本地视频语义检索工具 VideoSeek,支持以图搜视频、文本搜视频、片段预览与本地索引
本地视频语义检索工具 VideoSeek:支持以图搜视频、文本搜视频、片段预览与本地索引
最近我做了一个桌面端项目 VideoSeek。
它主要解决一个很实际的问题:
计算机干宣传岗,存于本地视频越来越多,而且都是自己拍的网上找不到,某次领导要我必须用某些画面的视频,就给了我一张截图,而我光靠画面和我那残存的记忆已无能为力,但由于我学过计算机视觉相关的一些知识…
于是我做了一个本地视频语义检索工具,支持:
- 文本搜视频
- 图片搜视频
- 本地视频库管理
- 视频片段预览
- 本地向量索引
- 远程公告和版本检查
这篇文章想完整记录一下这个项目的设计思路、技术实现、踩坑过程,以及我后面是怎么把它从“能跑”整理成“能发布”的。
一、项目能做什么
VideoSeek 是一个本地桌面工具,核心能力是:
1. 文本检索视频
输入一句自然语言描述,例如:
- 夜晚街道上一个人独自行走
- 动漫角色特写镜头
- 大量人物奔跑打斗的场景
系统会把文字编码成向量,然后到本地视频库里搜索最相似的画面片段。
2. 图片检索视频
除了文字,也支持直接上传一张图作为查询条件,做“以图搜视频”。
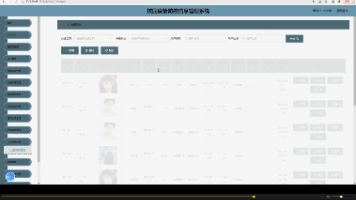
3. 本地视频库管理
支持在界面中维护多个视频目录,并且可以:
- 添加库
- 删除库
- 单库同步
- 全量更新索引
- 直接打开库目录
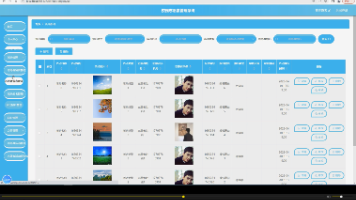
4. 命中片段预览
搜索结果不只是告诉你“在哪个文件”,而是可以直接生成短片段进行预览,确认效率高很多。
5. 参数设置
很多核心参数都可以直接调:
- 索引抽帧频率
- 搜索返回数量
- 预览时长
- 预览分辨率
- 缩略图尺寸
- FFmpeg 路径
二、项目演示
索引生成:
反击的巨兽每集24分钟,1秒1帧抽帧+生成向量+生成索引,耗时在1分钟左右
搜索演示:
搜索只需要一两毫秒!!!
三、项目技术栈
这个项目本质上是一个“桌面 UI + 多媒体处理 + 向量检索”的组合,主要技术栈如下:
PySide6:桌面 UIONNX Runtime:运行 CLIP 模型FAISS:向量索引与相似度检索OpenCV:图像读取与处理FFmpeg:抽帧、预览片段生成
四、整体实现思路
整体流程可以拆成 4 步:
1. 视频抽帧
先从本地视频中按一定频率抽取关键帧。
2. 特征提取
把每一帧送入 CLIP 视觉编码器,得到向量表示。
3. 建立索引
把这些向量保存下来,并构建 FAISS 索引。
4. 查询匹配
当用户输入文本或图片后,同样编码成向量,再去索引中做最近邻搜索。
可以简单理解成这样:
视频 -> 抽帧 -> 图像向量 -> FAISS索引
文本/图片 -> 查询向量 -> 相似度搜索 -> 命中片段
五、关键代码实现
1. 视频抽帧
项目里抽帧是通过 FFmpeg 做的。这样比很多纯 Python 解码方式更稳,也更适合生成后续预览片段。
def extract_frames_with_ffmpeg(video_path):
config = load_config()
fps = config.get("fps", 1)
cap = cv2.VideoCapture(video_path)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
cap.release()
if width <= 0 or height <= 0:
return [], []
ffmpeg_bin = get_ffmpeg_path()
command = [
ffmpeg_bin,
"-i",
video_path,
"-vf",
f"fps={fps}",
"-sn",
"-f",
"image2pipe",
"-pix_fmt",
"bgr24",
"-vcodec",
"rawvideo",
"-",
]
这里的 fps 含义很明确:
每秒抽取多少帧用于建索引。
例如 fps = 1,就是每秒抽 1 帧。
2. 图像编码
抽出来的帧会送到 CLIP ONNX 模型中编码:
class CLIPOnnxEngine:
def __init__(self):
providers = ["CUDAExecutionProvider", "CPUExecutionProvider"]
self.visual_session = ort.InferenceSession(
get_resource_path("models/clip_visual.onnx"),
providers=providers,
)
self.text_session = ort.InferenceSession(
get_resource_path("models/clip_text.onnx"),
