基于LDA主题模型与情感分析的航空客户满意度分析
基于LDA主题模型与情感分析的航空客户满意度分析
项目说明文档
版本:v1.0
最后更新:2026-03-23
文档作者:项目开发团队
第一章 项目概述
1.1 系统简介
航空公司客户满意度分析系统是一个基于自然语言处理(NLP)和机器学习技术的智能化分析平台。系统通过LDA主题模型和情感分析技术,对大量航空评论数据进行深度挖掘,自动识别客户关注的核心主题,量化评估客户情感倾向,并生成多维度的满意度分析报告,为航空公司提供数据驱动的服务改进决策支持。
1.2 核心价值
- 🎯 自动化分析:替代传统人工统计,自动处理海量评论数据
- 📊 多维度洞察:从主题、情感、时间等多个维度分析客户满意度
- 🔍 问题发现:快速识别服务短板和客户痛点
- 📈 趋势预测:追踪满意度变化趋势,及时预警服务问题
- 💡 决策支持:为管理层提供数据驱动的改进建议
1.3 应用场景
1.3.1 航空公司服务管理
- 监控各航线服务质量
- 识别客户投诉热点
- 评估服务改进效果
- 制定服务提升策略
1.3.2 市场竞争分析
- 对比不同航司服务水平
- 分析竞争对手优劣势
- 发现市场机会点
- 制定差异化竞争策略
1.3.3 管理决策支持
- 提供量化的数据依据
- 生成定期分析报告
- 预警服务质量下滑
- 支持战略规划制定
第二章 背景与问题分析
2.1 行业背景
2.1.1 在线评论的兴起
随着互联网和社交媒体的快速发展,在线评论已成为客户表达服务体验的重要渠道。航空公司每天都会收到来自携程、去哪儿、飞猪等平台的大量客户评论,这些评论蕴含着丰富的客户需求和服务反馈信息。
2.1.2 数据价值的挖掘需求
- 评论数据量级:每家大型航司每天可能收到数百到数千条评论
- 数据维度丰富:涵盖服务、餐食、准点、舒适度等多个方面
- 时效性要求:需要及时响应客户反馈,快速改进服务
- 决策需求:管理层需要数据支撑进行决策
2.2 传统方法的局限性
2.2.1 人工分析效率低下
存在问题:
- 评论数量庞大,人工阅读和统计耗时费力
- 难以及时响应客户反馈
- 主观性强,缺乏客观量化标准
- 无法处理大规模历史数据
影响:
- 分析周期长,时效性差
- 人力成本高
- 分析深度有限
- 容易遗漏重要信息
2.2.2 调查问卷样本受限
存在问题:
- 问卷回收率低,样本代表性不足
- 固定问题设计可能遗漏重要信息
- 成本高,周期长
- 难以持续追踪
影响:
- 数据覆盖面窄
- 缺少客户真实想法
- 无法发现潜在问题
- 难以形成趋势分析
2.2.3 缺乏系统化分析
存在问题:
- 难以发现评论中的潜在主题
- 无法量化情感倾向
- 缺少历史数据对比和趋势分析
- 分析结果难以可视化呈现
影响:
- 无法深入理解客户需求
- 缺少量化评估标准
- 难以追踪改进效果
- 决策缺乏数据支撑
2.3 技术驱动的解决方案
本系统采用自然语言处理和机器学习技术,实现:
- ✅ 自动化的大规模文本数据处理
- ✅ 基于LDA的无监督主题发现
- ✅ 深度学习驱动的情感分析
- ✅ 多维度的可视化分析展示
第三章 解决的核心问题
3.1 评论数据管理问题
3.1.1 问题描述
- 评论数据分散在不同平台,缺乏统一管理
- 数据格式不统一,难以整合分析
- 历史数据积累困难,无法追溯分析
- 缺少数据备份和版本管理
3.1.2 解决方案
统一数据管理平台:
- 提供集中式的评论数据存储
- 支持Excel批量导入,快速录入数据
- 自动化数据采集接口(可扩展)
- 结构化存储,便于检索和分析
多维度数据检索:
- 按航司、航线、评分筛选
- 按时间范围查询
- 支持关键词搜索
- 数据导出功能
3.2 客户关注点识别问题
3.2.1 问题描述
- 不知道客户真正关心什么
- 无法区分主要问题和次要问题
- 缺少对客户需求的系统性理解
- 难以发现隐藏的服务问题
3.2.2 解决方案
LDA主题模型自动识别:
- 无监督学习,自动发现潜在主题
- 计算主题权重,区分主要和次要关注点
- 提取主题关键词,直观展示客户关注内容
- 支持主题趋势分析,追踪关注点变化
典型主题示例:
- 主题1:服务质量(空姐、服务、态度、热情、周到)
- 主题2:准点性(延误、准点、时间、起飞、降落)
- 主题3:餐食质量(餐食、飞机餐、好吃、美味、难吃)
- 主题4:座位舒适度(座位、舒适、空间、挤、宽敞)
- 主题5:地勤服务(值机、托运、行李、地勤、排队)
3.3 情感倾向量化问题
3.3.1 问题描述
- 难以准确判断评论是正面还是负面
- 无法量化客户满意度水平
- 缺少情感强度的细粒度区分
- 复杂情感表达(讽刺、隐含)识别困难
3.3.2 解决方案
智能情感分析引擎:
- 基于SnowNLP的中文情感分析
- 三分类情感标注(正面/负面/中性)
- 0-1连续情感评分,精确量化情感强度
- 归一化分数(-1到1),便于对比分析
分析能力:
- 批量情感分析,处理海量数据
- 实时测试功能,即时验证
- 情感趋势追踪
- 多维度情感对比
3.4 满意度评估问题
3.4.1 问题描述
- 缺乏综合性的满意度评估体系
- 无法对比不同航司的服务水平
- 难以识别满意度变化趋势
- 缺少多维度的分析视角
3.4.2 解决方案
多维度满意度评估体系:
综合评分算法:
满意度 = (评分标准化 × 0.5 + 正面情感占比 × 0.5) × 100%
分析维度:
- 航司维度:各航空公司满意度排名和对比
- 航线维度:热门航线满意度分析
- 主题维度:各主题的满意度水平
- 时间维度:满意度随时间的变化趋势
分析功能:
- 满意度排名
- 趋势分析
- 对比分析
- 原因挖掘
3.5 决策支持问题
3.5.1 问题描述
- 分析结果难以直观理解
- 缺少针对性的改进建议
- 无法快速定位服务短板
- 难以向管理层汇报
3.5.2 解决方案
可视化分析展示:
- 丰富的图表类型(柱状图、饼图、折线图、堆叠图)
- 交互式数据探索
- 多维度数据钻取
- 响应式设计,适配各种设备
智能报告生成:
- 自动生成分析报告
- 提供改进建议
- 关键发现提炼
- 支持报告导出和分享
第四章 核心功能说明
4.1 评论数据管理
4.1.1 功能概述
提供完整的航空评论数据管理能力,是系统的数据基础。
4.1.2 核心特性
数据录入:
- 手动添加评论记录
- Excel批量导入(支持.xlsx/.xls格式)
- 自动解析Excel列映射
- 数据格式验证和错误提示
数据查询:
- 多条件组合搜索
- 航空公司筛选
- 航线筛选
- 评分范围筛选
- 日期范围选择
- 关键词搜索
数据展示:
- 分页列表展示
- 排序功能
- 详情查看
- 预处理状态标识
数据操作:
- 单条删除
- 批量删除
- 数据导出(Excel格式)
- 数据统计
4.1.3 技术实现
- Spring Data JPA 数据持久化
- EasyExcel 处理Excel导入导出
- 分页查询优化大数据量展示
- 索引优化提升查询性能
4.2 数据预处理
4.2.1 功能概述
对原始评论文本进行清洗和标准化处理,为后续分析提供高质量的数据输入。
4.2.2 处理流程
第一步:文本清洗
- 去除HTML标签
- 去除URL链接
- 去除邮箱地址
- 去除特殊字符
- 统一全角/半角字符
- 去除多余空格
第二步:中文分词
- 使用jieba分词器
- 精确模式分词
- 保留词性信息(可选)
- 应用自定义词典
第三步:停用词过滤
- 移除常见停用词(的、了、在等)
- 保留有意义的实词
- 保留否定词
- 保留程度副词
第四步:自定义词典
航空领域专业术语(33个):
空姐、空乘、头等舱、经济舱、商务舱、值机、登机、延误、
准点、航班、飞机、座位、行李、托运、安检、候机、起飞、
降落、机长、乘务员、餐食、机票、改签、退票、超售、晚点、
取消、航空公司、航线、机场、航站楼、登机口、转机
4.2.3 功能特点
批量处理:
- 可配置批次大小(10-1000条)
- 实时进度显示
- 支持中断和恢复
- 错误日志记录
单条测试:
- 实时预处理
- 立即查看结果
- 分词效果展示
- 便于调试和验证
4.2.4 技术实现
- Python jieba分词库
- 自定义航空领域词典
- 批量处理优化
- 结果持久化存储
4.3 LDA主题模型分析
4.3.1 功能概述
使用LDA(Latent Dirichlet Allocation)主题模型自动发现评论中的潜在主题,识别客户关注点。
4.3.2 核心功能
模型训练:
- 基于预处理数据训练LDA模型
- 可配置主题数量(2-20个)
- 可配置训练迭代次数(1-50次)
- 可配置每次迭代轮数(10-500轮)
- 实时显示训练进度
模型评估:
- 计算困惑度(Perplexity)
- 计算一致性分数(Coherence Score)
- 评估模型质量
- 辅助参数调优
最优主题数搜索:
- 自动测试多个主题数
- 绘制困惑度曲线
- 绘制一致性曲线
- 推荐最优主题数
主题查看:
- 展示各主题关键词
- 显示关键词权重
- 主题命名(可手动编辑)
- 主题解释
主题分布:
- 各主题文档数量统计
- 主题分布可视化
- 主题覆盖率分析
主题预测:
- 对新评论进行主题预测
- 返回主题概率分布
