DIT4DIT:联合建模视频动力学和动作以实现通用机器人控制
26年3月来自Mondo机器人公司和香港科大的论文“DIT4DIT: Jointly Modeling Video Dynamics And Actions For Generalizable Robot Control”。
视觉-语言-动作(VLA)模型已成为机器人学习领域一个极具前景的范式,但其表征仍然主要继承自静态图像-文本预训练,导致物理动力学只能从相对有限的动作数据中学习。相比之下,生成式视频模型编码丰富的时空结构和隐式物理信息,使其成为机器人操作的有力基础。然而,其潜力尚未得到充分挖掘。为了弥补这一差距,提出DiT4DiT,一种端到端的视频-动作模型,它将视频扩散transformer(DiT)与动作扩散transformer耦合在一个统一的级联框架中。DiT4DiT并非依赖于重建的未来帧,而是从视频生成过程中提取中间去噪特征,并将其用作动作预测的时间基础条件。进一步提出一种双流匹配目标,该目标采用解耦的时间步长和噪声尺度,用于视频预测、隐状态提取和动作推理,从而实现两个模块的协同训练。在仿真和真实世界基准测试中,DiT4DiT 均取得最先进的结果,在 LIBERO 和 RoboCasa GR1 上分别达到平均 98.6% 和 50.8% 的成功率,同时使用的训练数据量显著减少。
为了克服静态视频模型的物理盲点,近期的研究越来越多地转向生成式视频模型,这些模型自然地包含了丰富的时空先验和复杂的物理动力学(Hu et al., 2024; Ye et al., 2024; Liang et al., 2025; Feng et al., 2025; Liao et al., 2025; Wang et al., 2025; Zhong et al., 2025; Cen et al., 2025; Feng et al., 2025; Bi et al., 2025; Li et al., 2026)。从历史上看,机器人领域的视频预测主要用于视觉预测,通过“想象”未来状态来实现基于模型的规划(Finn & Levine, 2017; Ebert et al., 2018; Yang et al., 2023; Du et al., 2023)。然而,随着高保真扩散Transformer(DiT)的出现,一个将视频生成直接集成到策略学习中的新领域已经出现。
近期的一系列研究(Shen et al., 2025; Li et al., 2025a; Bi et al., 2025; Li et al., 2026)探索了将视觉动态和控制信号投影到共享的潜空间中。这些模型有效地将多种功能(例如正向模拟和逆向动力学)整合到一个单一的学习系统中。基于这种显式统一的趋势,Cosmos Policy(Kim,2026)通过微调预训练的视频扩散模型,进一步简化自适应过程,使其能够直接输出机器人动作和未来预期值,并将它们编码为原生视频扩散过程中的连续潜在帧。与其最为密切相关的工作是mimic-video(Pai,2025),它将预训练的视频骨干网络与独立的流匹配动作解码器相结合,并在中间流时刻以部分去噪的视频潜帧为条件来调整策略。
