从零起步学习AI大模型应用开发 || 第二章:RAG在AI应用开发中的作用及实战讲解
AI 知识问答应用场景
随着 AI 技术的快速发展,越来越多的公司开始利用 AI 重构传统业务,打造全新的用户体验和商业价值。其中,AI 知识问答是一个典型应用场景,广泛运用到教育、电商、咨询等行业,比如:
- 教育场景:AI 针对学生的薄弱环节提供个性化辅导
- 电商场景:AI 根据用户肤质推荐适合的护肤方案
- 法律咨询:AI 能解答法律疑问,节省律师时间
- 金融场景:AI 为客户提供个性化理财建议
- 医疗场景:AI 辅助医生进行初步诊断咨询
说白了,就是让 AI 利用特定行业的知识来服务客户,实现降本增效。其中,知识的来源可能来源于网络,也可能是自己公司私有的数据,从而让 AI 提供更精准的服务。
如何让 AI 获取知识?
在实现这个需求前,我们需要思考一个关键问题:知识从哪里获取呢?
首先 AI 原本就拥有一些通用的知识,对于不会的知识,还可以利用互联网搜索。但是这些都是从网络获取的、公开的知识。对于企业来说,数据是命脉,也是自己独特的价值,随着业务的发展,企业肯定会积累一波自己的知识库,如果让 AI 能够利用这些知识库进行问答,效果可能会更好,而且更加个性化。
