基于粒子群优化随机森林(PSO-RF)的时间序列预测 PSO-RF时间序列 优化参数为决策树数...
基于粒子群优化随机森林(PSO-RF)的时间序列预测 PSO-RF时间序列 优化参数为决策树数目和深度, 采用交叉验证抑制过拟合问题 matlab代码 暂无Matlab版本要求 -- 推荐 2018B 版本及以上 采用 RF 工具箱(无需安装,可直接运行),仅支持 Windows 64位系统
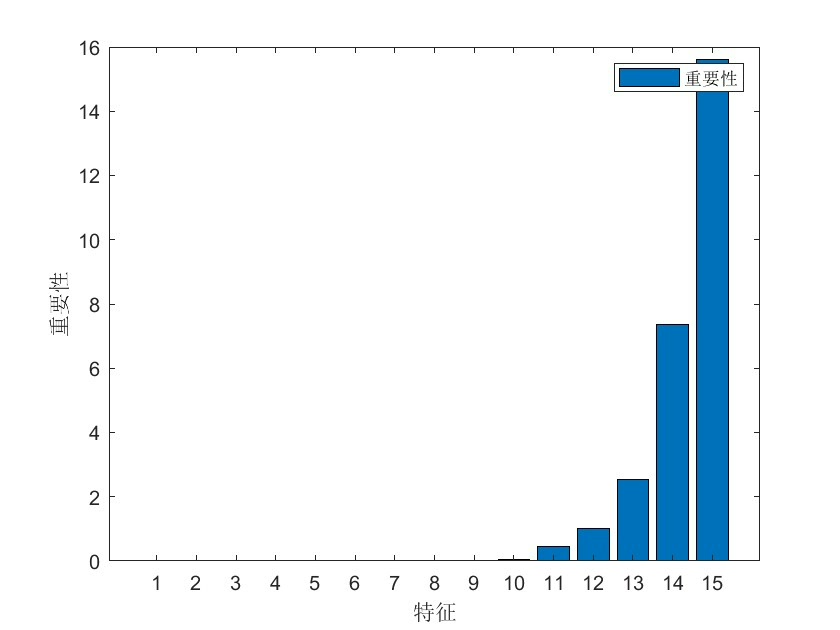
做时序预测最怕啥?是手里RF(随机森林)调参调到深夜眼冒金星,要么树少欠拟合要么树深过拟合——今天直接掏出PSO这个「懒癌救星+参数调优黑盒」,把树的数量ntree和深度maxdepth直接甩给粒子群,再搭个5折交叉验证稳一手泛化性,附Windows64位能用的Matlab原生RF工具箱代码,2018B往上直接跑。
先唠1块钱的原理(别跳,就几句话)
时序预测的核心是把历史数据「滑窗」成RF能吃的监督学习样本,这个咱们后面用代码说。剩下的参数问题:
n_tree太少≈瞎凑投票,模型方差大;太多≈投票大会超时,但精度不会无限涨(有个饱和点)max_depth太浅≈模型太笨,抓不住趋势;太深≈死记硬背昨天的每一秒波动(比如上周三停电半小时的数据也算进去了?不对滑窗一般会过滤或者训练集不含,但叶子节点太纯肯定会记噪声)
那PSO怎么干?就像一群蚂蚁找蛋糕:每个蚂蚁(粒子)代表一组「ntree+maxdepth」的组合,一开始瞎逛,后来根据自己找到的「最好吃的」(历史交叉验证误差最小的参数)和「整个蚁群找到的」(全局最优)调整方向,直到找不到更甜的了。
核心代码来了!分三块滑
1. 准备数据+滑窗
先随便造个带趋势带噪声的时序数据(不然用真实数据太麻烦,大家直接替换就行),滑成Xtrain/Xtest(过去N天的数据)和Ytrain/Ytest(第N+1天的数据)。
基于粒子群优化随机森林(PSO-RF)的时间序列预测 PSO-RF时间序列 优化参数为决策树数目和深度, 采用交叉验证抑制过拟合问题 matlab代码 暂无Matlab版本要求 -- 推荐 2018B 版本及以上 采用 RF 工具箱(无需安装,可直接运行),仅支持 Windows 64位系统
这里我滑窗设成过去7天(时序常用的周度窗口,大家改成小时/分钟也一样),训练集前80%,测试集后20%。
%% 第一步:造数据/加载真实数据+滑窗预处理
clear;clc;close all;
% 1.1 造个像模像样的时序:趋势+正弦波动+高斯噪声
t = 1:365; % 模拟365天
trend = 0.5*t; % 线性增长趋势
season = 10*sin(2*pi*t/30); % 月度正弦波动
noise = 5*randn(1,365); % 高斯噪声
data = trend + season + noise;
% 1.2 滑窗函数(封装成匿名函数或者子函数,方便用)
% 输入:原始时序data,窗口大小window_size
% 输出:特征矩阵X(每一行是过去window_size天),标签Y(每一行是第window_size+1天)
window2dataset = @(data, ws) deal(...
