照明,均匀柔和 | 曲面、抛光表面 | 消除阴影,但亮度不足 |
| 结构光 | 投影光栅/条纹,获取深度 | 3D测量、平整度检测 | 需要相机与投影仪标定 |
打光策略:
-
多光谱融合:可见光+红外+紫外,不同波段突出不同特征(如紫外激发荧光)
-
偏振成像:加装偏振片,抑制金属/水面反光
-
动态曝光:根据环境光实时调整曝光时间,保持图像稳定
-
频闪照明:与相机曝光同步,提高瞬时亮度,适合高速运动
2.4 四大工业自动化场景的完整设计与难点突破
场景一:精密装配与引导定位(航天器舱段对接)
场景描述:大型航天器舱段在总装过程中需实现毫米级对接,传统人工吊装效率低、风险高。要求视觉系统实时测量对接环的6D位姿(X,Y,Z,Roll,Pitch,Yaw),引导机械臂完成自动对接,对接精度±0.05mm,节拍≤3分钟/次。
硬件选型:
-
双目立体相机(各500万像素,全局快门)+ 结构光投影仪(红外波段)
-
激光测距仪(辅助深度测量)
-
机械臂末端安装高精度IMU(惯性测量单元)
打光方案:
-
高亮度LED环形光源(白色),避开对接面反光区域
-
结构光采用红外波段(850nm),避免环境光干扰
-
偏振片抑制金属表面反光
采图与标注:
-
采集不同光照、不同角度下的对接环图像(1000组)
-
标注环面边缘、特征点(螺栓孔、销钉)——使用多边形标注工具
-
标注6D位姿真值(通过激光跟踪仪测量)
算法设计:
-
关键点检测:YOLOv8-Pose检测对接环上的特征点(至少4个)
-
位姿解算:PnP算法(Perspective-n-Point),根据2D-3D对应点计算6D位姿
-
深度融合:双目视差+结构光深度,提升Z轴精度
-
时序平滑:卡尔曼滤波对连续位姿序列进行平滑,结合IMU数据补偿振动
部署:
-
位姿解算频率≥50Hz,通过EtherCAT实时传输给机器人控制器
-
机器人控制器采用位置控制模式,实时跟踪目标位姿
难点与解决方案:
| 难点 | 解决方案 |
|---|---|
| 金属表面反光导致特征丢失 | 偏振成像+多角度照明(环形光+同轴光组合),利用深度学习修复缺失边缘;引入反射模型实时调整曝光 |
| 对接环存在公差,特征不一致 | 引入三维模型匹配算法,基于CAD模型进行模板匹配,不依赖固定特征点 |
| 振动环境下位姿抖动 | 卡尔曼滤波平滑+IMU数据融合,补偿高频振动;采用鲁棒估计(RANSAC)剔除异常匹配点 |
| 现场存在强电磁干扰 | 所有信号线缆双层屏蔽,视觉处理单元独立机箱并接地,通信采用光纤隔离 |
实际项目成果:系统在模拟舱段对接试验中,对接成功率达99.5%,平均对接时间2分30秒,较人工提升效率40%。
场景二:高精度几何测量(导弹弹头轮廓检测)
场景描述:导弹弹头外轮廓必须满足气动外形公差要求(±0.01mm),需在生产线末端进行全尺寸在线测量,测量节拍≤10秒/件。
硬件选型:
-
远心镜头(消除透视畸变,放大倍率恒定)
-
高分辨率线阵相机(16k像素,采样率80kHz)
-
背光光源(高亮度LED,平行光)
-
精密旋转台(重复定位精度±0.002°)
打光方案:
-
背光照明,突出轮廓边缘,消除表面纹理干扰
-
平行光保证边缘锐利,无散射
采图:
-
旋转弹头(360°),线阵相机连续采集,重建圆柱面展开图
-
采集分辨率:每圈10000行,像素尺寸对应实物0.005mm
算法设计:
-
亚像素边缘提取:Canny算子检测边缘,然后通过插值(抛物线拟合)定位到亚像素精度(0.1像素)
-
轮廓拟合:最小二乘法拟合轮廓曲线,与CAD模型比对生成偏差云图
-
误差补偿:温度传感器实时采集环境温度,补偿热胀冷缩;旋转台偏心标定校正
部署:
-
工控机+GPU,实时输出测量报表
-
超差时自动报警,并标记不合格区域位置
难点与解决方案:
| 难点 | 解决方案 |
|---|---|
| 旋转台同心度误差导致图像扭曲 | 使用标准球标定旋转轴心(标定球直径已知),软件校正偏心;采用双相机对向测量,消除偏心影响 |
| 弹头表面存在油污/划痕干扰边缘 | 形态学滤波去除孤立噪点,采用RANSAC算法拟合椭圆,鲁棒剔除异常点(油污、划痕) |
| 环境温度变化导致热胀冷缩 | 引入温度传感器实时补偿尺寸偏差,每半小时自动标定一次标准件(石英棒) |
| 测量节拍要求<10秒/件 | FPGA硬件加速边缘提取,软件多线程并行处理(采集线程+计算线程流水线) |
实际项目成果:测量精度±0.005mm,重复性±0.002mm,单件测量时间8.5秒,满足军工质检要求。
场景三:复杂环境下目标识别与跟踪(无人机战场侦察)
场景描述:无人机在复杂战场环境下需自动识别敌方车辆、人员、伪装目标,并持续跟踪,抗干扰、抗欺骗。识别距离≥5km,跟踪精度≤1像素(稳定),目标丢失重捕获时间≤1秒。
硬件选型:
-
三光吊舱:可见光(30倍光学变焦)+ 长波红外(640×512)+ 激光测距(5km)
-
全部国产化(如中电科某型)
-
嵌入式边缘计算模块(国产AI芯片,算力≥100 TOPS,功耗≤30W)
打光:
-
无主动照明,依靠环境光与目标自身热辐射
-
夜间依靠热红外成像
采图与标注:
-
利用历史演习数据与仿真数据,构建样本库
-
目标类别:车辆(坦克、装甲车、运输车)、人员(单兵、班组)、装备(无人机、雷达)、伪装目标(伪装网、迷彩)
-
标注属性:类型、姿态(静止/运动)、方向、是否伪装
算法设计:
-
多模态融合检测:基于Transformer的融合网络,输入可见光、红外、激光雷达特征,输出3D目标检测结果
-
跟踪算法:卡尔曼滤波(运动预测)+ 光流法(特征点跟踪)+ 轨迹关联(匈牙利算法)
-
抗干扰:对抗训练(输入添加对抗样本),提升对伪装、欺骗的鲁棒性
-
云台控制:PID控制器,保持目标在视野中央
部署:
-
嵌入式边缘计算模块与飞控深度集成,通过串口或CAN总线通信
-
实现“锁定即跟”:操作员框选目标后,系统自动跟踪
难点与解决方案:
| 难点 | 解决方案 |
|---|---|
| 目标被树木/烟雾部分遮挡 | 利用热红外穿透烟雾,结合时序信息预测目标运动轨迹(卡尔曼滤波);采用“检测-跟踪-再检测”闭环,遮挡消失后快速重捕获 |
| 伪装网/迷彩降低可见光特征 | 短波红外+热红外联合识别,利用材料光谱差异(伪装网在短波红外波段反射率与植被不同);引入高光谱分析(如搭载多光谱相机) |
| 敌方释放红外诱饵弹 | 基于目标运动模型(诱饵弹弹道抛物线,车辆运动连续)与尺寸稳定性(诱饵弹尺寸小且衰减快)过滤诱饵,多目标跟踪关联(利用轨迹一致性) |
| 高速机动导致图像模糊 | 采用运动去模糊算法(基于GAN或Transformer),提升清晰度;提高相机帧率(≥60fps)并缩短曝光时间 |
| 电子干扰导致定位漂移 | 融合激光测距与惯性导航(IMU),不依赖GPS;采用抗干扰天线和跳频通信 |
实际项目成果:目标检测准确率≥98%(典型目标),跟踪精度1.2像素,抗干扰能力显著优于传统方法。
场景四:内部缺陷无损检测(装甲车焊接质量检测)
场景描述:装甲车体焊缝内部可能存在气孔、裂纹等缺陷,需在不破坏结构的前提下100%检测。检测速度≥2米/分钟,缺陷识别率≥98%。
硬件选型:
-
工业X射线数字成像系统(DR)+ 线阵探测器 + 自动扫描机构
-
X射线管电压可调(80-200kV),电流可调(1-10mA)
-
辅助红外热成像(用于表面缺陷检测)
打光:
-
无可见光需求,X射线源与探测器配合
-
红外热成像需预热,发射率设置需根据材料调整
采图:
-
连续扫描焊缝,生成DR图像(分辨率:0.1mm/像素)
-
同步采集热成像图(帧率30fps)
算法设计:
-
图像增强:自适应直方图均衡、非局部均值滤波(NL-means),提升对比度
-
缺陷分割:U-Net语义分割网络,输出缺陷区域掩码
-
缺陷分类:传统特征提取(灰度、面积、长宽比、圆形度)+ 随机森林分类,判断缺陷类型(气孔、裂纹、未熔合)
-
缺陷等级评定:根据缺陷尺寸、数量、位置综合评定
部署:
-
离线工作站,检测结果自动生成报告,并关联焊缝编号
-
支持历史数据追溯和质量趋势分析
难点与解决方案:
| 难点 | 解决方案 |
|---|---|
| X射线图像对比度低、噪声大 | 自适应直方图均衡(CLAHE)增强局部对比度;非局部均值滤波保留边缘去噪;深度学习去噪网络(DnCNN)预处理 |
| 缺陷样本极少(良率高) | 生成对抗网络(GAN)生成虚拟缺陷样本(CycleGAN风格迁移);数据增强(旋转、缩放、添加噪声);迁移学习(预训练于工业X光数据集如GDXray) |
