基于YOLO和大语言模型的消化道息肉智能识别系统
🏥 基于YOLO和大语言模型的消化道息肉智能识别系统
项目演示地址:https://www.bilibili.com/video/BV1h9Q6BFEDR/
项目获取地址:https://mbd.pub/o/bread/YZWckpxvbQ==
1. 项目研究背景与意义
消化道息肉是消化系统中最常见的隆起性病变之一,尤其是结直肠息肉,被公认为是结直肠癌的重要癌前病变。据统计,约 80%~95% 的结直肠癌由腺瘤性息肉逐步恶变而来("腺瘤-癌"序列)。早期发现并切除息肉是预防结直肠癌最有效的手段。然而,在实际的消化内镜检查中,由于息肉形态多样(有蒂、无蒂、扁平型等)、部分病变与正常黏膜颜色相近,漏诊率在文献报告中高达 6%~27%,给临床诊疗带来了巨大挑战。
本项目旨在设计并实现一套消化道息肉智能识别与辅助诊断系统。系统通过目标检测模型(YOLOv8)对内镜实拍图像进行毫秒级、高精度的息肉病灶定位;同时,系统引入了开源多模态大语言模型(LLaVA)与 RAG(检索增强生成)技术,在识别息肉的基础上提供息肉分型参考、诊疗方案建议等交互式辅助诊断功能。本系统的研究不仅能够有效降低内镜检查的漏诊率,也为探索深度学习与大模型在医学影像领域的工程化落地提供了重要参考价值,
2. 数据集详细描述
本项目核心训练与评测数据基于公开的 Kvasir-SEG 消化道内镜图像数据集。
2.1 数据集来源与规模
Kvasir-SEG 数据集由挪威 SimulaMet 研究中心发布,是消化道息肉分割与检测领域的权威基准数据集。
- 图像总数:1000 张高分辨率消化道内镜图像
- 标注格式:提供精确的像素级分割掩码(masks)及边界框(bounding box)标注
- 类别:polyp(息肉)— 单类别目标检测任务
- 标注文件:
