动手学深度学习笔记:数值稳定性
一、前言
在刚开始学习深度学习时,很多人都会遇到这样几个问题:
-
模型刚训练几轮,
loss直接变成nan -
学习率明明不大,但参数更新后结果越来越离谱
-
网络层数一深,梯度不是特别大,就是特别小
-
同样的代码,别人能跑,我一跑就崩
一开始我以为这是代码写错了,后来学习了李沐老师《动手学深度学习》中关于**数值稳定性(Numerical Stability)**的内容后,才明白:
很多深度学习训练问题,不一定是模型设计错了,而是数值计算过程本身不稳定。
这篇博客就来系统讲清楚:
-
什么是数值稳定性
-
为什么深度学习中会出现数值问题
-
梯度爆炸与梯度消失是怎么来的
-
如何从初始化、激活函数、归一化等角度解决问题
-
训练时出现
nan、inf应该怎么排查
这部分内容非常重要,它直接关系到后面神经网络能不能稳定训练。
二、什么是数值稳定性
所谓数值稳定性,本质上是指:
在计算过程中,数值不会因为层层运算而变得过大、过小,或者产生严重误差,从而影响最终结果。
在深度学习里,模型训练依赖大量矩阵乘法、加法、指数运算和反向传播。如果某一步计算结果过大或者过小,就可能出现:
-
上溢(overflow)
-
下溢(underflow)
-
梯度爆炸(gradient explosion)
-
梯度消失(gradient vanishing)
-
nan或inf
这会导致模型无法继续训练,或者训练效果非常差。
三、为什么深度学习特别容易出现数值问题
深度学习模型通常具有以下特点:
-
层数多
-
参数多
-
计算链条长
-
反向传播要经过很多层
-
经常涉及乘法连乘
而连乘恰恰是数值不稳定的主要来源。

这说明:
-
连乘很多个大于 1 的数,容易爆炸
-
连乘很多个小于 1 的数,容易消失
而神经网络的前向传播和反向传播,本质上都存在类似的连乘结构。
四、从一个简单例子理解数值不稳定
1. 前向传播中的问题

2. 反向传播中的问题
反向传播更容易出问题。
根据链式法则,梯度需要不断相乘:
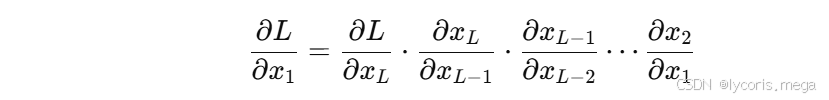
如果这些偏导数:
-
大多大于 1,梯度越来越大,发生梯度爆炸
-
大多小于 1,梯度越来越小,发生梯度消失
这也是深层网络难训练的重要原因。
五、梯度爆炸与梯度消失
1. 梯度爆炸
梯度爆炸指的是:
在反向传播过程中,梯度值越来越大,导致参数更新幅度过大,训练发散。
常见现象:
-
loss 突然变得非常大
-
参数值异常大
-
出现
inf或nan -
模型根本收敛不了
例如,若每层梯度都乘以 2,经过 20 层后:
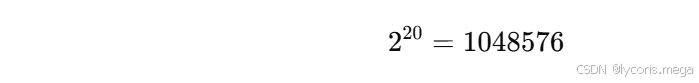
这已经非常大了。
2. 梯度消失
梯度消失指的是:
在反向传播过程中,梯度越来越接近 0,导致前面层几乎无法更新。
常见现象:
-
网络训练很慢
-
深层参数几乎不变
-
loss 下降特别困难
-
模型效果上不去
例如,若每层梯度都乘以 0.5,经过 20 层后:
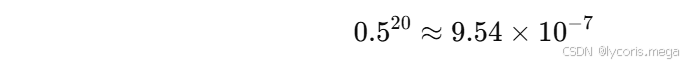
这个梯度已经非常小了,前面层基本学不到东西。
六、激活函数为什么会影响数值稳定性
激活函数不仅决定网络的非线性表达能力,还会影响梯度传播。
1. Sigmoid 的问题

如果层数一多,梯度会迅速变得极小,因此 Sigmoid 很容易导致梯度消失。
另外,Sigmoid 在输入绝对值很大时,会进入饱和区:
-
输入很大时,输出接近 1
-
输入很小时,输出接近 0
此时导数接近 0,训练更加困难。
2. Tanh 的问题

3. ReLU 的优势

七、参数初始化为什么重要
1. 为什么不能随便初始化
如果参数初始化过大,那么前向传播时输出会越来越大,容易爆炸。
如果参数初始化过小,那么输出会越来越小,梯度也容易消失。
所以,初始化的目标并不是“随机就行”,而是:
让每一层的输出方差和梯度方差尽量保持在合理范围内。
2. Xavier 初始化

