LLM 入门:ChatGPT 背后的原理(下)

讲座标题:Deep Dive into LLMs like ChatGPT
视频作者:Andrej Karpathy
原作链接:https://www.youtube.com/watch?v=7xTGNNLPyMI&ab_channel=AndrejKarpathy
编者按
Andrej Karpathy 在油管上发布了视频《Deep Dive into LLMs like ChatGPT》,用清晰直观的方式解释了 ChatGPT 背后的数学结构与工程逻辑。在《优化 | LLM 入门:ChatGPT 背后的原理(上)》中,我们回顾了讲座的上半场内容,从而对预训练(Pretraining)与后训练(Post-Training)有了初步的了解。本文将概括讲座的后半部分,主要介绍 LLM 中所涉及到的强化学习内容。
如何获得一个好的 ChatGPT 模型?在之前的推文中,我们了解到:首先通过预训练过程得到基础模型(Base-model),它可较好地进行读后续写工作;其次对模型进行后训练,从而使得模型适应一问一答的模式,懂得回答用户输入的问题。在本文中,我们对后训练中的内容进行适当的补充。
一、LLM 在问答中展现的性质
循序渐进的回答内容
在上文中,我们提到需要构建对话数据集,用于模型的后训练。
我们需要构建对话数据集,用于对基础模型进行后训练。其中对话数据集的文本内容过去往往通过人工撰写来获得,现在也可以利用 LLM 来帮助创建。

上面所举的例子都比较简单,回答的内容通常只有一句话。
那么对于较为复杂的问题,什么样的回答是合适的呢?我们注意到,GPT 本质上是在根据当前滑动窗口内的内容选择下一个输出的 token,以此往复;因此用于训练的回答内容最好是循序渐进的。换言之,我们根据问题内容和目前已有的推理内容,应当很容易地得出接下来的推理结果。

因此,对于上图中的应用题,我们更倾向于右边的回答。如果我们将左边的版本作为训练数据,那么模型在推理过程中容易出现错误的结果。这是因为,当滑动窗口内仅有语句 “Emily buys 3 apples and ... What is the cost of apples? ” 和 "The answer is " 对应的 token 以及对话数据格式自带的一些 token 时,模型很难一下子获得正确的答案 "$3". 因此我们在训练过程中需要避免这类情形。通过让模型学习右边的回答,我们为模型预留了足够的计算空间,从而使其能够学到真正的推理过程。
此外,我们在推理中也需要避免这类情形出现。如果我们向 GPT 输入上述问题,并强调 “仅写出最终的数字答案”,那么模型将遇到类似的问题。在推理过程中,我们同样需要为模型预留思考的空间。
模型的语言是 token
对于一些简单的问题,GPT 出人意料地表现得不好。前一段时间,互联网上流行着一个话题:各类 LLM 模型是否能正确回答出单词 strawberry 中有几个 r?当时不少模型给出的回答是 2 个。这件事也从侧面说明,LLM 并不擅长计数工作。
目前来看,各主流模型对于该问题的回答都已被修改为正确版本。其原因很可能在于 strawberry 问题太火了,因此各系统的工作人员实施了硬编码,让模型在检测到该问题的时候自动输出答案 “3个”。这并不代表 LLM 的计数能力真的提高了。
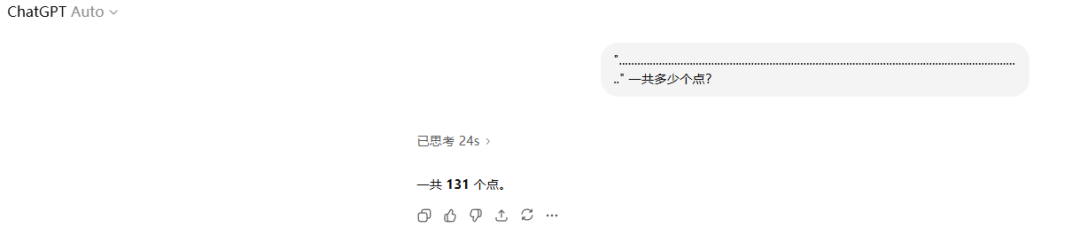
实际上,目前的 LLM 依旧不擅长计数工作。尽管 strawberry 是数对了,但当我们输入一串字符 “............” 并要求 GPT 数出有多少个点的时候,经常不能得到正确的回答。
相同的问题,在 ChatGPT-Auto、Deepseek 和豆包中得到了不同的答案。
注:实际一共有 131 个点。