| 不同厚度区域成像差异大 | 动态调整X射线管电压/电流,保证各区域曝光适当(自动曝光控制AEC);采用多能谱成像融合(不同能量下的图像叠加) |
| 检测效率要求高 | 并行处理流水线:采集与推理同步进行(双缓冲),实现实时检测;GPU加速推理(TensorRT) |
| 缺陷类型多样(气孔、裂纹等) | 多任务学习,同时输出缺陷类别和分割掩码;引入专家规则库辅助判断(如裂纹通常沿焊缝方向延伸) |
实际项目成果:缺陷识别率≥98%,误检率≤0.5%,检测速度2.5米/分钟,满足军工质检要求。
2.5 行业案例:半导体晶圆缺陷检测
场景描述:半导体晶圆制造过程中,表面缺陷(颗粒、划痕、图案缺陷)直接影响芯片良率。晶圆直径300mm,缺陷尺寸要求≤0.1μm,检测速度要求≥100片/小时。这是半导体行业最核心、难度最高的视觉检测任务之一。
-
精度要求极高:0.1μm级缺陷,远超普通工业视觉(通常0.1mm级)
-
成像难度大:晶圆表面高反光,图案复杂,缺陷与背景对比度极低
-
数据稀缺:良率极高,缺陷样本极少,且缺陷形态多样
-
速度要求高:每片晶圆需检测数百个芯片,总时间需控制在30秒内
-
行业普遍性:全球半导体制造均需此技术,是衡量视觉系统能力的“试金石”
硬件选型:
-
相机:高分辨率线阵相机(16k像素,像元尺寸3.5μm),配合高精度运动平台(定位精度±0.5μm)
-
镜头:高倍率远心镜头(放大倍率5×~20×),保证全视野放大倍率恒定
-
光源:多角度多光谱照明系统(明场+暗场+共焦),可根据不同缺陷类型切换
-
运动控制:气浮平台(高速、无摩擦),运动速度≥500mm/s
打光方案:
-
明场照明:垂直入射,检测颗粒、划痕等散射缺陷
-
暗场照明:斜入射,检测微小颗粒、表面粗糙度变化
-
共焦照明:点扫描,检测深度方向的缺陷(如凹坑)
-
多光谱融合:不同波长对不同类型的缺陷敏感(短波对表面缺陷敏感,长波对亚表面缺陷敏感)
采图策略:
-
晶圆逐行扫描,每片产生超过10万张图像(单张图像尺寸约2000×2000像素)
-
每张图像包含多个芯片,需要精确定位芯片边界
-
数据量极大:单片晶圆原始图像数据可达50GB以上
标注策略:
-
使用扫描电子显微镜(SEM)对缺陷区域进行复检,生成高精度标注真值
-
采用主动学习:模型识别困难样本,优先送SEM复检
-
标注类别:颗粒、划痕、图案缺陷(断线、桥接、缺失)、凹坑等
算法设计:
-
图像预处理:
-
图像配准:将采集图像与设计版图(GDSII)精确对齐,消除运动误差
-
噪声去除:小波变换去噪,保留高频细节
-
灰度校正:消除光源不均匀性
-
-
缺陷检测:
-
差分法(Die-to-Die):比较相邻芯片的图像,差异区域即为潜在缺陷。这是半导体检测最经典、最可靠的方法。
-
差分法(Die-to-Golden):与标准芯片模板比较,适用于重复性高的场景。
-
深度学习分割:U-Net、DeepLab等模型,直接从图像分割缺陷区域,适合复杂缺陷形态。
-
-
缺陷分类:
-
传统特征提取(面积、长宽比、圆度、纹理) + SVM/随机森林分类
-
深度学习分类器(ResNet、EfficientNet),对缺陷类型进行分类
-
-
缺陷量测:
-
亚像素边缘提取,精确测量缺陷尺寸
-
与设计规则比对,判断是否超出容忍范围
-
部署架构:
-
离线检测:扫描完成后集中处理,适合研发阶段
-
在线检测:边扫描边处理,实时报警,适合量产产线
-
并行处理:多GPU集群(8-16张GPU),分布式处理,单片晶圆处理时间<30秒
难点与解决方案(深化版):
| 难点 | 解决方案 | 技术依据 |
|---|---|---|
| 缺陷尺寸极小(0.1μm),远超光学衍射极限 | 采用高倍率远心镜头+亚像素边缘提取,结合多角度照明增强缺陷对比度 | 光学分辨率受限于波长,但亚像素算法可将定位精度提升至0.1像素以下 |
| 晶圆表面高反光,图案复杂 | 多角度多光谱照明(明场+暗场+共焦),偏振成像抑制反光;差分法消除背景图案干扰 | 暗场照明对微小颗粒敏感;差分法通过相邻芯片比较消除固定图案 |
| 缺陷样本极其稀缺 | 生成对抗网络(GAN)生成虚拟缺陷样本;迁移学习(预训练于其他半导体数据集);异常检测(仅学习正常样本) | 工业界普遍采用“正常样本建模+异常检测”应对数据稀缺问题 |
| 数据量极大,处理速度要求高 | 并行处理流水线(采集+预处理+检测+分类多线程);GPU集群加速;模型量化(INT8) | TensorRT INT8量化可保持95%精度,速度提升3-5倍 |
| 缺陷形态多样,难以穷举 | 多模型融合:差分法(召回率高)+深度学习(精度高)互补;集成学习(多个模型投票) | 差分法对任何“不同”都敏感,可覆盖未知缺陷类型;深度学习对已知类型精度高 |
| 设备振动、运动误差导致图像错位 | 高精度运动平台(气浮);图像配准算法(基于互相关或深度学习特征匹配) | 配准精度需达到亚像素级,否则差分法会产生大量伪缺陷 |
实际项目成果(参考行业标杆):
-
全球领先的半导体设备商(如KLA、Applied Materials)的晶圆检测系统,可实现0.1μm缺陷的检测,单晶圆处理时间<30秒,缺陷识别率>99%
-
国产替代方案(如中科飞测、上海精测)已实现28nm制程以下晶圆检测,逐步打破国外垄断
对工业视觉的启示:
-
半导体晶圆检测代表了工业视觉的“天花板”——精度最高、速度最快、数据量最大、算法最复杂
-
其技术方案(差分法+深度学习融合、并行处理、亚像素边缘提取)可降维应用于其他高端制造场景
-
数据稀缺问题的解决方案(异常检测、GAN生成)对其他工业场景有直接借鉴意义
2.6 工业视觉的五大核心困境
困境一:成像困境——拍不清楚,神仙难救
工业现场的成像条件远比实验室复杂:
-
光照不稳定:环境光变化、光源老化、工件表面反光
-
材质复杂:透明件、黑色吸光件、高反光件
-
运动模糊:高速流水线上工件抖动
-
景深不足:大尺寸工件不同部位高度差大
解决思路:工业项目常把70%的精力花在打光方案上,而非算法调参。光源、镜头、相机的选型和组合,往往是项目成败的分水岭。推荐流程:先确定检测需求(缺陷类型、精度、节拍)→ 选择合适的光源类型和打光方式 → 选择相机和镜头 → 采图验证 → 调整优化。
困境二:数据困境——缺陷样本比中彩票还难
工业缺陷检测项目最大的“坑”在于:你想检测的缺陷,恰恰是工厂最不想产生的。
-
缺陷样本稀缺:良率98%的产品,缺陷样本只占2%,且种类分散
-
缺陷形态不可控:划痕有长有短、有深有浅;脏污形态千变万化
-
标注成本极高:需要经验丰富的质检员逐像素标注
-
正负样本失衡:正常样本远多于缺陷样本
解决思路:
-
数据增强:通过合成缺陷、生成对抗网络(GAN)生成虚拟缺陷样本
-
迁移学习:用预训练模型+少量真实样本微调
-
异常检测:只学习“正常样本”的分布,偏离即判为异常(适合缺陷形态多变但正常形态稳定的场景)
-
主动学习:模型识别困难样本,优先送人工标注,提高标注效率
困境三:算法困境——精度、速度、算力的不可能三角
工业现场对算法有严格的三重要求:高精度、高速度、低算力成本,这三者往往难以兼得。
-
精度 vs 速度:用大模型追求最高mAP,但推理时间超限
-
深度学习 vs 传统算法:深度学习效果更好,但工业现场需要稳定、可解释、易调试
-
算力成本:工控机往往只有中低端GPU甚至CPU,算力受限
解决思路:
-
模型轻量化:用轻量级网络(MobileNet、EfficientNet-Lite)+ TensorRT/OpenVINO加速
-
传统+深度结合:用传统算法做粗定位(减少ROI),深度学习只处理关键区域
-
边缘部署:算力不够时考虑用NVIDIA Jetson等边缘计算设备
困境四:部署与运维困境——上线才是噩梦的开始
模型训练完成只是开始,真正的考验在产线部署和长期运维阶段。
-
环境差异:实验室光照、温度、振动与产线完全不同
-
硬件兼容性:相机、PLC、工控机、光源控制器需协同
-
模型退化:产线长期运行后,光源衰减、机械磨损、来料批次变化
-
维护成本:产线换型(新产品)需重新训练模型
解决思路:
-
灰度发布:新模型先小流量验证,稳定后再全量替换
-
自动化标注:建立“人工复检→自动标注→模型迭代”的闭环
-
低代码平台:让现场工程师能通过标注少量样本完成模型更新
-
预测性维护:监控光源衰减、镜头污染等,提前预警
困境五:项目管理困境——需求变、验收难、成本算不过来
工业视觉项目往往是“非标项目”,每个客户、每种产品都要定制化开发。
-
需求不明确:甲方说“我要检测划痕”,但什么算划痕?多深算?多长算?