kavsir_bboxes.json包含每张图像的宽高信息及所有息肉的边界框坐标
2.2 数据集处理工程
项目中内置了专门针对 Kvasir-SEG 数据集设计的转换脚本(convert_to_yolo.py)。该脚本实现了:
- JSON 标注解析:自动解析
kavsir_bboxes.json中的边界框坐标,提取xmin/ymin/xmax/ymax信息。 - 坐标归一化转换:将绝对像素坐标转换为 YOLO 标准格式的归一化中心点坐标(
x_center, y_center, width, height)。 - 自动划分数据集:严格按照
80% : 20%的比例随机划分训练集(Train)和验证集(Val)。 - 配置生成:自适应生成
data.yaml配置清单,直接对接 YOLO 模型训练。
3. 核心算法与理论基础
3.1 目标检测算法:YOLOv8
本项目选用 Ultralytics 发布的最先进目标检测框架 YOLOv8 作为核心视觉识别底座。
- 骨干网络 (Backbone):采用了增强版的 CSPDarknet 设计,引入了 C2f 模块来取代原有的 C3,强化了网络在提取不同尺度息肉特征时的信息流梯度,从而提高对小型扁平息肉的感知能力。
- 无锚框设计 (Anchor-Free):YOLOv8 摒弃了由人工经验设定的 Anchor Boxes,直接预测目标中心点及其边界距离(Decoupled Head),使模型具备极强的泛化能力,能够适应内镜图像中息肉大小和形态的巨大差异。
3.2 多模态视觉语言模型:LLaVA
除了边界框检测和标签分类,本项目集成了视觉指令微调模型 LLaVA (Large Language-and-Vision Assistant)。
- LLaVA 将视觉编码器(如 CLIP ViT-L/14)与大语言模型(LLaMA/Vicuna)相结合,具备极强的看图说话能力。