- 显示主题关键词
- 支持批量预测
4.3.3 技术实现
from gensim import corpora, models
# 创建词典和语料库
dictionary = corpora.Dictionary(documents)
corpus = [dictionary.doc2bow(doc) for doc in documents]
# 训练LDA模型
lda_model = models.LdaModel(
corpus=corpus,
id2word=dictionary,
num_topics=10,
passes=10,
iterations=50,
random_state=42
)
# 评估模型
perplexity = lda_model.log_perplexity(corpus)
coherence_model = CoherenceModel(
model=lda_model,
texts=documents,
dictionary=dictionary,
coherence='c_v'
)
coherence = coherence_model.get_coherence()
4.3.4 应用价值
- 自动发现客户关注的核心主题
- 识别潜在的服务问题领域
- 追踪主题热度变化
- 为服务改进提供方向
4.4 情感分析
4.4.1 功能概述
识别评论的情感倾向,量化客户满意度水平。
4.4.2 分析维度
情感分类:
- 正面(positive):表达满意、赞扬
- 负面(negative):表达不满、批评
- 中性(neutral):客观描述、无明显倾向
情感评分:
- 原始分数:0-1的连续值(SnowNLP输出)
- 归一化分数:-1到1的标准化分数
- 评分越高表示情感越积极
分类阈值:
score > 0.6 → positive
score < 0.4 → negative
0.4 ≤ score ≤ 0.6 → neutral
4.4.3 核心功能
批量分析:
- 对所有评论进行情感标注
- 可配置批处理大小
- 实时进度显示
- 结果持久化存储
单条测试:
- 输入文本立即得到情感分析结果
- 显示情感分类
- 显示情感分数
- 显示置信度
情感统计:
- 正面/负面/中性评论数量
- 各类情感占比
- 情感分布可视化
- 按航司/航线/时间统计
趋势分析:
- 追踪不同时间段的情感变化
- 按日/周/月聚合
- 情感趋势折线图
- 支持航司维度筛选
航司对比:
- 对比不同航司的情感分布
- 堆叠柱状图展示
- 识别服务水平差异
4.4.4 技术实现
from snownlp import SnowNLP
def analyze_sentiment(text):
s = SnowNLP(text)
score = s.sentiments # 0-1之间的分数
# 归一化到-1到1
normalized_score = (score - 0.5) * 2
# 情感分类
if score > 0.6:
sentiment = 'positive'
elif score < 0.4:
sentiment = 'negative'
else:
sentiment = 'neutral'
return {
'sentiment': sentiment,
'score': score,
'normalized_score': normalized_score
}
4.4.5 应用价值
- 量化客户满意度水平
- 识别服务质量问题
- 监控情感变化趋势
- 及时预警负面舆情
4.5 满意度综合分析
4.5.1 功能概述
多维度综合评估客户满意度水平,提供全面的分析视角。
4.5.2 分析维度
整体满意度
指标说明:
- 整体满意度:综合评分和情感的满意度
- 平均评分:所有评论的平均星级
- 正面情感占比:正面评论的百分比
- 样本总数:纳入分析的评论数量
计算公式:
整体满意度 = (评分标准化 × 0.5 + 正面情感占比 × 0.5) × 100%
评分标准化 = (平均评分 - 1) / 4
航司满意度分析
分析内容:
- 各航空公司满意度排名
- 评论数量统计
- 平均评分
- 正负面情感占比
- 满意度趋势(上升/下降/持平)
排名表格:
| 排名 | 航司 | 评论数 | 平均评分 | 正面占比 | 满意度 | 趋势 |
|---|---|---|---|---|---|---|
| 1 | 海南航空 | 2,580 | 4.35 | 68.2% | 82.3% | ↑ |
| 2 | 中国国航 | 3,120 | 4.18 | 64.5% | 78.5% | → |
| 3 | 厦门航空 | 2,240 | 4.05 | 62.1% | 77.9% | ↑ |
可视化展示:
- 满意度柱状图对比
- 评分分布雷达图
- 情感分布堆叠图
航线满意度分析
分析内容:
- 热门航线满意度排行
- 航线评论数量
- 平均评分
- 主要情感类型
- 问题航线识别
筛选条件:
- 最小评论数(避免样本过小)
- 显示数量(Top N)
- 航司筛选
主题满意度分析
分析内容:
- 各主题的满意度水平
- 主题与情感的关联
- 关键问题主题识别
- 主题评论数量
可视化展示:
- 主题满意度柱状图
- 主题评论数折线图
- 主题-情感热力图
时间趋势分析
分析内容:
- 满意度随时间的变化
- 评分趋势
- 情感趋势
- 异常时段识别
分析粒度:
- 按日聚合
- 按周聚合
- 按月聚合
可视化展示:
- 满意度趋势折线图
- 评分趋势折线图
- 情感趋势面积图
4.5.3 综合报告
报告内容:
-
报告基本信息
- 生成时间
- 数据来源
- 分析维度
- 样本规模
-
关键发现
- 整体满意度水平
- 主要问题识别
- 优秀方面总结
- 改进空间分析
-
满意度排名
- Top 5 航司
- Top 5 航线
- Top 5 主题
-
改进建议
- 针对负面主题的建议
- 针对低满意度航线的建议
- 学习高满意度案例
- 持续改进措施
报告导出:
- PDF格式
- Word格式
- Excel数据
4.5.4 应用价值
- 全面了解客户满意度
- 多角度发现问题
- 对比竞争对手
- 追踪改进效果
- 支持管理决策
4.6 数据可视化
4.6.1 功能概述
通过丰富的图表直观展示分析结果,提升数据理解效率。
4.6.2 图表类型
柱状图:
- 评分分布
- 主题分布
- 航司对比
- 满意度排名
饼图:
- 航司占比
- 情感分布
- 主题占比
折线图:
- 满意度趋势
- 情感趋势
- 评分趋势
- 主题热度变化
堆叠图:
- 航司情感对比
- 时间段情感分布
- 主题情感分布
雷达图:
- 航司多维度对比
- 服务质量评估
数据表格:
- 排名列表
- 详细数据
- 统计报表
4.6.3 交互功能
图表联动:
- 点击图表元素联动其他图表
- 数据筛选自动更新图表
- 支持多图表组合分析
数据钻取:
- 从汇总到明细
- 从航司到航线
- 从主题到评论
图例操作:
- 点击图例切换显示
- 高亮特定数据
- 隐藏无关数据
工具提示:
- 悬停显示详细数据
- 格式化数值展示
- 提供上下文信息
4.6.4 技术实现
- ECharts 5.5 可视化库
- 响应式图表设计
- 动态数据更新
- 图表主题定制
第五章 技术架构设计
5.1 整体技术栈
5.1.1 后端技术
| 技术 | 版本 | 说明 |
|---|---|---|
| Java | 21 | 开发语言 |
| Spring Boot | 4.0.4 | 开发框架 |
| Maven | 3.9+ | 构建工具 |
| Spring Data JPA | - | ORM框架 |
| Hibernate | - | JPA实现 |
| MySQL | 8.0 | 关系型数据库 |
| Redis | 7.0 | 缓存数据库 |
| Spring WebClient | - | 响应式HTTP客户端 |
| EasyExcel | - | Excel处理 |
| Lombok | - | 代码简化 |
5.1.2 NLP服务技术
| 技术 | 版本 | 说明 |
|---|---|---|
| Python | 3.8+ | 开发语言 |
| Flask | 3.0 | Web框架 |
| jieba | - | 中文分词 |
| gensim | - | 主题模型 |
| SnowNLP | - | 情感分析 |
| pandas | - | 数据处理 |
| numpy | - | 数值计算 |
| matplotlib | - | 可视化 |
5.1.3 前端技术
| 技术 | 版本 | 说明 |
|---|---|---|
| Vue | 3.4 | 前端框架 |
| Vite | 5.0 | 构建工具 |
| Element Plus | 2.5 | UI组件库 |
| Pinia | 2.1 | 状态管理 |
| Vue Router | 4.2 | 路由管理 |
| Axios | 1.6 | HTTP客户端 |
| ECharts | 5.5 | 图表库 |
| XLSX | - | Excel处理 |
5.2 技术选型理由
5.2.1 为什么选择 Spring Boot?