相比之下,本文探索视频和动作生成的联合训练,使动作模型能够学习如何在视频生成过程的不同阶段提取有效特征,从而产生更鲁棒的表示。
首先考察视频生成能否作为策略学习的有效代理(proxy)目标。长期以来,对动作标注数据的强依赖性限制了VLA模型的扩展性。以往尝试通过辅助任务(例如,接地和以视频动作模型为中心的潜特征建模)来利用视觉监督的方法通常样本效率低下。例如,FLARE(Zheng et al., 2025)等方法试图将当前-未来表示与预训练的VLM对齐,但难以捕捉连续的像素级物理动态。相比之下,视频生成是一种高效的无监督预训练信号。如图所示,视频动态目标比接地和FLARE式基线方法收敛速度更快,最终成功率更高。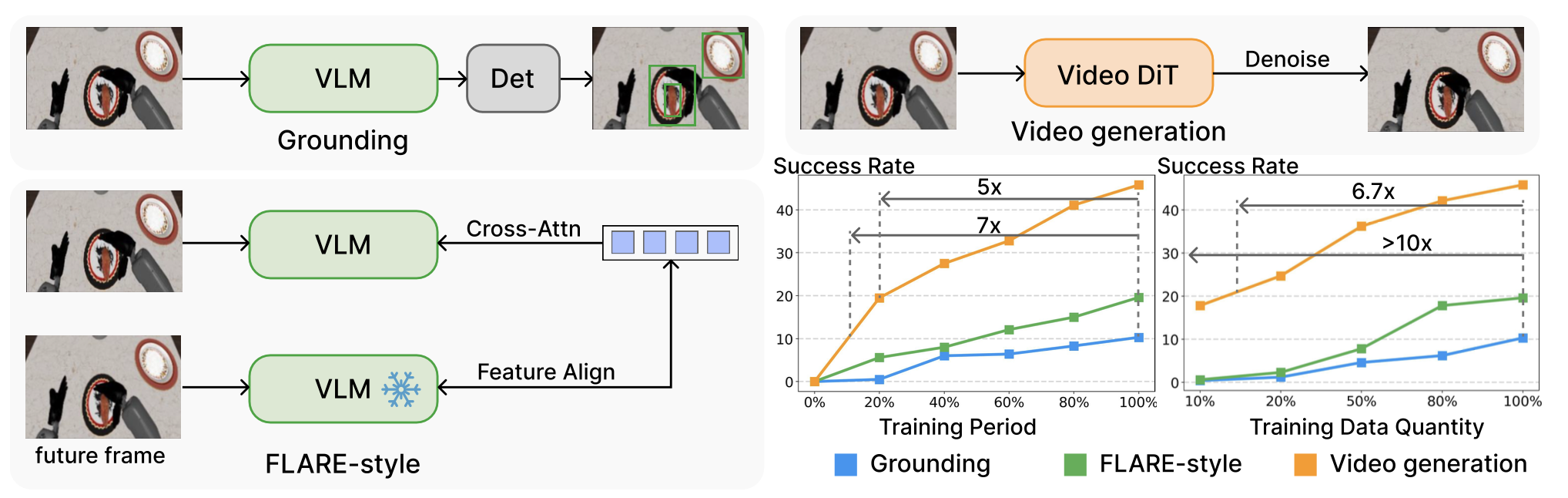
为此,提出DiT4DiT,一个采用双DiT架构的统一端到端(E2E)视频-动作模型(VAM)。与以往基于视觉语言自回归骨干网络的方法不同,该框架采用了双向视频扩散Transformer(DiT)(Peebles & Xie, 2023)。在去噪过程中,从未来帧的生成中提取紧凑的潜特征,并利用这些特征来指导动作学习,从而使策略能够基于控制物理交互的生成式视觉动态。为了避免不相交的多阶段优化,进一步提出一种基于双流匹配的统一联合训练范式,该范式在一个框架内优化视频和动作生成。该方法为这两个模块分配不同的时间步长和噪声尺度,从而能够在将去噪后的多阶段视频潜特征迁移到动作潜特征空间的同时,实现独立或耦合的更新。这种设计简化训练流程,并显著缩短收敛周期。
本文的核心假设是视频生成是机器人控制的有效代理(proxy)任务。因此,首先对其进行测试,以确保设计选择基于实证证据。针对两种范式进行对比研究。第一种是目标级接地(如Bjorck,2025),即使用辅助检测头训练VLM,以驱动VLM理解VLA中目标的“是什么”和“在哪里”。另一种是基于VLM的隐世界建模方法,类似于FLARE。FLARE(Zheng,2025)使用可学习的查询来关注VLM中的特征,并将这些查询与未来观测的潜嵌入对齐。本文放弃FLARE中查询的扩散过程,而是采用类似FLARE的预训练方法。用 Qwen3-2B (Bai et al., 2025) 和 Cosmos-Predict2.5-2B (Ali et al., 2025) 作为视频模型骨干网络,以确保可训练参数的规模保持一致。
