Transformer:颠覆AI的注意力革命
Transformer 是 2017 年由 Google 在《Attention Is All You Need》中提出的深度学习架构,核心以自注意力机制(Self-Attention) 为基础,摒弃了传统 RNN/CNN 的序列依赖式建模方式,通过并行计算和全局上下文建模,大幅提升了序列建模的效率和效果,成为 NLP、CV、多模态等领域的基础架构,BERT、GPT、ViT 等经典模型均基于 Transformer 衍生。
其核心设计理念是 注意力机制主导 + 编码器 - 解码器框架,整体结构简洁且模块化,所有操作均基于张量的并行计算,无需按序列逐步处理,这是它与 RNN 类架构最核心的区别。
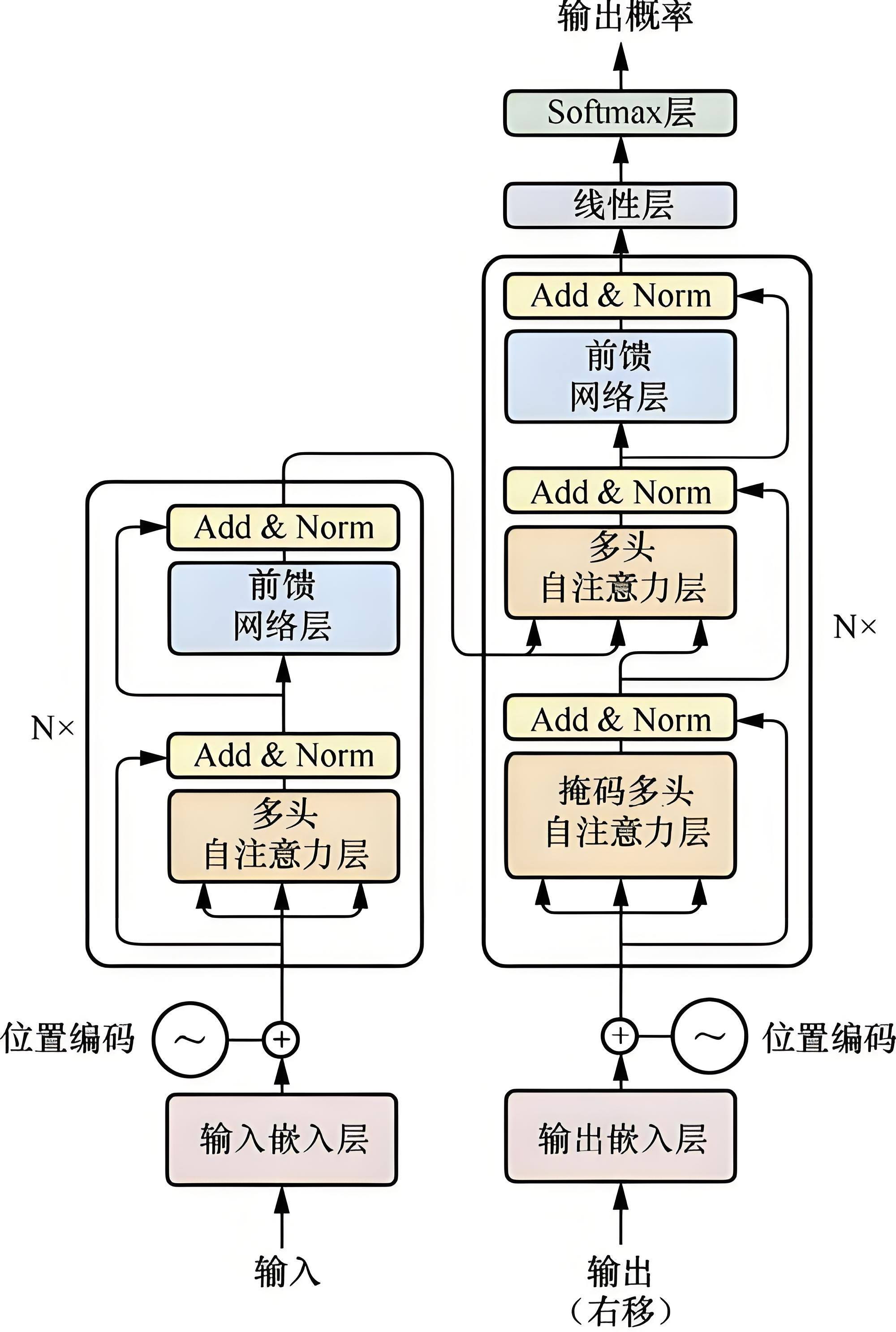
一、Transformer 整体架构:编码器 - 解码器双模块
Transformer 标准架构为编码器(Encoder)+ 解码器(Decoder) 双塔结构,适用于序列到序列(Seq2Seq) 任务(如机器翻译、文本摘要);而后续的 BERT(仅编码器)、GPT(仅解码器)则是对该架构的单塔裁剪,核心组件完全复用。
- 编码器(Encoder):负责对输入序列进行特征编码,捕捉输入的全局上下文信息,输出包含完整语义的上下文表征(Context Vector),所有层的输入输出均能看到整个序列的信息;
- 解码器(Decoder):负责基于编码器的表征和已生成的输出序列,预测下一个 token,采用自回归方式生成输出,同时通过掩码注意力避免看到未来的 token,保证生成的序列性。
核心模块组成:编码器由N 层相同的编码器层堆叠而成,解码器由N 层相同的解码器层堆叠而成(原论文中 N=6),且编码器、解码器的每层结构均包含注意力机制、前馈神经网络(FFN)、层归一化(Layer Normalization) 和残差连接(Residual Connection) 四大核心组件。
二、Transformer 核心前置组件:词嵌入 + 位置编码
Transformer 本身无内置的序列位置感知能力(所有 token 并行处理),而语言、时序等序列数据的位置信息至关重要,因此输入层必须通过词嵌入 + 位置编码,为每个 token 赋予语义信息和位置信息,二者拼接 / 相加后作为编码器 / 解码器的输入。
1. 词嵌入(Embedding)
将离散的 token(如单词、字)映射为低维稠密的实值向量,捕捉 token 的基础语义信息,维度记为d_model(原论文中 d_model=512),是 Transformer 中所有张量的核心维度,保证各模块间的维度兼容。
2. 位置编码(Positional Encoding)
通过数学公式为不同位置的 token 生成唯一的位置向量,与词嵌入向量逐元素相加(维度相同),让模型感知 token 的序列位置。原论文采用正弦余弦位置编码,公式简单且支持无限长度的序列(优于固定词典的位置嵌入),核心原理是:位置越近的 token,位置向量的相似度越高,位置越远则相似度越低,让模型学习到序列的相对位置和绝对位置。