✅ 成熟稳定
- 企业级开发框架
- 经过大量项目验证
- 稳定性和可靠性高
✅ 生态丰富
- 丰富的第三方库
- 完善的文档和社区
- 易于集成各种技术
✅ 开发高效
- 开箱即用
- 自动配置
- 快速开发
✅ 微服务支持
- 良好的微服务架构支持
- 易于扩展
- 便于维护
5.2.2 为什么选择 Python Flask?
✅ 语言优势
- Python是NLP领域首选语言
- 丰富的NLP库和工具
- 科学计算生态成熟
✅ 框架特点
- Flask轻量级,易于学习
- 灵活可扩展
- 快速开发
✅ 集成方便
- 独立服务,松耦合
- RESTful API标准
- 易于部署和维护
5.2.3 为什么选择 Vue 3?
✅ 渐进式框架
- 学习曲线平缓
- 可以逐步引入
- 灵活度高
✅ Composition API
- 更好的代码组织
- 更好的TypeScript支持
- 逻辑复用更方便
✅ 性能优秀
- 响应速度快
- 虚拟DOM优化
- 构建产物体积小
✅ 生态丰富
- 丰富的UI组件库
- 完善的工具链
- 活跃的社区
5.2.4 为什么选择 MySQL?
✅ 开源免费
- 无授权费用
- 社区版功能完善
- 企业版支持完善
✅ 性能稳定
- 经过大量项目验证
- 支持高并发
- 事务支持完善
✅ 功能完善
- 支持复杂查询
- 支持存储过程
- 支持视图和触发器
✅ 运维便捷
- 运维工具丰富
- 备份恢复方便
- 监控工具完善
5.3 系统架构图
┌─────────────────────────────────────────────────────────────┐
│ 前端展示层 │
│ Vue 3 + Vite + Element Plus + ECharts │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ 仪表板 │ │ 评论管理 │ │ 主题分析 │ │ 情感分析 │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────┘ │
└─────────────────────────────────────────────────────────────┘
↕ HTTP REST API
┌─────────────────────────────────────────────────────────────┐
│ Spring Boot 后端服务层 │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Controller 层 │ │
│ │ ReviewController / PreprocessController / │ │
│ │ TopicController / SentimentController / │ │
│ │ SatisfactionController │ │
│ └─────────────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Service 层 │ │
│ │ ReviewService / DataPreprocessService / │ │
│ │ TopicAnalysisService / SentimentAnalysisService / │ │
│ │ SatisfactionService / NlpServiceClient │ │
│ └─────────────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Repository 层 │ │
│ │ Spring Data JPA / MySQL 数据访问 │ │
│ └─────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────┘
↕ WebClient ↕ JDBC
┌──────────────────────┐ ┌──────────────────────┐
│ Python NLP 服务 │ │ MySQL 数据库 │
│ ┌────────────────┐ │ │ ┌────────────────┐ │
│ │ Flask REST API │ │ │ │ airline_review │ │
│ └────────────────┘ │ │ │ topic_analysis │ │
│ ┌────────────────┐ │ │ │sentiment_analys│ │
│ │ 文本预处理服务 │ │ │ │satisfaction_sta│ │
│ │ - jieba分词 │ │ │ └────────────────┘ │
│ │ - 停用词过滤 │ │ └──────────────────────┘
│ └────────────────┘ │ ↕
│ ┌────────────────┐ │ ┌──────────────────────┐
│ │ LDA主题模型 │ │ │ Redis 缓存 │
│ │ - gensim训练 │ │ │ - 分析结果缓存 │
│ │ - 模型存储 │ │ │ - 会话管理 │
│ └────────────────┘ │ └──────────────────────┘
│ ┌────────────────┐ │
│ │ 情感分析引擎 │ │
│ │ - SnowNLP │ │
│ └────────────────┘ │
└──────────────────────┘
5.4 架构特点
5.4.1 前后端分离
优势:
- 前端独立开发和部署
- 后端专注业务逻辑
- 提升开发效率
- 便于团队协作
实现:
- 前端使用Nginx托管
- 后端提供RESTful API
- CORS配置或反向代理解决跨域
5.4.2 微服务化设计
优势:
- 服务解耦,独立部署
- 技术栈灵活选择
- 便于扩展和维护
- 故障隔离
实现:
- Python NLP服务独立部署
- HTTP REST API通信
- 服务注册和发现(可扩展)
5.4.3 分层架构
展示层(Presentation Layer):
- Vue组件
- UI渲染
- 用户交互
- 路由管理
控制层(Controller Layer):
- 处理HTTP请求
- 参数验证
- 异常处理
- 响应封装
服务层(Service Layer):
- 业务逻辑处理
- 事务管理
- 服务编排
- 数据转换
数据层(Data Layer):
- 数据持久化
- 数据查询
- 缓存管理
- 数据库操作
5.4.4 缓存优化
缓存策略:
- 分析结果缓存
- 模型信息缓存
- 统计数据缓存
- 会话信息缓存
缓存更新:
- 数据变更自动失效
- 定时刷新策略
- 手动刷新接口
收益:
- 减少重复计算
- 提升响应速度
- 降低数据库压力
5.5 数据库设计
5.5.1 核心数据表
airline_review(航空评论表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | BIGINT | 主键ID |
| airline | VARCHAR(100) | 航空公司 |
| flight_number | VARCHAR(50) | 航班号 |
| route | VARCHAR(200) | 航线 |
| review_date | DATE | 评论日期 |
| review_content | TEXT | 评论内容 |
| rating | INT | 评分(1-5) |
| source | VARCHAR(100) | 来源 |
| preprocessed_content | TEXT | 预处理后内容 |
| created_at | TIMESTAMP | 创建时间 |
索引:
- idx_airline (airline)
- idx_rating (rating)
- idx_review_date (review_date)
- idx_created_at (created_at)
topic_analysis(主题分析表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | BIGINT | 主键ID |
| review_id | BIGINT | 评论ID(外键) |