在 RoboCasa 仿真环境中,使用 GR1 人形机器人 (Nasiriany et al., 2024; Bjorck et al., 2025) 完成了 24 个桌面操作任务,并进行了验证。为了更有效地评估代理任务的有效性,在所有三个实验设置中都将预训练阶段与动作专家的下游训练解耦。视频模型骨干网络在目标数据集上以自监督的方式进行训练(除了接地任务使用预先标注的边界框),然后在动作专家的微调过程中保持冻结状态。实验结果(见上图)表明,视频生成目标在训练效率和可扩展性方面具有优越性。生成代理任务使模型能够更快地收敛到高性能策略(速度提升高达 7 倍),并在训练过程早期就捕捉到关键的操作线索。此外,它还展现出稳健的扩展性:与基于语义的方法相比,数据效率显著提高(高达 10 倍),并且随着数据量的增加,性能持续提升。这验证了视频生成不仅是一种高效的训练任务,而且是一种可行的、可扩展的机器人控制代理(proxy)。
通过采用双重流匹配目标,本文框架能够同时优化视频合成和动作预测。这种协同作用使得动作策略能够直接从联合分布中导出轨迹,从而有效地将机器人控制与视频骨干网的生成动力学联系起来。
流匹配。流匹配 (FM) 旨在回归一个随时间变化的速度场 v_θ (x, τ),该速度场沿着噪声分布 p_1 = N (0, I ) 和数据分布 p_0 之间的概率路径传输样本(Lipman,2022)。流匹配的训练目标是最小化预测速度场 v_θ 与目标速度之间的预期 L2 距离。在推理过程中,采样是通过求解与学习的速度场 v_θ 相关的常微分方程 (ODE) 来实现的。该过程涉及从 τ = 1 处的噪声分布开始,向 τ = 0 处的数据分布对 v_θ进行积分。这里采用一阶欧拉离散化方法进行数值积分。
问题陈述。与当前 VLA 策略直接从观测值映射到动作(如 π_θ(a_t | o_t, l),其中 l 为语言目标)不同,DiT4DiT 遵循预测视频动态-逆动态的范式。具体来说,该任务是从视频 DiT 的推断中采样视频动态,并通过反转(reverse)采样的视频动态来预测动作。训练任务是对视频生成和动作生成的概率分布 (即 p_v 和 p_a)的联合概率分布 p_va 进行建模,例如 o_t+1, a_t ∼ p_va(· | o_t, l)。
双-DiT架构
DiT4DiT框架的概览如图所示: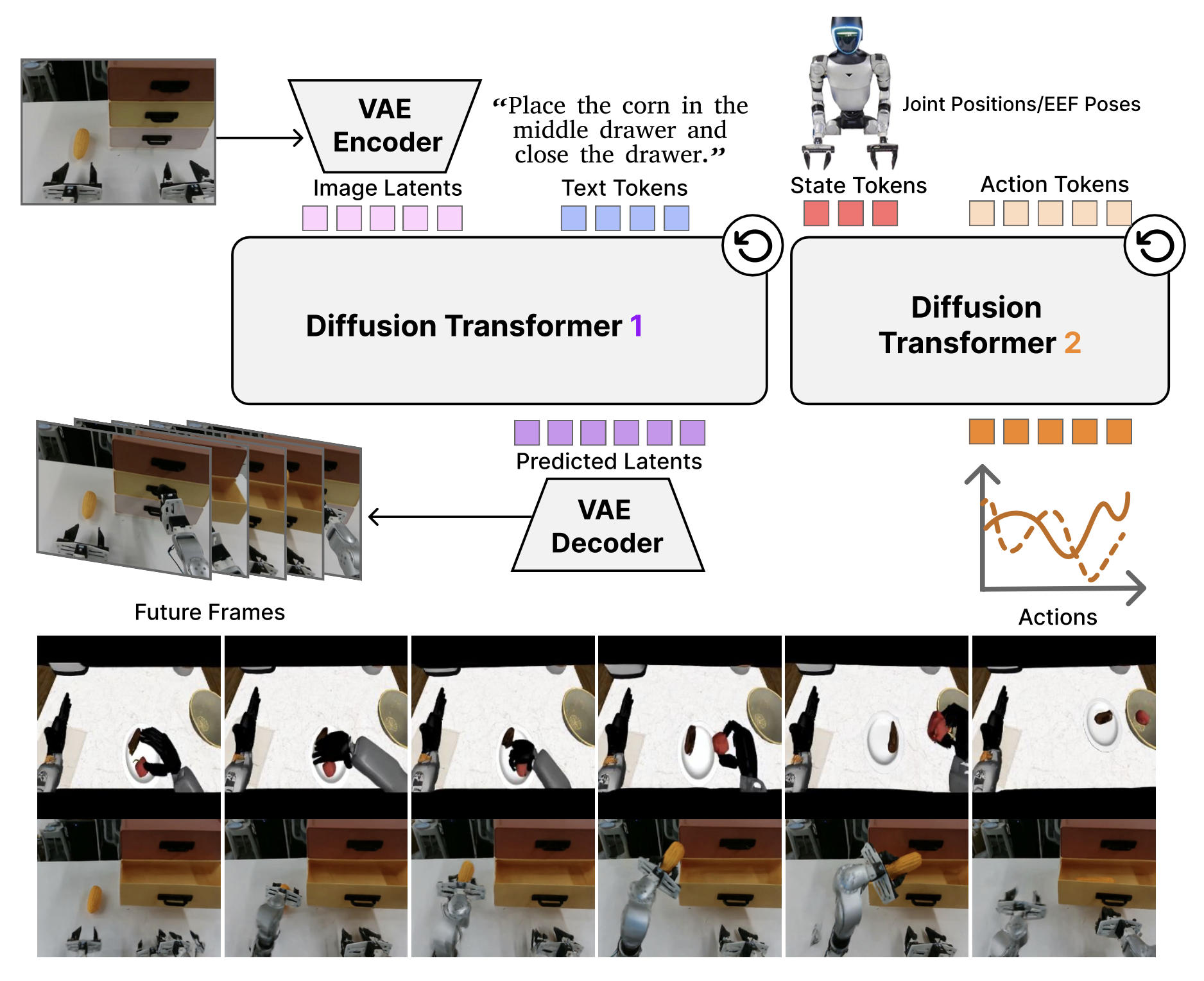
令 o_t 表示观测帧(条件输入),T_cond 表示条件帧的数量,o_t+1 表示真实未来帧,T_v 表示未来帧的范围。
视频 DiT。用 Cosmos-Predict2.5-2B(Ali,2025)作为视频骨干网络的初始化。该骨干网络由两个主要组件构成:一个因果视频 VAE 和一个视频扩散Transformer。时空 VAE 作为初始压缩阶段,通过显著的空间和时间下采样,将高维像素空间观测值 o_t 和 o_t+1 映射到紧凑的潜空间,分别记为 z0_t 和 z0_t+1。归一化的潜变量 z0_t 随后由 DiT 进行处理。DiT 采用流预测参数化,并通过 Cosmos-Reason1 的多层嵌入(Azzolini,2025)以语言指令为条件。关键在于,其并未直接使用最终的去噪视频输出,而是将 DiT(Peebles & Xie,2023)重新用作特征提取器:前向钩子(forward hook)机制拦截流时间步 τ_f 中的中间隐藏激活值(来自特定的深度 Transformer 模块或所有层的平均值),从而将生成过程转换为丰富的视觉tokens,供下游任务使用。
