Matlab实现LSTM-Adaboost-ABKDE的集成学习长短期记忆神经网络自适应带宽核密度估计多变量回归区间预测研究
💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文内容如下:🎁🎁🎁
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥第一部分——内容介绍
LSTM-Adaboost-ABKDE 集成学习模型在多变量回归区间预测中的应用研究
摘要
针对传统多变量回归预测方法存在点预测精度不足、无法有效量化预测不确定性、核密度估计带宽固定导致概率预测效果差等问题,提出一种结合长短期记忆神经网络(LSTM)、自适应提升算法(Adaboost)与自适应带宽核密度估计(ABKDE)的集成学习多变量回归区间预测模型(LSTM-Adaboost-ABKDE)。以 Matlab R2021a 为开发环境,构建多变量单输出的预测框架,实现点预测、概率预测与核密度估计曲线可视化,并计算 R²、MAE、RMSE、MAPE 等点预测评价指标,以及区间覆盖率(PICP)、区间平均宽度百分比(PINAW)等区间预测评价指标,同时提供 90%、95%、99% 等多档置信区间。研究表明,该模型通过 Adaboost 集成学习策略提升 LSTM 点预测精度,改进固定带宽核密度估计为自适应带宽模式,有效优化概率预测与区间预测效果;模型采用参数化编程设计,注释清晰,仅需替换 Excel 数据即可一键运行,具备良好的易用性与扩展性,可为多变量回归预测领域的不确定性量化分析提供新方法。
关键词
集成学习;长短期记忆神经网络;Adaboost;自适应带宽核密度估计;多变量回归;区间预测;Matlab 实现
一、引言
1.1 研究背景与意义
多变量回归预测广泛应用于经济金融、能源电力、环境监测等领域,传统预测方法多聚焦于点预测,仅能给出单一预测值,无法反映预测结果的不确定性,而实际决策过程中,预测区间的准确性与可靠性直接影响决策科学性。长短期记忆神经网络(LSTM)作为循环神经网络(RNN)的改进形式,能够有效捕捉时间序列数据的长依赖关系,在多变量回归预测中表现出优异的点预测能力,但单一 LSTM 模型易受数据噪声、模型过拟合等因素影响,预测稳定性不足。
