一文讲透 Token:从“词元”到大模型底层机制
一、开篇:为什么你必须搞懂 Token?
你可能每天都在用大模型,但如果我问你:
-
40 万 Context Window,到底能装多少内容?
-
Token 和“字数”“单词数”到底是什么关系?
-
为什么同一句话,有时“很费 Token”?
大多数人会模糊回答。
但实际上,Token 是理解大模型能力边界的第一把钥匙。
👉 40 万 Token ≠ 40 万字 ≠ 40 万个单词
https://platform.openai.com/tokenizer
更重要的是:
👉 2026年3月24日,也就是今天,国家数据局在官方发布中首次提到 Token 的标准中文译名——“词元(Ciyuan)”。
https://www.sina.cn/news/detail/5280098790150976.html
这意味着,这个概念已经从“技术黑话”,正式进入国家级标准体系。
二、Token(词元)介绍
Token(词元)是:大模型处理信息的最小信息单元,具有智能时代可计量、可定价、可交易的特征。
据国家数据局统计,2024年初,中国日均词元(Token)调用量为1000亿;至2025年底,跃升至100万亿;今年3月,已突破140万亿,两年增长超千倍。
http://t.cn/AXfnOsyH
但需要特别强调:
-
它不是“字”;也不是“词”;更不是“字符数”。
一个核心误区,很多人会误认为:1 Token = 1 个字,实际上完全不是这样。
