VLA的下一步怎么走?CVPR 2026给出了四个关键词
瓶颈虽未破,但破局方向有
——顶会盘点
目录
02 See, Plan, Rewind:赋予VLA模型进度感知与闭环纠错能力
04 RehearseVLA:基于物理一致世界模型的VLA模拟后训练
06 ManualVLA:从“是什么”到“怎么做”,赋予机器人长时域任务规划能力
此前我们曾分享过关于 VLA 发展的冷静判断:VLA 并非方向错误,而是受限于当下技术与数据条件,难以快速实现通用化突破:
“
一是 VLM 视觉表征能力不足,杂乱场景识别、3D 空间推理能力薄弱;
二是模型缺乏真实物理世界常识,生成与决策不符合物理规律;
三是动作 - 视觉多模态训练数据极度匮乏,难以支撑规模化泛化学习;
四是现有范式难以统一多技能、长时序任务,模型合并与技能复用效果极差。
关于其能否真正走向通用具身智能仍存在诸多争议与质疑,但作为当前具身智能领域的核心方向,VLA的每一次实质性的突破都引发圈内不小的关注。
本次CVPR 2026收录的多项VLA工作,恰好针对上述痛点展开针对性探索,本次我们立足客观视角,盘点六篇代表性工作,呈现VLA在现实约束下的真实演进路径。
本文所选取的论文,均来自近期发布于arXiv的CVPR 2026VLA相关工作,力求覆盖当前研究的几条核心脉络。受限于篇幅,更多同样出色甚至更具影响力的工作未能在本文中得到呈现。欢迎在评论区留言补充,我们也会持续追踪和介绍这一领域的最新进展。
01 MergeVLA:迈向通用VLA代理的跨技能模型合并
在大型语言模型和视觉模型领域 ,模型合并(Model Merging)已被证明是一种整合多任务能力的有效方法,它可以在不重新训练或访问原始数据集的情况下,将多个专业化模型整合成一个统一的模型。
然而,当研究人员尝试将这种方法应用于在不同操作任务上微调的VLA专家模型时,却发现合并后的模型成功率几乎为零。
昆士兰大学的研究团队深入剖析了这一反常现象,发现其根本原因在于两点:
-
微调使得VLM主干中的LoRA适配器朝向发散的、任务特定的方向发展,产生了严重的参数冲突;
-
动作专家通过自注意力反馈形成了跨层依赖,导致任务信息在全局扩散,阻碍了模块化的重组;

技术亮点:
为了解决上述不可合并的问题,研究团队提出了 MergeVLA,这是一种从设计之初就保留“可合并性”的创新架构:
-
稀疏激活的LoRA适配器:通过引入任务掩码(Task Masks),MergeVLA能够选择性地激活对当前任务有贡献的合并参数,同时抑制那些会误导其他任务的参数。
-
纯交叉注意力动作专家:模型对动作专家进行了重新配置,移除了自注意力传播,仅依赖交叉注意力路径。
-
测试时任务路由器:在推理阶段,当任务身份未知时,MergeVLA采用了一个无需训练的任务路由器。
在真实的SO101机械臂上,MergeVLA实现了高达90.0%的成功率,而且展现出了跨任务、跨环境和跨具身的强大泛化能力。
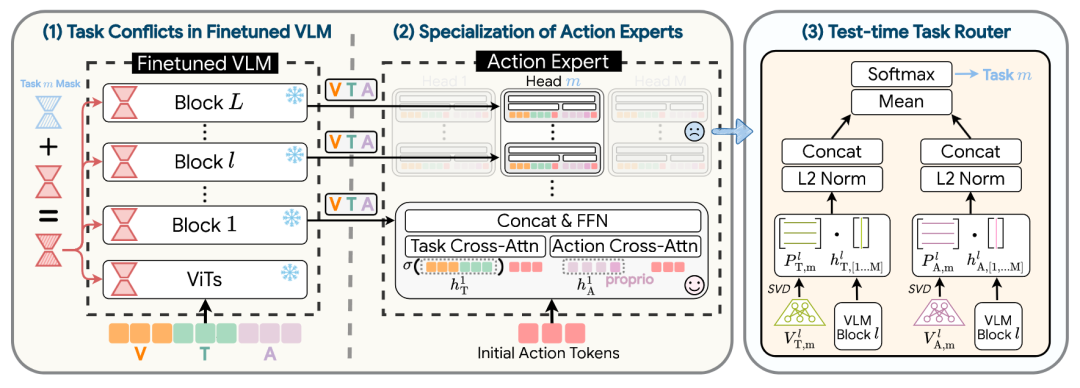
▲MergeVLA架构概览。
02 See, Plan, Rewind:赋予VLA模型进度感知与闭环纠错能力
在日常生活中 ,人类在执行抓取和操作任务时,大脑会自然而然地将目标分解为多个中间阶段性目标,规划手部轨迹,并持续监控执行进度——这一切几乎是在潜意识中完成的。

如何让机器人像人类一样,拥有明确的、基于空间的进度感知并实现自主闭环纠错,成为了一个亟待解决的挑战。
技术亮点:
为了赋予VLA模型这种认知能力,中国科学技术等研究团队提出了 See, Plan, Rewind (SPR) 框架,通过一个持续的闭环周期来实现稳健的机器人操作:
-
细粒度空间子任务规划(See & Plan):模型不再仅仅依赖抽象的语言指令,而是将任务分解为一系列具体的2D空间航点(waypoints)。在“See”阶段,模型识别剩余的子任务并输出其2D空间坐标;在“Plan”阶段,模型规划出从当前夹爪位置到下一个子目标航点的2D轨迹。
-
进度驱动的异常检测与回溯(Rewind):在执行过程中,SPR通过一个状态记录器(State Recorder)持续监控预测的子任务数量和规划轨迹。如果发现子任务数量长时间未减少(如反复抓取失败),或轨迹长时间停滞(如发生碰撞),就会触发“Rewind”机制。
-
无需额外数据的恢复策略:Rewind机制会让机器人执行一个简短的学习过的撤回动作,使其脱离错误状态,恢复到正常的分布内状态(in-distribution states),然后再重新开始See-Plan循环。