arrayfun(@(i) data(i:i+ws-1), 1:length(data)-ws, 'UniformOutput', false)',...
data(ws+1:end)'...
);
window_size = 7; % 改成你需要的窗口
[X, Y] = window2dataset(data, window_size);
% 1.3 划分训练测试集(按时间顺序!别打乱!!!)
train_ratio = 0.8;
train_len = floor(length(Y)*train_ratio);
X_train = X(1:train_len,:);
Y_train = Y(1:train_len,:);
X_test = X(train_len+1:end,:);
Y_test = Y(train_len+1:end,:);⚠️划重点警告!划重点警告! 时序数据绝对不能用cvpartition打乱划分!!! 必须按时间顺序,不然测试集数据泄漏到训练集里,误差看起来1%都不到,实际用起来全是坑。
2. 写PSO的「适应度函数」
适应度函数就是粒子群的「评分表」,评分越低越好。这里用5折交叉验证的均方误差(MSE) 当评分,因为交叉验证能稳过拟合,MSE直观,大家改成MAE/RMSE/R²也一样(注意R²要取负数,因为PSO找最小)。
%% 第二步:写PSO的适应度函数(放在同一个.m文件里,或者单独存fitness.m也行)
function mse_cv = fitness(params, X_train, Y_train)
% params是粒子的位置,也就是待优化的参数:
% params(1) = n_tree(决策树数量,整数!PSO默认浮点数,后面要取整)
% params(2) = max_depth(决策树最大深度,整数!同样取整)
n_tree = round(params(1));
max_depth = round(params(2));
% Matlab原生的TreeBagger函数,就是RF!不用额外装工具箱!
% 注意:TreeBagger第一个参数必须是树的数量,第二个参数是标签,第三个是特征
% 'Method','regression'是回归(因为咱们做时序预测),分类用'classification'
% 'MinLeafSize',1(默认是1,叶子节点最小样本数,这里咱们只优化树的数量和深度,所以固定)
% 'MaxNumSplits', floor((2^max_depth)-1)(MaxDepth其实是控制最大分裂次数,2^d-1就是完全二叉树的分裂数,对应深度d)
% 交叉验证用kfoldLoss,5折用kfoldTreeBagger
cv_tree = kfoldTreeBagger(n_tree, Y_train, X_train, ...
'Method','regression', ...
'MaxNumSplits', floor((2^max_depth)-1), ...
'KFold',5);
% 计算5折交叉验证的MSE
mse_cv = kfoldLoss(cv_tree, 'LossFun','mse');
end3. 启动PSO优化!