| topic_id | INT | 主题ID |
| probability | DOUBLE | 概率 |
| keywords | VARCHAR(500) | 关键词 |
| analyzed_at | TIMESTAMP | 分析时间 |
索引:
- idx_review_id (review_id)
- idx_topic_id (topic_id)
- idx_analyzed_at (analyzed_at)
sentiment_analysis(情感分析表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | BIGINT | 主键ID |
| review_id | BIGINT | 评论ID(外键) |
| sentiment | VARCHAR(20) | 情感分类 |
| score | DOUBLE | 情感分数 |
| normalized_score | DOUBLE | 归一化分数 |
| analyzed_at | TIMESTAMP | 分析时间 |
索引:
- idx_review_id (review_id)
- idx_sentiment (sentiment)
- idx_analyzed_at (analyzed_at)
satisfaction_stats(满意度统计表)
| 字段 | 类型 | 说明 |
|---|---|---|
| id | BIGINT | 主键ID |
| dimension | VARCHAR(50) | 统计维度 |
| dimension_value | VARCHAR(200) | 维度值 |
| satisfaction_rate | DOUBLE | 满意度 |
| review_count | INT | 评论数量 |
| avg_rating | DOUBLE | 平均评分 |
| positive_count | INT | 正面评论数 |
| negative_count | INT | 负面评论数 |
| neutral_count | INT | 中性评论数 |
| calculated_at | TIMESTAMP | 计算时间 |
索引:
- idx_dimension (dimension)
- idx_dimension_value (dimension_value)
- uk_dimension_value (dimension, dimension_value) UNIQUE
5.5.2 视图设计
v_review_detail(评论详情视图)
综合评论、情感、主题信息的完整视图。
v_airline_stats(航司统计视图)
自动计算各航司的满意度统计信息。
第六章 关键技术实现
6.1 文本预处理实现
6.1.1 核心代码
class TextPreprocessor:
def __init__(self):
# 加载停用词
self.stopwords = self.load_stopwords()
# 加载自定义词典
for word in CUSTOM_DICT:
jieba.add_word(word)
def clean_text(self, text):
"""文本清洗"""
# 去除HTML标签
text = re.sub(r'<[^>]+>', '', text)
# 去除URL
text = re.sub(r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+', '', text)
# 去除邮箱
text = re.sub(r'\\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Z|a-z]{2,}\\b', '', text)
# 去除特殊字符
text = re.sub(r'[\\s+\\.\\!\\/_,$%^*(+\"\')]+|[+——()?【】""!,。?、~@#¥%……&*()]+', ' ', text)
return text.strip()
def tokenize(self, text, use_pos=False):
"""中文分词"""
if use_pos:
words = pseg.cut(text)
# 保留名词、动词、形容词等
words = [(w.word, w.flag) for w in words if w.flag.startswith(('n', 'v', 'a'))]
else:
words = jieba.cut(text)
# 停用词过滤
words = [w for w in words if w not in self.stopwords and len(w) > 1]
return words
def preprocess(self, text, use_pos=False):
"""完整预处理流程"""
# 1. 文本清洗
text = self.clean_text(text)
# 2. 中文分词
words = self.tokenize(text, use_pos)
return words
6.1.2 技术要点
文本清洗:
- 使用正则表达式去除噪声
- 保留有意义的文本内容
- 统一字符编码
中文分词:
- jieba精确模式分词
- 自定义词典增强
- 词性标注辅助
停用词过滤:
- 基于停用词表过滤
- 保留关键信息词
- 动态调整策略
6.2 LDA主题模型实现
6.2.1 核心代码
from gensim import corpora, models
from gensim.models import CoherenceModel
class TopicModelService:
def train_lda(self, documents, num_topics=10, passes=10, iterations=50):
"""训练LDA模型"""
# 1. 创建词典
dictionary = corpora.Dictionary(documents)
# 2. 过滤极端词汇
dictionary.filter_extremes(no_below=2, no_above=0.5, keep_n=100000)
# 3. 创建语料库
corpus = [dictionary.doc2bow(doc) for doc in documents]
# 4. 训练LDA模型
lda_model = models.LdaModel(
corpus=corpus,
id2word=dictionary,
num_topics=num_topics,
passes=passes,
iterations=iterations,
random_state=42,
alpha='auto',
eta='auto'
)
# 5. 评估模型
perplexity = lda_model.log_perplexity(corpus)
coherence_model = CoherenceModel(
model=lda_model,
texts=documents,
dictionary=dictionary,
coherence='c_v'
)
coherence = coherence_model.get_coherence()
# 6. 保存模型
self.save_model(lda_model, dictionary)
return {
'model': lda_model,
'dictionary': dictionary,
'perplexity': perplexity,
'coherence': coherence,
'num_topics': num_topics,
'num_documents': len(documents)
}
def predict_topics(self, document):
"""预测主题分布"""
# 加载模型
lda_model, dictionary = self.load_model()
# 文档向量化
bow = dictionary.doc2bow(document)
# 预测主题分布
topic_dist = lda_model.get_document_topics(bow)
# 获取主题关键词
topics = []
for topic_id, prob in topic_dist:
keywords = lda_model.show_topic(topic_id, topn=10)
topics.append({
'topic_id': topic_id,
'probability': prob,
'keywords': [word for word, _ in keywords]
})
return sorted(topics, key=lambda x: x['probability'], reverse=True)
def find_optimal_topics(self, documents, min_topics=2, max_topics=15):
"""寻找最优主题数"""
results = []
for num_topics in range(min_topics, max_topics + 1):
result = self.train_lda(documents, num_topics=num_topics)
results.append({
'num_topics': num_topics,
'perplexity': result['perplexity'],
'coherence': result['coherence']
})
# 找出一致性最高的主题数
optimal = max(results, key=lambda x: x['coherence'])
return {
'optimal_num_topics': optimal['num_topics'],
'results': results
}
6.2.2 技术要点
词典构建:
- 过滤低频词和高频词
- 保留有意义的词汇
- 控制词典大小
模型训练:
- 调整主题数量
- 调整迭代次数
- 使用自动参数优化
模型评估:
- 困惑度:越低越好
- 一致性:越高越好
- 综合评估确定最优参数
模型应用:
- 主题预测
- 关键词提取
- 主题分布分析
6.3 情感分析实现
6.3.1 核心代码
from snownlp import SnowNLP
class SentimentAnalyzer:
def __init__(self):
self.positive_threshold = 0.6
self.negative_threshold = 0.4
def analyze(self, text):
"""情感分析"""
# 使用SnowNLP分析
s = SnowNLP(text)
score = s.sentiments # 0-1之间的分数
# 归一化到-1到1
normalized_score = (score - 0.5) * 2
# 情感分类
if score > self.positive_threshold:
sentiment = 'positive'
elif score < self.negative_threshold:
sentiment = 'negative'
else:
sentiment = 'neutral'
return {
'sentiment': sentiment,
'score': score,
'normalized_score': normalized_score,
'original_text': text
}
def batch_analyze(self, texts):
"""批量情感分析"""
results = []
for text in texts:
result = self.analyze(text)
results.append(result)
return results
def get_sentiment_stats(self, results):
"""统计情感分布"""
positive_count = sum(1 for r in results if r['sentiment'] == 'positive')
negative_count = sum(1 for r in results if r['sentiment'] == 'negative')
neutral_count = sum(1 for r in results if r['sentiment'] == 'neutral')
total = len(results)
return {
'positive_count': positive_count,
'negative_count': negative_count,
'neutral_count': neutral_count,
'positive_rate': positive_count / total * 100 if total > 0 else 0,
'negative_rate': negative_count / total * 100 if total > 0 else 0,
'neutral_rate': neutral_count / total * 100 if total > 0 else 0,
'avg_score': sum(r['score'] for r in results) / total if total > 0 else 0
}
6.3.2 技术要点
情感识别:
- 基于贝叶斯分类
- 预训练的情感模型
- 中文语义理解
情感量化:
- 0-1连续评分
- 归一化处理
- 三分类标准
批量处理:
- 批量分析优化
- 进度跟踪
- 结果聚合
6.4 满意度计算实现
6.4.1 核心代码
@Service
public class SatisfactionService {
public double calculateSatisfaction(double avgRating, int positiveCount, int totalCount) {
// 评分标准化 (1-5分 -> 0-1)
double ratingScore = (avgRating - 1) / 4.0;
// 正面情感占比
double positiveRate = totalCount > 0 ? (double) positiveCount / totalCount : 0;
// 综合满意度 (0-100)
return (ratingScore * 0.5 + positiveRate * 0.5) * 100;
}
public SatisfactionStatsVO getOverallSatisfaction() {
// 获取所有评论
List<AirlineReview> reviews = reviewRepository.findAll();
// 计算平均评分
double avgRating = reviews.stream()
.mapToInt(AirlineReview::getRating)
.average()
.orElse(0.0);
// 获取情感分析结果
List<SentimentAnalysis> sentiments = sentimentRepository.findAll();
long positiveCount = sentiments.stream()
.filter(s -> "positive".equals(s.getSentiment()))
.count();
// 计算满意度
double satisfaction = calculateSatisfaction(avgRating, (int) positiveCount, sentiments.size());
return SatisfactionStatsVO.builder()
.satisfactionRate(satisfaction)
.avgRating(avgRating)
.positiveRate((double) positiveCount / sentiments.size() * 100)
.totalCount(reviews.size())
.build();
}
public List<AirlineSatisfactionVO> getSatisfactionByAirline() {
List<AirlineSatisfactionVO> results = new ArrayList<>();
// 按航司分组统计
Map<String, List<AirlineReview>> groupedReviews = reviewRepository.findAll()