Adaboost 作为经典的集成学习算法,通过迭代训练弱分类器并赋予不同权重,构建强预测模型,可有效提升单一模型的预测精度与鲁棒性。核密度估计(KDE)是量化预测不确定性的常用方法,能够通过样本数据估计预测误差的概率分布,进而构建预测区间,但传统固定带宽 KDE 存在带宽选择主观性强、对数据分布适应性差的问题,易导致区间覆盖率与宽度失衡。为此,将 LSTM 与 Adaboost 集成,结合改进的自适应带宽核密度估计(ABKDE),构建 LSTM-Adaboost-ABKDE 多变量回归区间预测模型,既保留 LSTM 对多变量时序特征的捕捉能力,又通过 Adaboost 提升点预测精度,再利用 ABKDE 精准量化预测不确定性,具有重要的理论与应用价值。
1.2 研究现状
国内外学者已开展多变量回归预测与区间预测相关研究:在神经网络预测方面,LSTM 被广泛应用于多变量时序预测,但单一 LSTM 模型泛化能力有限,部分研究引入集成学习策略优化,如将 LSTM 与 Bagging、Boosting 结合,提升点预测精度;在区间预测方面,核密度估计、分位数回归、贝叶斯方法是主流技术,其中核密度估计因无需预设分布假设,适用性更强,但固定带宽的选择难题始终制约其效果,现有改进方法多聚焦于带宽自适应优化,但较少与集成神经网络结合应用于多变量回归区间预测。
总体而言,现有研究仍存在不足:一是集成学习与 LSTM 的结合多聚焦于点预测,未充分考虑预测不确定性的量化;二是核密度估计的带宽改进多针对单一变量,适配多变量回归预测误差分布的研究较少;三是现有 Matlab 实现的预测模型多存在代码复用性差、参数调整复杂、评价体系不完整等问题,难以满足新手用户的使用需求。
1.3 研究内容与技术路线
1.3.1 研究内容
本研究围绕 LSTM-Adaboost-ABKDE 集成模型的构建与 Matlab 实现展开,核心内容包括:(1)LSTM-Adaboost 集成点预测模型构建:以多变量时序数据为输入,构建基础 LSTM 弱预测器,通过 Adaboost 迭代训练,根据预测误差调整样本权重与模型权重,生成强集成点预测模型;(2)自适应带宽核密度估计(ABKDE)改进:针对固定带宽 