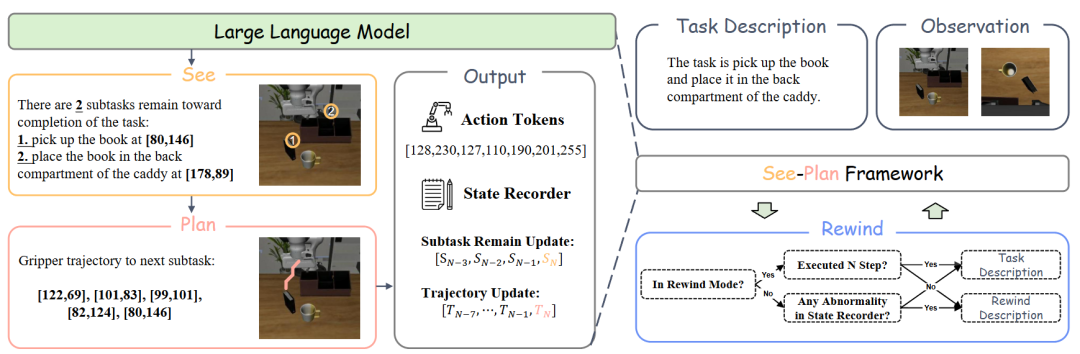
▲SPR框架概览。
03 AtomicVLA:解锁机器人原子技能学习的无限可能
现实世界中的机器人任务往往涉及长时域、多步骤的问题求解,这要求机器人具备持续获取新技能的泛化能力。
现有的VLA模型大多使用在聚合数据上训练的单体动作解码器。这种设计不仅扩展性差,而且在增量学习新技能时,经常会与之前掌握的技能产生严重干扰,导致“灾难性遗忘”,从而阻碍了机器人终身学习能力的发展。
技术亮点:
针对这一挑战,中山大学等团队提出了 AtomicVLA,这是一个将任务规划与动作执行无缝统一的端到端框架:
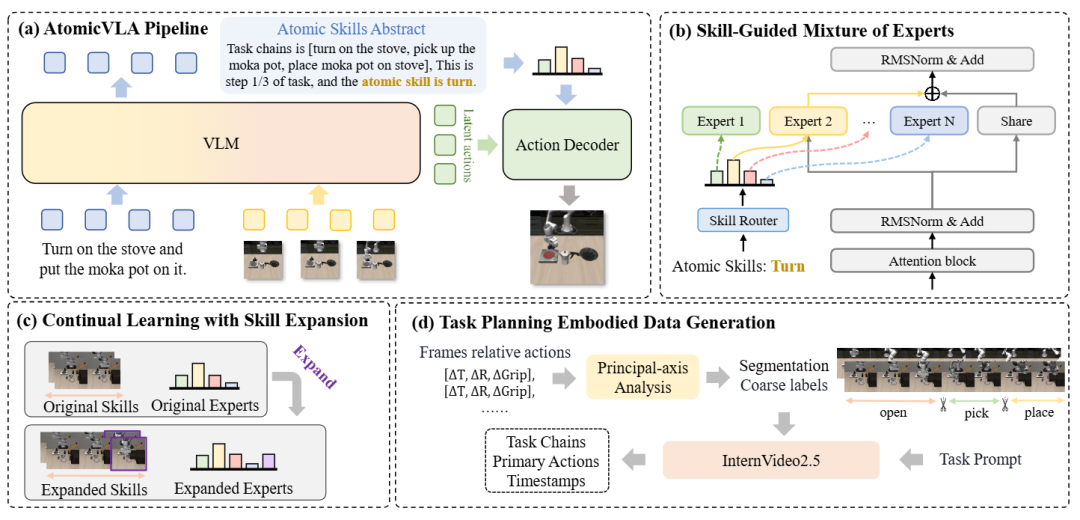
▲AtomicVLA管道与技能引导混合专家架构。
-
统一的“思考-行动”架构:模型首先从输入观察中推断当前执行状态,动态激活思考模块或行动模块。
在任务初始化或子技能转换时,模型会进行“思考”,生成任务链并输出原子技能抽象;在行动阶段,则根据技能抽象生成精确的电机控制信号。
-
技能引导的混合专家(SG-MoE):为了实现持续学习,AtomicVLA构建了一个可扩展的原子技能库。该库包含一个共享专家和多个专用技能专家,每个专家都专精于掌握一种通用且精确的原子技能。
-
灵活的路由与持续扩展:通过精心设计的技能编码机制和可扩展的路由编码器,当引入新技能时,只需训练对应的新专家和相关的路由参数,现有专家保持不变。这有效防止了灾难性遗忘,确保了技能的稳定增长。
在真实世界Franka机器人的长时域任务和持续学习实验中,AtomicVLA分别稳定超越基线18.3%和21%,充分验证了原子技能抽象在复杂任务中的巨大潜力。

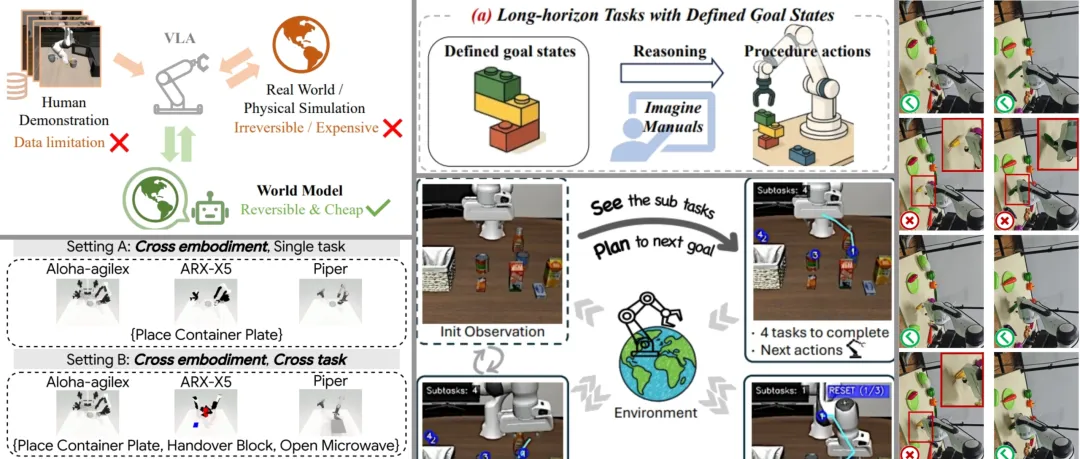
04 RehearseVLA:基于物理一致世界模型的VLA模拟后训练
虽然强化学习(RL)的后训练被证明是解决数据不足的有效途径,但在真实的物理世界中,环境往往是不可重置的。例如,在工业自动化等高风险领域,机器人的错误交互可能会导致昂贵的设备损坏,这使得在真实环境中进行大量的试错学习变得极不现实。
技术亮点:
为了寻找一个既能避免物理风险,又能提供丰富语义理解的“理想测试床”,阿里巴巴等研究团队提出了 RehearseVLA,一个基于世界模型的低成本强化学习后训练框架:
-
物理一致的世界模拟器:该框架使用基于视频的世界模型替代真实的物理交互。它作为一个交互式的未来帧预测器,能够合成以动作为条件的图像序列。
-
VLM引导的即时反射器(Instant Reflector):这是一个语义感知的奖励模块,它通过评估预测视觉帧与语言指令之间的语义对齐度,为模型提供连续的密集奖励信号。
-
实时任务终止机制:即时反射器还能实时预测动作是否完成。一旦确认成功执行(例如到达目标状态),它会立即终止动作序列,有效防止了成功后多余的破坏性动作。
在复杂的机器人操作任务中,该方法有效克服了传统VLA数据效率低、受限于安全约束以及执行效率低下等问题,为资源受限环境下的VLA后训练提供了一种高度实用且可扩展的解决方案。
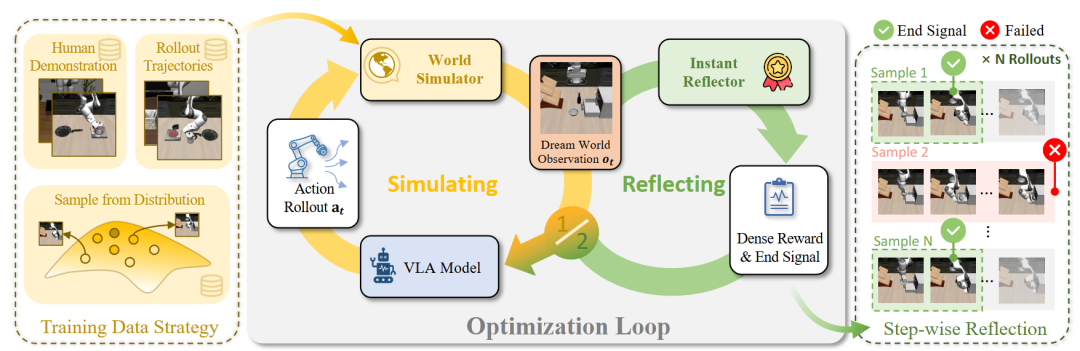
▲RehearseVLA框架概览。
05 ACoT-VLA:基于“动作思维链”的通用策略学习
抽象的语义或视觉表征往往无法传递精确执行底层动作所需的细粒度知识,最有效的推理方式应该是直接在动作空间中进行审议。
技术亮点:
基于这一洞察,北航、智元研究团队提出了动作思维链(Action Chain-of-Thought, ACoT) 范式,并设计了ACoT-VLA架构:
-
显式动作推理器(EAR):这是一个轻量级的Transformer模块。它基于多模态观察,直接合成粗粒度的参考运动轨迹,在动作空间内提供显式、可执行的指导。
-
隐式动作推理器(IAR):该模块通过对下采样的多模态表示与可学习查询之间应用交叉注意力建模,提取潜在的动作先验,提供隐式的行为灵感。
-
动作引导预测(AGP)头:通过交叉注意力机制,协同整合显式和隐式两种动作指导,将其作为最终去噪过程的条件,从而生成平滑且精确的可执行动作序列。
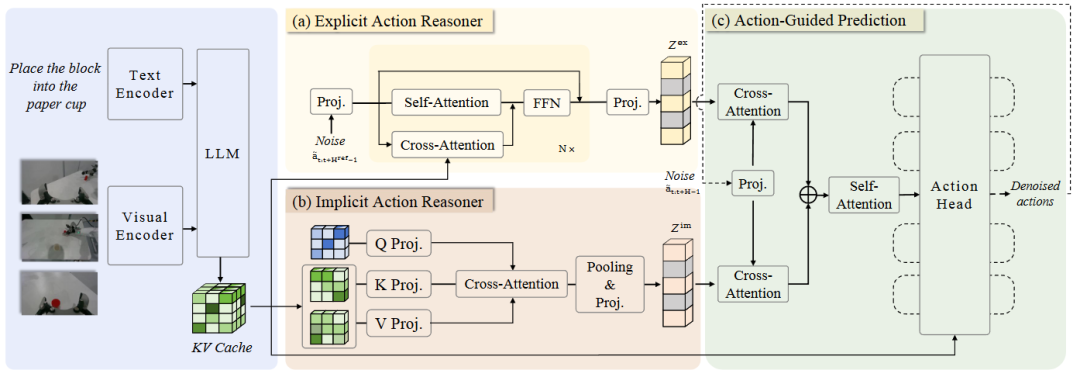
▲图1 |ACoT-VLA架构总览。
06 ManualVLA:从“是什么”到“怎么做”,赋予机器人长时域任务规划能力
当人类面对一堆散乱的乐高积木和一张成品图纸时,我们能够直觉地在脑海中分解步骤,推断出“先拼底座,再拼外墙”的操作手册,并逐步完成拼装。