如果不给 AI 提供特定领域的知识库,AI 可能会面临这些问题:
- 知识有限:AI 不知道你的最新课程和内容
- 编故事:当 AI 不知道答案时,它可能会 “自圆其说” 编造内容
- 无法个性化:不了解你的特色服务和回答风格
- 不会推销:不知道该在什么时候推荐你的付费课程和服务
那么如何让 AI 利用自己的知识库进行问答呢?这就需要用到 AI 主流的技术 —— RAG。
RAG 概念
什么是 RAG?
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索技术和 AI 内容生成的混合架构,可以解决大模型的知识时效性限制和幻觉问题。
简单来说,RAG 就像给 AI 配了一个 “小抄本”,让 AI 回答问题前先查一查特定的知识库来获取知识,确保回答是基于真实资料而不是凭空想象。
从技术角度看,RAG 在大语言模型生成回答之前,会先从外部知识库中检索相关信息,然后将这些检索到的内容作为额外上下文提供给模型,引导其生成更准确、更相关的回答。
通过 RAG 技术改造后,AI 就能:
- 准确回答关于特定内容的问题
- 在合适的时机推荐相关课程和服务
- 用特定的语气和用户交流
- 提供更新、更准确的建议
可以简单了解下 RAG 和传统 AI 模型的区别:
| 特性 | 传统大语言模型 | RAG 增强模型 |
|---|---|---|
| 知识时效性 | 受训练数据截止日期限制 | 可接入最新知识库 |
| 领域专业性 | 泛化知识,专业深度有限 | 可接入专业领域知识 |
| 响应准确性 | 可能产生 “幻觉” | 基于检索的事实依据 |
| 可控性 | 依赖原始训练 | 可通过知识库定制输出 |
| 资源消耗 | 较高(需要大模型参数) | 模型可更小,结合外部知识 |
RAG 工作流程
RAG 技术实现主要包含以下 4 个核心步骤,让我们分步来学习:
- 文档收集和切割
- 向量转换和存储
- 文档过滤和检索
- 查询增强和关联
1、文档收集和切割
文档收集:从各种来源(网页、PDF、数据库等)收集原始文档
文档预处理:清洗、标准化文本格式
文档切割:将长文档分割成适当大小的片段(俗称 chunks)
- 基于固定大小(如 512 个 token)
- 基于语义边界(如段落、章节)
- 基于递归分割策略(如递归字符 n-gram 切割)