动作扩散Transformer (DiT)。为了将这些视觉表征解码为连续的机器人控制指令,采用一个专用的动作DiT,该变换器改编自 GR00T-N1(Bjorck,2025)。该组件作为一个独立的流匹配模型运行,由一系列Transformer模块堆叠而成,每个模块都利用自适应层归一化 (AdaLN)(Peebles & Xie,2023)注入扩散时间步信息,并利用交叉注意层来关注视频骨干网提取的视觉特征 hτ_f_t。该 DiT 的输入序列是本体感受状态嵌入、编码的噪声动作轨迹以及一组可学习的“未来tokens”的串联,这些“未来tokens”作为运动规划任务的压缩查询。通过交叉注意机制,动作头将时空视觉上下文与机器人的状态融合,从而将噪声输入细化为连贯的轨迹。该网络以线性投影结束,该投影预测动作序列的速度矢量场,从而允许在推理过程中通过迭代数值积分合成最终轨迹。
视频和动作的联合训练
为了实现视频和动作潜表征的同时建模,提出一种双流匹配机制。该方法将生成式视频预测和动作推理的逆动力学统一到一个学习范式中,并通过联合目标优化两个动态时间序列(DiT)。
三-时间步(Tri-timestep)方案。这种联合优化的核心挑战在于平衡生成建模和特征提取的不同需求。为了解决这个问题并实现视频和动作潜表征的同步建模,采用一种非对称的三-时间步方案,将视觉骨干网的扩散过程与动作模块的扩散过程解耦,如图所示。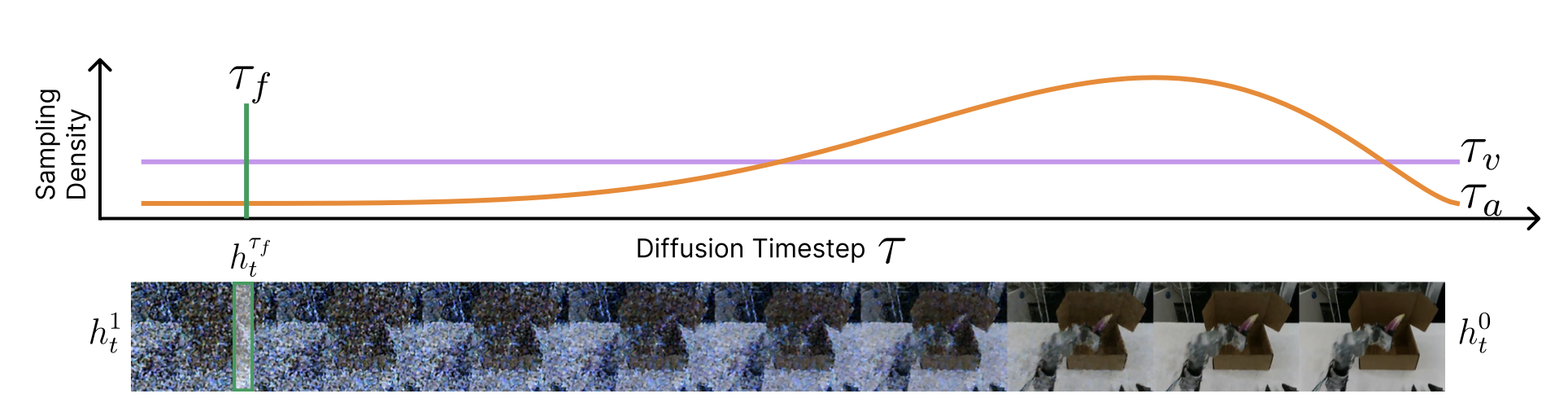
对于视频生成模块,遵循标准的扩散训练范式(NVIDIA,2025a;Ali,2025)。在每个训练步骤中,预测时间步 τ_v 从均匀分布 τ_v ∼ U [0, 1] 中随机采样。这使得模型暴露于所有噪声水平,迫使其学习合成未来帧所需的完整去噪轨迹。
相反,特征提取过程需要在迭代过程中保持确定性和一致性表征,以确保下游动作模块接收到稳定的输入信号。因此,在提取中间表征 hτ_f_t 时,以固定的时间步 τ_f 将上下文帧输入到去噪骨干网。这个固定的时间步长充当一个条件信号,用于选择骨干网络的特定“工作点”:早期扩散阶段强调全局结构,而后期阶段则关注细粒度的细节。通过固定这个值,稳定潜表征,从而在训练和推理过程中都能获得对下游动作预测始终有效的特征。
最后,动作 DiT 依赖于第三个独立的时间步长 τ_a。与采用均匀采样的视频生成模块不同,τ_a 在训练期间服从 Beta 分布(τ_a = 1 − σ,其中 σ ∼ Beta(α, β))。这种有偏连续时间采样策略将更多的训练资源分配给流轨迹中最关键的阶段。这种完全解耦使得动作解码器能够独立学习最优的逆动力学——将纯噪声映射到精确的动作——同时始终依赖于由固定特征提取时间步长 τ_f 提供的稳定视觉特征。