然而,对于现有的视觉-语言-动作(VLA)模型来说,这种需要严格对齐预定义最终状态的长时域任务(如乐高拼装或物体重排)却是一个巨大的挑战。
为了弥补这一能力鸿沟,研究人员试图赋予VLA模型类似人类生成操作手册的能力,从而将抽象的最终目标转化为一系列连贯、精确的执行步骤。
技术亮点:
为了实现这一目标,北京大学等研究团队提出了 ManualVLA,这是一个基于混合专家Transformer(MoT)架构的统一VLA框架:
-
规划与动作双专家协同:ManualVLA在统一框架内集成了两个专家模块。规划专家(Planning Expert)负责处理人类指令、当前图像和目标图像,生成包含子目标图像、2D位置提示和文本指令的多模态“操作手册(Manual)”;动作专家(Action Expert)则接收这些手册信息,预测精确的底层动作。
-
手册思维链(ManualCoT)推理:模型引入了独特的ManualCoT机制。在显式层面上,手册中的位置指示器被作为视觉提示直接嵌入到动作专家的观察中;在隐式层面上,规划专家生成的手册token通过跨任务共享注意力机制,为动作生成提供潜在的上下文指导。
-
3D高斯数字孪生工具包:由于训练规划专家需要大量的中间状态数据,而真实世界的数据收集成本极高。团队巧妙地开发了一个基于3DGS的高保真数字孪生工具包。该工具包能够自动合成大量的多模态手册数据,彻底解决了数据收集的瓶颈。
得益于手册条件提供的丰富信息,ManualVLA仅需在约100条真实轨迹上进行微调,就能实现高度可泛化的操作。同时,它在其他通用操作任务上也保持了最先进的性能,证明了该框架在复杂推理和精确控制之间的完美平衡。
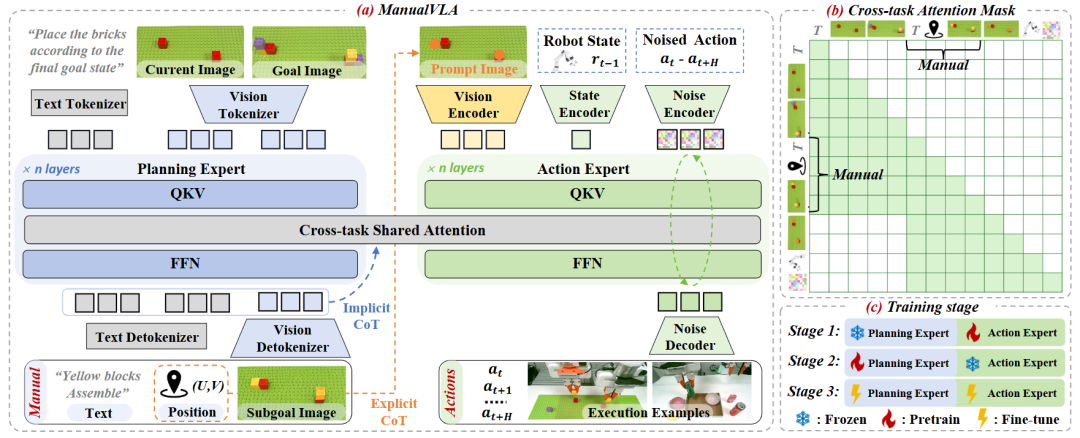
▲ManualVLA框架概览。
07 总结
纵观本期盘点的 CVPR 2026 VLA 工作,我们可以从中提炼出几个贯穿始终的关键词。
-
推理(Reasoning)
无论是动作思维链、手册思维链还是进度感知,研究者们都在努力让模型在执行动作之前先"想清楚",将抽象的语义理解转化为可执行的物理指导。
-
鲁棒性(Robustness)
从闭环纠错到失败中学习,模型不再满足于"一次成功",而是开始具备在复杂、未知环境中自我检测与恢复的能力。