三、Transformer 核心核心:自注意力机制(Self-Attention)
自注意力机制是 Transformer 的灵魂,核心作用是让序列中的每个 token,都能关注到序列中其他所有 token,并根据关联程度分配不同的注意力权重,最终融合成包含全局上下文信息的新表征。简单来说:每个 token 的新表征 = 自身信息 + 其他 token 的信息 × 关联权重,实现了对全局上下文的建模,且所有 token 的注意力计算并行完成。
1. 自注意力的核心计算步骤(以 Scaled Dot-Product Attention 为例,原论文采用)
输入为 3 个同维度向量(由词嵌入 + 位置编码生成,维度d_model):
- Q(Query):查询向量,代表 “当前 token 要找什么”;
- K(Key):键向量,代表 “其他 token 有什么”;
- V(Value):值向量,代表 “其他 token 的实际信息”;Q/K/V 由输入向量分别乘以 3 个可学习的权重矩阵WQ/WK/WV得到,维度均为dk(原论文中dk=64)。
计算流程共 4 步,全程并行:
- 计算注意力得分:将 Q 与 K 的转置做点积,衡量每个 Query 与所有 Key 的关联程度,得分越高则关联越强;
- 缩放(Scaled):将得分除以dk,避免因dk过大导致点积结果过大,进而让 Softmax 后权重过于极端(趋近 0 或 1),影响模型学习;
- 掩码(Mask,可选):仅解码器的自注意力使用,对未来位置的 token 得分置为 -∞,经 Softmax 后权重为 0,保证生成时不会看到未来的 token(编码器无掩码,可看到所有 token);
- Softmax 归一化:将缩放后的得分做 Softmax,得到注意力权重(所有权重和为 1),代表当前 token 对其他 token 的关注程度;
- 加权融合 Value:将注意力权重与 V 做矩阵乘法,得到当前 token 的上下文表征,融合了所有 token 的信息且带有关联权重。
核心公式:Attention(Q,K,V)=Softmax(dkQKT)V
2. 多头注意力(Multi-Head Attention):自注意力的升级
原论文并未直接使用单头自注意力,而是采用多头注意力,这是对自注意力的关键优化,核心是将 Q/K/V 拆分为 h 个独立的头(原论文 h=8),分别计算自注意力,再将结果拼接后线性变换,让模型能同时捕捉不同维度、不同类型的上下文关联(如语法关联、语义关联)。
多头注意力优势:单头注意力只能学习到一种全局关联,而多头注意力可让不同头关注不同的 token 关联(如一头关注相邻词,一头关注远距的核心词),提升模型对上下文的建模能力。
计算流程:
- 将 Q/K/V 分别通过 h 个权重矩阵,拆分为 h 组维度为dk=dmodel/h的子 Q / 子 K / 子 V;