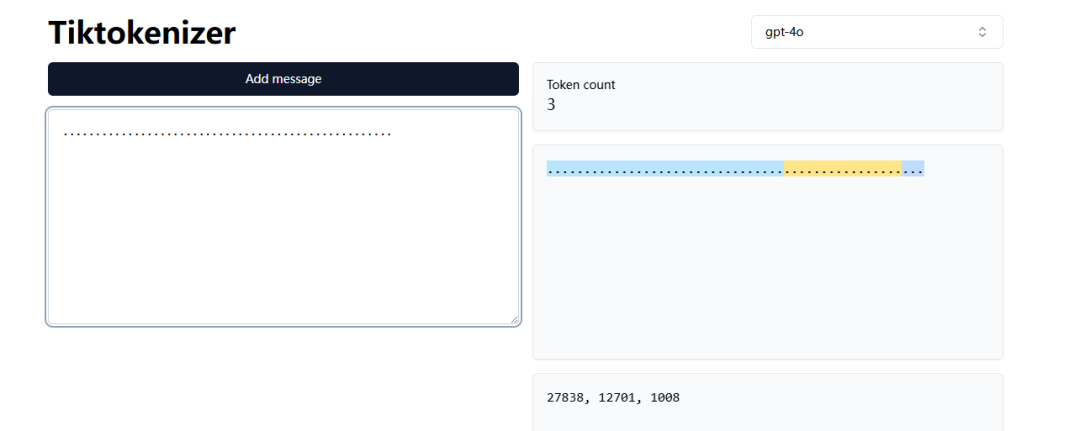
这是因为,这串字符对于我们而言是一串点,对于模型而言则是几个 token(例如下方的 27838,12701,1008)。因此模型无法直接计数,还需要先将 token 转换成对应字符串才行,而这些步骤对于 GPT 是费力的。
对于与字符串相关的问题,Andrej 所给的建议是在提问时额外要求模型用 python 处理。让模型将输入的字符串原封不动地复制到 python 中,是一项容易实现的工作;在 python 中对字符串进行计数等处理工作,同样可轻松实现。
这一步并不适用于所有的 LLM 模型。对于 deepseek 和豆包而言,当我们要求它们利用 python 为上述字符串".........." 计数时,模型均无法输出正确的答案。保险起见,我们可以要求它们生成对应的 python 代码,并将代码在本地 ide 运行,从而确定字符串处理 / 计数的结果。
二、后训练中的可选环节:强化学习
强化学习的具体实现
我们将经过对话数据集训练的模型称为 SFT model(supervised finetuning)。对于部分主流模型而言,SFT model 即为提供给用户的最终模型;对于另一部分主流模型而言,我们需要经过类似强化学习的训练过程,得到最终模型。
在下图中,Andrej 将模型经过预训练 -- 监督微调 -- 强化学习的过程与人的学习过程联系在一起。我们首先阅读书本中叙述性的文字,从而获取基本概念,这一步类似模型的预训练;其次,我们通过例题和对应的详细回答,学习解题的思路,这一步类似模型的监督微调;最后,我们尝试完成书本上给出的课后练习,通过将自己得到的结果与正确答案相比较,从而判断目前的解题思路是否合适,从而调整、巩固自己的做题能力,这一步对应模型的强化学习。

根据上文,我们知道模型的推理是需要逐步进行的,这给我们构建对话数据集带来了大致的解答思路。在此基础上,Andrej 给出了四种不同的解答版本,如下图所示。
对于我们而言,第二种回答是最利于理解的。注意到,模型的语言是 token。在强化学习这一步中,模型将自行探索哪一种解答是最利于模型自身理解的。对于每个问题,模型将生成多个解答,然后根据这些解答内容是否符合真实答案,从而对模型参数实现微调。在训练过程中,模型将越发偏向有利于推导出正确答案的解答版本。
通过强化学习得到的结论
deepseek 团队发表的相关论文表明,经过强化学习后,我们可以允许模型使用更多 token 回答问题,从而提高对应解答的正确率。在下图中,我们可以看到 deepseek 的深度思考过程。注意到,模型解答过程中试图尝试不同的思路,并且会回头对自己已经产生的论断进行检查,这使得回答的正确率提升。这一模型与我们回答问题时类似。

创造性内容的评判标准:从 RL 到 RLHF
对于强化学习中的问题,我们需要给出对应的答案。对于数学题、围棋比赛,我们可以给出明确的正确答案和判别规则;然而对于一些创造性内容(例如诗词、笑话),我们需要人为地给出一些打分的标准。这一训练过程被称作基于人类反馈的强化学习(RLHF, Reinforcement Learning from Human Feedback)。
在这个环节中,为了减少人工判断的成本,我们会训练一个神经网络用于特定任务的打分(例如对于每个文本,给出 0-1之间的幽默度打分),其训练数据来自于人工标注员对若干文本的排序(例如以 5 个文本为一组,人工标注员每次根据文本的幽默程度从高到低排序,分别给出 1,2,3,4,5 的标签)。在得到了打分模型之后,我们借助它训练 SFT 模型。
然而,打分模型无法完全达到人类的判断水平。对于某些毫无意义的话,打分模型会给出很高的分数。而强化学习又极其容易寻找到这些打分模型的漏洞,从而使得训练后的模型最终倾向于回答出毫无意义的话。注意到,这类内容在模型中是无穷无尽的,因此即使我们特意规定模型不能生成某句废话,它也会在强化学习的过程中找到另一句高分的废话,作为最终偏好的输出。
实际上,在训练过程中,模型的效果是先上升后急速下降的。由于无法规避打分模型的漏洞,因此我们会在模型效果提升一段时间时候结束训练,从而防止其受到更大的负面影响。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)