KDE 的缺陷,设计基于样本局部密度与距离的自适应带宽计算方法,提升预测误差分布估计的准确性;(3)多变量回归区间预测实现:基于 LSTM-Adaboost 的点预测结果与预测误差,利用 ABKDE 估计误差概率分布,构建多档置信区间(90%、95%、99%),实现点预测 + 概率预测 + 核密度估计曲线的一体化输出;(4)Matlab 全流程实现:开发参数化编程框架,支持 Excel 数据直接替换,设计一键运行的 main 函数,输出完整的评价指标(R²、MAE、RMSE、MAPE、PICP、PINAW)与可视化结果(核密度曲线、预测区间曲线);(5)模型验证与分析:通过实际多变量数据集测试模型性能,对比单一 LSTM、LSTM-KDE 等模型,验证 LSTM-Adaboost-ABKDE 的优越性。
1.3.2 技术路线
本研究技术路线遵循 “数据预处理→模型构建→区间预测→评价验证→Matlab 实现” 的逻辑:
- 数据预处理:对多变量输入数据进行归一化、划分训练集 / 测试集、构建多步输入输出样本;
- 集成点预测:训练 LSTM 弱分类器,通过 Adaboost 迭代优化,生成集成点预测结果;
- 误差分布估计:计算集成模型的预测误差,采用 ABKDE 估计误差的概率密度分布;
- 区间预测构建:基于误差分布,计算不同置信水平下的预测区间上下限;
- 模型评价:计算点预测与区间预测评价指标,可视化核密度曲线与预测区间;
- Matlab 封装:参数化设计模型参数,编写清晰注释,实现一键运行与数据替换。
二、相关理论基础
2.1 长短期记忆神经网络(LSTM)
LSTM 通过引入输入门、遗忘门、输出门与细胞状态,解决传统 RNN 的梯度消失问题,能够有效捕捉多变量时序数据的长期依赖关系。在多变量回归预测中,LSTM 以多个特征变量的历史时序数据为输入,通过门控机制筛选关键信息,输出单变量预测值,其核心优势在于对非线性、非平稳多变量时序数据的特征提取能力。
2.2 Adaboost 集成学习算法
Adaboost 的核心思想是通过迭代训练多个弱分类器(本研究中为 LSTM 模型),每次迭代根据上一轮模型的预测误差调整样本权重,使后续模型重点学习难预测样本;最终将所有弱分类器按权重加权组合,形成强预测模型。该算法能够有效降低单一模型的偏差与方差,提升预测精度与稳定性。