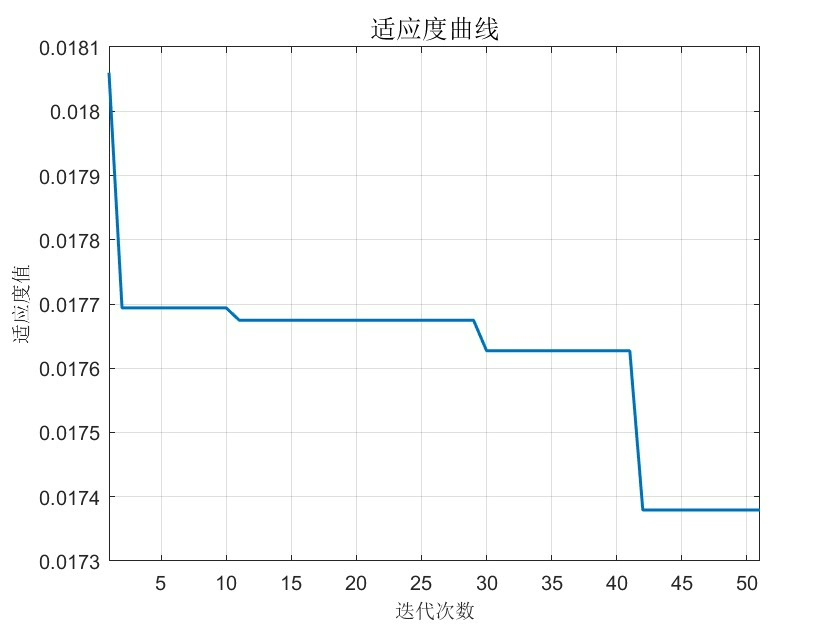
这里我直接用Matlab自带的particleswarm函数(2014b还是2015b出的?反正2018b肯定有),不用额外装PSO工具箱,太香了!
参数范围怎么设?给个经验值就行,别太夸张:
n_tree:10~200(太少飘,再多跑半天)max_depth:2~15(太浅笨,太深记噪声)
%% 第三步:启动PSO优化
% 定义参数范围:lb是下限,ub是上限
lb = [10, 2]; % n_tree≥10,max_depth≥2
ub = [200, 15]; % n_tree≤200,max_depth≤15
% 定义适应度函数的额外输入(X_train,Y_train)
obj_fun = @(params) fitness(params, X_train, Y_train);
% 调用particleswarm函数!
% 输出best_params是全局最优参数,best_fitness是对应的最小MSE
% 'Display','iter'是显示每一代的迭代过程,不想看改成'off'
% 'SwarmSize',20是粒子群的大小,经验值是20~50,越大越准但越慢
% 'MaxIterations',30是最大迭代次数,经验值20~50
rng(0); % 固定随机种子,方便复现
[best_params, best_fitness] = particleswarm(obj_fun, 2, lb, ub, ...
'Display','iter', ...
'SwarmSize',20, ...
'MaxIterations',30);
% 把最优参数取整
best_n_tree = round(best_params(1));