-
验收标准苛刻:要求“零漏检”,但人工也有漏检
-
成本高企:硬件+软件+算法+调试+维护
-
项目周期长:从选型到交付,动辄3-6个月
解决思路:
-
需求前期固化:用标准样品+明确定义(缺陷定义卡)锁定验收标准
-
平台化交付:将通用能力封装成平台,减少重复开发
-
分阶段验收:硬件验收→算法验收→试运行验收→终验,降低回款风险
-
成本控制:优先选用国产替代方案,复用已有算法模块
第三部分:跨界借鉴——其他行业的视觉方案
3.1 自动驾驶:多传感器融合 vs 纯视觉的路线之争
特斯拉FSD(纯视觉路线)
-
硬件:8个摄像头(1280×960,36Hz),自研FSD芯片(144 TOPS)
-
算法:HydraNet(共享骨干网络+多任务头),BEV(鸟瞰视图)+ Transformer,将8个摄像头的2D图像融合为3D空间感知
-
数据闭环:影子模式+自动标注+超算中心训练。全球数百万辆车实时采集边缘场景,自动回传,形成数据飞轮
-
优势:成本低(感知硬件约500-6000元),系统简洁,数据闭环强大
-
劣势:浓雾/暴雨下性能下降,深度估计存在误差,有“幻觉”风险(如将广告牌上的车辆识别为真实车辆)
-
对工业的启示:数据闭环是持续迭代的关键。工业场景也可建立“产线数据→云端训练→模型更新”的闭环,实现模型的持续优化。
华为ADS(多传感器融合路线)
-
硬件:激光雷达(896线,图像级点云)+ 毫米波雷达(4D成像)+ 超声波雷达 + 摄像头(11个)
-
算法:GOD网络(通用障碍物检测)+ PDP网络,端到端架构,不依赖高精地图
-
优势:极端天气下性能稳定(激光雷达穿透雨雾),异形障碍物识别能力强(如路面散落的轮胎、纸箱),可解释性好
-
劣势:成本高(感知硬件约2万元),系统复杂,数据融合难度大
-
对工业的启示:多传感器冗余是提升系统可靠性的关键。在关键工位,可采用“可见光+红外+激光”多模态融合,保证单传感器失效时系统仍能工作。
Waymo(L4级自动驾驶标杆)
-
硬件:第五代Robotaxi配备8颗摄像头、5颗雷达和3颗激光雷达;第六代增加到13颗摄像头、4颗激光雷达,最远探测距离500米
-
策略:不追求“减配”,只追求“绝对安全”。采用极致的硬件冗余,任何单点失效不影响系统运行
-
应用:无人出租车(每周超25万次付费出行)、无人货运
-
对工业的启示:对于军工等安全关键场景,应采用极致冗余设计——双计算节点、多传感器异构融合、双电源备份。
英伟达(底层算力平台)
-
芯片:Orin(254 TOPS)、Thor(2000 TOPS),集成安全岛(ASIL-D功能安全等级)
-
软件:DriveOS、DriveWorks SDK、Drive Sim(仿真平台)
-
优势:全球超过90%的自动驾驶公司使用其芯片,从数据中心训练到车端推理的全栈支持
-
对工业的启示:选择生态成熟的算力平台可大幅降低开发难度。工业场景可优先选用NVIDIA Jetson或华为昇腾等有完善生态的硬件。
深度借鉴点:
-
BEV感知架构:将多相机2D特征融合为3D空间表示,可用于工业中的多相机拼接、大范围场景感知
-
端到端架构:从感知直接输出控制指令,减少中间环节,降低延迟
-
影子模式:持续采集“边缘场景”,用于模型迭代。工业场景可采集“人工复检”数据,优化模型
-
高精度时空同步:多传感器微秒级同步,是融合感知的基础
3.2 医疗视觉:从专用模型到多模态大模型
德适生物 iMedImage™
-
定位:全球参数规模最大的医学影像通用大模型
-
数据:基于8000万医疗数据预训练,支持CT、MRI、超声、染色体等19种模态
-
效果:构建新专病模型仅需数百例影像和数天训练,成本降低超90%
-
市场:染色体核型分析准确率99.86%,2024年中国市场占有率30.6%,打破蔡司、徕卡垄断
-
对工业的启示:基础模型+微调范式可大幅降低工业视觉新场景的开发成本。用一个通用模型(如SAM、DINOv2)覆盖多种任务,新场景仅需少量样本微调。
深睿医疗 Deepwise MetAI X
-
架构:“影像+文本”双AI引擎,整合放射、超声、内镜、核医学、病理等多模态数据
-
功能:报告智能生成、纠错、结构化解读,全院级影像中枢
-
应用:连续多届CMEF核心展品,已落地数百家医院
-
对工业的启示:多模态融合(视觉+文本+传感器)可实现综合认知。工业场景可融合视觉检测结果与工艺参数、设备状态、维修记录,实现智能决策。
哈医大一院 CorVIS系统
-
功能:冠状动脉CTA全息可视化,5秒内完成智能分割、斑块分析、三维重建
-
精度:准确率95%
-
创新:国际首创,获中俄博览会高度评价
-
对工业的启示:实时三维重建可应用于工业数字孪生。将2D图像重建为3D模型,用于虚拟装配、远程维修指导。
MSDA-VLM(手术室屏幕数据采集)
-
场景:手术室监护设备屏幕数据采集(设备无标准接口,医生需手动抄录)
-
技术:视觉语言模型(VLM)+ 模糊检测(基于LBP纹理特征),在预训练VLM基础上微调
-
效果:识别精度提升17%,已在真实医院系统部署
-
对工业的启示:视觉语言模型可解决工业中“非结构化数据采集”问题。例如,读取老旧设备的仪表盘读数、识别铭牌上的参数。
深度借鉴点:
-
基础模型+微调:用通用模型快速适应新场景,大幅降低数据需求
-
多模态融合:融合影像、文本、时序数据,实现综合诊断
-
可解释性输出:输出置信度、热力图、量化指标,增强决策可信度
-
小样本学习:仅需数十张样本即可微调,解决工业数据稀缺问题
3.3 文化艺术:高精度三维重建与数字化
数字敦煌
-
技术:多视角三维重建(结构光扫描+多视图立体),纹理映射
-
精度:毫米级,支持在线360°浏览
-
规模:30个洞窟、4.5万平方米壁画、2000尊彩塑
-
对工业的启示:多视角融合可用于装备数字孪生。无人机+地面相机协同,构建大范围高精度地图。
Art Recognition(艺术品鉴真)
-
技术:笔触特征分析(卷积神经网络提取笔触纹理),微观纹理识别
-
精度:鉴定油画真伪,准确率>95%
-
应用:已鉴定数百幅作品,包括疑似达芬奇作品
-
对工业的启示:微观纹理分析可用于高端制造中的材料鉴别、表面质量评估。
谷歌Arts & Culture
-
技术:NeRF(神经辐射场)+ Gaussian Splatting(高斯泼溅)实时重建
-
功能:文物虚拟复原,沉浸式AR/VR展示
-
性能:Gaussian Splatting比NeRF快100倍,支持实时渲染
-
对工业的启示:实时三维重建可用于虚拟维修训练、远程协作、战场环境快速建模。
深度借鉴点:
-
NeRF/Gaussian Splatting:从稀疏视角快速重建高保真3D场景
-
纹理映射:将高分辨率纹理映射到3D模型,提升逼真度
-
多视角融合:多相机协同,构建大范围高精度地图
3.4 安防与智慧城市:视频结构化与大规模检索
海康威视“深眸”
-
功能:人脸识别布控,亿级底库毫秒级检索
-
技术:大规模人脸检索(特征向量索引)、跨年龄段识别、活体检测
-
场景:城市级监控、重大活动安保
-
对工业的启示:大规模检索技术可用于工业质量追溯。快速检索历史缺陷图像,分析缺陷趋势。
旷视“河图”
-
功能:行为分析、行人重识别、异常行为实时告警
-
技术:姿态估计(HRNet)、时序动作识别(SlowFast)
-
场景:智能安防、智慧园区
-
对工业的启示:行为分析可用于工厂安全监控(如检测工人未戴安全帽、进入危险区域)。
商汤方舟
-
功能:视频结构化,从视频中提取“穿红衣男子”等属性信息
-
技术:行人重识别(ReID)、属性识别(性别、年龄、着装)
-
场景:公共安全、商业智能
-
对工业的启示:视频结构化可用于仓储物流中的人员/货物追踪。
深度借鉴点:
-
边缘-云协同:边缘节点实时处理,云端训练和存储,平衡延迟与算力
-
多目标跟踪:ReID技术可应对目标遮挡、再识别,适用于复杂场景
-
视频结构化:从监控视频中提取结构化信息,用于质量追溯、行为分析
3.5 新零售与消费电子:轻量化、低功耗、体验优先
Amazon Go(即拿即走)
-
硬件:顶视相机+重力传感器+货架传感器