-
效率(Efficiency)
无论是仅需少量演示的世界模型后训练,还是无需重新收集数据的模型合并,降低部署成本、提升数据利用率成为共同追求。
-
可扩展性(Scalability)
原子技能库的持续扩展、混合专家架构的模块化设计,都指向同一个目标:让机器人能够像人类一样,终身积累新技能而不遗忘旧能力。
期待这些技术能在不久的将来,真正赋能各行各业的机器人应用。
参考文献:
1. MergeVLA: Cross-Skill Model Merging Toward a Generalist Vision-Language-Action Agent。https://arxiv.org/abs/2511.18810
2. See, Plan, Rewind: Progress-Aware Vision-Language-Action Models for Robust Robotic Manipulation。https://arxiv.org/abs/2603.09292
3. AtomicVLA: Unlocking the Potential of Atomic Skill Learning in Robots。https://arxiv.org/abs/2603.07648
4. RehearseVLA: Simulated Post-Training for VLAs with Physically-Consistent World Model。https://arxiv.org/abs/2509.24948
5. ACoT-VLA: Action Chain-of-Thought for Vision-Language-Action Models。https://arxiv.org/abs/2601.11404
6. ManualVLA: A Unified VLA Model for Chain-of-Thought Manual Generation and Robotic Manipulation。https://arxiv.org/abs/2512.02013

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)