Token 的产生依赖于一个组件: Tokenizer
它的作用是:
-
把文本切分为一个个 Token
-
再把 Token 转换为数字
举个例子,一句话:“马克喜欢人工智能吗”
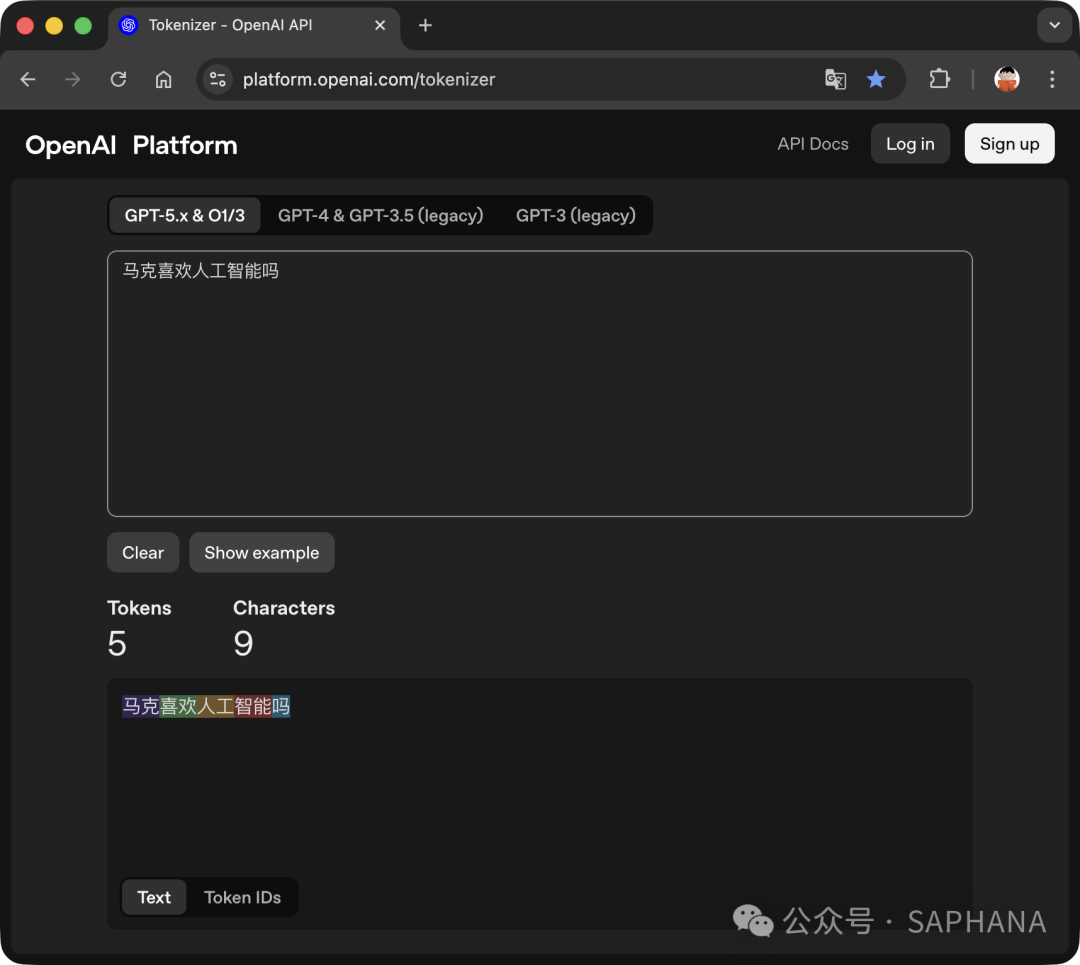
在 Tokenizer 处理后变成:
-
马克
-
喜欢
-
人工
-
智能
-
吗
👉 一共 5 个 Token(词元)。
三、大模型的基本工作原理
要理解 Token,必须先理解大模型。大模型本质是一个巨大的数学函数,内部全部是:矩阵运算 和 向量计算。它的特点:
-
输入:数字 → 输出:数字
👉 它并不理解人类文字语言
关键问题
既然模型只认数字:
👉 那人类语言是如何被处理的?
答案就是:Tokenizer
https://platform.openai.com/tokenizer
Tokenizer 的两个核心功能
1️⃣ 编码(Encoding)👉 把文字转换为数字 |
2️⃣ 解码(Decoding)👉 把数字转换为文字 |
完整流程
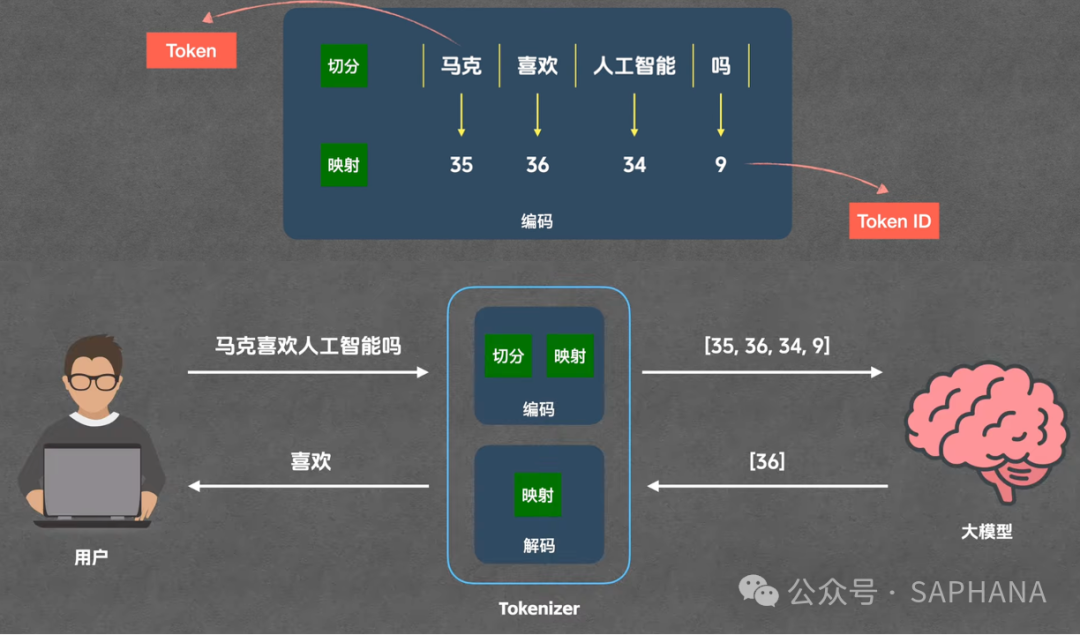
以问题为例:
“马克喜欢人工智能吗”
第一步:编码
编码包含两个子步骤:
(1)切分
把句子拆成 Token:
-
马克
-
喜欢
-
人工智能
-
吗
(2)映射
每个 Token → 一个数字(Token ID)
例如:
-
马克 → 35
-
喜欢 → 36
👉 注意:Token 是“文字”,Token ID 是“数字”,两者一一对应。
