交通 | 机器学习如何助力大规模双层优化---自行车网络设计案例解读

编者按:
当双层优化遇到“百万级 follower”,问题的难度不再来自模型形式,而来自规模本身——意味着每评估一个上层决策,都需要求解上百万个下层优化问题。在这样的规模下,精确求解几乎不可行,而简单抽样或黑箱预测又难以保证解的质量。本文介绍的这项工作由多伦多大学团队完成,并发表于 2025 年的 Manufacturing & Service Operations Management (MSOM),给出了一个颇具启发性的答案:将机器学习嵌入大规模双层优化模型之中,在优化过程中同时控制预测误差,并在严格的理论框架下分析最优性差距。它不是单纯的机器学习应用,也不是传统的随机规划近似技巧,而是在优化模型内部构造一个“可控的近似机制”,让 ML 成为可以被分析、被约束、被证明有效的工具。更重要的是,这套方法不仅在理论上给出了解质量保证,也在真实的城市案例中实现了显著提升,并已进入实际规划流程。对于研究大规模两阶段随机规划、双层优化、ML + Optimization 融合,或关注基础设施规划问题的读者来说,这是一篇兼具方法创新与现实影响力的工作,值得细读。
[1] Chan, T. C. Y., Lin, B., & Saxe, S. (2025). Machine Learning-Augmented Optimization of Large Bilevel and Two-stage Stochastic Programs: Application to Cycling Network Design. Manufacturing & Service Operations Management.
一、从一个真实问题开始
近年来,越来越多城市开始推广自行车出行。原因很简单:有利于缓解交通拥堵,有助于降低碳排放,提升公共健康水平。但现实中,影响居民是否骑车的最大障碍之一,是“安全感”。如果一条道路车流量大、没有独立车道、路口设计复杂,即使距离很近,人们也未必愿意骑行。因此,在交通规划中有一个重要概念:Low-stress cycling infrastructure(低压力自行车网络),也就是让普通成年人在“心理压力可接受”的条件下骑行的道路系统。但在有限的城市预算下,可改造的道路很多,不可能一次性全部升级。于是规划者面临一个核心问题:在有限预算下,哪些路段应该优先建设,才能让更多人通过“安全的自行车网络”到达工作地点?
这并不是一个简单的“选几条路”的问题。一条道路是否值得建设,不只取决于它本身,而取决于它在整个网络中的作用——它是否连通关键区域,是否打通瓶颈,是否让更多人能够到达重要目的地。论文采用的核心指标叫做 Low-stress cycling accessibility,这里我们可以简单理解为:在安全(低压力)条件下,一个城市的自行车网络能覆盖多少经济活动。研究表明,这个指标与实际骑行比例高度相关,也已被多伦多市政府用于政策评估。
因此,在多伦多的骑行网络规划中,作者将问题建模为一个 双层优化(bilevel optimization)问题,目标是:在一定的预算约束下,最大化城市在“安全骑行条件”下所支持的经济活动覆盖能力。具体结构是:
- 上层(Leader):城市交通规划者,决定在哪些道路上建设自行车基础设施,受总长度或预算限制(例如 100 公里)。
- 下层(Followers):城市中所有可能的“出发地–目的地(OD)对”,假设骑行者会在低压力网络中选择最短路径。
也就是说:每一个 OD 对都会根据上层设计的网络,计算一条最优骑行路径。回到多伦多的真实案例数据中,问题规模远超想象:城市被划分为 3,702 个小区域(DA),每个区域既是居民出发地,也是工作岗位所在地区,所有可能的 OD 对数量超过 115 万个…这意味着每评估一个网络设计方案,都需要解超过一百万个最短路问题。下层问题的巨大规模使得商业求解器往往难以找到可行解,原始双层模型的计算时间可超过 10 小时。正是在这个背景下,作者提出了:用机器学习增强的大规模双层优化的方法。
二、为什么这个问题“计算上不可行”?