-
算法:多目标跟踪+商品检测+重力感应融合
-
性能:同时追踪50+顾客,购物准确率>99%
-
技术:不依赖RFID,纯视觉+传感器融合
-
对工业的启示:多传感器融合(视觉+重力)可提升定位精度,用于仓储自动化、无人零售。
苹果Face ID
-
硬件:3D结构光(红外点阵投影仪+红外相机+泛光照明)
-
算法:深度学习人脸识别+活体检测(防照片/面具攻击)
-
性能:误识率<1/1,000,000,功耗极低
-
对工业的启示:低功耗嵌入式视觉可用于单兵装备、便携检测设备;活体检测技术可防止欺骗攻击。
Google Lens
-
功能:以图搜图、文字识别、商品搜索
-
技术:特征向量检索(对比学习),支持10亿级图片库毫秒级检索
-
应用:拍照购物、文字翻译、植物识别
-
对工业的启示:以图搜图可用于工业故障诊断(拍摄故障零件,检索相似历史案例)。
深度借鉴点:
-
低功耗设计:移动端模型剪枝、量化技术可迁移到工业嵌入式平台
-
多传感器融合:视觉+惯性+重力,提升定位精度
-
以图搜图:特征向量检索,可用于故障诊断、质量追溯
3.6 各行业方案对比总结
| 行业 | 核心需求 | 技术重点 | 可借鉴点 |
|---|---|---|---|
| 工业/制造 | 精密测量、缺陷检测、定位引导 | 高精度、高速度、稳定性 | 亚像素边缘提取、多模态融合、小样本学习 |
| 自动驾驶 | 环境感知、决策规划、定位建图 | 多传感器融合、BEV感知、端到端 | 冗余设计、数据闭环、高精度时空同步 |
| 医疗 | 辅助诊断、手术导航、染色体分析 | 多模态融合、可解释性、高敏感度 | 基础模型+微调、多模态大模型、小样本学习 |
| 文化艺术 | 文物数字化、虚拟修复、沉浸式展示 | 三维重建、纹理映射、高保真渲染 | NeRF/Gaussian Splatting、多视角融合 |
| 安防 | 人脸识别、车辆布控、行为分析 | 大规模检索、视频结构化 | 边缘-云协同、多目标跟踪、视频结构化 |
| 新零售 | 即拿即走、客流分析、货架巡检 | 多目标跟踪、轻量化模型 | 多传感器融合、低成本边缘部署 |
| 消费电子 | 人脸解锁、计算摄影、AR交互 | 低功耗、实时性、自然交互 | 低功耗嵌入式视觉、异构计算、隐私保护 |
跨界借鉴的核心逻辑:
-
自动驾驶教会我们:冗余设计、数据闭环、BEV感知
-
医疗教会我们:基础模型+微调、多模态融合、可解释性
-
文化艺术教会我们:实时三维重建、高保真渲染
-
安防教会我们:边缘-云协同、大规模检索
-
新零售教会我们:低成本多传感器融合、轻量化模型
-
消费电子教会我们:低功耗设计、自然交互
第四部分:视觉数字化的两大框架与前沿技术
4.1 图像识别:感知与理解——从像素到语义的压缩
这是视觉数字化的“眼睛”,负责从图像中提取信息、理解世界。其本质是一个“压缩”过程——将数百万像素压缩成几个类别、几个坐标、几段描述。
| 子任务 | 核心目标 | 技术代表 | 典型应用 | 工业价值 |
|---|---|---|---|---|
| 分类 | “这是什么?” | ResNet、ViT、ConvNeXt | 图片标签、内容审核 | 产品良品/不良品分类 |
| 检测 | “它在哪里?” | YOLO、Faster R-CNN、DETR | 缺陷定位、车辆检测 | 缺陷位置标记、目标定位引导 |
| 分割 | “它长什么样?” | U-Net、Mask R-CNN、SAM | 病灶分割、遥感地物提取 | 精确勾勒缺陷轮廓、尺寸测量 |
| 姿态估计 | “它怎么动的?” | HRNet、MediaPipe | 人机交互、运动分析 | 工人动作识别、机械臂位姿估计 |
| 深度估计 | “它有多远?” | MiDaS、Monodepth2 | 自动驾驶、AR/VR空间定位 | 3D测量、抓取点深度计算 |
技术演进路径:
-
第一阶段:手工特征(SIFT、HOG)+ 浅层分类器(SVM)——特征工程主导
-
第二阶段:卷积神经网络(AlexNet、ResNet)——端到端学习,特征自动提取
-
第三阶段:视觉Transformer(ViT、Swin)——全局建模,突破CNN局部感受野限制
-
第四阶段:基础模型(SAM、DINOv2)——大规模预训练,零样本/小样本泛化
工程应用中的关键考量:
-
精度与速度的平衡:工业场景常采用“轻量级骨干(如EfficientNet)+ TensorRT量化”,在保持95%精度的前提下,速度提升3-5倍
-
小样本适应性:采用迁移学习(ImageNet预训练)+ 微调,仅需数百张标注样本即可达到可接受的精度
-
可解释性需求:输出热力图(Grad-CAM)、置信度、特征可视化,帮助工程师理解模型决策
4.2 图像生成:合成与创造——从隐空间到像素的解码
这是视觉数字化的“画笔”,负责创造新的、不存在的图像内容。其本质是一个“解压缩”过程——从随机噪声或文字描述,一步步去噪生成有意义的图像。
| 子任务 | 核心目标 | 技术代表 | 典型应用 | 工业价值 |
|---|---|---|---|---|
| 文生图 | 从文字描述生成图像 | Stable Diffusion、DALL·E、Midjourney | 创意设计、概念图生成 | 新产品外观设计、缺陷样本生成 |
| 图像编辑/修复 | 修改图像内容 | Inpainting(SD Inpaint)、ControlNet | 老照片修复、物体擦除 | 去除图像中的无关物体、修复遮挡区域 |
| 图像超分辨率 | 低清变高清 | ESRGAN、Real-ESRGAN、Stable Diffusion Upscaler | 监控图像增强、医疗影像超分 | 提升低分辨率工业图像的检测精度 |
| 风格迁移 | 改变图像风格 | CycleGAN、AdaIN | 艺术创作、虚拟试妆 | 模拟不同光照条件下的成像效果 |
| 三维生成 | 从2D生成3D | NeRF、DreamFusion、TripoSR | 3D资产创建、数字孪生 | 从多视角2D图像重建3D模型 |
| 视频生成 | 生成动态内容 | Sora、Runway Gen-3、Luma Dream Machine | 短视频制作、虚拟场景生成 | 生成动态仿真数据,用于算法训练 |
技术演进路径:
-
第一阶段:生成对抗网络(GAN)——生成器与判别器博弈,生成逼真图像,但训练不稳定
-
第二阶段:扩散模型(Diffusion Model)——逐步去噪生成,训练稳定,生成质量高,成为主流
-
第三阶段:多模态条件生成(ControlNet、IP-Adapter)——通过文本、边缘图、深度图等条件控制生成内容,可控性大幅提升
-
第四阶段:视频生成与世界模型(Sora)——生成连续、物理一致的视频,模拟世界演化
工程应用中的关键考量:
-
缺陷样本生成:利用扩散模型生成虚拟缺陷图像,解决工业数据稀缺问题。例如,在半导体晶圆检测中,可生成各种形态的划痕、颗粒、图案缺陷
-
数据增强:生成不同光照、角度、背景下的图像,提升模型鲁棒性
-
仿真数据生成:结合数字孪生,生成高保真仿真数据,用于算法训练和验证
4.3 交互与仿真:融合与闭环——从被动感知到主动参与
这是正在崛起的新范式,将“识别”和“生成”结合,形成一个可交互、可演进的数字世界。其本质是建立“感知-决策-行动-反馈”的闭环。
| 子方向 | 核心目标 | 技术代表 | 典型应用 | 工业价值 |
|---|---|---|---|---|
| 具身智能/视觉-语言-行动 | 看懂+生成+行动 | RT-2、OpenVLA | 机器人根据指令完成任务 | 自然语言指挥工业机器人 |
| 世界模型 | 模拟物理世界的演化 | Sora、Genie、Unreal Engine 5 + AI | 预测下一帧、仿真训练 | 预测缺陷演化、虚拟试运行 |
| 数字孪生/三维重建 | 构建物理世界的数字副本 | Gaussian Splatting、NeRF、RealityCapture | 工业数字孪生、智慧城市 | 产线数字孪生、远程运维 |