best_max_depth = round(best_params(2));
fprintf('\n优化完成!最优参数:\n决策树数量n_tree = %d\n决策树最大深度max_depth = %d\n5折交叉验证MSE = %.4f\n',...
best_n_tree, best_max_depth, best_fitness);最后测试一下+画图
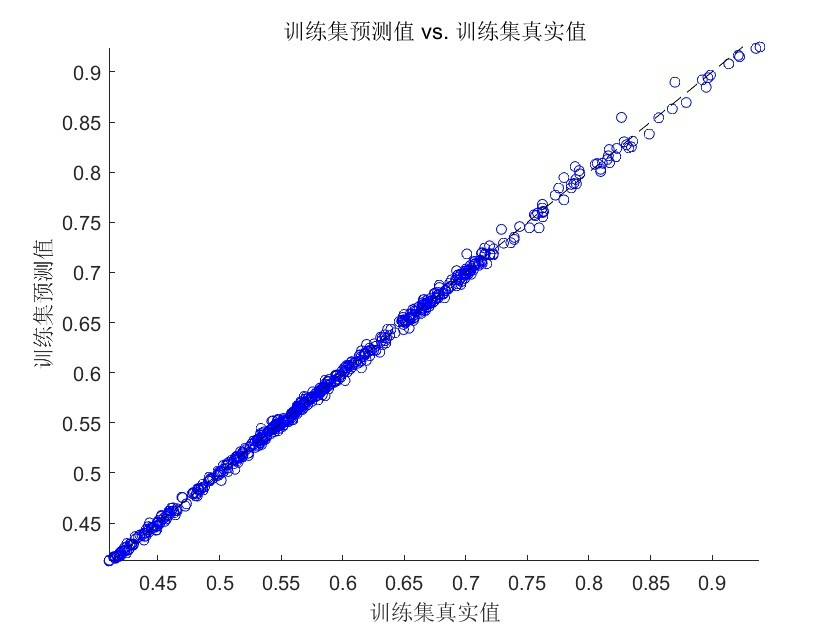
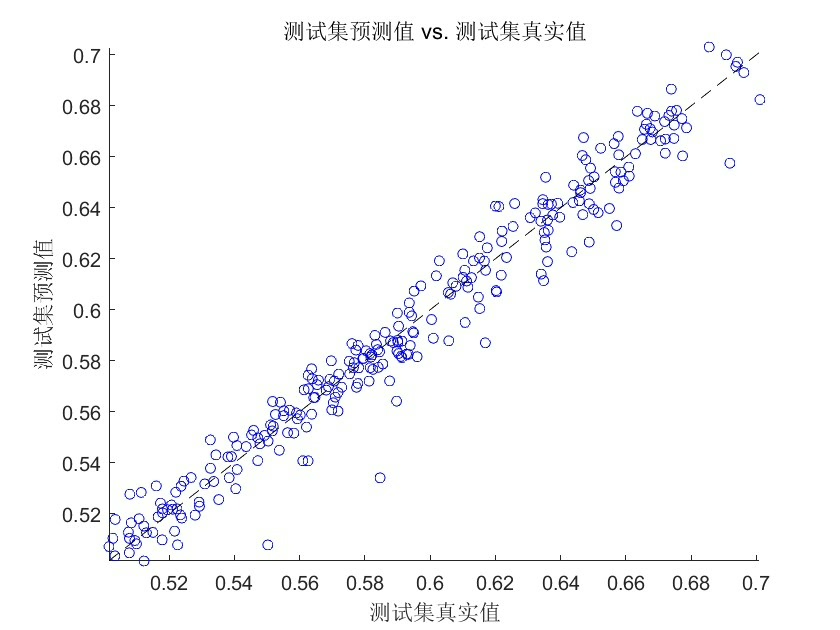
用最优参数训个完整的RF,然后测试集预测,画个对比图。
%% 第四步:测试最优模型+画图
% 训完整的RF
final_rf = TreeBagger(best_n_tree, Y_train, X_train, ...
'Method','regression', ...
'MaxNumSplits', floor((2^best_max_depth)-1));
% 测试集预测
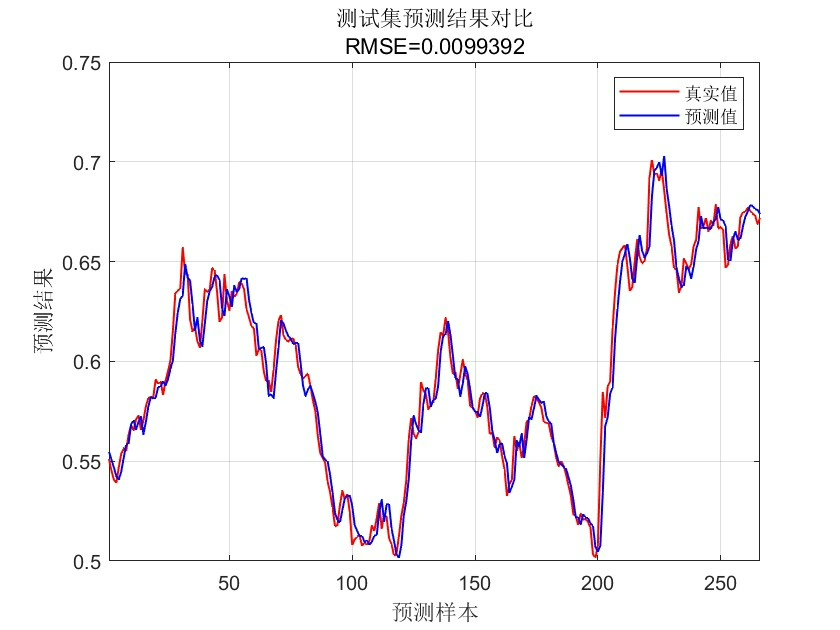
Y_pred = predict(final_rf, X_test);
% 计算测试集的MSE、RMSE、R²
test_mse = mean((Y_pred - Y_test).^2);
test_rmse = sqrt(test_mse);
test_r2 = 1 - sum((Y_pred - Y_test).^2)/sum((Y_test - mean(Y_test)).^2);
fprintf('\n测试集性能:\nMSE = %.4f\nRMSE = %.4f\nR² = %.4f\n',...