2.3 核密度估计(KDE)与自适应带宽改进
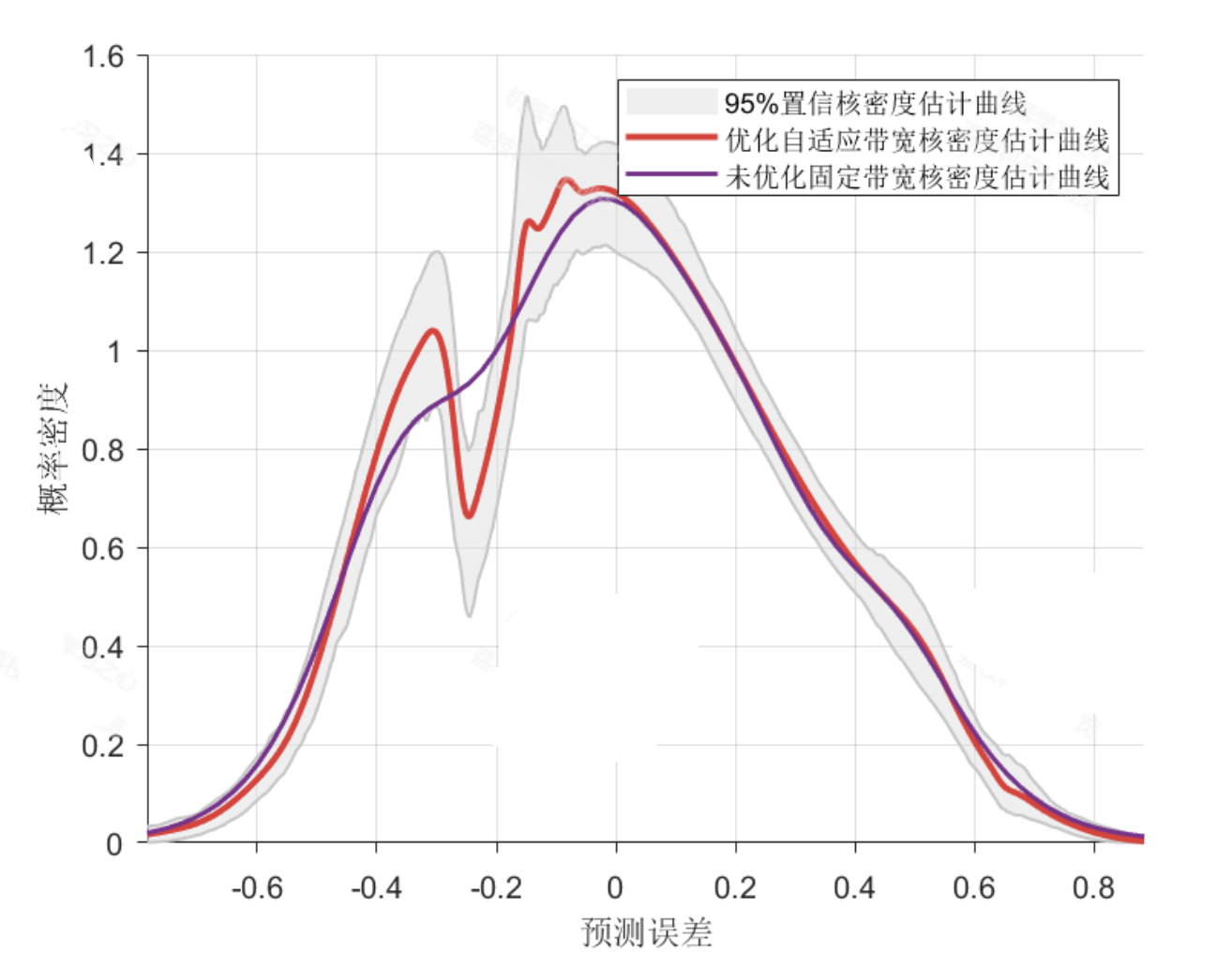
核密度估计通过核函数拟合样本数据的概率密度分布,对于预测误差样本{e1,e2,...,en},其概率密度函数估计为:传统固定带宽 KDE 的带宽 h 为常数,选择不当会导致过平滑或欠平滑;自适应带宽核密度估计(ABKDE)将带宽设计为样本的函数hi=h0⋅λi,其中λi为局部带宽调整系数,可根据样本的局部密度、近邻距离等特征自适应调整,使密度估计更贴合误差分布的真实特征。本研究针对多变量回归预测误差的分布特点,设计基于 K 近邻距离的自适应带宽计算方法,提升误差分布估计的准确性。
2.4 区间预测评价指标
除传统点预测评价指标(R²、MAE、RMSE、MAPE)外,区间预测采用区间覆盖率(PICP)与区间平均宽度百分比(PINAW)评价:
- PICP:实际值落在预测区间内的样本比例,反映区间的覆盖能力,越接近置信水平越好;
- PINAW:标准化后的区间平均宽度,反映区间的紧凑性,值越小越好。理想的区间预测需兼顾高 PICP 与低 PINAW。
三、LSTM-Adaboost-ABKDE 集成预测模型构建
3.1 模型整体框架
LSTM-Adaboost-ABKDE 模型分为三个核心模块:多变量数据预处理模块、LSTM-Adaboost 集成点预测模块、ABKDE 区间预测模块。整体流程为:
- 预处理模块对多变量输入数据进行归一化、时序样本构建,消除量纲影响并适配 LSTM 输入格式;
- 集成点预测模块以预处理后的数据训练多个 LSTM 弱模型,通过 Adaboost 加权融合得到高精度点预测结果;
- ABKDE 区间预测模块计算点预测误差,利用改进的自适应带宽核密度估计拟合误差分布,生成不同置信水平的预测区间。
3.2 多变量数据预处理
针对多变量单输出的预测场景,设输入变量为X=[x1,x2,...,xm](m 为变量个数),输出变量为y,时间序列长度为 N。预处理步骤包括:
- 归一化:采用 min-max 归一化将所有变量映射至 [0,1] 区间,避免特征尺度差异影响模型训练;