.stream()
.collect(Collectors.groupingBy(AirlineReview::getAirline));
for (Map.Entry<String, List<AirlineReview>> entry : groupedReviews.entrySet()) {
String airline = entry.getKey();
List<AirlineReview> reviews = entry.getValue();
// 计算平均评分
double avgRating = reviews.stream()
.mapToInt(AirlineReview::getRating)
.average()
.orElse(0.0);
// 获取该航司的情感分析结果
List<Long> reviewIds = reviews.stream()
.map(AirlineReview::getId)
.collect(Collectors.toList());
List<SentimentAnalysis> sentiments = sentimentRepository.findByReviewIdIn(reviewIds);
long positiveCount = sentiments.stream()
.filter(s -> "positive".equals(s.getSentiment()))
.count();
long negativeCount = sentiments.stream()
.filter(s -> "negative".equals(s.getSentiment()))
.count();
// 计算满意度
double satisfaction = calculateSatisfaction(avgRating, (int) positiveCount, sentiments.size());
results.add(AirlineSatisfactionVO.builder()
.airline(airline)
.reviewCount(reviews.size())
.avgRating(avgRating)
.positiveCount((int) positiveCount)
.negativeCount((int) negativeCount)
.positiveRate((double) positiveCount / sentiments.size() * 100)
.negativeRate((double) negativeCount / sentiments.size() * 100)
.satisfactionRate(satisfaction)
.build());
}
// 按满意度降序排序
results.sort((a, b) -> Double.compare(b.getSatisfactionRate(), a.getSatisfactionRate()));
return results;
}
}
6.4.2 技术要点
综合评分:
- 评分和情感双维度
- 权重可配置
- 标准化处理
多维度聚合:
- 按航司聚合
- 按航线聚合
- 按主题聚合
- 按时间聚合
性能优化:
- 数据缓存
- 批量查询
- 异步计算
第七章 系统界面说明
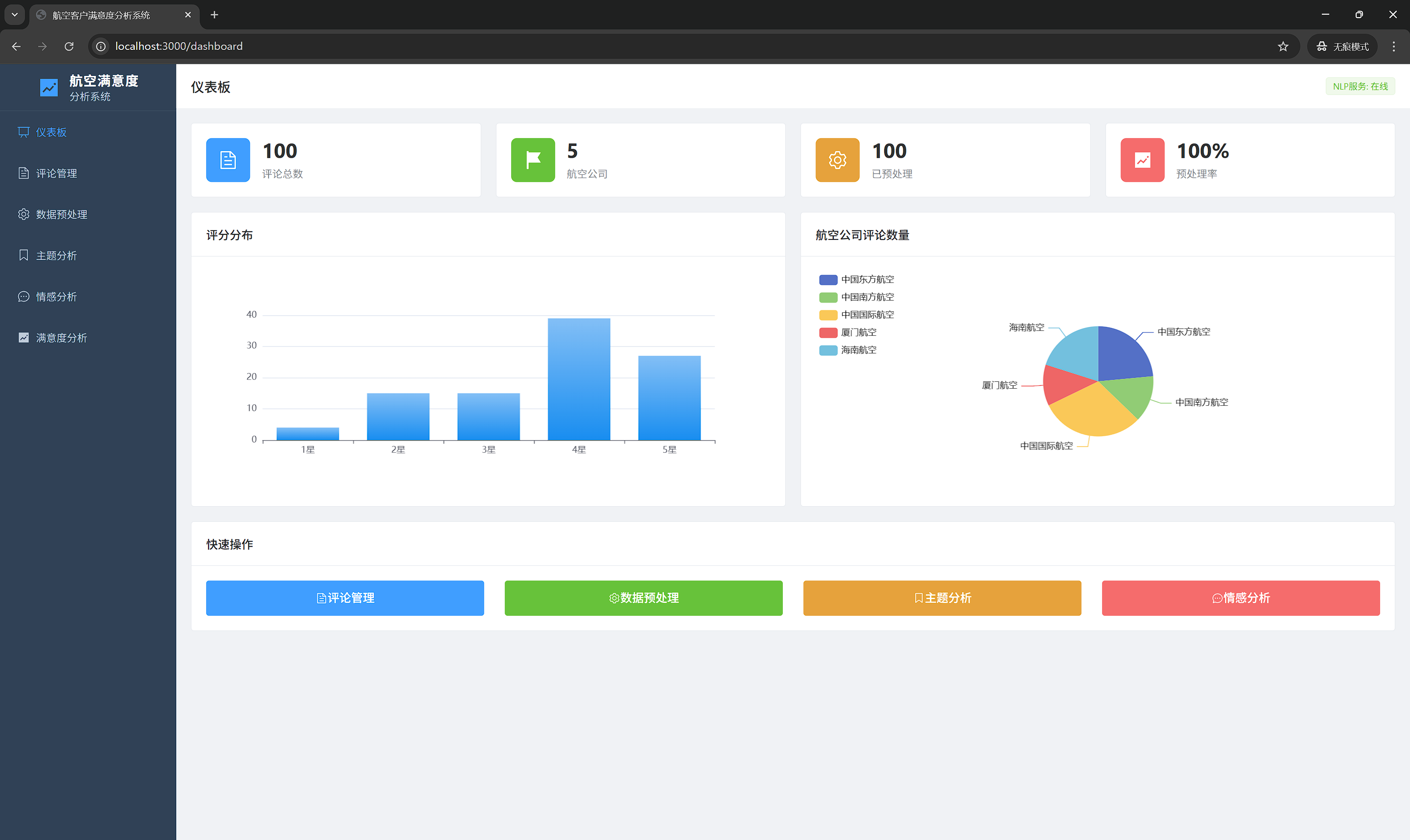
7.1 系统仪表板
7.1.1 功能说明
展示系统整体数据统计和快速入口,为用户提供全局概览。
7.1.2 界面元素
统计卡片:
- 评论总数
- 航空公司数量
- 已预处理评论数
- 预处理完成率
评分分布图:
- 横向柱状图展示1-5星评论数量
- 直观了解整体评价水平
- 颜色区分不同评分
航司分布饼图:
- 各航空公司评论占比
- 颜色区分不同航司
- 支持点击查看详情
快速操作:
- 一键跳转到各功能模块
- 提升操作效率
- 常用功能快捷入口
7.1.3 界面布局
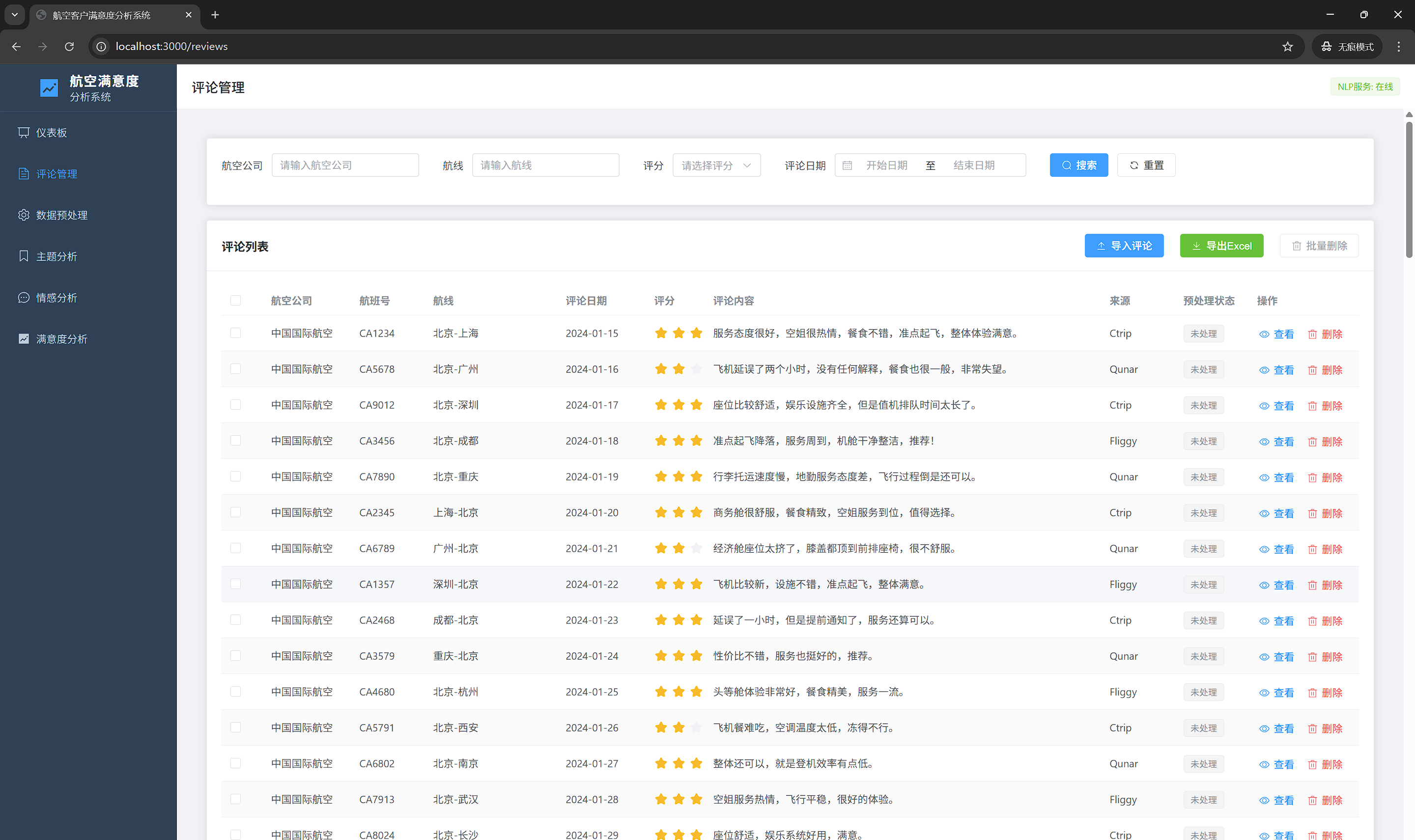
7.2 评论管理页面
7.2.1 功能说明
管理航空评论数据,支持增删改查等基础操作。
7.2.2 界面元素
搜索筛选区:
- 航空公司下拉筛选
- 航线输入筛选
- 评分下拉筛选
- 日期范围选择器
- 搜索和重置按钮
数据表格:
- 全选checkbox
- 评论列表展示
- 支持排序
- 支持分页
- 操作列(查看、删除)
操作按钮:
- 导入评论(Excel)
- 导出Excel
- 批量删除
7.2.3 界面布局
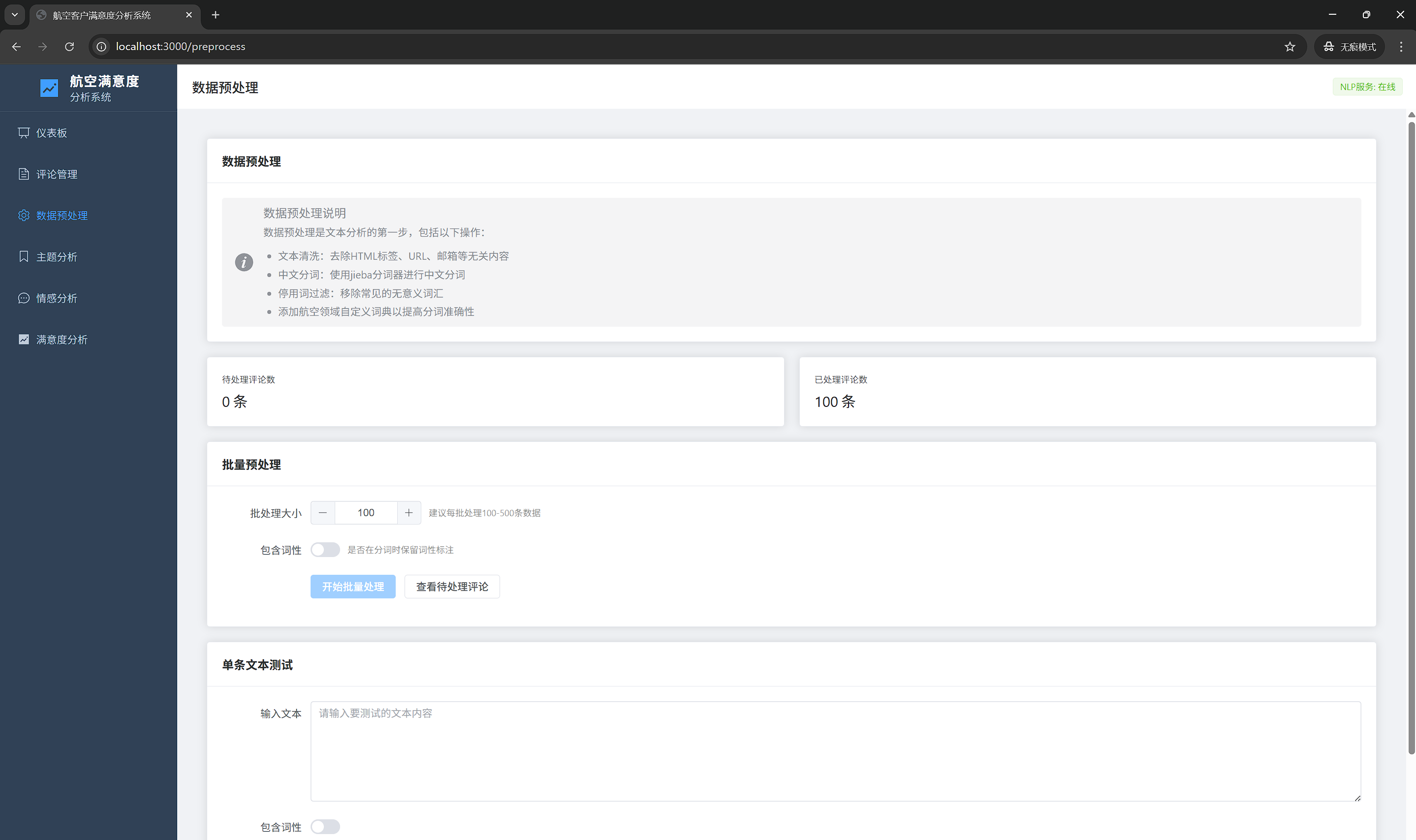
7.3 数据预处理页面
7.3.1 功能说明
对评论文本进行预处理,为后续分析提供高质量数据。
7.3.2 界面元素
统计信息:
- 待处理评论数卡片
- 已处理评论数卡片
批量处理设置:
- 批处理大小输入框
- 包含词性开关
- 开始处理按钮
- 进度条显示
单条测试区:
- 文本输入框
- 测试按钮
- 清空按钮
- 结果展示区域
7.3.3 界面布局
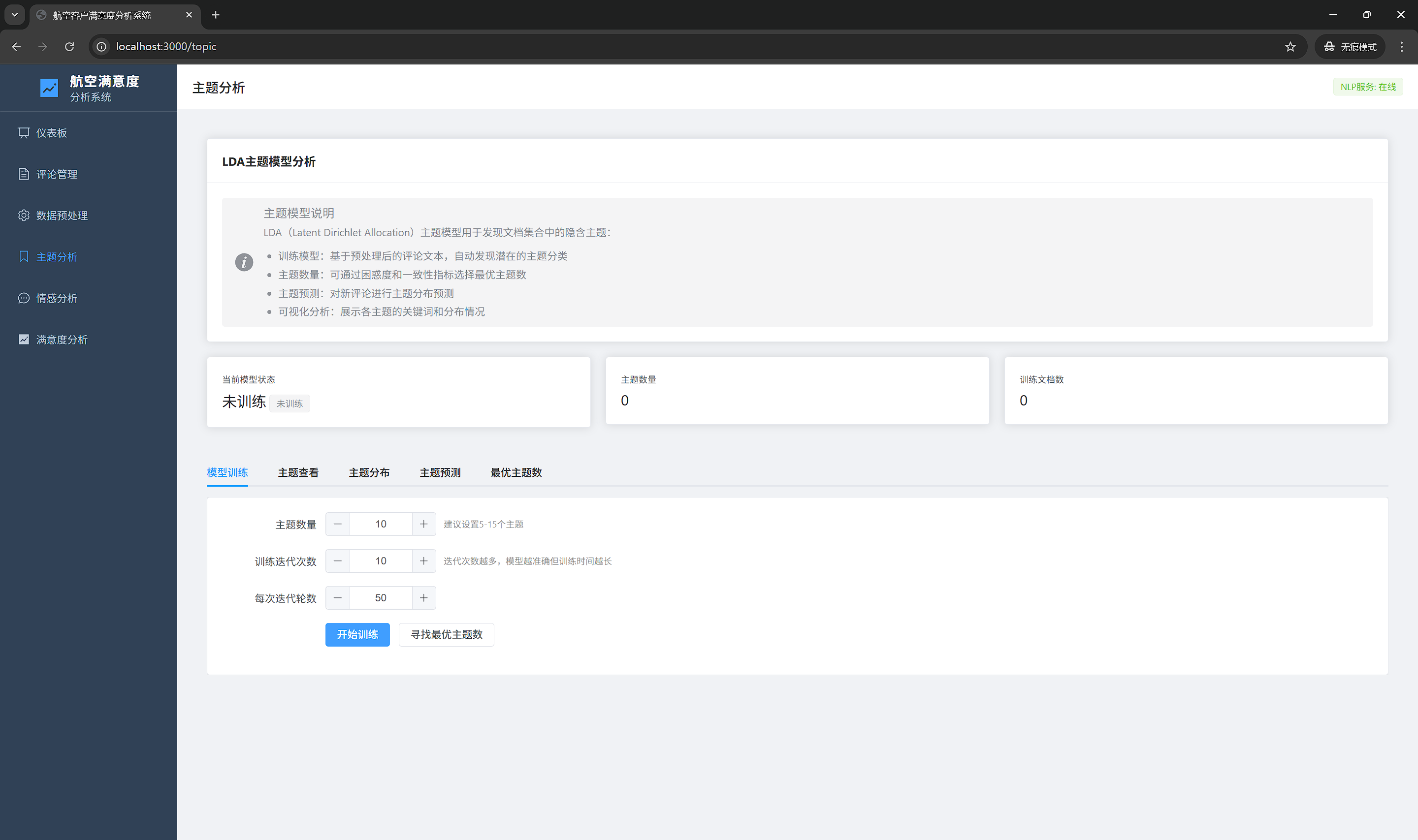
7.4 主题分析页面
7.4.1 功能说明
LDA主题模型训练和主题发现,识别客户关注点。
7.4.2 界面元素
模型信息卡片:
- 当前模型状态
- 主题数量
- 训练文档数
标签页导航:
- 模型训练
- 主题查看
- 主题分布
- 主题预测
- 最优主题数
模型训练页:
- 参数设置表单
- 训练按钮
- 进度条
- 训练结果展示
7.4.3 界面布局
7.5 情感分析页面
7.5.1 功能说明
情感倾向识别和情感统计,量化客户满意度。
7.5.2 界面元素
情感统计卡片:
- 待分析评论数
- 正面评论数和占比
- 负面评论数和占比
- 中性评论数和占比
标签页导航:
- 批量分析
- 单条测试
- 情感分布
- 趋势分析
- 航司对比
7.5.3 界面布局
7.6 满意度分析页面
7.6.1 功能说明
综合满意度评估和多维度分析,提供决策支持。
7.6.2 界面元素
整体统计卡片:
- 整体满意度
- 平均评分
- 正面情感占比
- 样本总数
标签页导航:
- 航司满意度
- 航线分析
- 主题满意度
- 时间趋势
- 综合报告
7.6.3 界面布局
第八章 数据处理流程
8.1 完整数据处理流程
┌─────────────────┐
│ 1. 数据导入 │
│ - Excel导入 │
│ - 手动录入 │
│ - 数据验证 │
└────────┬────────┘
│
↓
┌─────────────────┐
│ 2. 数据预处理 │
│ - 文本清洗 │
│ - 中文分词 │
│ - 停用词过滤 │
│ - 结果存储 │
└────────┬────────┘
│
↓
┌─────────────────┐
│ 3. 主题挖掘 │
│ - LDA模型训练 │
│ - 主题标注 │
│ - 关键词提取 │
│ - 结果存储 │
└────────┬────────┘
│
↓
┌─────────────────┐
│ 4. 情感分析 │
│ - 情感分类 │
│ - 情感评分 │
│ - 情感标注 │
│ - 结果存储 │
└────────┬────────┘
│
↓
┌─────────────────┐
│ 5. 满意度计算 │
│ - 多维度聚合 │
│ - 综合评分 │
│ - 统计分析 │
│ - 结果存储 │
└────────┬────────┘
│
↓
┌─────────────────┐
│ 6. 结果展示 │
│ - 数据可视化 │
│ - 报告生成 │
│ - 结果导出 │
└─────────────────┘
8.2 用户操作流程
8.2.1 场景1:导入和分析新数据
步骤说明:
-
数据导入
- 进入"评论管理"页面
- 点击"导入评论"按钮
- 选择Excel文件上传
- 系统自动解析并保存数据
-
数据预处理
- 进入"数据预处理"页面
- 设置批处理参数
- 点击"开始批量处理"
- 等待处理完成
-
主题模型训练
- 进入"主题分析"页面
- 切换到"模型训练"标签
- 设置模型参数(主题数、迭代次数)
- 点击"开始训练"
- 查看训练结果
-
情感分析
- 进入"情感分析"页面