| 视觉语言导航 | 理解环境并规划路径 | VLN-BERT、Habitat | 室内机器人导航、盲人辅助 | AGV自主导航、无人机侦察 |
| 神经渲染 | 实时生成逼真场景 | DLSS 3.5、Unreal Engine 5.5 | 游戏实时渲染、虚拟制片 | 虚拟培训、维修辅助 |
技术演进路径:
-
第一阶段:数字孪生——静态3D模型,离线渲染
-
第二阶段:实时重建(NeRF、Gaussian Splatting)——从稀疏视角实时重建动态场景
-
第三阶段:世界模型——模拟物理世界演化,预测未来状态
-
第四阶段:具身智能——视觉-语言-行动统一建模,实现自主决策
工程应用中的关键考量:
-
数字孪生:构建产线、装备的高保真数字副本,用于远程监控、故障诊断、虚拟调试
-
世界模型:预测缺陷演化趋势,实现预测性维护;模拟产线运行,优化生产节拍
-
具身智能:实现自然语言指挥机器人,降低编程门槛
4.4 前沿技术成果
基础模型(Foundation Model)
-
代表:SAM(Segment Anything Model)、DINOv2、CLIP
-
特点:在海量数据上预训练,获得通用视觉理解能力;可通过提示(点、框、文本)灵活适应不同任务
-
工业价值:零样本分割(SAM可直接分割图像中的任何物体),小样本微调(仅需数十张样本即可适应新任务),大幅降低数据需求
-
技术细节:SAM采用Transformer架构,在1100万张图像上预训练,支持点、框、文本等多种提示方式;DINOv2采用自监督学习,无需标注即可学习鲁棒特征
世界模型(World Model)
-
代表:Sora、Genie
-
特点:模拟物理世界的演化规律,预测未来帧;可生成连续、物理一致的视频,时长可达60秒
-
工业价值:仿真训练(生成虚拟环境用于算法测试),缺陷演化预测(预测微小缺陷的发展趋势),虚拟试运行(模拟产线运行,优化参数)
-
技术细节:Sora采用扩散Transformer(DiT)架构,在大量视频数据上训练,涌现出对物理规律的理解(如重力、碰撞、遮挡)
多模态融合
-
代表:CLIP、Flamingo、GPT-4V
-
特点:统一文本、图像、语音、传感器信号的表示空间,实现跨模态理解和生成
-
工业价值:综合认知能力(可处理“看到+理解+推理”的复杂任务),自然交互(用自然语言查询视觉内容),知识融合(将工艺文档与视觉检测结果关联)
-
技术细节:CLIP通过对比学习对齐图像和文本特征;Flamingo通过交叉注意力融合视觉特征与语言模型
神经辐射场(NeRF)与高斯泼溅(Gaussian Splatting)
-
代表:NeRF、3D Gaussian Splatting
-
特点:从稀疏视角合成高保真3D场景;高斯泼溅比NeRF快100倍,支持实时渲染
-
工业价值:实时三维重建(装备数字孪生),虚拟维修训练(沉浸式培训),战场环境快速建模
-
技术细节:NeRF用MLP隐式表示场景,需要大量采样点;高斯泼溅用3D高斯函数显式表示,通过光栅化快速渲染
扩散模型(Diffusion Model)
-
代表:Stable Diffusion、DALL·E
-
特点:通过逐步去噪生成高质量图像,可控性强,训练稳定
-
工业价值:生成虚拟缺陷样本,数据增强,超分辨率增强,图像修复
-
技术细节:前向过程逐步添加噪声,反向过程学习去噪;通过文本嵌入控制生成内容
对抗防御
-
代表:对抗样本检测、模型指纹、后门检测
-
特点:检测并防御针对深度模型的攻击,保障系统安全
-
工业价值:防止敌方利用对抗攻击欺骗视觉系统(如通过在车辆上贴特殊图案使模型漏检),保障供应链安全(检测模型中是否植入后门)
-
技术细节:对抗样本检测通过分析模型中间层特征识别异常输入;模型指纹在训练时嵌入唯一标识,可验证模型来源
第五部分:军工级视觉系统的全流程设计
5.1 项目定位与预算分配
项目名称:面向高端制造与无人装备的智能视觉感知与决策平台
总投资:3亿元人民币
建设周期:24个月
目标:构建自主可控、高可靠、强实时、抗干扰的军工级视觉系统,覆盖精密制造、无人平台、战场感知等核心场景。系统需通过GJB 150系列环境适应性试验和GJB 151B电磁兼容性试验,MTBF≥5000小时,国产化率≥95%。
预算分配:
| 投入方向 | 预算占比 | 核心内容 | 金额(万元) |
|---|---|---|---|
| 自主可控硬件研发与采购 | 35% | 国产化高算力芯片、抗辐射加固、特种光学镜头、多模态传感器融合模组 | 10,500 |
| 高可靠性系统集成与制造 | 20% | 军工级结构设计、宽温域测试、电磁兼容性设计、冗余备份系统 | 6,000 |
| 算法研发与数据闭环平台 | 25% | 基础模型训练、小样本学习、多模态融合、仿真数据生成平台、自动标注工具链 | 7,500 |
| 实地测试与认证 | 10% | 第三方权威检测、GJB150/151B全项试验、外场实装测试(累计10万公里/1000小时) | 3,000 |
| 长期运维与升级 | 10% | 5年质保、模型持续迭代、现场技术支持、人员培训 | 3,000 |
| 合计 | 100% | 30,000 |
5.2 选型——国产化硬件详细清单
光学传感器(全系列国产替代)
| 传感器类型 | 推荐国产型号 | 关键参数 | 军工级加固措施 |
|---|---|---|---|
| 可见光相机 | 海康MV-CH250-90GM | 2500万像素,全局快门,帧率51fps,动态范围71dB | 壳体CNC加工,镀膜防盐雾,内部灌胶抗震,-40℃~+70℃工作 |
| 短波红外 | 立景光电SW640 | 640×512,InGaAs,0.9-1.7μm,帧率100Hz | 集成TEC温控,-40℃启动,抗强光 |
| 长波红外 | 高德红外GAVIN615 | 640×512,非制冷,NETD≤30mK,帧率50Hz | 无热化镜头,自动快门校正,抗盐雾 |
| 激光雷达 | 禾赛AT128 | 200m@10%反射率,点频153万点/秒,视场角120°×25.4° | 自研抗干扰算法,适应强光/雨雾,抗冲击10g |
| 高光谱 | 双利合谱GaiaField | 400-1000nm,光谱分辨率2.8nm,波段数256 | 推扫式成像,内置校正板,抗振动 |
| 毫米波雷达 | 行易道4D成像雷达 | 探测距离300m,角度分辨率1°,速度精度0.1m/s | 全天候,抗电子干扰,符合GJB 151B |
计算平台详细配置
| 组件 | 型号/规格 | 数量 | 冗余设计 |
|---|---|---|---|
| 主计算节点 | 华为昇腾Atlas 800 (4×昇腾910B) | 2套 | 双节点热备,心跳监测,故障自动切换 |
| 边缘计算节点 | 寒武纪MLU220-M.2 | 4个 | 部署于无人机/无人车,与中心节点协同 |
| 存储阵列 | 同有科技NetStor (100TB NVMe) | 1套 | RAID 6 + 热备盘,支持国密加密 |
| 交换网络 | 东土科技SICOM3000 (万兆工业交换机) | 2台 | 冗余环网,自愈时间<50ms |
| 操作系统 | 国产实时操作系统ReWorks/SylixOS | - | 任务调度延迟≤1ms,满足硬实时要求 |
| 电源模块 | 新雷能定制电源 | 2套 | 双冗余,支持热插拔,输入电压范围18-36V DC |
传感器融合与标定系统
-
高精度标定板:定制陶瓷标定板,热膨胀系数<1ppm/℃,含编码点,支持自动识别
-
时空同步模块:基于PTP/IEEE 1588协议的同步控制器,所有传感器同步精度<1μs
-
IMU:国产光纤惯导,零偏稳定性0.01°/h,与视觉系统紧耦合
5.3 打光——多光谱动态照明系统
照明单元配置:
| 照明单元 | 波长/类型 | 控制方式 | 功能 |
|---|---|---|---|
| 白光LED阵列 | 4000K-6500K可调 | PWM调光,8位精度 | 昼间补光,抑制频闪 |
| 红外LED阵列 | 850nm/940nm双波段 | 与相机曝光同步频闪 | 夜间隐蔽照明,抗干扰 |