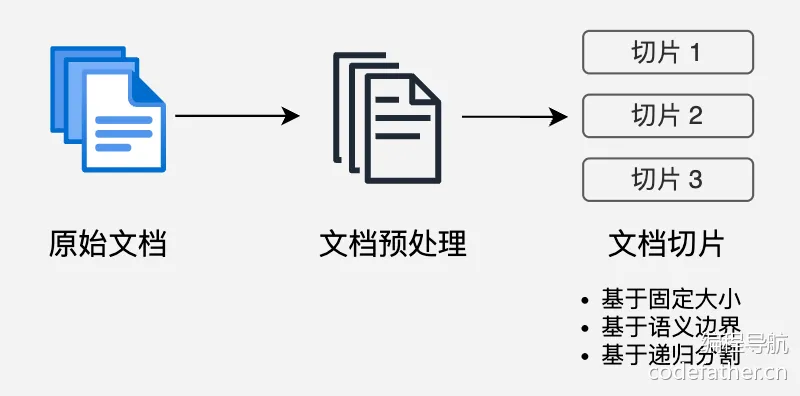
2、向量转换和存储
向量转换:使用 Embedding 模型将文本块转换为高维向量表示,可以捕获到文本的语义特征
向量存储:将生成的向量和对应文本存入向量数据库,支持高效的相似性搜索
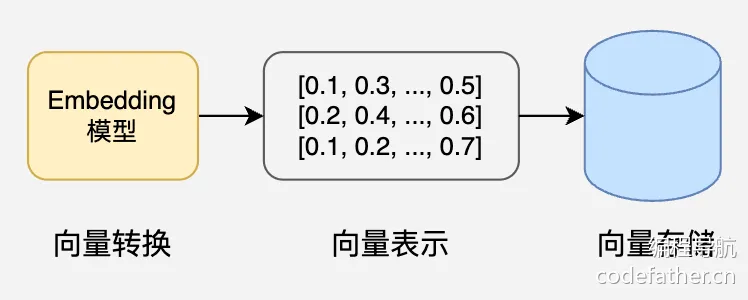
3、文档过滤和检索
查询处理:将用户问题也转换为向量表示
过滤机制:基于元数据、关键词或自定义规则进行过滤
相似度搜索:在向量数据库中查找与问题向量最相似的文档块,常用的相似度搜索算法有余弦相似度、欧氏距离等
上下文组装:将检索到的多个文档块组装成连贯上下文
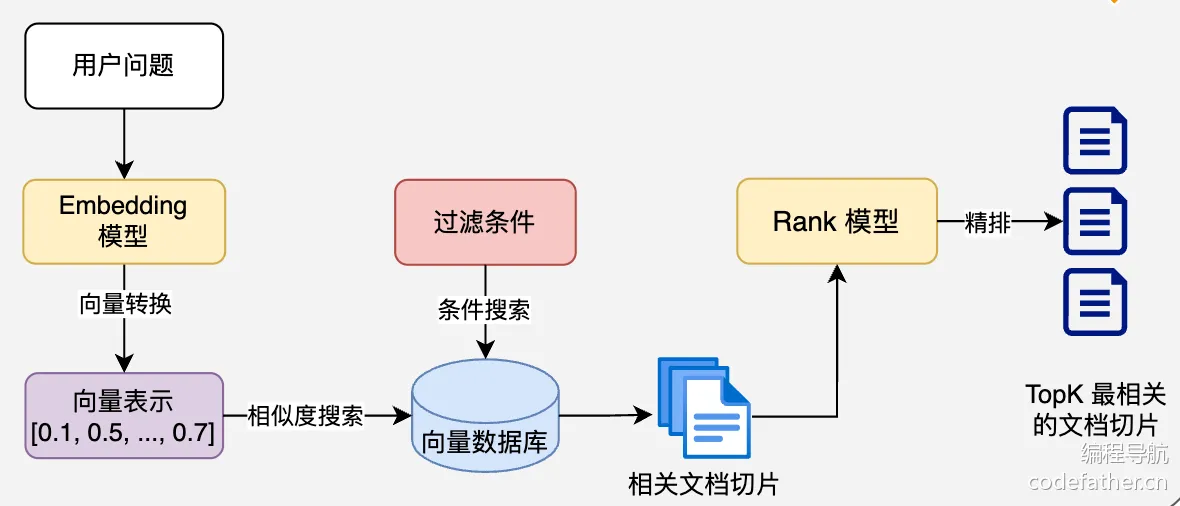
4、查询增强和关联
提示词组装:将检索到的相关文档与用户问题组合成增强提示
上下文融合:大模型基于增强提示生成回答
源引用:在回答中添加信息来源引用
后处理:格式化、摘要或其他处理以优化最终输出
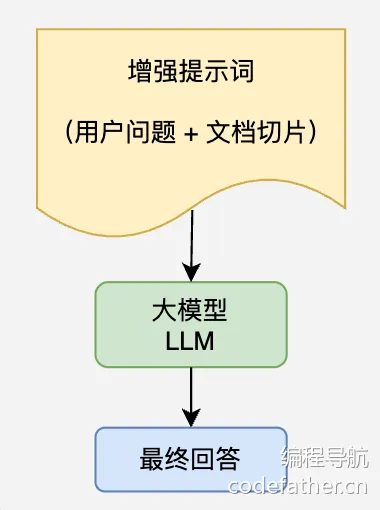
完整工作流程