Token ID 没有语义,它只是编号
第二步:模型计算
Tokenizer 把 Token ID 列表传给模型:
👉 模型进行大量矩阵运算
然后输出:
👉 一个 Token ID
第三步:解码
Tokenizer 把 Token ID → Token
例如:
-
36 → “喜欢”
输出方式
你在平时使用AI的过程中应该已经注意到了,模型不是一次输出一句话,而是一次输出一个 Token,然后继续生成下一个。当然现在生成速度变快,有时间可能注意不到这个过程。
四、Tokenizer 的训练过程
很多人以为 Tokenizer 非常复杂,其实:
Tokenizer 是训练出来的,但远比大模型简单
常见算法有两种:Unigram 和 BPE(Byte Pair Encoding)。
其中 Google 常用 Unigram,而 OpenAI / Anthropic 常用 BPE。
BPE 的核心思想
找出经常一起出现的字,并把它们合并成一个 Token
训练步骤详解
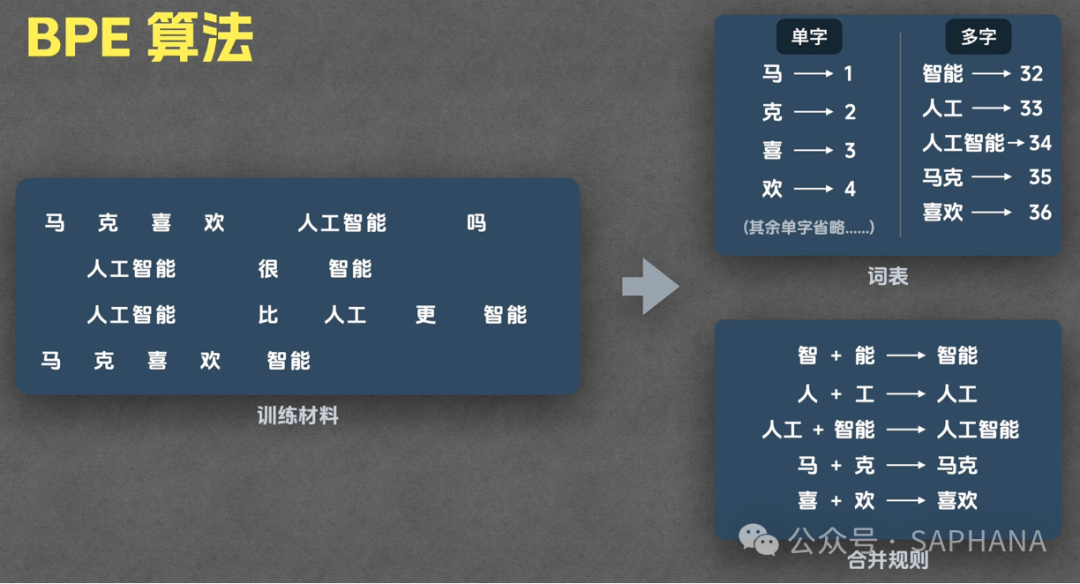
Step 1:准备训练语料
一堆文本数据
Step 2:初始化词表
把所有单字加入词表:
-
马/克/喜/欢/人/工/智/能/吗
每个字:
👉 都是一个 Token
👉 都有一个 Token ID
Step 3:统计共现频率
算法扫描语料,寻找:
👉 哪些字经常一起出现
Step 4:执行合并
|
步骤 |
发现 |
操作 |