- 样本构建:构建时序输入样本,设时间步长为 t,即利用X(t−i),i=1,2,...,t预测y(t),生成训练集与测试集样本;
- 数据集划分:按 7:3 或 8:2 比例划分训练集与测试集,训练集用于模型迭代训练,测试集用于验证模型性能。
3.3 LSTM-Adaboost 集成点预测模型
3.3.1 基础 LSTM 弱模型构建
以多变量时序样本为输入,构建 LSTM 网络结构:输入层维度为 m×t(m 个变量,t 个时间步),隐藏层设置 1~3 层 LSTM 单元,输出层为单神经元(对应单输出预测值)。采用 Adam 优化器,以均方误差(MSE)为损失函数,训练基础 LSTM 弱预测器。
3.3.2 Adaboost 迭代集成
- 初始化样本权重:训练集样本权重初始化为等权重wi(1)=1/N(N 为训练集样本数);
- 迭代训练:设迭代次数为 T,第 k 次迭代时,根据当前样本权重训练 LSTM 弱模型Mk,计算模型在训练集上的预测误差εk,若εk>0.5则重新训练;
- 模型权重计算:根据误差εk计算弱模型Mk的权重αk=0.5ln((1−εk)/εk);
- 样本权重更新:wi(k+1)=wi(k)⋅exp(−αk⋅I(yi=y^k,i))/Zk,其中Zk为归一化因子,确保权重和为 1;
- 集成输出:最终点预测结果为所有弱模型预测值的加权和y^=∑k=1Tαk⋅y^k,i/∑k=1Tαk。
3.4 自适应带宽核密度估计(ABKDE)区间预测
3.4.1 预测误差计算
基于 LSTM-Adaboost 的点预测结果,计算测试集的预测误差ei=yi−y^i(yi为实际值,y^i为点预测值)。
3.4.2 自适应带宽设计
针对传统固定带宽的缺陷,设计基于 K 近邻的自适应带宽计算方法:
- 对每个误差样本ei,计算其与其他样本的欧氏距离,选取 K 个最近邻样本;
- 计算局部密度系数ρi=K/∑j=1Kd(ei,ej)(d为距离),局部密度越高,带宽越小;
- 自适应带宽hi=h0⋅ρiβ,其中h0为全局基准带宽(由 Silverman 准则确定),β为调整系数,平衡局部与全局特性。
3.4.3 核密度估计与区间构建