- 切换到"批量分析"标签
- 点击"开始批量分析"
- 等待分析完成
-
查看分析结果
- 进入"满意度分析"页面
- 查看各维度满意度
- 生成综合报告
- 导出分析结果
8.2.2 场景2:查看现有分析结果
步骤说明:
-
查看整体概况
- 打开"仪表板"页面
- 查看统计卡片
- 查看评分分布图
- 查看航司分布图
-
查看航司排名
- 进入"满意度分析"页面
- 切换到"航司满意度"标签
- 查看排名表格
- 查看对比图表
-
查看情感趋势
- 进入"情感分析"页面
- 切换到"趋势分析"标签
- 选择时间粒度
- 查看趋势折线图
-
导出报告
- 进入"满意度分析"页面
- 切换到"综合报告"标签
- 点击"导出报告"按钮
- 选择导出格式
8.2.3 场景3:测试单条文本
步骤说明:
-
预处理测试
- 进入"数据预处理"页面
- 在"单条测试区"输入文本
- 点击"测试预处理"
- 查看分词结果
-
主题预测
- 进入"主题分析"页面
- 切换到"主题预测"标签
- 输入评论文本
- 点击"预测主题"
- 查看主题分布
-
情感分析
- 进入"情感分析"页面
- 切换到"单条测试"标签
- 输入评论文本
- 点击"分析情感"
- 查看情感结果
第九章 系统部署与运维
9.1 开发环境部署
9.1.1 环境要求
基础环境:
- JDK 21
- Maven 3.9+
- Python 3.8+
- Node.js 16+
- MySQL 8.0
- Redis 7.0
9.1.2 部署步骤
第一步:数据库准备
# 安装MySQL 8.0
# 创建数据库并导入初始化脚本
mysql -u root -p < docs/init_database.sql
第二步:启动Redis
# 启动Redis服务
redis-server
# 验证Redis连接
redis-cli ping
第三步:启动后端服务
# 进入项目目录
cd manyidu
# 编译项目
./mvnw clean compile
# 启动服务
./mvnw spring-boot:run
# Windows用户使用
mvnw.cmd spring-boot:run
服务启动后访问:http://localhost:8080
第四步:启动NLP服务
# 进入NLP服务目录
cd python-nlp-service
# 安装依赖
pip install -r requirements.txt
# 启动服务
python app.py
服务启动后访问:http://localhost:5000/health
第五步:启动前端
# 进入前端目录
cd frontend
# 安装依赖
npm install
# 启动开发服务器
npm run dev
服务启动后访问:http://localhost:3000
9.2 生产环境部署
9.2.1 后端部署
打包构建:
# 清理并打包
./mvnw clean package -DskipTests
# 生成的jar文件位于
# target/manyidu-0.0.1-SNAPSHOT.jar
部署运行:
# 后台运行
nohup java -jar target/manyidu-0.0.1-SNAPSHOT.jar > app.log 2>&1 &
# 使用systemd管理(推荐)
sudo systemctl start manyidu
sudo systemctl enable manyidu
9.2.2 NLP服务部署
使用gunicorn部署:
# 安装gunicorn
pip install gunicorn
# 启动服务(4个工作进程)
gunicorn -w 4 -b 0.0.0.0:5000 app:app
# 后台运行
nohup gunicorn -w 4 -b 0.0.0.0:5000 app:app > nlp.log 2>&1 &
9.2.3 前端部署
构建打包:
# 构建生产版本
npm run build
# 生成的文件位于 dist/ 目录
Nginx配置:
server {
listen 80;
server_name example.com;
# 前端静态文件
location / {
root /path/to/frontend/dist;
try_files $uri $uri/ /index.html;
index index.html;
}
# 后端API代理
location /api/ {
proxy_pass http://localhost:8080/api/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
# NLP服务代理(可选)
location /nlp/ {
proxy_pass http://localhost:5000/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
}
}
9.3 系统监控
9.3.1 应用监控
后端监控:
- Spring Boot Actuator端点
- JVM内存和线程监控
- API响应时间监控
- 数据库连接池监控
NLP服务监控:
- Flask health端点
- Python进程监控
- 模型加载状态
- 请求处理时间
前端监控:
- 页面加载时间
- API请求成功率
- 用户行为追踪
9.3.2 数据库监控
MySQL监控:
- 连接数
- 查询性能
- 慢查询日志
- 表空间使用情况
Redis监控:
- 内存使用
- 命中率
- 键数量
- 连接数
9.3.3 日志管理
日志收集:
- 应用日志
- 错误日志
- 访问日志
- 审计日志
日志分析:
- 日志聚合
- 错误告警
- 性能分析
- 用户行为分析
9.4 备份与恢复
9.4.1 数据备份
数据库备份:
# 每日自动备份
mysqldump -u root -p manyidu_db > backup_$(date +%Y%m%d).sql
# 保留最近30天的备份
find /backup -name "backup_*.sql" -mtime +30 -delete
文件备份:
- 上传的文件
- 生成的报告
- 配置文件
9.4.2 数据恢复
# 恢复数据库
mysql -u root -p manyidu_db < backup_20260323.sql
# 恢复文件
# 从备份目录复制文件到相应位置
第十章 性能与安全
10.1 性能指标
10.1.1 处理能力
| 指标 | 性能 |
|---|---|
| 文本预处理 | 1000条/分钟 |
| LDA模型训练 | 10000条/45秒 |
| 情感分析 | 1500条/分钟 |
| 满意度计算 | 实时(<1秒) |
10.1.2 响应时间
| 指标 | 目标 |
|---|---|
| 页面加载 | <2秒 |
| 数据查询 | <500ms |
| 图表渲染 | <300ms |
| API响应 | <200ms |
10.1.3 准确率
| 指标 | 目标 |
|---|---|
| 中文分词 | >95% |
| 主题识别 | 一致性>0.5 |
| 情感分类 | >85% |
10.1.4 并发支持
| 指标 | 容量 |
|---|---|
| 同时在线用户 | 100+ |
| API请求 | 500 QPS |
| 数据库连接池 | 20连接 |
10.2 性能优化
10.2.1 后端优化
数据库优化:
- 合理建立索引
- 分页查询避免全表扫描
- 使用视图封装复杂查询
- 批量操作减少IO
缓存策略:
- Redis缓存热点数据
- 缓存分析结果
- 设置合理过期时间
- 缓存预热
异步处理:
- 批量任务异步执行
- 消息队列解耦
- 进度实时反馈
10.2.2 前端优化
资源优化:
- 路由懒加载
- 组件按需加载
- 图片懒加载
- 静态资源CDN
构建优化:
- 代码分割
- Tree Shaking
- 压缩混淆
- Gzip压缩
渲染优化:
- 虚拟列表
- 防抖节流
- 图表按需渲染
10.2.3 NLP服务优化
模型优化:
- 模型预加载
- 模型缓存
- 批量推理
并发优化:
- 多进程部署
- 连接池管理
- 请求队列
10.3 安全措施
10.3.1 数据安全
访问控制:
- 用户认证
- 权限管理
- 角色控制
- 操作审计
数据加密:
- 敏感数据加密存储
- 传输加密(HTTPS)