分别理解上述 4 个步骤后,我们可以将它们组合起来,形成完整的 RAG 检索增强生成工作流程:
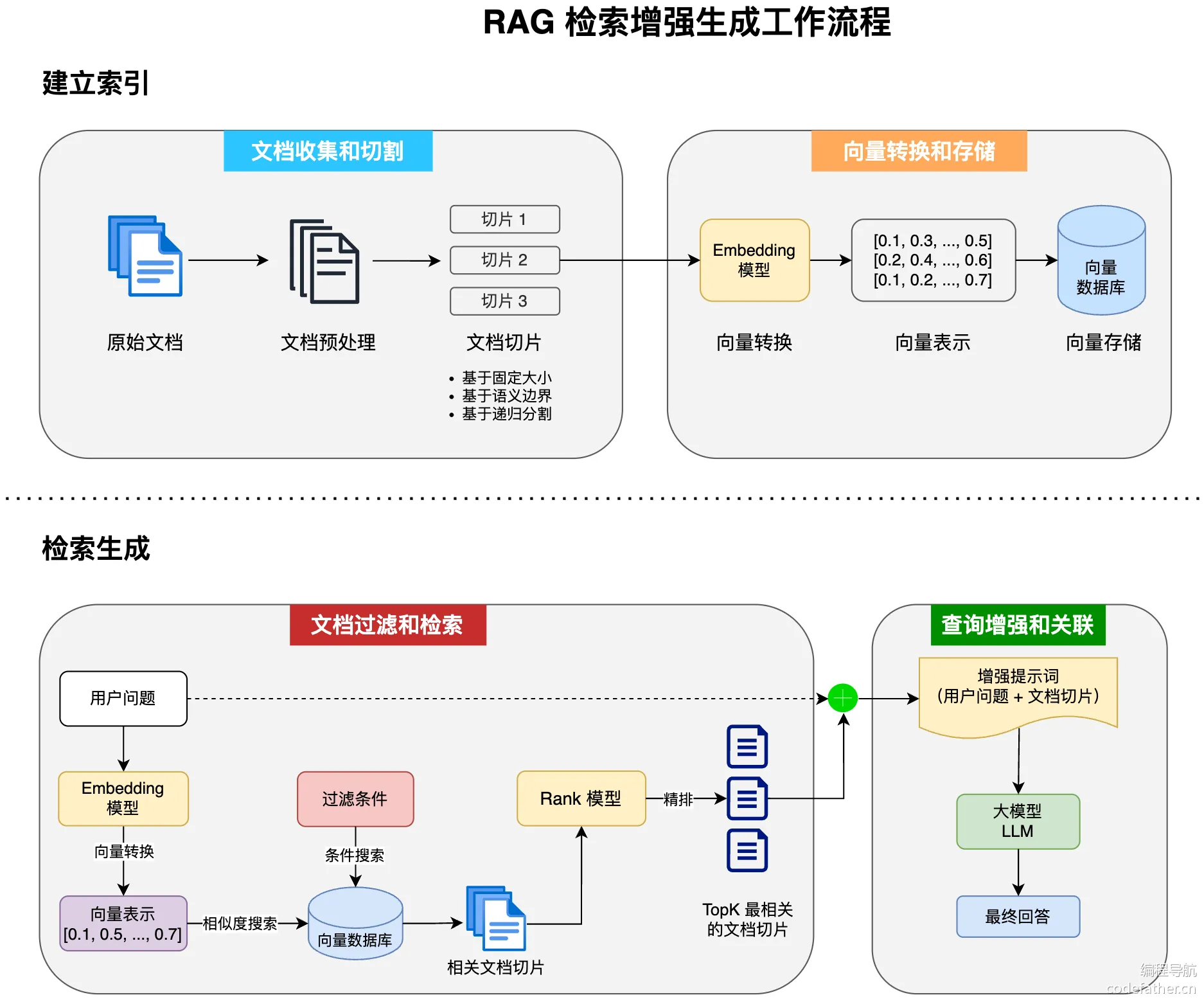
上述工作流程中涉及了很多技术名词,让我们分别进行解释。
RAG 相关技术
Embedding 和 Embedding 模型
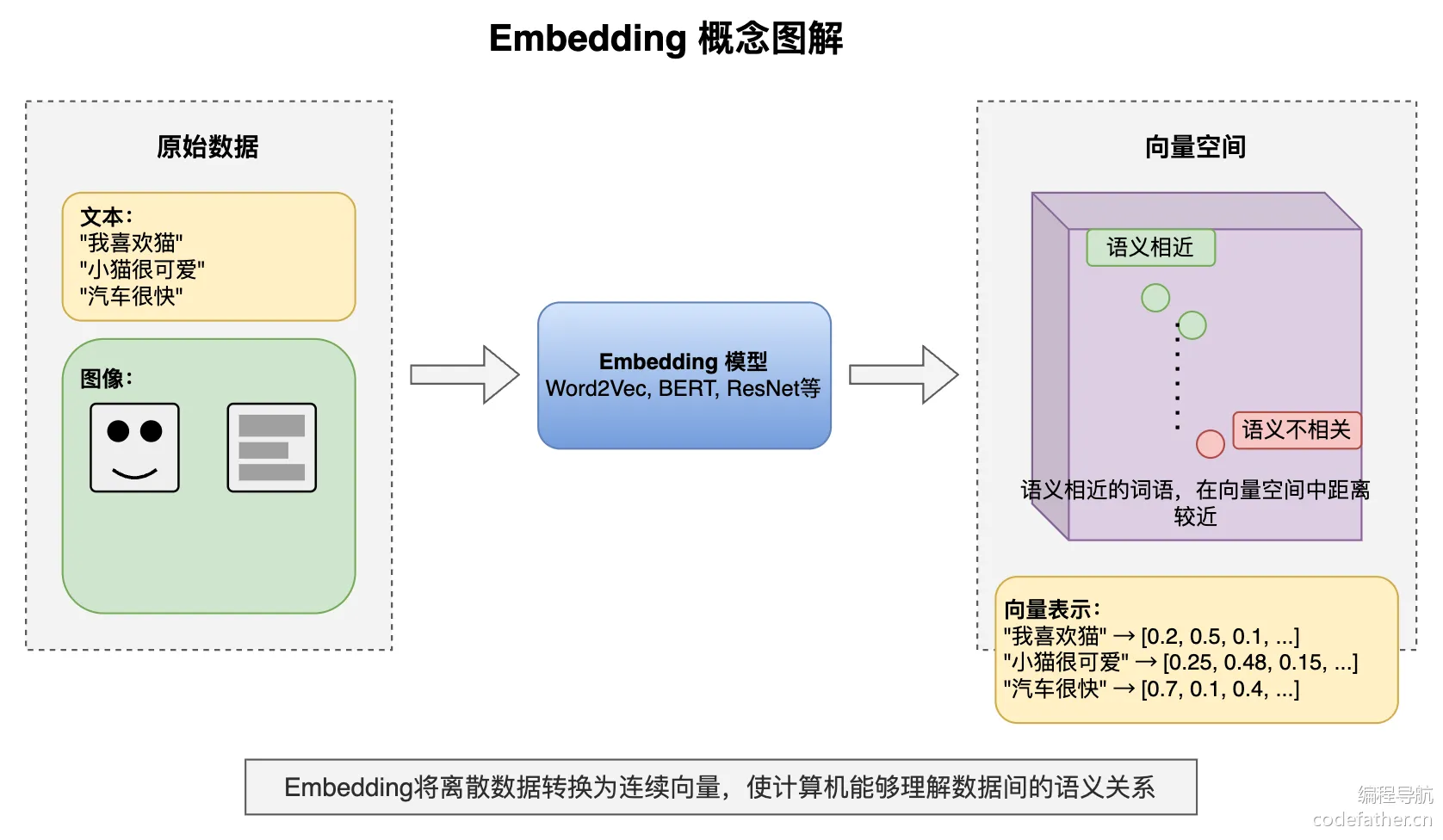
Embedding 嵌入是将高维离散数据(如文字、图片)转换为低维连续向量的过程。这些向量能在数学空间中表示原始数据的语义特征,使计算机能够理解数据间的相似性。
Embedding 模型是执行这种转换算法的机器学习模型,如 Word2Vec(文本)、ResNet(图像)等。不同的 Embedding 模型产生的向量表示和维度数不同,一般维度越高表达能力更强,可以捕获更丰富的语义信息和更细微的差别,但同样占用更多存储空间。
举个例子,“鱼皮” 和 “鱼肉” 的 Embedding 向量在空间中较接近,而 “鱼皮” 和 “帅哥” 则相距较远,反映了语义关系。
向量数据库
向量数据库是专门存储和检索向量数据的数据库系统。通过高效索引算法实现快速相似性搜索,支持 K 近邻查询等操作。