- 项目中封装了针对消化内科领域的
System Prompt,引导 LLaVA “扮演消化内科医学影像诊断专家”,对内镜图像中的息肉进行形态学分析和分型参考。
3.3 检索增强生成 (RAG)
为防止 AI 大模型"幻觉"现象导致错误的医学建议,系统设计了 RAG 流程。当 YOLOv8 识别出息肉时,系统会自动从 SQLite 医学知识库抽取该类型息肉的标准《临床表现》和《诊疗方案》,拼接成 Context 送入大模型,使得最终生成的诊断分析准确可控。
4. 系统总体架构与模块设计
系统采用前后端分离的主流现代前后端架构。
┌───────────────────────────────────────────────────────────────┐
│ 前端 Web 展示层 (React + Vite) │
│ ┌──────────────┐ ┌──────────────┐ ┌─────────────┐ ┌────────┐ │
│ │ 智能诊断台 │ │ 数据分析大屏│ │ 模型在线训练│ │医学知识库│ │
│ └──────────────┘ └──────────────┘ └─────────────┘ └────────┘ │
└─────────────────────────┬─────────────────────────────────────┘
│ HTTP RESTful API (Axios通信)
┌─────────────────────────┴─────────────────────────────────────┐
│ 核心业务逻辑层 (FastAPI + Python) │
│ ┌──────────────┐ ┌──────────────┐ ┌─────────────┐ │