| 紫外LED | 365nm | 持续照明 | 激发荧光物质,识别特种标记 |
| 偏振照明 | 线偏振/圆偏振可切换 | 电动偏振轮 | 消除金属/水面反光 |
| 结构光投影 | 红外散斑/条纹 | DLP微镜阵列 | 主动三维成像 |
| 激光照明 | 808nm,可调功率 | 连续/脉冲模式 | 远距离主动照明,抗环境光 |
控制策略:
-
环境光传感器实时监测,自动选择最优照明模式
-
支持“照明-成像”闭环优化:根据图像反馈(对比度、信噪比、直方图分布)自动调整光源强度/方向/波长
-
夜间模式:切换至红外照明,关闭白光,降低暴露风险
-
电磁兼容设计:所有光源驱动器内置EMI滤波器,符合GJB 151B
5.4 采图——实装采集与仿真生成
实装采集平台:
| 平台类型 | 搭载传感器 | 采集内容 | 数据量目标 | 采集地点 |
|---|---|---|---|---|
| 固定翼无人机 | 三光吊舱+高光谱 | 大面积战场侦察、伪装目标识别 | 500小时/年 | 沙漠/丛林/雪地/城市 |
| 旋翼无人机 | 可见光+激光雷达 | 低空精细建模、动态目标跟踪 | 300小时/年 | 各类地形,低空50-200m |
| 无人车 | 环视相机+4D毫米波 | 地面移动目标、道路环境 | 2000公里/年 | 越野/城市道路 |
| 固定站点 | 全景相机+热成像 | 关键区域持续监控 | 24×7全天候 | 军事基地周边 |
| 实弹测试 | 高速相机(1000fps) | 弹道轨迹、爆炸瞬间 | 50次测试 | 靶场 |
仿真数据生成:
-
场景建模:使用Unreal Engine 5 + 真实卫星地形数据,构建10km×10km级高保真战场环境,包含植被、建筑、道路、河流、动态目标(车辆、人员)。
-
传感器建模:开发物理级传感器模型,精确模拟:
-
相机:畸变(径向/切向)、噪声(高斯/泊松)、运动模糊(速度/方向)、曝光自适应、热噪声
-
激光雷达:点云密度随距离衰减、多路径效应、运动畸变、强度衰减
-
红外:目标温度分布、大气衰减、背景辐射、太阳反射
-
高光谱:光谱响应函数、大气吸收带
-
-
对抗样本生成:利用扩散模型自动生成:
-
伪装网覆盖的车辆(不同颜色、纹理)
-
红外诱饵干扰场景(诱饵弹轨迹、热辐射特性)
-
恶劣天气退化图像(暴雨、大雾、沙尘、雪)
-
电子干扰导致的图像噪声、条纹、丢帧
-
-
数据规模:≥100万组多模态同步数据,覆盖1000+种场景变化,标注信息自动生成(包括3D bounding box、分割掩码、目标轨迹、传感器参数)
5.5 标注——半自动标注流水线
| 层级 | 工具/方法 | 效率提升 | 质量保障 |
|---|---|---|---|
| 预标注 | SAM+DINOv2自动生成初版标注 | 减少80%人工工作量 | 置信度阈值>0.95自动采纳 |
| 人工修正 | 自研Web标注平台,多模态联动 | 单人日均标注2000框 | 三级审核(标注员-组长-专家) |
| 标注规范 | 《军事目标视觉标注规范v1.0》 | 统一标准,减少歧义 | 每批次随机抽检10%,合格率>99% |
| 主动学习 | 模型识别困难样本优先送人工 | 聚焦高价值样本 | 模型迭代速度提升3倍 |
| 交叉验证 | 多模态一致性校验 | 自动检测标注错误 | 不同模态间目标匹配准确率≥99% |
标注类别体系(部分):
| 大类 | 细分类别 | 属性 |
|---|---|---|
| 车辆 | 坦克(型号:T-72、M1A2等)、装甲车、步兵战车、运输车、导弹发射车 | 方向(0-360°)、速度、是否伪装、是否开火 |
| 人员 | 单兵、班组(2-5人)、携行装备(步枪/火箭筒) | 姿态(站立/卧倒/奔跑)、方向、是否隐蔽 |
| 装备 | 无人机(旋翼/固定翼)、雷达天线、伪装网、工事 | 型号、工作状态、尺寸 |
| 行为 | 举枪、投掷、驾驶、隐蔽、移动方向 | 开始时间、结束时间、置信度 |
5.6 训练——多任务模型与优化策略
模型架构:
text
输入层:多模态数据(可见光RGB 3通道 + 红外1通道 + 激光雷达BEV 4通道 + 高光谱16通道)
↓
数据预处理层:归一化、时间对齐、空间对齐
↓
共享骨干网络:Swin Transformer V2(多尺度特征提取,5层金字塔结构)
↓
多模态融合模块:Cross-Attention Transformer(6层,8头),自适应融合不同模态,输出融合特征
↓
多任务头(并行输出):
├─ 目标检测头:CenterNet风格,输出3D bounding box(位置、尺寸、朝向)
├─ 语义分割头:UPerNet,输出像素级分类(21类)
├─ 实例分割头:Mask2Former,输出实例级分割掩码
├─ 关键点检测头:姿态估计,输出人体/车辆关键点(17点/8点)
├─ 深度估计头:单目深度回归,输出深度图
└─ 行为识别头:时序Transformer(L=16帧),输出行为类别
↓
输出层:结构化感知结果(JSON格式),包含目标ID、类别、位置、姿态、轨迹、置信度
训练策略:
| 参数 | 设置 | 说明 |
|---|---|---|
| 分布式训练 | 8张昇腾910B,数据并行 | 总批量大小64,梯度累积 |
| 优化器 | AdamW | 学习率1e-4,权重衰减0.05 |
| 学习率调度 | Cosine annealing | T_max=100,最小学习率1e-6 |
| 训练轮数 | 200 epochs | 早停策略,验证集连续10轮不提升则停止 |
| 数据增强 | 随机裁剪、旋转(±30°)、颜色抖动、模糊、噪声、CutMix、MixUp | 增强鲁棒性,减少过拟合 |
| 损失函数权重 | 检测:分割:关键点:深度:行为 = 1:0.5:0.3:0.2:0.3 | 多任务联合优化 |
| 评估指标 | mAP@0.5:0.95(检测)、mIoU(分割)、PCK(关键点)、RMSE(深度)、Accuracy(行为) | 多维度评估 |
小样本学习:
-
针对新出现的目标类型(如新型无人机、伪装车辆),采用元学习(MAML)或基于度量的方法(原型网络)
-
仅需数十张标注样本即可快速适应,新场景开发周期从数月缩短至数周
5.7 部署——实时性、确定性、安全性
模型轻量化技术:
| 技术 | 方法 | 效果 |
|---|---|---|
| 量化 | INT8量化(TensorRT)+ 校准集 | 模型体积减少75%,推理速度提升3倍,精度损失<0.5% |
| 剪枝 | 结构化剪枝(移除不重要的通道) | FLOPs减少40%,精度损失<1% |
| 蒸馏 | 教师模型(大模型)→学生模型(轻量级) | 学生模型达到教师95%精度,速度提升5倍 |
| 算子融合 | 合并Conv+BN+ReLU为单算子 | 减少内存访问,延迟降低20% |
部署架构:
性能指标:
-
端到端延迟:≤25ms(从曝光到输出决策)
-
吞吐量:≥40帧/秒(单节点)
-
故障切换时间:≤10ms(双节点热备)
-
内存占用:≤8GB(预留20%余量)
安全措施:
| 安全层级 | 措施 | 依据标准 |
|---|---|---|
| 物理安全 | 机箱防拆设计、防篡改标签、电磁屏蔽 | GJB 151B |
| 系统安全 | 国产实时操作系统、安全启动、访问控制 | GJB 7691 |
| 模型安全 | AES-256加密、运行时解密到安全内存 | GM/T 0002 |
| 数据安全 | 混沌压缩感知加密、国密算法SM4 | GM/T 0004 |
| 通信安全 | 光纤隔离、跳频通信、数据签名 | GJB 5612 |
5.8 调试与验收——全生命周期保障
环境适应性测试(GJB 150系列):
| 测试项目 | 标准 | 测试条件 | 判定标准 |
|---|---|---|---|
| 低温工作 | GJB 150.4A | -40℃,保持4小时,通电测试 | 功能正常,无性能下降 |