注意,并不是只有向量数据库才能存储向量数据,只不过与传统数据库不同,向量数据库优化了高维向量的存储和检索。
AI 的流行带火了一波向量数据库和向量存储,比如 Milvus、Pinecone 等。此外,一些传统数据库也可以通过安装插件实现向量存储和检索,比如 PGVector、Redis Stack 的 RediSearch 等。
用一张图来了解向量数据库的分类:

召回
召回是信息检索中的第一阶段,目标是从大规模数据集中快速筛选出可能相关的候选项子集。强调速度和广度,而非精确度。
举个例子,我们要从搜索引擎查询 “编程导航 - 程序员一站式编程学习交流社区” 时,召回阶段会从数十亿网页中快速筛选出数千个含有 “编程”、“导航”、“程序员” 等相关内容的页面,为后续粗略排序和精细排序提供候选集。
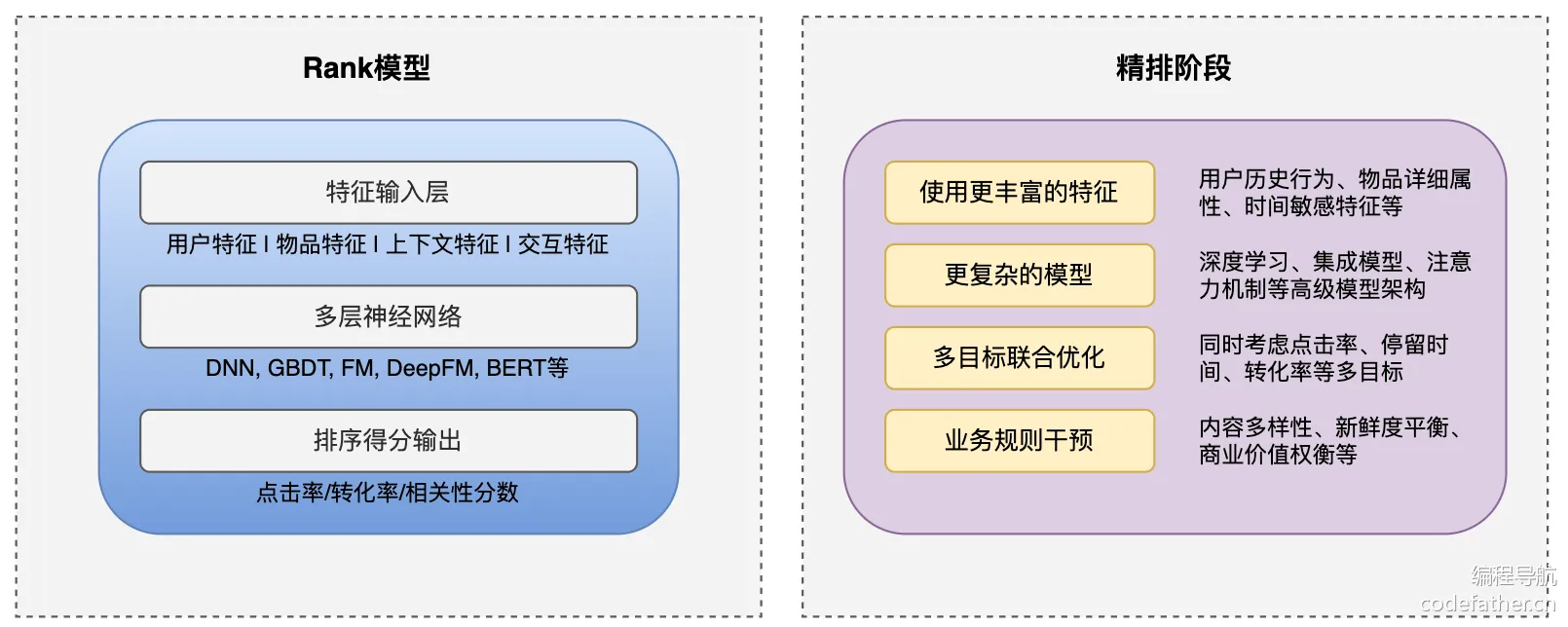
精排和 Rank 模型
精排(精确排序)是搜索 / 推荐系统的最后阶段,使用计算复杂度更高的算法,考虑更多特征和业务规则,对少量候选项进行更复杂、精细的排序。