│ │ YOLO 推理引擎 │ │ RAG 与多模态控制│ │ 多线程训练调度│ │
│ └──────────────┘ └──────────────┘ └─────────────┘ │
└────────┬────────────────────────┬──────────────────────┬──────┘
│ │ │
┌────────┴────────┐ ┌────────┴────────┐ ┌────────┴────────┐
│ SQLite 关系数据库│ │ 本地文件系统/模型│ │ Ollama 模型微服务│
│ (知识库/检测历史)│ │ (YOLO 权重/源图片)│ │ (LLaVA-13B) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
包含的五大主打前台应用:
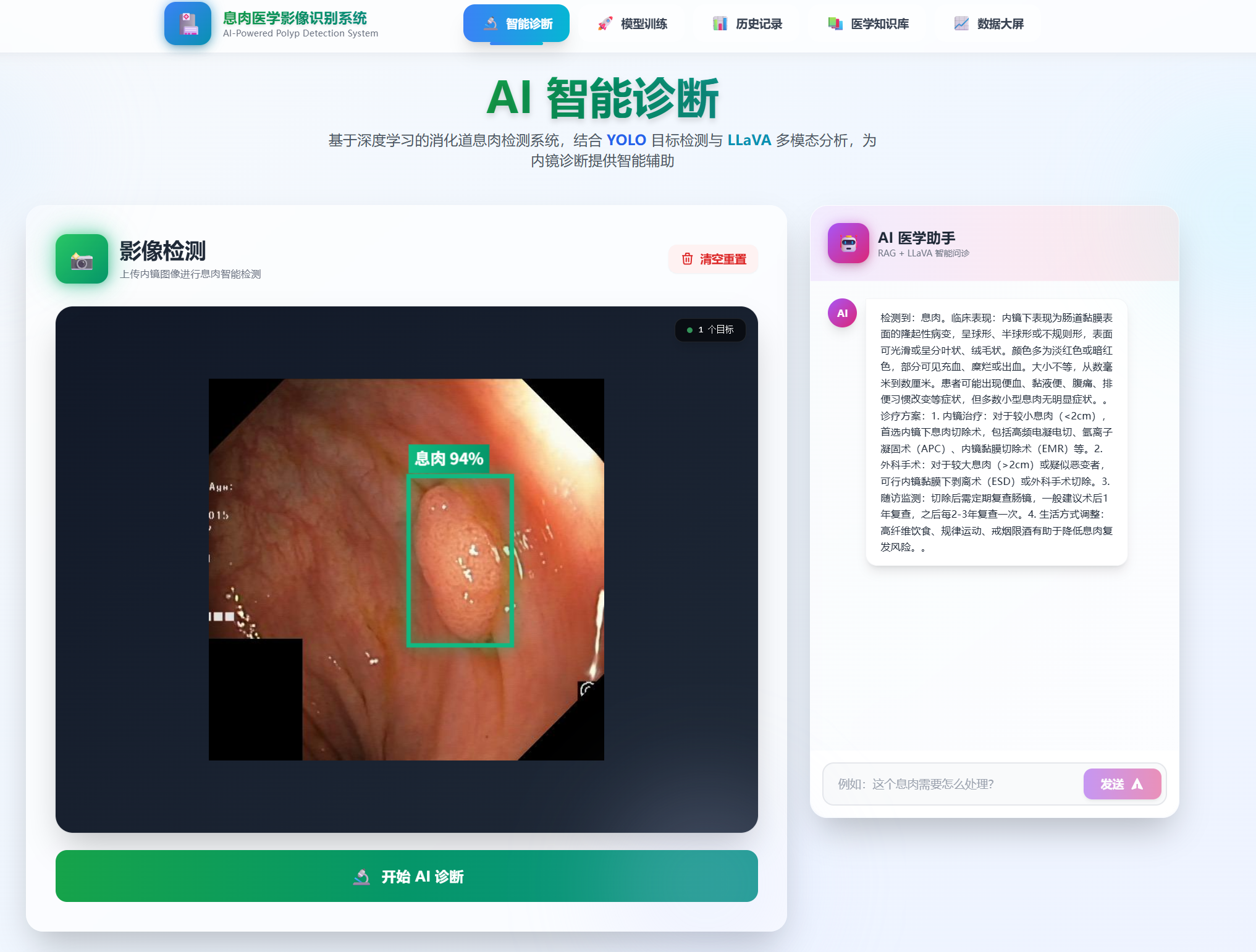
- Dashboard 智能诊断:支持拖拽上传内镜图像、息肉实时框选与渲染、AI 医学助手交互界面。
- Statistics 数据大屏:通过读取历史数据,统计息肉检出率、分布排行,并提供系统级临床洞察分析。
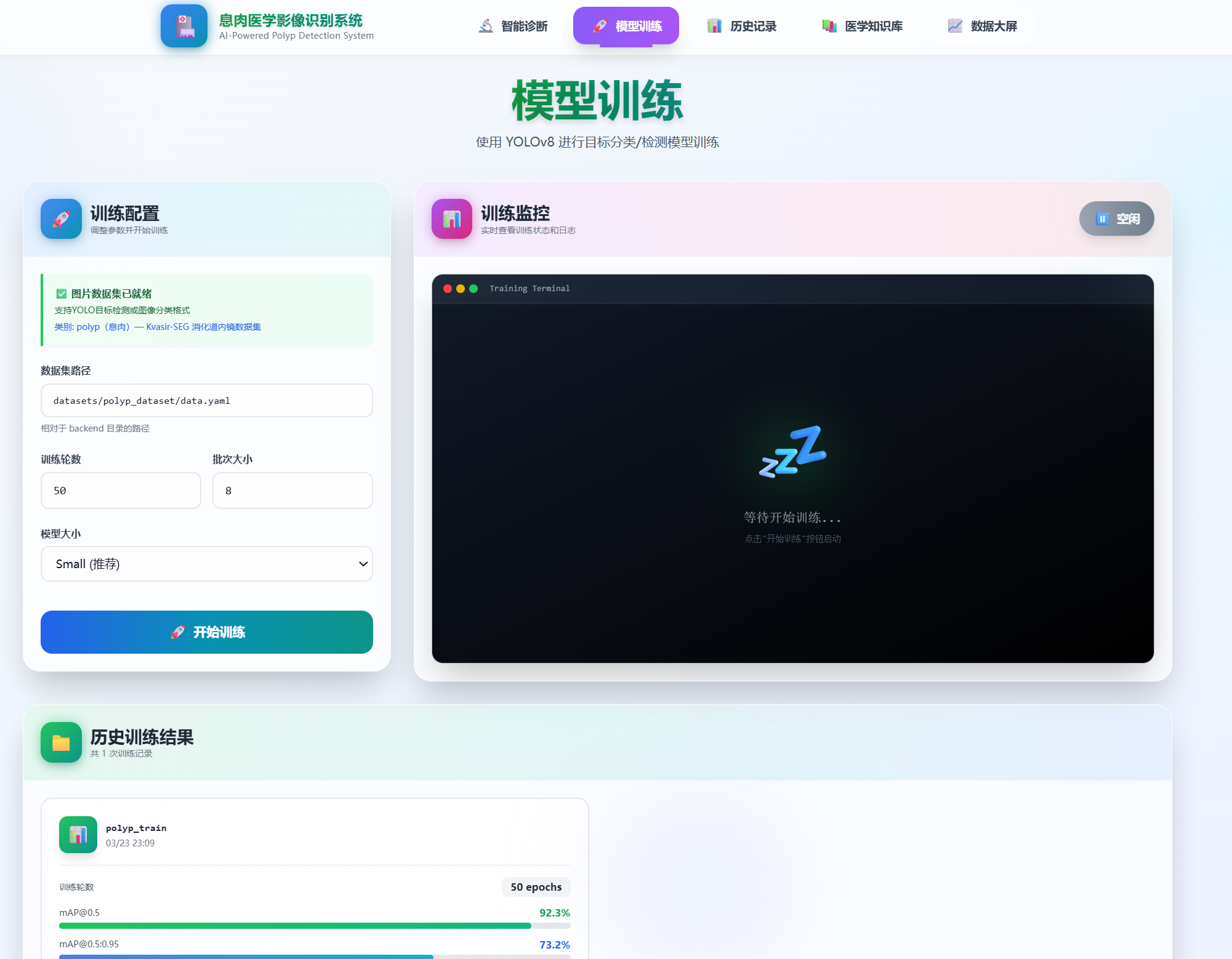
- Training 模型训练:用户可以在网页端自主选择数据集、设置 Epoch、并发 Batch,直接驱动后端 YOLO 开启训练,并实时追踪 Loss、mAP 指标。
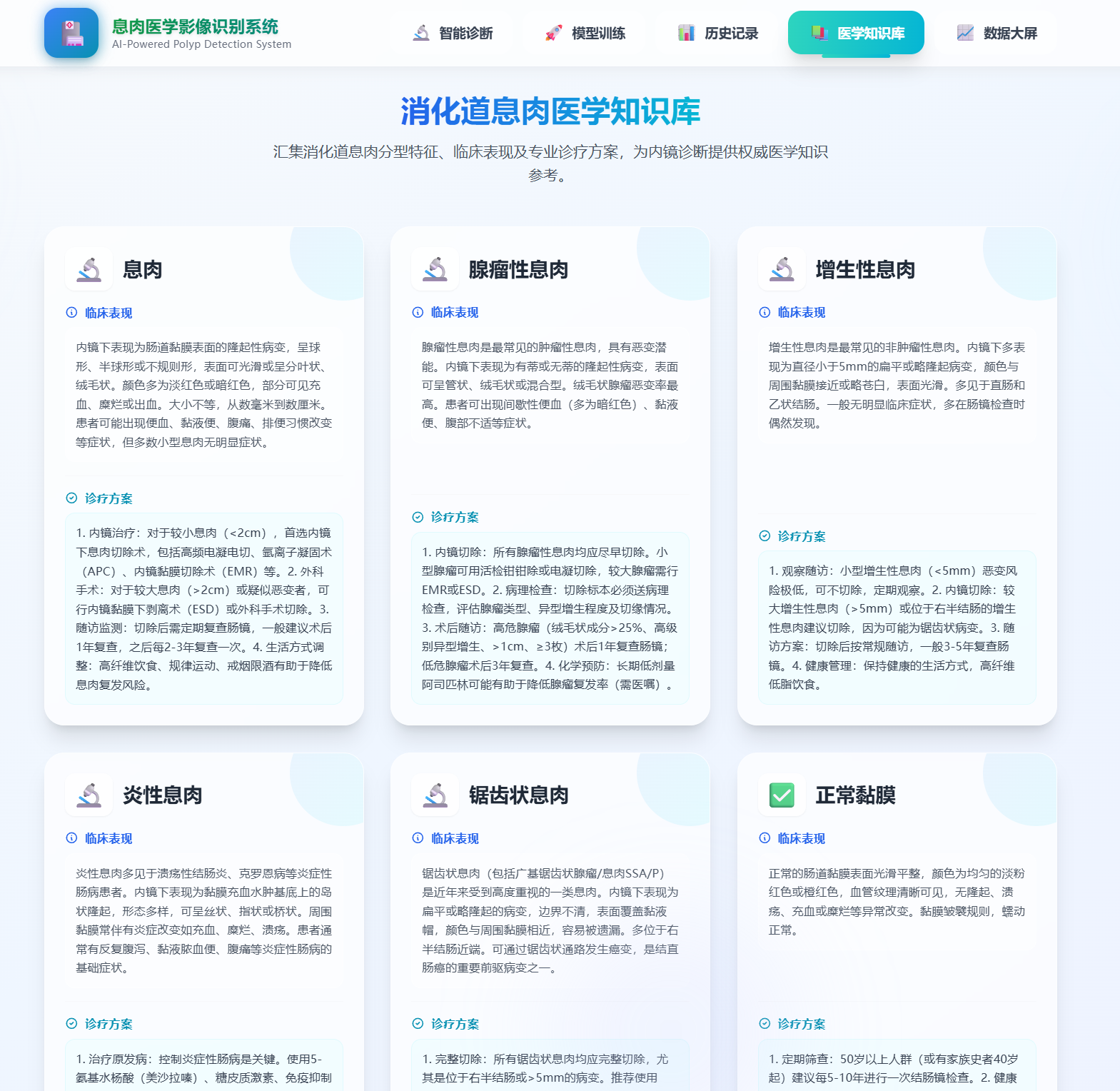
- Knowledge Base 医学知识库:完整的独立网格化排布的图文库,列出消化道息肉各类型的临床表现及诊疗方案。
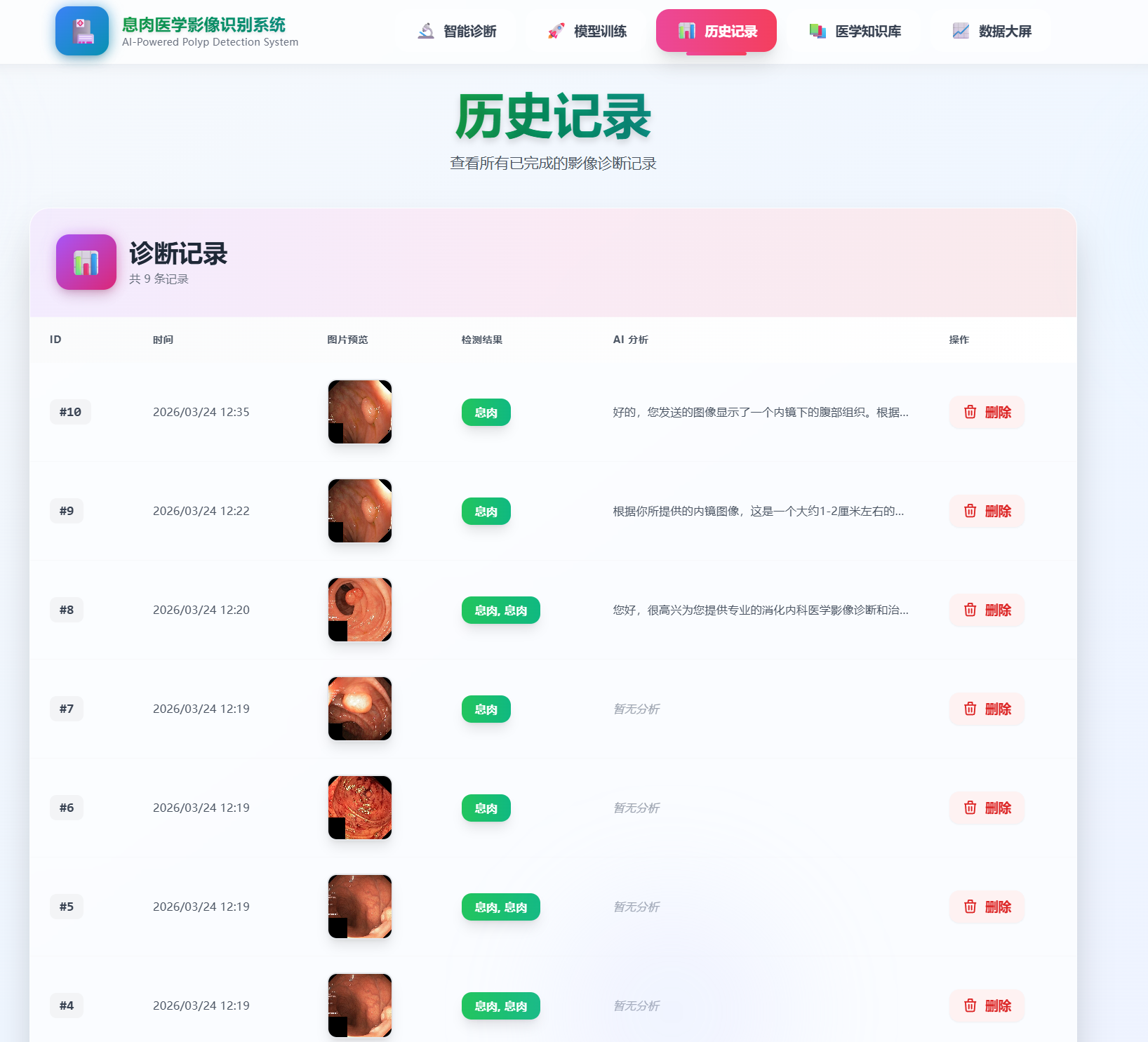