| 高温工作 | GJB 150.3A | +70℃,保持4小时,通电测试 | 功能正常,无热关机 |
| 振动 | GJB 150.16A | 随机振动,20-2000Hz,6小时/轴向 | 结构无损坏,图像无抖动 |
| 冲击 | GJB 150.18A | 半正弦波,40g,11ms | 无结构损坏,重启后功能恢复 |
| 盐雾 | GJB 150.11A | 5% NaCl,35℃,48小时 | 无明显腐蚀,电气性能正常 |
| 霉菌 | GJB 150.10A | 28天培养 | 不长霉或轻微生长(等级≤1) |
| 湿热 | GJB 150.9A | 40℃,95% RH,48小时 | 无凝露,绝缘电阻≥100MΩ |
| 低气压 | GJB 150.2A | 海拔5000m,保持1小时 | 功能正常,无放电现象 |
电磁兼容性测试(GJB 151B):
| 测试项 | 限值 | 测试方法 |
|---|---|---|
| CE102(电源线传导发射) | ≤60dBμV(10kHz-10MHz) | 10μH LISN,频谱分析仪 |
| RE102(电场辐射发射) | ≤30dBμV/m(30MHz-1GHz) | 暗室,天线测量 |
| CS114(电缆束注入传导敏感度) | 10V(10kHz-200MHz) | 注入探头,监测功能异常 |
| RS103(电场辐射敏感度) | 50V/m(30MHz-1GHz) | 功放+天线,监测误码率 |
外场实装测试:
| 测试场景 | 地点 | 持续时间 | 测试内容 |
|---|---|---|---|
| 沙漠环境 | 某试验场 | 30天 | 沙尘、高温、强光下目标识别稳定性 |
| 丛林环境 | 某训练基地 | 30天 | 遮挡、低光照、伪装目标识别 |
| 雪地环境 | 某寒区试验场 | 30天 | 强反射、低温、能见度低 |
| 城市环境 | 模拟城市街区 | 30天 | 复杂背景、动态干扰、电子对抗 |
| 综合拉练 | 野外综合演练 | 连续100小时 | 全系统协同工作,可靠性验证 |
验收指标:
| 指标 | 要求 | 测试方法 |
|---|---|---|
| 目标检测准确率 | 典型目标≥98%,小目标(32×32像素)≥90% | 现场实测与标注数据比对 |
| 漏检率 | ≤0.5% | 统计未被识别的真实目标 |
| 虚警率 | ≤0.1次/小时 | 统计错误报警次数 |
| 端到端延迟 | ≤30ms(从曝光到输出决策) | 示波器测量信号链路 |
| 定位精度 | ≤0.05mm(近距离),≤1m(远距离) | 激光跟踪仪比对 |
| 环境适应性 | 通过GJB 150系列试验 | 第三方检测机构认证 |
| 电磁兼容性 | 符合GJB 151B | 暗室测试 |
| 连续工作时间 | MTBF≥5000小时 | 加速寿命试验 |
| 国产化率 | ≥95%(核心器件、操作系统、算法框架) | 元器件清单审核 |
第六部分:混沌理论视角下的工业视觉系统
6.1 混沌理论的核心概念与工业映射
混沌理论是研究确定性非线性系统中出现的貌似随机的、不可预测的行为的理论体系。其核心特征与工业视觉系统的映射关系如下:
(1)初值敏感性
-
定义:对于任意两个初始值不同的轨道,其距离在演化过程中会被指数放大。
-
数学表达:Lyapunov指数λ>0,相邻轨迹分离速度∝e^{λt}
-
工业映射:微小的光照变化、工件位置偏移,可能导致检测结果的剧烈波动。例如,光源强度下降1%,灰度均值下降10个灰度级,原本在阈值边缘的微弱缺陷被“吞没”,漏检率从0.1%飙升到5%。
(2)长期不可预测性
-
定义:系统的长期行为无法通过初值精确预测。
-
工业映射:视觉系统在长期运行中,光源衰减、镜头污染、机械磨损、来料批次变化等因素叠加,模型精度难以预知何时会降到阈值以下。
(3)内在随机性
-
定义:系统内部存在确定性规则,但表现出类似随机过程的复杂性。
-
工业映射:缺陷形态无限多样(划痕有长有短、有深有浅、有直有弯),无法用有限规则穷举,呈现出“确定性随机性”。
(4)奇异吸引子
-
定义:混沌系统在相空间中收敛到的复杂几何结构,具有分形维度。
-
工业映射:视觉系统的状态空间(光源强度、工件位置、检测精度等)可能收敛到低维流形,但在这个流形上,系统行为复杂而不可预测。
6.2 从有序到无序再到新的有序:技术演进的辩证
工业视觉系统的技术演进,遵循着混沌理论中的“有序-无序-新的有序”循环:
第一阶段(有序):传统视觉算法
-
特征:规则驱动,行为确定、可预测
-
数学本质:确定性线性/非线性系统,Lyapunov指数≤0
-
类比:周期轨道
-
局限:适应能力有限,无法处理规则之外的任何情况
第二阶段(无序):深度学习模型
-
特征:数据驱动,从海量数据中涌现认知能力,但行为不可解释
-
数学本质:高维非线性系统,存在混沌行为
-
类比:混沌吸引子
-
局限:决策过程“黑箱”,可解释性差,存在“幻觉”风险
第三阶段(新的有序):混合模型+混沌优化
-
特征:在保留深度学习泛化能力的同时,通过混合架构增强可解释性,通过混沌优化提升全局寻优能力
-
数学本质:混沌控制——在混沌系统中提取有序结构
-
价值:既强大又可控,既智能又可解释
6.3 混沌优化算法在视觉系统中的工程应用
混沌优化算法的数学基础:
以一维Logistic映射为例:
xn+1=μxn(1−xn),μ∈[0,4],x∈[0,1]xn+1=μxn(1−xn),μ∈[0,4],x∈[0,1]
当控制参数$\mu \in (3.6, 4]$时,系统进入混沌状态,表现出:
-
遍历性:轨道可以在[0,1]区间内不重复地遍历所有状态
-
初值敏感性:微小差异导致轨道迅速分离
-
自相似性:具有分形结构
这些性质使得混沌序列可以用于搜索最优解,避免传统优化算法陷入局部最优。
应用一:光源参数优化
-
问题:传统打光依赖人工试凑,难以找到全局最优
-
方法:利用混沌序列遍历照明参数空间(强度、角度、波长),根据成像质量反馈动态调整
-
算法:
-
初始化混沌序列$x_0$,映射到照明参数空间
-
对每个参数组合,采集图像,计算成像质量$J$(对比度、信噪比)
-
更新最优参数,根据反馈调整混沌搜索方向
-
重复直到收敛
-
-
效果:30ms内收敛至最优参数,较固定打光提升缺陷检出率15%
应用二:模型超参数调优
-
问题:深度学习模型超参数多,网格搜索效率低
-
方法:混沌粒子群优化(CPSO),利用混沌序列初始化粒子群,避免陷入局部最优
-
算法:
-
利用Logistic映射生成混沌序列,初始化粒子群位置和速度
-
计算每个粒子的适应度(验证集精度)
-
更新个体最优和全局最优
-
对部分粒子施加混沌扰动,增强全局搜索能力
-
-
效果:在磁瓦表面缺陷检测中,CPSO优化的LSSVM模型识别率显著优于传统方法
应用三:图像分割阈值优化
-
问题:传统Otsu方法在图像对比度低时效果差
-
方法:混沌搜索算法自动搜索最优分割阈值
-
算法:
-
生成混沌序列,映射到灰度阈值空间
-
计算每个阈值下的类间方差(或自定义代价函数)
-
选择最优阈值
-
-
效果:对微弱缺陷的敏感性显著提升,分割精度提高20%
应用四:数据加密
-
问题:军工数据需要高强度加密,同时考虑传输带宽
-
方法:混沌压缩感知,利用混沌映射生成测量矩阵,同时实现压缩与加密
-
算法:
-
利用Logistic映射生成混沌测量矩阵$\Phi$
-
对图像信号$x$进行压缩测量:$y = \Phi x$
-
传输加密后的压缩数据$y$
-
接收端利用混沌序列重构测量矩阵,通过优化算法恢复$x$
-
-
效果:密钥空间达$(2^{64})^{2048}$量级,重构数据相似度0.947,计算效率较传统加密提升5倍
6.4 混沌控制与自适应系统
混沌控制的核心思想:通过微小的扰动,将混沌系统的行为引导到期望的轨道上。
OGY方法(Ott-Grebogi-Yorke):
-
识别混沌系统中的不稳定周期轨道
-
当系统轨迹接近目标轨道时,施加微小扰动将其锁定到轨道上
-
扰动幅度小,不破坏系统原有动力学特性
在工业视觉中的应用:
-