3. He 初始化
He 初始化更适合 ReLU。
因为 ReLU 会把一部分输入变成 0,所以需要稍微更大的初始化方差来补偿。
常见思想是:
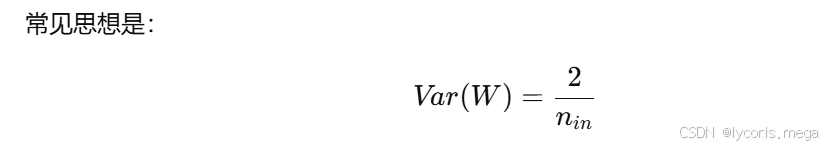
He 初始化在深层 ReLU 网络中非常常见。
八、为什么深层网络更难训练
随着层数增加,网络会面临几个问题:
1. 连乘效应更严重
无论是前向传播还是反向传播,只要层数加深,连乘次数就增加。
这会让数值更容易爆炸或消失。
2. 梯度传递路径更长
越靠前的层,梯度需要经过更多层才能传回来。
一旦中间某些层的梯度很小,前面层几乎就收不到有效更新信号。
3. 激活值分布不断漂移
每一层输出的分布可能都不同,导致后续层训练困难。
这也是后来 Batch Normalization 被提出的重要原因。
九、如何解决数值稳定性问题
这一部分是重点,也是训练神经网络时最实用的内容。
1. 合理的参数初始化
不要用过大或过小的随机数初始化参数。
一般建议:
-
Sigmoid / Tanh:Xavier 初始化
-
ReLU:He 初始化
在 PyTorch 中常见写法:
import torch
from torch import nn
linear = nn.Linear(128, 64)
nn.init.xavier_uniform_(linear.weight) # Xavier 初始化
nn.init.zeros_(linear.bias)
或者:
nn.init.kaiming_uniform_(linear.weight, nonlinearity='relu') # He 初始化
2. 使用合适的激活函数
通常优先考虑:
-
ReLU
-
Leaky ReLU
-
GELU
尽量少在深层网络中大量使用普通 Sigmoid,除非你明确知道为什么要用它。
3. 数据归一化
输入数据尺度差异过大,也会导致训练不稳定。
例如图像数据通常会做:
-
除以 255
-
标准化到均值 0、方差 1 附近
如果输入数据本身就特别大,那么模型前几层的输出也容易特别大。
4. 批量归一化 Batch Normalization
BatchNorm 的作用可以简单理解为:
把每一层的中间输出拉回到较稳定的分布范围内。
好处包括:
-
加快收敛
-
缓解梯度消失和梯度爆炸
-
允许使用更大学习率
-
提高训练稳定性
PyTorch 写法:
net = nn.Sequential(
nn.Linear(784, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Linear(256, 10)
)
5. 梯度裁剪 Gradient Clipping
当梯度过大时,可以对梯度进行裁剪,避免更新过猛。
这在 RNN、LSTM 等序列模型中尤其常见。
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
它的意思是:
如果梯度范数超过 1.0,就按比例缩小。
6. 控制学习率
学习率过大,也会让参数更新一步跨太远,导致 loss 震荡甚至爆炸。
常见建议:
-
模型不稳定时,先尝试减小学习率
-
配合学习率调度器逐步下降
-
不要一上来就设置很大的学习率
7. 使用残差连接
残差连接是 ResNet 成功的关键之一。
核心思想:
[
y = F(x) + x
]
它可以让梯度更顺畅地从后面层传回前面层,从而缓解深层网络中的梯度消失问题。
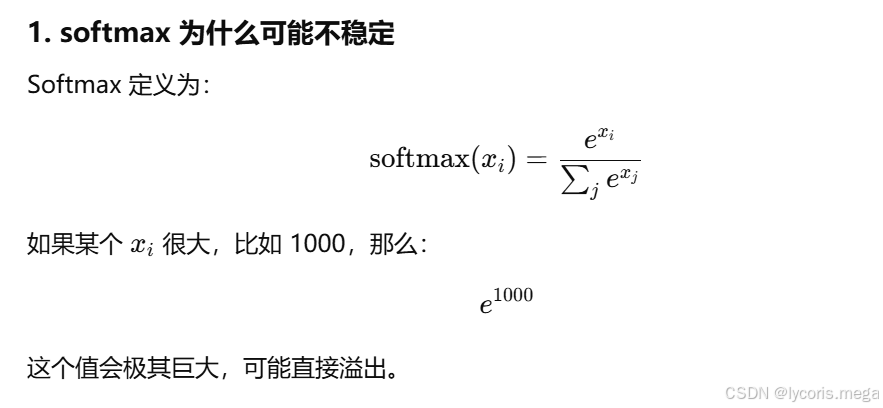
十、softmax 和交叉熵中的数值稳定性
这一块非常经典,也特别容易考。