- 每组子向量分别计算 Scaled Dot-Product Attention,得到 h 组子上下文表征;
- 将 h 组子表征拼接为维度dmodel的向量,再通过一个线性层做最终变换,得到多头注意力的输出。
3. 三种注意力的应用场景
Transformer 中多头注意力分为 3 类,适配编码器和解码器的不同需求:
- 编码器自注意力:双向自注意力,无掩码,输入序列的每个 token 可关注所有 token,捕捉输入的全局上下文;
- 解码器自注意力:掩码双向自注意力,带掩码,保证生成时仅关注已生成的 token,不看到未来;
- 编码器 - 解码器注意力:交叉注意力,Q 来自解码器上一层输出,K/V 来自编码器最终输出,让解码器的每个生成 token,都能关注到输入序列的所有 token(如机器翻译中,生成英文时关注中文原文的对应词)。
四、Transformer 每层的基础结构:残差连接 + 层归一化 + 前馈神经网络
编码器层和解码器层的核心组件除了注意力机制,还包含前馈神经网络(FFN),且所有核心模块均搭配残差连接和层归一化,保证模型的训练稳定性和梯度传播(避免深度堆叠导致的梯度消失)。
1. 前馈神经网络(FFN)
对注意力机制的输出做逐 token 的非线性变换,进一步提取深层特征,所有 token 并行计算,结构为两层全连接 + ReLU 激活,中间层维度为dff=2048(原论文),输出维度还原为dmodel。公式:FFN(x)=max(0,xW1+b1)W2+b2
2. 残差连接(Residual Connection)
将模块的输入与输出逐元素相加,形成 “短路连接”,核心作用是让梯度能直接通过残差路径传播至浅层,避免模型深度增加时的梯度消失问题。Transformer 中,多头注意力和FFN模块均配有残差连接,即:模块输出 = 模块输入 + 模块自身计算结果。
3. 层归一化(Layer Normalization,LN)
对每个 token 的特征向量做归一化处理(均值为 0,方差为 1),让模型的输入分布更稳定,提升训练速度和泛化能力。Transformer 采用 **“预归一化”** 方式(原论文后续优化的主流方式):层归一化放在模块输入前,即模块输入 = LN(上一层输出),再送入注意力 / FFN 模块,搭配残差连接形成 **“LN - 注意力 - 残差 - LN-FFN - 残差”** 的经典结构。
五、编码器与解码器的单层详细结构
1. 编码器单层结构(核心:双向自注意力)
输入 → 层归一化(LN)→ 多头自注意力(双向,无掩码)→ 残差连接 → 层归一化(LN)→ 前馈神经网络(FFN)→ 残差连接 → 输出核心特点:无掩码,全程捕捉输入序列的全局双向上下文,所有操作并行。
2. 解码器单层结构(核心:掩码自注意力 + 交叉注意力)