先看标准形式。论文第 3 章给出的模型,目标函数本质上是:
minx∈Xf(x)+∑s∈SqsGs(x)\min_{x \in X} f(x) + \sum_{s\in S} q^s G^s(x)x∈Xminf(x)+s∈S∑qsGs(x)
简单解释一下模型中的符号:xxx是上层决策(在哪些道路上建设自行车基础设施),Gs(x)G_s(x)Gs(x)代表在给定网络xxx下第sss个 OD 对的最优路径成本(即骑行者在低压力网络中的最短路结果),SSS是所有 follower 的集合(在多伦多案例中超过一百万个 OD 对),qsq^sqs对应第sss个 OD 对的权重,例如该目的地所包含的工作岗位数量。
是不是问题的形式这么看还蛮简单清晰的?实际上的问题在于:每评估一个 xxx,都需要解超过一百万个最短路问题。从理论上看,这只是重复计算;但在真实规模下,计算量会迅速失控。要理解这篇文章的核心技术贡献,首先要意识到:这个问题的计算瓶颈,很大程度上来自于下层 follower 集合SSS的巨大规模。当SSS达到百万级时,传统方法通常有两类思路:一类做法是只抽样少量 followers(例如 1% 的 OD 对)进行建模,这样的话虽然规模下降了,但无法保证所得解在全部一百万个 OD 对上的整体质量。另一类方法是先用机器学习预测,再优化。具体来说,训练一个模型去近似整体目标函数
G^(x)≈∑sGs(x)\hat G(x) \approx \sum_{s} G_s(x)G^(x)≈s∑Gs(x)
然后在这个 surrogate 模型上进行优化。然而,这类方法通常是“先预测、后优化”:机器学习模型是预训练的,优化决策本身并不会反过来影响模型结构或参数,因此理论上的最优性保证也较为薄弱。
三、这篇论文的核心思想:“优化与训练一体化”
minx, Pf(x)+∑t∈TqtGt(x)+∑s∈S∖TqsP(fs)\min_{x,\,P} \quad f(x) + \sum_{t\in T} q^t G^t(x) + \sum_{s\in S\setminus T} q^s P(f^s)x,Pminf(x)+t∈T∑qtGt(x)+s∈S∖T∑qsP(fs)
s.t.∑t∈Tmt∣P(ft)−Gt(x)∣≤Lˉs.t. \quad \sum_{t\in T} m^t |P(f^t) - G^t(x)| \le \bar{L}s.t.t∈T∑mt∣P(ft)−Gt(x)∣≤Lˉ
论文第 3.3 节提出的核心模型可以概括为:在优化上层决策xxx的同时,引入一个预测模型PPP。在目标函数中,对抽样得到的一小部分 followersTTT仍然进行精确计算,而对未被抽样的部分S∖TS \setminus TS∖T,则通过机器学习模型 P(fs)P(f^s)P(fs)进行预测。真正关键的是,模型中加入了一个训练误差约束:在样本集合TTT上,预测值 P(ft)P(f^t)P(ft)与真实成本 Gt(x)G^t(x)Gt(x)的偏差必须被控制在一个上界 Lˉ\bar{L}Lˉ之内。这意味着,机器学习模型必须在样本上“拟合得足够好”。更重要的是,xxx和PPP是同时优化的——模型参数不是预训练得到的,而是作为决策变量的一部分参与优化。正是这种“优化与训练一体化”的结构,使作者能够建立:所得到的上层解在“全体 followers”意义下仍然具有可证明的误差界。
四、这种近似方法可靠吗?
在提出上述模型之后,一个自然的问题是:这种近似方法到底在什么条件下是“可靠的”?作者在论文第四节中给出了严格的理论分析,包括概率界与最优性差距上界。这里我们不展开具体推导细节,感兴趣的读者可以直接查阅原文。我们只提炼其中几个核心思想。
作者首先证明:只要满足两个关键条件,得到的上层解在“全体 follower”意义下依然是可证明高质量的。第一,follower 的特征必须是“有意义的”,即在特征空间中相近的 follower,其成本变化模式也应相似;第二,抽样方式需要尽量均衡,避免某一个样本代表过多未抽样的 follower。在这两个条件同时成立的情况下,即便我们只显式建模一小部分 followers,最终得到的网络设计仍然对整体人群具有可靠的性能保证。