训练。如算法 1 所述,视频和动作的 DiT 模块被联合微调,以实现对视频和动作潜表征的同时建模。在训练过程中,文本编码器和视觉 VAE 被冻结,参数更新完全限制在 DiT 模块上,以使其适应目标域。基于这种双时间步设计,整体训练目标被表述为联合流匹配损失。
对于视频的流匹配目标,视频DiT训练通过vvideo_θ 来预测速度,其将当前观测值 z0_t 和语言目标 l 传递到未来潜状态。对于动作的流匹配目标,动作DiT学习将噪声动作映射到目标动作速度 ε-a0_t。关键在于,该动作预测以机器人本体感受状态 s 和从时间步 τ_f 的视频骨干网络中提取的隐特征 hτ_f_t 为条件。通过联合最小化这些目标,该框架确保视觉世界的生成动力学能够内在地支持复杂机器人动作的执行。
推理
在推理过程中,DiT4DiT 框架展现出高度灵活的生成能力,能够同时执行视频生成和动作预测。它执行一个解耦的采样过程,可以合成未来的视觉动态,推断精确的机器人控制指令,或者同时执行这两个任务,详见如下算法 2。
视频 DiT 采样。当需要合成未来的视觉动态时,该框架会激活视频生成路径。当前的观测值 o_t 通过冻结的 VAE 编码器被压缩成潜表示 z0_t。视频模型从标准的高斯噪声分布 zˆ_t+1 ∼ N (0, I) 开始,迭代地更新 N_v 个离散步骤的潜表示。在每个流步 τ_v 中,网络根据初始观测值 z0_t 和语言目标 l 预测速度场 vˆ。使用欧拉步规则更新潜变量,直至达到干净的未来状态,然后通过 VAE 解码器将其投影回像素空间,从而得到预测的未来帧 oˆ_t+1。
动作 DiT 采样。动作条件化并非依赖于完整视频生成循环的中间状态,而仅需一个确定性的特征提取步骤。对一个新的噪声潜变量进行采样,并在固定的特征提取时间步 τ_f 处严格执行一次视频骨干网络的前向传播。此步骤通过钩子(hook)机制 H 截获中间激活值,从而得到一个稳定且确定的隐表示 hτ_f_t。在建立视觉上下文后,动作轨迹由噪声 aˆ_t ∼ N (0, I) 初始化。经过 N_a 个数值积分步骤,动作 DiT 基于提取的生成特征 hτ_f_t 和机器人本体感觉状态 s 预测动作速度场。通过迭代改进轨迹,最终得到精确的预测动作 aˆ_t。
实验设置
LIBERO 基准测试。LIBERO 基准测试(Liu,2024)专注于 Franka Emika Panda 机械臂执行的操作任务。评估涵盖四个不同的测试套件——LIBERO-Spatial、LIBERO-Object、LIBERO-Goal 和 LIBERO-Long——旨在系统地测试模型在泛化到新的空间配置、与未见过的物体交互、解释语言指令以及执行扩展视野行为方面的能力。每个类别的标准数据集包含 500 条演示轨迹,均匀分布在 10 个不同的任务中。