|---|---|---|
|
第一轮 |
👉 “智 + 能”出现最多 → 合并为:“智能” |
|
|
第二轮 |
👉 “人 + 工” → 合并为:“人工” |
|
|
第三轮 |
👉 “人工 + 智能” → 合并为:“人工智能” |
|
|
后续 |
|
|
关键特点
👉 合并后的 Token 还可以继续参与合并
👉 Tokenizer 包含两部分:
1️⃣ 词表(Vocabulary)
2️⃣ 合并规则(Merge Rules)
五、Tokenizer 的使用过程
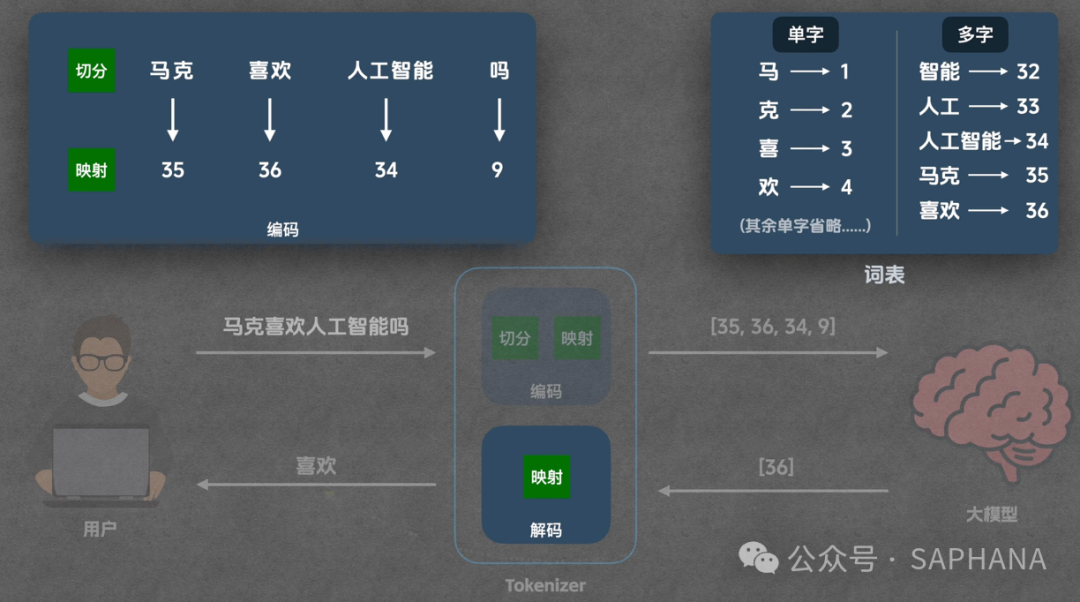
编码阶段
Step 1:初始切分
句子:
“马克喜欢人工智能吗?”
先拆为:
马 / 克 / 喜 / 欢 / 人 / 工 / 智 / 能 / 吗
Step 2:应用合并规则
逐条匹配:
-
智 + 能 → 智能
-
人 + 工 → 人工
-
人工 + 智能 → 人工智能
-
喜 + 欢 → 喜欢
-
马 + 克 → 马克
👉 最终得到:
-
马克
-
喜欢
-
人工智能
-
吗
Step 3:映射为 Token ID
查词表完成
解码阶段
模型输出:Token ID → 查词表 → Token
例如:36 → “喜欢”
关键补充
-
编码:需要切分 + 映射
-
解码:只需要映射(不需要切分)
因为:模型一次只输出一个 Token (一个词或者一个字)
六、Token 与字数的换算关系
现在回到最开始的问题:
👉 为什么 Token ≠ 字数?