- History 留存记录:支持回看与销毁过往的检测诊断数据。
5. 核心代码模块解析
本项目结构清晰,各司其职,适合基于此扩展和二次开发:
backend/main.py: 基于 FastAPI 的路由中枢系统。处理请求鉴权、静态资源代理挂载,以及协调detector和analyzer返回息肉位置坐标与 AI 分析文字。backend/engine.py: AI 模型调度工厂。封闭实现了YOLODetector(使用 PyTorch 驱动硬件进行推断) 及LLaVAAnalyzer(实现图像的 Base64 转码及动态 Prompt 构建以连接本地端大模型)。backend/training.py: 多线程训练管理器。通过 Python 的threading保护非阻塞的主线程运转,允许外部实时获取训练日志。backend/convert_to_yolo.py: Kvasir-SEG 数据集转换脚本。解析 JSON 标注文件,将边界框转换为 YOLO 格式。frontend/src/App.jsx: 前端 React 骨架。应用了 Tailwind CSS 构建"玻璃拟态(Glassmorphism)"全局外观,实现 SPA 标签页路由切换。frontend/src/pages/: 存放了各面板业务的核心逻辑和可视化图表绘制。
6. 实验平台与环境要求
为保证顺利复现和训练,建议平台环境满足以下指标。
硬件要求
- CPU: 四核心及以上(推荐Intel i5/i7或同等规格)
- 内存: 8GB RAM(涉及大模型与图形识别交叠推荐 16GB 以上)
- GPU: NVIDIA GPU,具备 6GB 以上显存(强烈推荐用于模型训练;单纯测试推理 CPU 亦可平替)
软件环境
- 操作系统: Windows 10/11, Ubuntu 20.04+