建立视觉系统的“状态空间模型”:成像质量$Q$、检测精度$A$、系统延迟$L$作为状态变量
-
光源参数$S$、算法参数$P$作为控制变量
-
当系统检测到状态偏离期望轨道时(例如,缺陷检出率下降),混沌控制器自动调整控制变量,将系统拉回期望状态
自适应控制架构: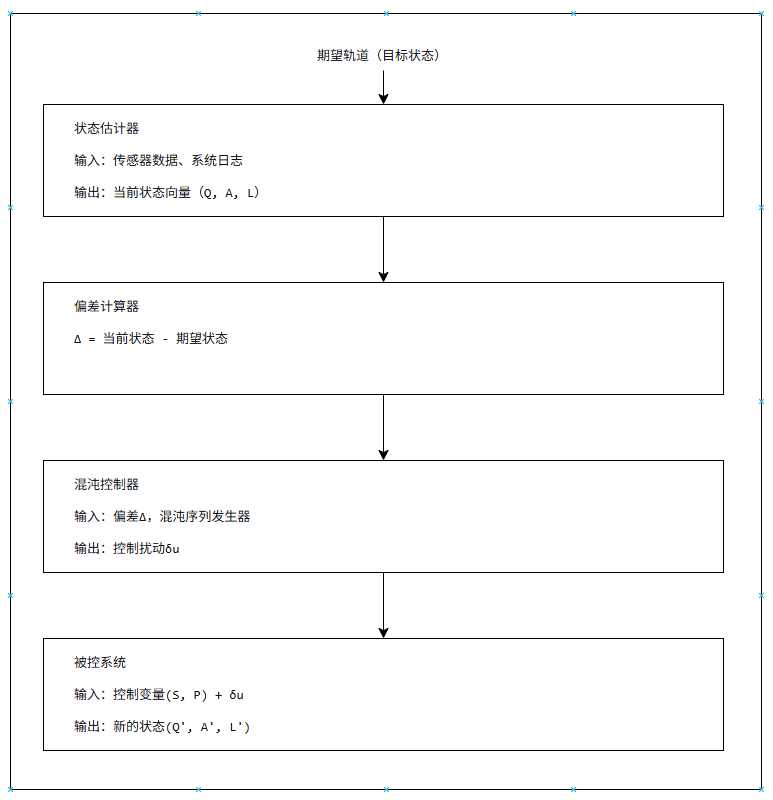
工程价值:让视觉系统从“静态的、预设的”走向“动态的、自适应的”,具备在环境变化时自动调整的能力。
6.5 前沿展望:从感知智能到认知智能
基础模型+微调范式
-
现状:用一个通用视觉大模型(如SAM、DINOv2)覆盖多种识别任务
-
展望:新场景仅需数十张样本微调,开发周期从数月缩短至数天
-
混沌视角:基础模型在大规模数据上训练,收敛到“混沌吸引子”,具有丰富的知识表示;微调过程相当于在吸引子附近施加扰动,引导到目标轨道
世界模型
-
现状:模拟物理世界的演化规律,预测下一帧
-
展望:可用于仿真训练、缺陷演化预测、虚拟环境生成,实现“预见”智能
-
混沌视角:世界模型本质上是对物理系统动力学方程的近似,可预测系统的混沌行为
多模态融合
-
现状:融合视觉、力觉、听觉、文本知识
-
展望:实现综合认知,可处理“看到+理解+推理”的复杂任务
-
混沌视角:不同模态的信息构成高维相空间,多模态融合相当于在相空间中寻找低维流形,提取核心特征
混沌理论深化
-
设备健康预测:基于混沌时间序列分析(Lyapunov指数、关联维度),预测视觉系统性能退化趋势,实现预测性维护
-
缺陷演化预测:基于混沌动力学模型(如Logistic映射、Lorenz系统),预测微小缺陷的扩展路径,实现早期预警
-
生产系统优化:将视觉检测结果作为混沌系统的反馈输入,动态调整生产参数,实现闭环优化
第七部分:结语——从看见到看懂再到预见
工业视觉的演进,是一场关于“看”的认知革命。
第一代系统“看见”——捕捉图像,提取特征,与模板匹配。这是“眼睛”的功能。它基于确定性规则,行为可预测,但适应能力有限。如同混沌理论中的“周期轨道”,稳定但僵化。
第二代系统“看懂”——理解图像,识别缺陷,判断好坏。这是“大脑”的介入。它从海量数据中涌现认知能力,如同混沌系统,强大但不可预测、不可解释。
第三代系统,将学会“预见”——预测缺陷演化,预判设备状态,预防质量事故。这是“智慧”的觉醒。它融合传统与深度、识别与生成、感知与决策,如同混沌控制,在混沌中提取秩序,既强大又可控。
从有序到无序再到新的有序,从规则驱动到数据驱动再到混沌控制,工业视觉正沿着一条螺旋上升的路径不断进化。这条路充满了挑战——成像的困境、数据的稀缺、算法的妥协、部署的复杂、混沌的干扰,但每一次克服挑战,都意味着系统向更高层次的智能迈进一步。
对于从业者而言,理解混沌理论,拥抱复杂性,设计融合传统与深度、确定性与概率、可解释与泛化的混合系统,将是未来十年工业视觉领域最核心的能力。具体而言:
-
在架构层面,采用“传统算法粗筛+深度学习精判”的混合模式,兼顾速度与精度
-
在数据层面,利用生成式AI(扩散模型)合成虚拟缺陷样本,解决数据稀缺问题
-
在算法层面,引入混沌优化算法进行全局寻优,避免陷入局部最优
-
在系统层面,构建自适应闭环,实现“照明-成像-检测-反馈”的动态优化
-
在安全层面,采用混沌加密保障数据安全,对抗样本防御提升系统鲁棒性
而对于国家战略而言,自主可控、高可靠、强实时的军工级视觉系统,不仅是保障装备质量与战场优势的关键,更是智能制造时代大国竞争力的重要基石。从半导体晶圆的纳米级缺陷检测,到航天器舱段的毫米级对接引导,再到战场无人机的全天候目标识别,工业视觉正在重塑国防工业的每一个环节。
混沌理论告诉我们:看似无序的复杂系统,内部可能隐藏着确定性的规律。找到这些规律,就能在混沌中提取秩序。
这或许就是工业视觉的终极使命——在混沌的世界里,建立永恒的秩序。
参考文献
[1] Wu, C. H. (2011). Evolutionary computation in machine vision for manufacturing and logistics industry. Ph.D. Thesis, The Hong Kong Polytechnic University.
[2] 基于混沌特性的磁瓦表面缺陷视觉提取方法研究. 万方数据, 2014.
[3] 工业互联网的概念、体系架构及关键技术. 物联网学报, 2022.
[4] 工业视觉缺陷检测算法演进:从“手工匠人”到“自主专家”的工程实践. 视觉系统设计, 2025.
[5] Liu, X., Hou, B., & Zhao, Q. (2019). Monitoring data encryption method for howitzer shell transfer arm using chaos and compressive sensing. Journal of Algorithms & Computational Technology, 2019.
[6] 基于混沌理论的检测系统应用研究综述. 甘肃高师学报, 2013(02).
[7] Zhao, R. (2024). Research on the application of deep learning-based machine vision in automated inspection. Applied Mathematics and Nonlinear Sciences.
[8] 刘丁, 吴雄君, 杨延西, 辛菁. (2008). 基于改进变尺度混沌优化的自标定位置视觉伺服. 自动化学报, 34(6): 623-631.
[9] 齐昕雨. (2021). 基于分布式视频的电磁敏感性实时监测技术研究. 南京理工大学硕士学位论文.
[10] Kirillov, A., et al. (2023). Segment Anything. arXiv:2304.02643.
[11] Brown, T., et al. (2020). Language Models are Few-Shot Learners. NeurIPS.
[12] Radford, A., et al. (2021). Learning Transferable Visual Models From Natural Language Supervision. ICML.
[13] Dosovitskiy, A., et al. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR.
[14] Carion, N., et al. (2020). End-to-End Object Detection with Transformers. ECCV.
[15] Rombach, R., et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR.
[16] Mildenhall, B., et al. (2020). NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. ECCV.
[17] Kerbl, B., et al. (2023). 3D Gaussian Splatting for Real-Time Radiance Field Rendering. SIGGRAPH.
[18] 海康机器人. 工业相机产品手册. 2025.
[19] 华为. 昇腾AI处理器技术白皮书. 2024.
[20] NVIDIA. TensorRT Developer Guide. 2025.
[21] 中科飞测. 晶圆缺陷检测系统技术规格书. 2024.
[22] 德适生物. iMedImage™医学影像大模型白皮书. 2025.
[23] 深睿医疗. Deepwise MetAI X产品技术白皮书. 2024.
[24] 哈医大一院. CorVIS冠状动脉全息可视化系统技术报告. 2025.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)