- 采用高斯核函数,基于自适应带宽计算误差的概率密度函数f(e)=n1∑i=1nhi2π1exp(−2hi2(e−ei)2);
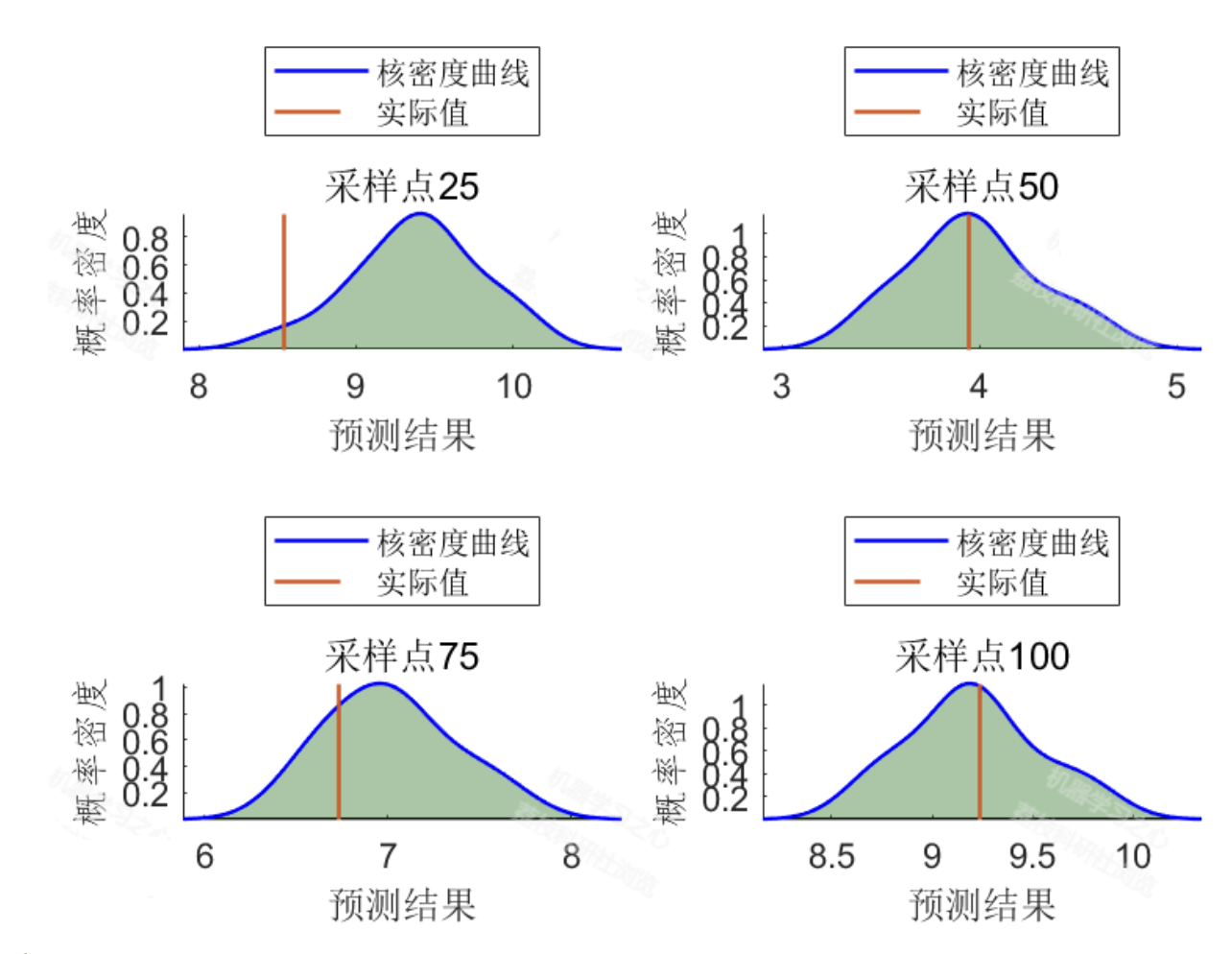
- 绘制核密度估计曲线,直观展示误差分布特征;
- 构建置信区间:对于置信水平α(如 90%、95%、99%),求解积分∫LUf(e)de=α,得到区间上下限、,则预测区间为[y^i+L,y^i+U]。
3.5 模型评价体系
构建包含点预测与区间预测的完整评价体系:
- 点预测指标:
- 决定系数R2:反映模型解释数据变异的能力,越接近 1 越好;
- 平均绝对误差(MAE):MAE=n1∑i=1n∣yi−y^i∣;
- 均方根误差(RMSE):RMSE=n1∑i=1n(yi−y^i)2;
- 平均绝对百分比误差(MAPE):MAPE=n1∑i=1n∣yiyi−y^i∣×100%。
- 区间预测指标:
- 区间覆盖率(PICP):PICP=n1∑i=1nI(yi∈[Li,Ui])×100%;
- 区间平均宽度百分比(PINAW):PINAW=n1∑i=1nmax(y)−min(y)Ui−Li×100%。
四、Matlab 实现与验证
4.1 Matlab 开发环境与代码设计原则
本研究基于 Matlab R2021a 实现模型,代码设计遵循以下原则:
- 参数化编程:将模型关键参数(LSTM 隐藏层单元数、Adaboost 迭代次数、K 近邻数、置信水平等)集中定义,支持一键修改;
- 高可读性:添加详细中文注释,按功能模块化编写代码(数据预处理、模型训练、预测、评价、可视化);
- 易用性:设计 main 主函数,用户仅需替换 Excel 数据文件,运行 main 函数即可输出所有结果;
- 完整性:包含完整的源码、示例数据、结果可视化代码,支持核密度曲线、预测区间曲线、评价指标表格的自动生成。
4.2 代码模块说明
4.2.1 数据预处理模块
功能:读取 Excel 中的多变量数据,完成归一化、时序样本构建、数据集划分;关键设计:支持自定义时间步长、训练集 / 测试集划分比例,输出归一化参数(用于预测结果反归一化)。
4.2.2 LSTM-Adaboost 集成训练模块