- 关键依赖栈: Python 3.8+, Node.js 18.0+, PyTorch (推荐搭配对应 CUDA 版本的环境)
7. 快速部署与启动指南
步骤 1:安装 Ollama 与大模型基座
系统依赖本地的 LLaVA 多模态模型负责辅助诊断输出。
- 前往
ollama.com或者在终端直接输入(Mac/Linux):curl -fsSL https://ollama.com/install.sh | sh - 运行模型拉取命令:
ollama pull llava
步骤 2:数据集准备与转换
cd backend
# 运行数据集转换脚本,将 Kvasir-SEG 转换为 YOLO 格式
python convert_to_yolo.py
(脚本会自动读取 datasets/kvasir-seg/kavsir_bboxes.json,按 80:20 比例划分训练集和验证集)
步骤 3:启动后端引擎(API 层)
cd backend
# 推荐使用虚拟环境或 conda,安装系统依赖
pip install -r requirements.txt
# 启动服务端 (若遇到 WinError 10013 端口占用,可修改为 --port 8080)
uvicorn main:app --reload --host 0.0.0.0 --port 8000
(系统首次运行时,会自动根据 data/diseases.json 在后台初始化创建 sql_app.db 医学知识库数据库。)
步骤 4:启动前端可视化面板
cd frontend
# 拉取最新的 node_modules 依赖库
npm install
# 热部署启动 Vite 服务器
npm run dev
前端服务将运行在 http://localhost:5173
步骤 5:访问应用
在浏览器打开 http://localhost:5173,开始使用系统!