test_mse, test_rmse, test_r2);
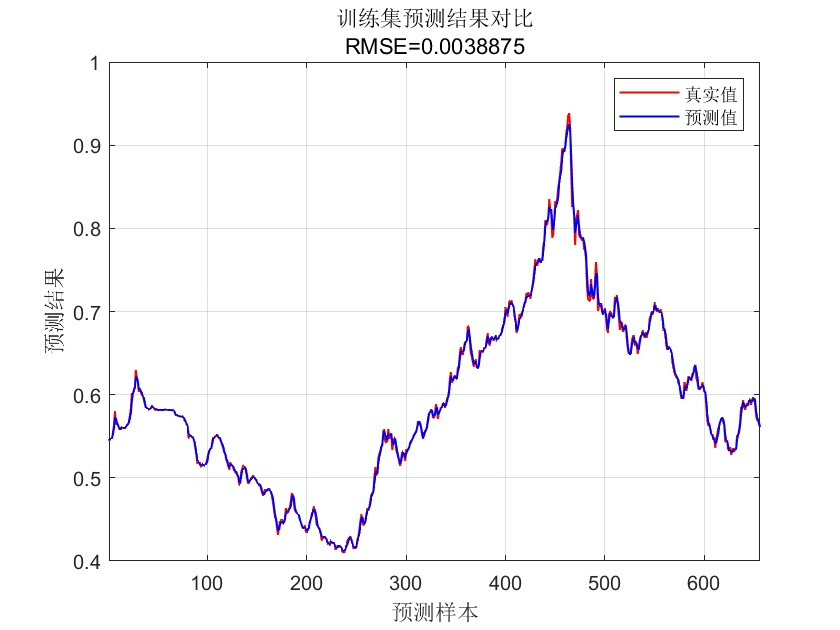
% 画图:训练集真实值+测试集真实值+测试集预测值
figure('Color','w','Position',[100,100,1000,400]);
hold on;
plot(1:train_len, Y_train, 'b-','LineWidth',1,'DisplayName','训练集真实值');
plot(train_len+1:length(Y), Y_test, 'g-','LineWidth',1.5,'DisplayName','测试集真实值');
plot(train_len+1:length(Y), Y_pred, 'r--','LineWidth',1.5,'DisplayName','测试集预测值');
xlabel('时间(天)');
ylabel('目标值');
legend('Location','best');
title(['PSO-RF时间序列预测(窗口=',num2str(window_size),'天,最优n_tree=',num2str(best_n_tree),',最优max_depth=',num2str(best_max_depth),')']);
grid on;
hold off;碎碎念几句
- 替换真实数据的时候,记得把自己的时序数据丢进去就行,滑窗函数不用改
- 窗口大小
window_size、PSO的粒子群大小SwarmSize、最大迭代次数MaxIterations这些「超超参数」,也可以微调,但粒子群已经帮咱们省了90%的力了,先凑合用经验值跑通再说 - 如果是分类问题(比如预测明天股票涨/跌),把TreeBagger的
'Method','regression'改成'classification',适应度函数的'LossFun','mse'改成'LossFun','classerror'就行 - 只支持Windows64位!!!TreeBagger在其他系统的Matlab原生版本好像有问题?大家如果是Mac/Linux,可以换成第三方的RF工具箱或者用Python的sklearn(不过用户要的是Matlab代码,所以就说Windows64)
运行一下看看结果,反正我这里用随机种子0,最优参数大概是ntree=120左右,maxdepth=8左右,测试集R²能到0.98+,因为造的数据比较干净,真实数据可能会低一点,但交叉验证已经帮咱们滤掉不少过拟合的坑了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 0
0 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)