输入 → 层归一化(LN)→ 多头自注意力(掩码,仅看已生成 token)→ 残差连接 → 层归一化(LN)→ 多头交叉注意力(Q 来自解码器,K/V 来自编码器)→ 残差连接 → 层归一化(LN)→ 前馈神经网络(FFN)→ 残差连接 → 输出核心特点:先通过掩码自注意力建模已生成序列的上下文,再通过交叉注意力关联输入序列的信息,保证生成的 token 与输入语义匹配。
六、Transformer 的输出层:线性层 + Softmax
解码器的最终输出是维度为dmodel的张量,需通过输出层转换为对目标 token 的预测概率:
- 线性层:将解码器输出的dmodel维向量,映射至目标词表维度(如机器翻译的英文词表);
- Softmax 层:将线性层的输出做归一化,得到每个目标 token 的预测概率,概率最大的 token 即为模型的预测结果。
在生成任务中,解码器采用自回归方式:每次预测一个 token,将其加入解码器的输入,再预测下一个 token,直至生成结束符(<EOS>)。
七、Transformer 的核心优势与设计本质
1. 四大核心优势
- 并行计算:摒弃 RNN 的序列逐步处理,所有 token 的注意力、FFN 计算均并行完成,训练效率大幅提升,支持大批次、长序列训练;
- 全局上下文建模:自注意力机制让每个 token 能直接关注到序列的所有 token,无 RNN 的长距离依赖衰减问题,能更好捕捉长序列的语义关联;
- 模块化设计:编码器、解码器层高度复用,组件(注意力、FFN、LN、残差)解耦,便于裁剪(如仅用编码器做理解任务,仅用解码器做生成任务)和扩展;
- 跨领域适配性:无需修改核心结构,仅需调整输入输出层,即可适配 NLP(翻译、问答)、CV(ViT 做图像分类)、多模态(CLIP 做图文匹配)等多个领域。
2. 设计本质
Transformer 的本质是 “以自注意力机制为核心,通过编码器捕捉输入全局上下文,通过解码器自回归生成输出,全程基于并行计算的序列建模框架”,而 “Attention Is All You Need” 的核心内涵,是证明了仅靠注意力机制,即可实现比 RNN/CNN 更高效、更优的序列建模 **,颠覆了传统的序列建模思路。
八、Transformer 的经典衍生形态
标准 Transformer 的编码器 - 解码器架构适用于 Seq2Seq 任务,后续为适配不同场景,衍生出两大核心单塔形态,成为行业主流:
- 仅编码器架构(Encoder-only):代表模型 BERT,核心做自然语言理解(NLU) 任务(如文本分类、命名实体识别、语义匹配),采用双向自注意力,能充分捕捉输入的全局语义;
- 仅解码器架构(Decoder-only):代表模型 GPT 系列,核心做自然语言生成(NLG) 任务(如文本生成、对话、摘要),采用掩码自注意力,自回归生成序列,更贴合生成任务的序列性需求。
此外,还有 Encoder-Decoder 的改进版(如 T5、BART),通过引入 “掩码语言模型” 等预训练任务,提升模型的泛化能力,适用于更复杂的 Seq2Seq 任务。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)