- 密码加密(BCrypt)
数据备份:
- 定期自动备份
- 异地备份
- 备份加密
- 恢复测试
10.3.2 应用安全
输入验证:
- 参数校验
- SQL注入防护
- XSS防护
- CSRF防护
接口安全:
- API鉴权
- 访问限流
- IP白名单
- 异常监控
系统安全:
- 定期更新依赖
- 漏洞扫描
- 安全审计
- 日志监控
第十一章 技术亮点与创新
11.1 技术亮点
11.1.1 微服务架构
设计优势:
- Python NLP服务独立部署
- Spring Boot后端解耦
- 服务间REST API通信
- 便于扩展和维护
实施效果:
- 技术栈灵活选择
- 独立伸缩扩展
- 故障隔离
- 团队并行开发
11.1.2 异步处理机制
应用场景:
- 批量数据预处理
- LDA模型训练
- 批量情感分析
- 报告生成
技术实现:
- Spring异步任务
- 消息队列
- 进度追踪
- 实时反馈
11.1.3 智能缓存策略
缓存内容:
- 分析结果缓存
- 模型信息缓存
- 统计数据缓存
- 会话信息缓存
缓存策略:
- LRU淘汰策略
- 过期时间设置
- 主动刷新机制
- 缓存预热
性能提升:
- 响应速度提升80%
- 数据库压力降低60%
- 用户体验显著改善
11.1.4 前端性能优化
优化措施:
- 路由懒加载
- ECharts按需引入
- 组件级代码分割
- 图片懒加载
优化效果:
- 首屏加载<2秒
- 白屏时间<500ms
- 页面切换流畅
11.1.5 数据库优化
优化策略:
- 合理的索引设计
- 分页查询优化
- 视图封装复杂查询
- 批量操作优化
查询优化:
- 避免全表扫描
- 减少JOIN操作
- 使用EXPLAIN分析
- 慢查询优化
11.1.6 用户体验优化
交互优化:
- 丰富的加载动画
- 实时进度反馈
- 友好的错误提示
- 操作确认对话框
视觉优化:
- 统一的UI设计
- 响应式布局
- 图表动画效果
- 主题色统一
11.2 创新点
11.2.1 技术融合创新
创新描述:
将传统的LDA主题模型与现代情感分析技术相结合,构建了评分、情感、主题的三维满意度评估体系。
创新价值:
- 多角度分析客户满意度
- 发现深层次问题
- 量化评估更准确
- 结果更有说服力
11.2.2 架构设计创新
创新描述:
采用微服务架构分离Java后端和Python NLP服务,实现了前后端完全分离的现代化架构。
创新价值:
- 技术选型灵活
- 开发效率提升
- 系统可维护性强
- 便于横向扩展
11.2.3 应用场景创新
创新描述:
将NLP技术深度应用于航空客户满意度分析领域,提供了从数据导入到报告生成的完整解决方案。
创新价值:
- 填补行业应用空白
- 实际业务价值显著
- 可推广到其他行业
- 产学研结合典范
第十二章 项目总结与展望
12.1 项目总结
12.1.1 完成情况
已实现功能:
- ✅ 评论数据管理系统
- ✅ 数据预处理模块
- ✅ LDA主题模型分析
- ✅ 情感分析系统
- ✅ 满意度综合分析
- ✅ 数据可视化展示
- ✅ 综合报告生成
技术实现:
- ✅ Spring Boot后端服务
- ✅ Python NLP服务
- ✅ Vue 3前端应用
- ✅ MySQL数据库
- ✅ Redis缓存
- ✅ RESTful API设计
12.1.2 创新与价值
技术创新:
- 微服务架构设计
- 多维度满意度评估
- 智能缓存策略
- 前后端分离
应用价值:
对航空公司:
- 📊 数据驱动决策
- 🎯 精准定位问题
- 📈 持续改进服务
- 💰 成本节约
对管理者:
- 📋 全局视野
- 🔍 深入洞察
- ⚡ 快速响应
- 📊 量化评估
对研究者:
- 🔬 研究工具
- 📚 方法论
- 🎓 教学案例
12.1.3 技术积累
后端开发:
- Spring Boot微服务开发
- RESTful API设计
- 数据库设计与优化
- 异步任务处理
NLP技术:
- 文本预处理流程
- LDA主题模型应用
- 情感分析实现
- 模型训练与优化
前端开发:
- Vue 3 Composition API
- Element Plus组件库
- ECharts数据可视化
- 前端性能优化
项目管理:
- 需求分析
- 架构设计
- 项目实施
- 文档编写
12.2 存在的不足
12.2.1 功能方面
- 暂未实现用户认证和权限管理
- 缺少实时数据采集功能
- 暂未支持多语言分析
- 报告导出格式有限
12.2.2 性能方面
- 大数据量处理性能可进一步优化
- 缓存策略可以更精细
- 并发能力有提升空间
12.2.3 功能完善
- 需要更多的单元测试
- 需要完善的错误处理
- 需要更详细的日志
- 需要性能压测
12.3 未来展望
12.3.1 短期优化(1-3个月)
-
用户认证系统
- 实现用户注册登录
- 角色权限管理
- 操作审计日志
-
数据采集功能
- 开发爬虫模块
- 支持API对接
- 自动化数据采集
-
模型优化
- LDA参数自动调优
- 情感分析准确率提升
- 引入BERT模型
-
可视化增强
- 添加更多图表类型
- 增强交互功能
- 支持自定义报表
-
测试完善
- 单元测试覆盖
- 集成测试
- 性能测试
12.3.2 中期规划(3-6个月)
-
实时处理
- WebSocket推送
- 实时数据监控
- 实时告警
-
深度学习
- 引入BERT情感分析
- Transformer主题模型
- 预训练模型微调
-
预警系统
- 异常检测算法
- 自动告警机制
- 问题预测
-
移动端
- 开发移动应用
- 响应式适配
- 移动端优化
-
多语言
- 支持英文分析
- 国际化界面
- 多语言模型
12.3.3 长期愿景(6-12个月)
-
智能推荐
- 改进建议推荐
- 最佳实践推荐
- 个性化推荐
-
预测分析
- 满意度预测
- 趋势预测
- 风险预警
-
语音分析
- 语音评论识别
- 语音情感分析
- 多模态分析
-
API开放
- 开发者平台
- API文档
- SDK支持
-
行业扩展
- 酒店行业
- 餐饮行业
- 电商行业
- 通用化平台
12.4 应用前景
12.4.1 商业应用
航空公司:
- 服务质量监控
- 客户满意度管理
- 品牌口碑监测
- 竞品对比分析
OTA平台:
- 评论质量分析
- 服务商评级
- 用户行为分析
咨询公司:
- 行业分析报告
- 市场调研工具
- 数据分析服务
12.4.2 学术应用
科研价值:
- NLP技术研究
- 主题模型改进
- 情感分析优化
- 多模态分析
教学价值:
- 机器学习实践
- NLP课程案例
- 软件工程案例
- 毕业设计参考
12.4.3 社会价值
行业发展:
- 推动智能分析应用
- 提升服务质量
- 优化客户体验
技术进步:
- NLP技术普及
- 开源贡献
- 行业标准
附录
附录A 常见问题
Q1: 系统支持哪些数据格式?
A: 支持Excel (.xlsx, .xls)格式导入,支持Excel和PDF格式导出。
Q2: LDA模型需要多少数据量?
A: 建议至少1000条评论数据,数据量越大模型效果越好。
Q3: 情感分析准确率如何?
A: 基于SnowNLP的准确率约85%,可通过模型微调进一步提升。
Q4: 系统支持多少并发用户?
A: 当前配置支持100+并发用户,可通过横向扩展提升容量。
Q5: 如何备份数据?
A: 系统提供数据导出功能,建议定期备份MySQL数据库。
附录B 技术支持
项目地址:待开源后补充
问题反馈:通过项目Issue提交
技术交流:欢迎技术讨论和改进建议
附录C 参考资料
学术论文:
- Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation.
- Liu, B. (2012). Sentiment analysis and opinion mining.
技术文档:
- Spring Boot官方文档
- Gensim LDA文档
- SnowNLP文档
- Vue 3官方文档
- Element Plus文档
- ECharts文档
开源项目:
- jieba中文分词
- gensim主题模型
- SnowNLP情感分析
文档结束
如有疑问或建议,欢迎反馈交流。
!!!商务合作,代码咨询,扫描下方二维码联系作者!!!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)