📖 使用指南
智能诊断
-
上传图像
- 点击上传区域或拖拽内镜图像到上传框
- 支持 JPG、PNG 格式
- 建议使用高清内镜截图
-
开始检测
- 点击"开始 AI 诊断"按钮
- 等待几秒钟,系统会自动检测息肉
- 检测结果显示在图片上方
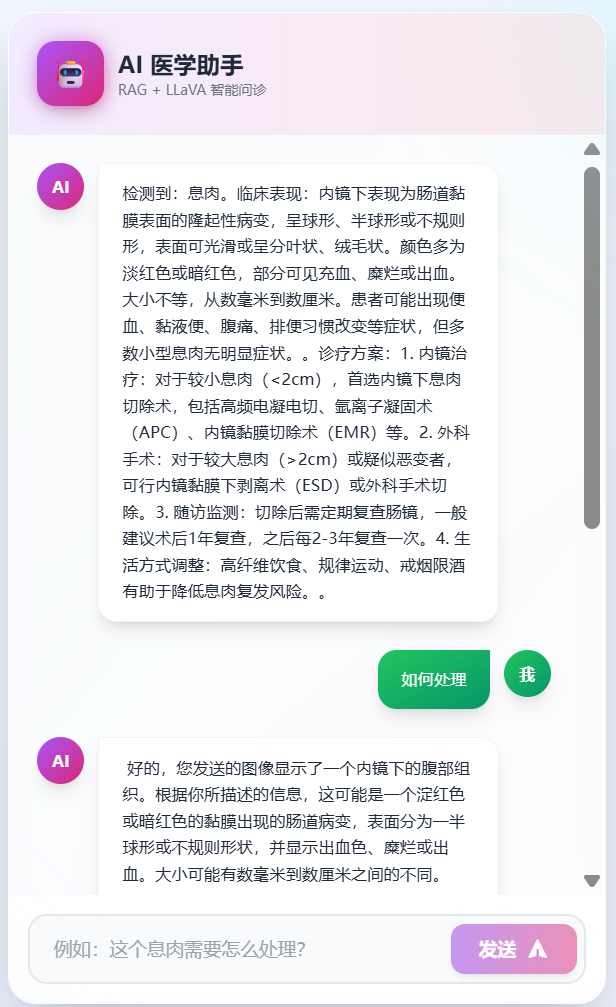
-
AI 问诊
- 在右侧对话框输入问题
- 例如:“这个息肉需要怎么处理?”
- AI 会基于检测结果和医学知识库回答
模型训练
-
准备数据集
- 使用 YOLO 格式的数据集
- 运行
convert_to_yolo.py转换 Kvasir-SEG 数据集 - 包含
data.yaml配置文件
-
配置参数
- 设置训练轮数(epochs)
- 选择批次大小(batch size)
- 选择模型尺寸(n/s/m/l/x)
-
开始训练
- 点击"开始训练"按钮
- 在终端查看实时日志
- 训练完成后查看指标
历史记录
- 查看所有诊断记录
- 点击记录查看详情
- 删除不需要的记录
📁 项目结构
PDS/
├── backend/ # 后端代码
│ ├── main.py # FastAPI 主应用
│ ├── engine.py # YOLO 和 LLaVA 引擎
│ ├── training.py # 训练管理器
│ ├── models.py # 数据库模型
│ ├── database.py # 数据库配置
│ ├── convert_to_yolo.py # Kvasir-SEG 数据集转换脚本
│ ├── requirements.txt # Python 依赖
│ ├── model.pt # YOLO 模型文件
│ ├── uploads/ # 上传的图片
│ ├── runs/ # 训练结果
│ └── datasets/ # 数据集目录
│ ├── kvasir-seg/ # Kvasir-SEG 原始数据集
│ │ ├── images/ # 1000张内镜原图
│ │ ├── masks/ # 分割掩码
│ │ └── kavsir_bboxes.json # 边界框标注
│ └── kvasir-sessile/ # Kvasir-Sessile 扩展数据集
│
├── frontend/ # 前端代码
│ ├── src/
│ │ ├── pages/
│ │ │ ├── Dashboard.jsx # 主诊断页面
│ │ │ ├── Training.jsx # 训练页面
│ │ │ ├── History.jsx # 历史记录页面
│ │ │ ├── KnowledgeBase.jsx # 医学知识库
│ │ │ └── Statistics.jsx # 数据大屏
│ │ ├── App.jsx # 应用主组件
│ │ └── index.css # 全局样式
│ ├── public/ # 静态资源
│ ├── package.json # Node 依赖
│ ├── vite.config.js # Vite 配置
│ ├── tailwind.config.js # Tailwind 配置
│ └── postcss.config.js # PostCSS 配置
│
├── data/
│ └── diseases.json # 息肉医学知识库
│
└── README.md # 本文件

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)