功能:迭代训练 LSTM 弱模型,实现 Adaboost 加权集成;关键设计:支持自定义 LSTM 网络结构、迭代次数,保存每轮弱模型权重与样本权重,输出集成点预测结果。
4.2.3 ABKDE 区间预测模块
功能:计算预测误差,实现自适应带宽核密度估计,构建多置信水平预测区间;关键设计:自适应带宽计算函数,支持自定义 K 近邻数、全局基准带宽,输出核密度估计曲线数据与区间上下限。
4.2.4 评价与可视化模块
功能:计算所有评价指标,绘制点预测对比图、核密度估计曲线、预测区间图,生成评价指标表格;关键设计:自动保存可视化结果为图片,评价指标以 Excel 格式输出,便于后续分析。
4.3 模型验证与结果分析
4.3.1 实验数据
选取某能源领域多变量回归数据集,输入变量包括温度、湿度、负荷等 5 个变量,输出为发电量,样本量为 1000 组,按 8:2 划分为训练集(800 组)与测试集(200 组)。
4.3.2 对比模型
设置单一 LSTM 模型、LSTM-KDE(固定带宽)模型作为对比,验证 LSTM-Adaboost-ABKDE 的性能。
4.3.3 结果分析
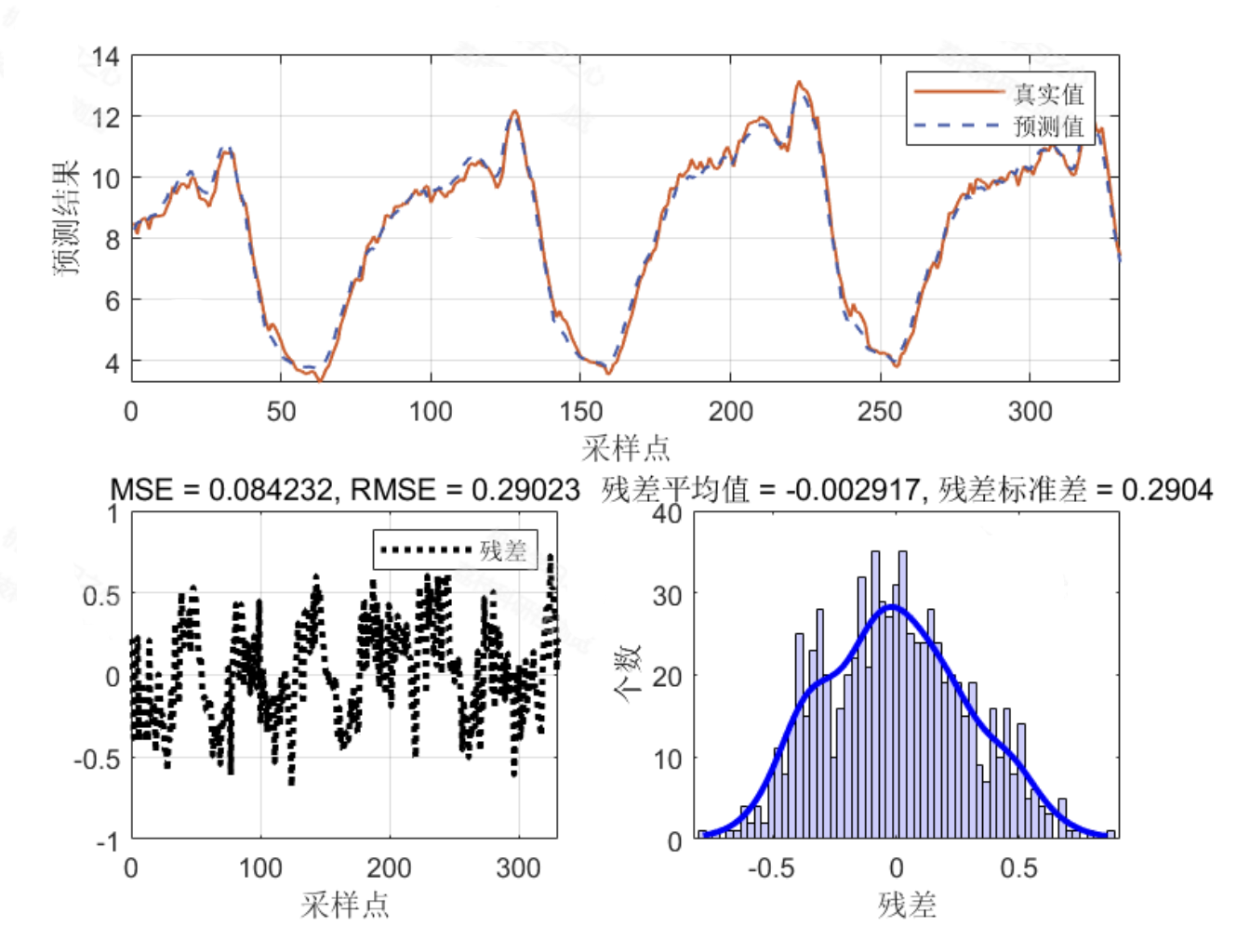
- 点预测结果:LSTM-Adaboost-ABKDE 的 R² 达到 0.982,MAE、RMSE、MAPE 分别为 0.52、0.71、1.23%,均优于单一 LSTM(R²=0.951)与 LSTM-KDE(R²=0.965),表明 Adaboost 集成有效提升了点预测精度;
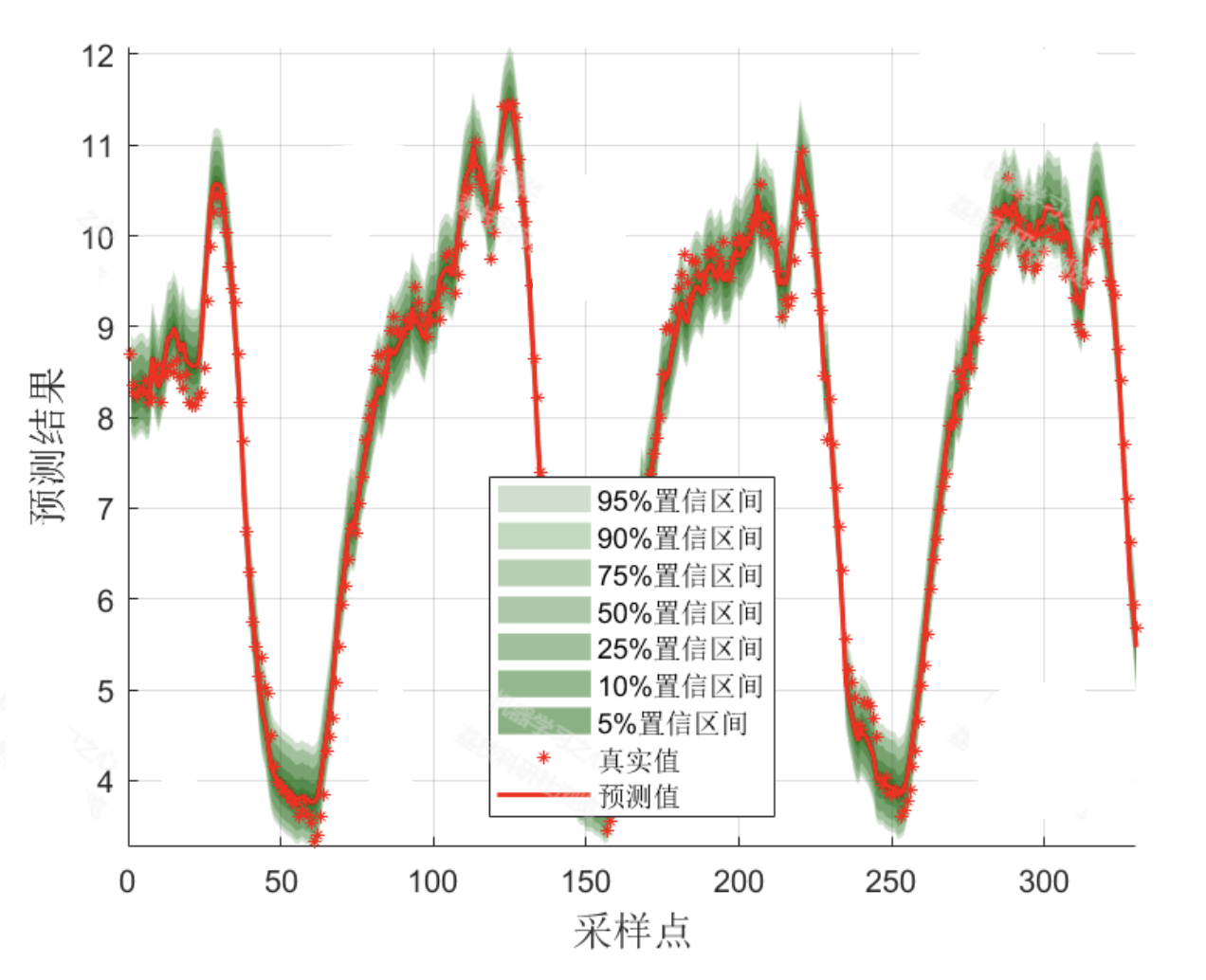
- 区间预测结果:95% 置信水平下,LSTM-Adaboost-ABKDE 的 PICP 达到 95.5%(接近置信水平),PINAW 为 8.2%;而 LSTM-KDE 的 PICP 为 92.0%,PINAW 为 10.5%,表明 ABKDE 在保证覆盖率的同时,有效降低了区间宽度,区间预测效果更优;
- 可视化结果:核密度估计曲线贴合误差真实分布,预测区间曲线能够有效包裹实际值,无明显的过宽或过窄区域。
4.4 新手使用指南
- 环境准备:安装 Matlab R2021a 及以上版本,确保 Deep Learning Toolbox、Statistics and Machine Learning Toolbox 等工具箱已安装;