RoboCasa-GR1 桌面基准测试。为了在更复杂的模型上进一步评估方法,采用 RoboCasa-GR1 桌面基准测试(Bjorck,2025;Nasiriany,2024)。该基准测试基于 RoboCasa 仿真框架,采用 Fourier GR1 人形机器人,该机器人配备两条 7 自由度机械臂、两只 6 自由度 Fourier 灵巧手和一条 3 自由度腰部,从而构成一个 29 维动作空间。视觉观察方面,策略完全依赖于机器人的自视摄像头。该测试套件包含 24 个不同的家庭操作任务,旨在评估策略处理各种活动的能力,这些活动涵盖从与铰接体的交互(例如,打开微波炉或橱柜)到使用新物体进行复杂的抓取和放置行为。标准数据集提供大量的远程操作演示,为 24 个任务中的每一个都提供 1000 条人工采集的轨迹。在评估过程中,每个任务都进行 50 次测试,每次测试的最大环境步数为 720。报告每个任务在多次部署中的平均成功率(%)以及所有 24 个任务的总体平均成功率。
真实世界的 G1 任务。为了验证方法在实际应用中的适用性,将策略部署在 Unitree G1 人形机器人上。该机器人系统具有连续的 16 自由度动作空间,由两个 7 自由度机械臂和 ALOHA2 夹爪驱动,并完全依赖机器人的自视(自视角)摄像头进行视觉观察。为了全面评估模型在各种物理交互和空间推理挑战中的鲁棒性,构建一个包含七项不同家庭操作任务的基准测试套件。如图所示,这些任务包括:“拾取和放置、摆放花朵、堆叠杯子、将盘子放入架子、包装盒、移动勺子和抽屉交互”。对于每项任务,收集包含 200 个人类演示片段的数据集。在评估阶段,对每项任务进行 20 次独立的实际部署,并将成功率作为主要指标进行评估。
策略设置和基线。为了严格评估所提出的 DiT4DiT 框架,将其与一系列最先进的策略进行基准测试,主要关注已建立的 GR00T 系列(Bjorck,2025;NVIDIA,2025b)以及一个自定义的、参数匹配的基线模型 Qwen3DiT。该基线方法结合 Qwen3-VL(Bai,2025)2B 基础模型和与 DiT4DiT 相同的动作 DiT。
对于模拟实验,从头开始训练 DiT4DiT 和 Qwen3DiT。这确保对它们固有的架构效率和学习能力进行严格公平的比较,而其余外部基线则使用其官方开源的预训练权重进行评估。
对于真实世界实验,采用两-阶段训练流程。 DiT4DiT 首先在模拟的 GR1 数据集(Bjorck,2025)的一个子集上进行预训练,该子集包含 241,450 个episodes,以获取基本的时空先验信息,然后在远程操作的真实 G1 演示数据集上进行微调。在此设置下,将方法与 GR00T-N1.5(Bjorck,2025)和 Qwen3DiT 进行比较。为了提供严格的消融,Qwen3DiT 采用与 DiT4DiT 完全相同的预训练和微调流程。相比之下,GR00T-N1.5 则使用其官方预训练权重进行初始化,受益于规模更大的先验数据,然后再在目标真实任务上进行微调。具体而言,预训练数据量仅为官方 GR00T-N1.5 模型所用训练数据规模的约 15%。