3. 为什么框架里常把 softmax 和交叉熵合在一起
因为:
-
单独算 softmax 可能不稳定
-
再手动取对数还可能产生额外误差
所以很多框架提供了更稳定的封装版本,比如 PyTorch 的:
loss_fn = nn.CrossEntropyLoss()
它内部已经把这些数值稳定性问题处理好了。
因此平时训练分类模型时,不要自己先做 softmax 再送入 CrossEntropyLoss。
十一、训练中出现 nan 怎么办
这是最常见的实际问题之一。
如果训练时出现了 nan,可以从下面几个方向排查。
1. 学习率是不是太大
先把学习率调小,很多问题都会立刻缓解。
2. 输入数据有没有异常值
检查:
-
是否有缺失值
-
是否有极大值
-
是否归一化
-
标签是否正确
3. loss 函数使用方式是否正确
例如:
-
CrossEntropyLoss前不要自己做 softmax -
BCEWithLogitsLoss前不要自己做 sigmoid
因为这些损失函数已经集成了更稳定的实现。
4. 初始化是否不合理
如果初始化过大,第一轮前向传播就可能把数值放大到失控。
5. 是否需要梯度裁剪
特别是 RNN、Transformer、深层网络中,梯度裁剪很有必要。
6. 打印张量范围
可以在训练时打印:
print(x.min(), x.max())
print(loss.item())
看看是不是某一层输出已经非常夸张。
十二、一个直观总结:数值稳定性到底在解决什么
其实可以把数值稳定性理解成一句话:
让网络中的信号和梯度,在层与层之间传播时,既不要无限放大,也不要迅速消失。
它解决的不是“模型有没有想法”,而是“模型能不能活着训练完”。
如果没有数值稳定性保障,那么再好的网络结构,也可能训练不起来。
十三、我对这一节的理解
学习这一节之后,我最大的感受是:
以前总觉得深度学习难,是因为模型结构复杂;
后来才发现,很多问题其实出在底层数值计算机制上。
比如:
-
为什么激活函数不能乱选
-
为什么初始化方法不是随便写个 random
-
为什么 BatchNorm、残差连接这么重要
-
为什么 loss 会变成
nan
这些问题都和数值稳定性高度相关。
也就是说,数值稳定性虽然听起来像“理论细节”,但它实际上决定了:
-
模型能不能训
-
训练快不快
-
深层网络能不能收敛
-
最终效果能不能出来
所以这部分内容绝对不是可有可无,而是深度学习的基础。
十四、代码小实验:观察梯度消失与爆炸
下面给一个简单小实验,用来体会连乘导致的数值问题。
import torch
# 模拟多层连乘
x = torch.tensor(1.0)
# 情况1:不断放大
for i in range(20):
x = x * 1.5
print("连续乘1.5,结果为:", x.item())
# 情况2:不断缩小
x = torch.tensor(1.0)
for i in range(20):
x = x * 0.5
print("连续乘0.5,结果为:", x.item())
运行后你会发现:
-
连续乘 1.5,值会越来越大
-
连续乘 0.5,值会越来越接近 0
这和深度网络中的前向传播、反向传播本质上是类似的。
十五、结语
数值稳定性是学习深度学习时绕不开的一关。
它不像卷积、注意力机制那样“看起来很酷”,但它决定了一个模型能否正常训练。
在实际学习和写代码时,我觉得应该重点记住下面几点:
-
深层网络容易出现梯度爆炸和梯度消失
-
激活函数会影响梯度传播
-
参数初始化非常关键
-
BatchNorm、梯度裁剪、残差连接都在帮助稳定训练
-
出现
nan时,先查学习率、初始化、数据和 loss 使用方式
只有把这些基础问题弄明白,后面学 CNN、RNN、Transformer 时才不会总被训练问题卡住。
十六、重点速记版
1. 什么是数值稳定性
训练过程中,数值不能过大、过小,也不能出现严重误差。
2. 为什么会不稳定
神经网络中存在大量连乘,层数一深就容易爆炸或消失。
3. 两大典型问题
-
梯度爆炸:梯度过大,训练发散
-
梯度消失:梯度过小,前层学不到东西
4. 常见解决方法
-
合理初始化(Xavier、He)
-
选择合适激活函数(ReLU)
-
数据归一化
-
BatchNorm
-
梯度裁剪
-
控制学习率
-
残差连接
如果你和我一样,刚开始学深度学习时总遇到 loss=nan、模型不收敛、训练发散的问题,那么一定要认真理解“数值稳定性”这一节。
它不仅仅是理论内容,更是后续写好深度学习代码的重要基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)