比如,短视频推荐先通过召回获取数万个可能相关视频,再通过粗排缩减至数百条,最后精排阶段会考虑用户最近的互动、视频热度、内容多样性等复杂因素,确定最终展示的 10 个视频及顺序。

Rank 模型(排序模型)负责对召回阶段筛选出的候选集进行精确排序,考虑多种特征评估相关性。
现代 Rank 模型通常基于深度学习,如 BERT、LambdaMART 等,综合考虑查询与候选项的相关性、用户历史行为等因素。举个例子,电商推荐系统会根据商品特征、用户偏好、点击率等给每个候选商品打分并排序。
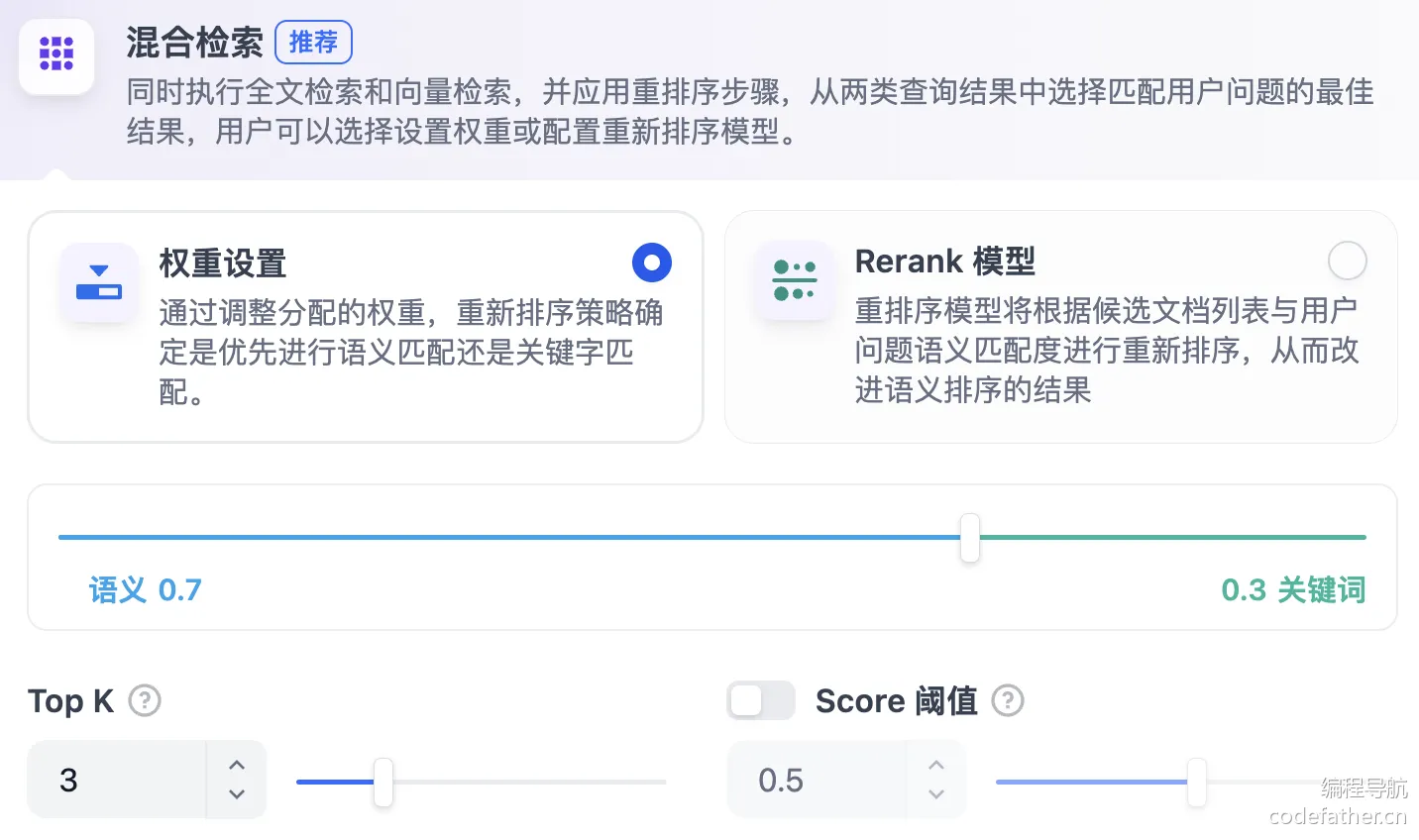
混合检索策略
混合检索策略结合多种检索方法的优势,提高搜索效果。常见组合包括关键词检索、语义检索、知识图谱等。
比如在 AI 大模型开发平台 Dify 中,就为用户提供了 “基于全文检索的关键词搜索 + 基于向量检索的语义检索” 的混合检索策略,用户还可以自己设置不同检索方式的权重。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 17
17 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)