为什么这两个条件如此关键?理论上,作者将最优性差距清晰地分解为两部分:Bias 与 Variance。Bias 来自预测误差——未抽样 follower 与样本 follower 在特征空间中的距离越大,预测误差越可能上升;Variance 则来自抽样不均衡——如果某个样本“代表”了过多未抽样 follower,那么个体误差的波动会被放大。这种分解并非经验直觉,而是严格概率界的结果。也正因为有这样的结构,作者设计了一种具有“覆盖 + 平衡”思想的抽样算法:一方面尽量缩小未抽样 follower 与样本之间的特征距离(控制 Bias),另一方面限制每个样本所代表的 follower 数量(控制 Variance),而不是简单随机抽样。
接下来便是更核心的问题:什么样的特征才算“有意义”?在理论假设中,有一个关键条件——如果两个 follower 在特征空间中彼此接近,那么在任意上层决策xxx下,它们的最优成本Gs(x)G^s(x)Gs(x)不应差异过大。换句话说,特征空间中的“距离”必须真实反映成本函数的变化结构。如果特征设计不合理,例如只用地理坐标,那么两个在地图上接近的 OD 对,可能在网络连通性上却完全不同,这会直接放大预测误差,使理论界变得松弛。
为了解决这个问题,作者构建了一个数据驱动的表征学习过程。他们先随机采样若干上层决策,观察不同 followers 在这些网络设计下的成本变化模式;如果两个 followers 在多种网络下表现相似,就认为它们在行为上相似。基于这种相似性构建 follower–follower 关系图,并使用类似 DeepWalk / Skip-Gram 的方法学习低维 embedding。这样得到的表示具有一个重要性质——“行为相似”的 follower,在特征空间中距离更近。实验结果也表明,这种 learned representation 显著优于手工设计的几何特征或传统图论指标(如中心性)。更重要的是,它使理论分析中的 Lipschitz 条件更容易满足,从而收紧误差上界,提升整体解的质量。
五、真实案例:多伦多自行车网络规划
在真实的多伦多案例中,问题规模相当可观:网络包含 10,448 个节点、35,686 条道路,以及 1,154,663 个 OD 对。规划目标是在预算约束下,最大化“30 分钟内通过低压力道路可达的工作岗位数量”。如果直接求解原始双层模型,每个实例的计算时间往往超过 10 小时,几乎难以在实际规划流程中使用。而采用 ML-augmented 方法后,计算时间仅为原始模型的 0.5%–5%,却能得到接近最优的解质量。
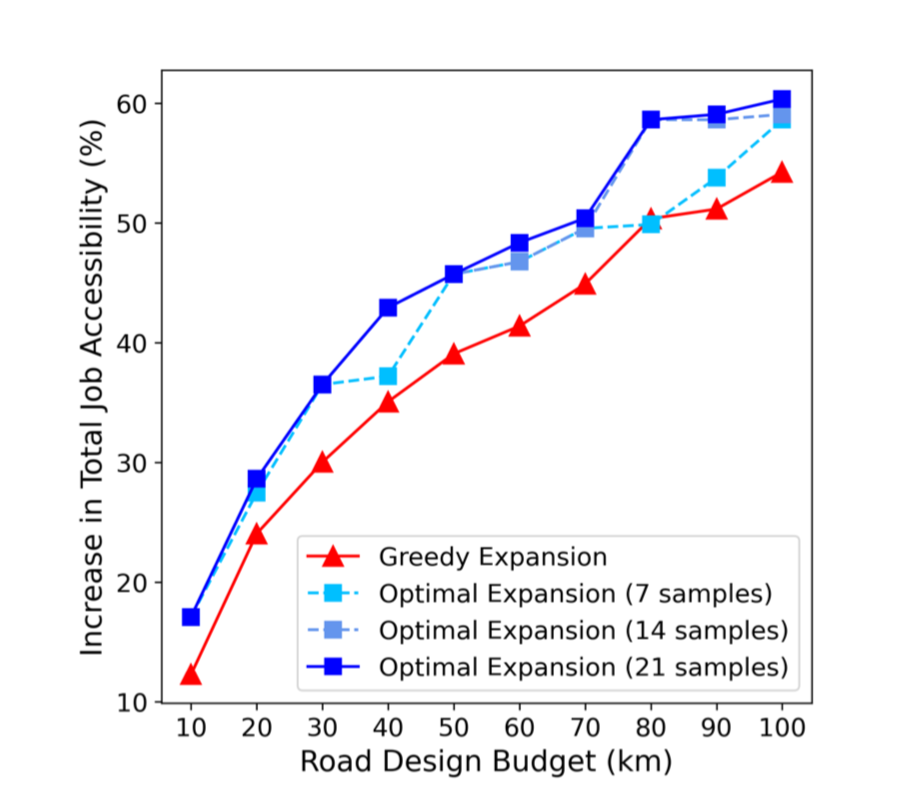
下面这个图展示了不同预算水平下的性能对比。可以看到,在相同预算下,ML-augmented 的最优扩展方案明显优于传统的贪心扩展方法。总体而言,相比当前多伦多采用的贪心策略,可达性平均提升约 19.2%。换句话说,如果原本需要建设 100 km 的自行车网络才能达到某一水平的可达性,现在仅需约 70 km 即可实现相近效果,对应潜在节省约 1800 万美元。更重要的是,该模型已被实际用于多伦多 2025–2030 年的自行车基础设施规划,让我们可以真正看到运筹学方法在真实政策决策中的落地价值。
参考文献:
[1] Chan, T. C. Y., Lin, B., & Saxe, S. (2025). Machine Learning-Augmented Optimization of Large Bilevel and Two-stage Stochastic Programs: Application to Cycling Network Design. Manufacturing & Service Operations Management.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)