核心原因
Tokenizer 不只是翻译器,它还是压缩器
示例:“马克喜欢人工智能吗” → 9 个字
处理后:4 个 Token
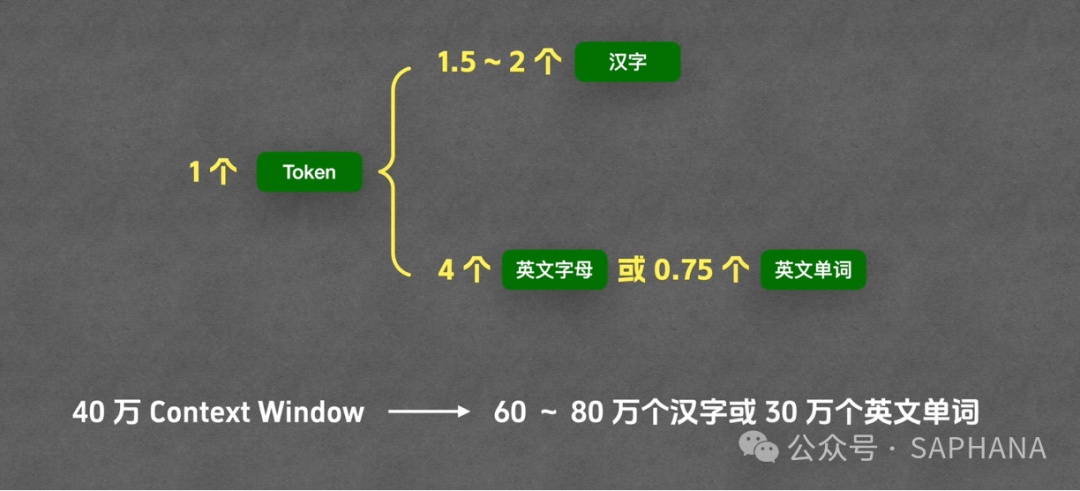
换算关系(经验值)
|
类型 |
换算 |
|---|---|
|
中文 |
1 Token ≈ 1.5~2 个汉字 |
|
英文 |
1 Token ≈ 4 个字母 or 0.75 个单词 |
Context Window 的真实含义
例如:40 万 Token
大致等价于:
-
中文:60~80 万字
-
英文:约 30 万单词
七、总结
我们用一句话总结整篇内容:
Token(词元)是大模型处理信息的最小单位,由 Tokenizer 通过“切分 + 映射”生成,本质是对语言的结构化压缩表示。
你必须记住的 5 个关键点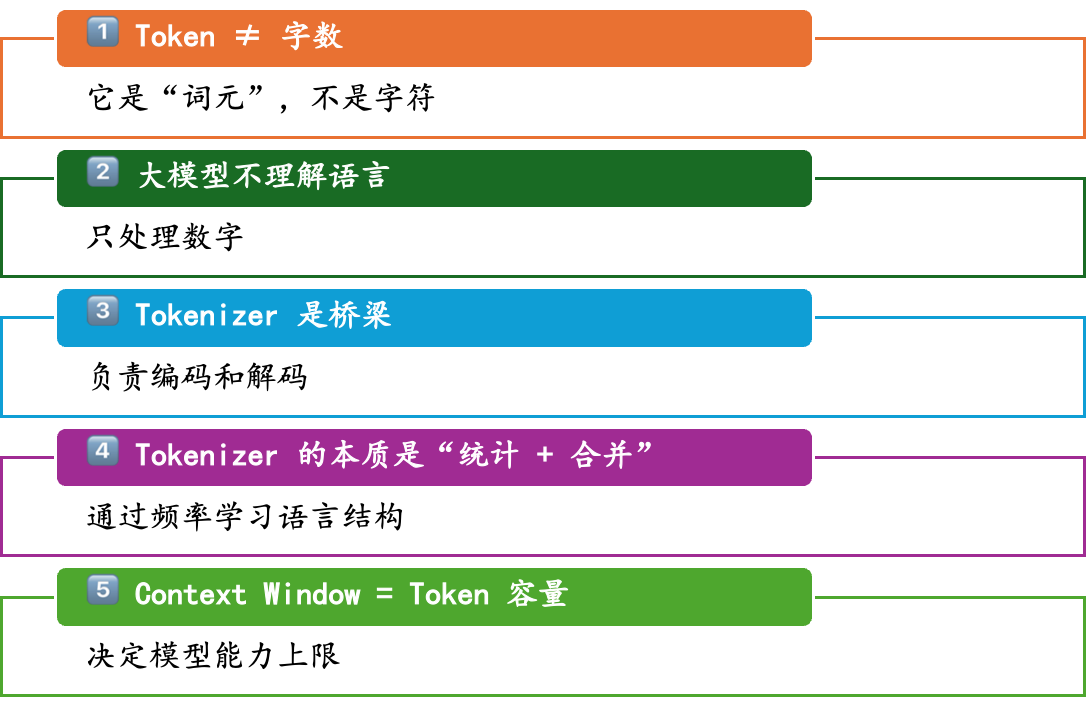

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)