为了严格评估基础学习能力和物理部署可行性,将数据集的使用策略性地划分为两个不同的流程:一个用于模拟基准测试评估,另一个用于实际部署。
模拟基准测试数据:为了在模拟环境中评估该框架,直接在目标数据集上训练模型。对于 RoboCasa-GR1(Nasiriany,2024)桌面任务,用 Fourier GR1 Unified 1K 数据集(Bjorck,2025),该数据集包含 24,000 个演示片段,这些片段使用高度复杂的 29 自由度 GR1 人形机器人采集。对于 LIBERO(Liu,2024)基准测试,用其官方数据集,该数据集包含 1,693 个片段,基于 7 自由度 Franka Emika Panda 机械臂。由于无法访问各种方法的全部预训练数据集,因此在这些数据集上从头开始训练可以确保在模拟环境中与基线方法进行严格公平的评估。
真实任务的预训练数据:为了便于稳健的物理部署,DiT4DiT 需要经过一个关键的预训练阶段,以获取基本的时空和物理先验信息。在此阶段,用规模化的 Fourier GR1 Pretrain 10K 数据集(Bjorck,2025),该数据集包含 29 自由度 GR1 机器人的 241,450 个训练片段。该预训练数据集仅占基线模型(例如 GR00T-N1.5)所利用的海量数据的 15%,这充分体现生成式视频骨干网络的数据效率。
真实世界微调数据:预训练完成后,将对模型进行微调,使其生成先验信息适应目标物理机器人。在此阶段,用定制的真实机器人数据集,该数据集包含1400个高质量的远程操控演示片段(每个任务200个片段)。该数据集专为Unitree G1人形机器人量身定制,可在连续的16自由度动作空间内运行。这一关键的微调阶段成功地将基于仿真的广泛物理动力学转化为精确的、真实世界的连续控制指令。
如图所示,真实世界实验系统基于 Unitree G1 人形机器人构建,该机器人具有 16 自由度的动作空间,由两个 7 自由度机械臂驱动。每个机械臂都配备一个 ALOHA 2(Aldaco,2024)夹爪,以实现高精度的双手操作。视觉感知方面,机器人头部安装一台 Intel RealSense D435i 摄像头,用于以 640x480 分辨率捕捉以机器人自身为中心的 RGB 图像。实时推理在一台配备单块 NVIDIA GeForce RTX 4090 GPU 的工作站上执行。
数据采集通过基于 VR 的远程操作流程完成,该流程使用 PICO VR 头显和手持控制器。这种设置允许操作者通过将动作直接映射到机器人的关节上,从而提供自然流畅的演示。 XRoboToolkit(Zhao,2025)框架管理整个软件栈,确保多模态传感器数据的精确同步和演示轨迹的高质量记录。该集成环境支持从人工数据采集到自主策略部署的无缝过渡。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献127条内容
已为社区贡献127条内容

所有评论(0)