providers=providers,
)
def encode_images(self, frames):
embeddings = []
for frame in frames:
blob = self._preprocess(frame)
feat = self.visual_session.run(None, {"input": blob})[0].astype(np.float32)
feat /= (np.linalg.norm(feat, axis=-1, keepdims=True) + 1e-10)
embeddings.append(feat)
return np.vstack(embeddings)
文本查询则走文本编码器:
def get_text_embedding(text):
return engine.encode_text(text)
3. 建立向量索引
使用 FAISS 构建全局索引:
@measure_time("Index build time:")
def create_clip_index(vectors_list, index_file):
vectors = np.asarray(vectors_list, dtype="float32")
vectors = np.asarray([
vector / np.linalg.norm(vector) if np.linalg.norm(vector) != 0 else vector
for vector in vectors
], dtype="float32")
index = faiss.IndexFlatIP(vectors.shape[1])
index.add(vectors)
faiss.write_index(index, index_file)
return index
4. 结果搜索
搜索时的逻辑也比较直接:
def search_vector(query_vector, index, timestamps, video_paths, top_k=10):
actual_k = min(top_k, index.ntotal)
if actual_k <= 0:
return []
distances, indices = index.search(query_vector, actual_k)
matched_results = []
for rank, index_value in enumerate(indices[0]):
if index_value == -1 or index_value >= len(video_paths):
continue
timestamp = timestamps[index_value]
video_path = video_paths[index_value]
matched_results.append((timestamp, timestamp, distances[0][rank], video_path))
return matched_results
最终拿到的是:
命中的时间戳 、相似度分数 、原始视频路径
六、项目重构:从“能跑”到“能维护”
其实这个项目一开始并没有现在这么整洁。
最早版本的问题很典型:
- UI、索引、搜索、配置全写在一层
- 改一个按钮,容易牵到业务逻辑
- 加功能时越来越难维护
- 一些历史文件还混着编码污染
- 使用的是pytorch打包后安装包高达3个G
后来我使用codex辅助做了一系列比较大的结构整理,把代码重新分层,重构了项目。改用onnx runtime最后将安装包减小到500MB左右。
七、结语
VideoSeek 从最开始的一个想法,逐渐做成了一个完整的桌面应用:
- 有搜索能力
- 有索引能力
- 有预览能力
- 有多页 UI
- 有设置系统
- 有远程公告
- 有版本检查
也有一套清晰得多的工程结构
这类项目最有意思的地方就在于:
它不只是“技术能不能做出来”,而是“能不能真的变成一个好用的工具”。
如果你也在做本地 AI 工具、桌面应用,或者也对视频检索方向感兴趣,欢迎交流,最后跪谢codex,给我完善项目帮大忙了,巨好用,强烈推荐!!!
八、项目链接
GitHub:https://github.com/O-O-O-O-O-O-O-O-O-O-O-O-O-O-O-O/VideoSeek
直接下载安装包:
1、Gitee Release: https://gitee.com/lIlIlIlIlIlIlIlIlIlIlIlIl/VideoSeek/releases
2、GitHub Release: https://gitee.com/O-O-O-O-O-O-O-O-O-O-O-O-O-O-O-O//VideoSeek/releases

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)