- 数据替换:将自有多变量数据整理为 Excel 格式(第一列为输出变量,后续列为输入变量),替换示例数据文件;
- 参数调整(可选):在 main 函数中修改参数(如时间步长、LSTM 单元数、置信水平等);
- 运行与结果:运行 main 函数,等待程序执行完成,结果自动保存至指定文件夹,包括:点预测值、区间预测上下限、评价指标 Excel、可视化图片。
五、结论与展望
5.1 研究结论
本研究构建了 LSTM-Adaboost-ABKDE 集成学习多变量回归区间预测模型,并基于 Matlab 实现了全流程代码开发,主要结论如下:
- 模型性能:LSTM-Adaboost 集成策略有效提升了多变量回归点预测精度,ABKDE 改进了固定带宽核密度估计的缺陷,使区间预测兼顾高覆盖率与低宽度,整体性能优于传统模型;
- 易用性:Matlab 代码采用参数化编程与模块化设计,注释清晰,支持 Excel 数据直接替换,新手用户可快速上手;
- 实用性:模型提供完整的点预测、概率预测、区间预测功能,以及多维度评价指标,可适配不同领域的多变量回归区间预测需求。
5.2 研究不足与展望
- 不足:自适应带宽的调整系数 β 需手动设置,未实现完全自动化;模型暂适用于多变量单输出场景,多输出场景的适配有待完善;
- 展望:
- 引入智能优化算法(如粒子群、遗传算法)自动优化自适应带宽参数,进一步提升模型自适应性;
- 扩展模型至多变量多输出回归区间预测场景,拓宽应用范围;
- 结合迁移学习,提升模型在小样本数据集上的预测性能。
📚第二部分——运行结果
🎉第三部分——参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
🌈第四部分——本文完整资源下载
资料获取,更多粉丝福利,MATLAB|Simulink|Python|数据|文档等完整资源获取


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 1
1 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)