大模型入门三部曲-3:使用lm-evaluation-harness评测ollama部署的本地模型
·
使用 lm-evaluation-harness 评测 Ollama Gemma 2 模型
本文档介绍如何通过 lm-evaluation-harness 框架评测本地 Ollama 部署的 Gemma 2 模型
如果缺少环境安装可以参考:
三部曲1:从0-1体验模型部署到评测
三部曲2:从0-1体验本地ollama部署小模型
目录
环境准备
前置条件
- ✅ Ollama 已安装并运行
- ✅ Gemma 2 模型已下载:
ollama pull gemma2:2b - ✅ Python 3.9+
- ✅ 足够的磁盘空间(评测框架约需 2-5GB)
验证 Ollama 服务
# 确保 Ollama 服务正在运行
ollama serve
# 验证模型可用
ollama list
# 应显示 gemma2:2b
# 测试模型响应
curl http://localhost:11434/api/generate -d '{
"model": "gemma2:2b",
"prompt": "Hello",
"stream": false
}'
安装 lm-evaluation-harness
方式一:从源码安装(推荐)
# 1. 克隆仓库
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
cd lm-evaluation-harness
# 2. 创建虚拟环境
python -m venv venv
source venv/bin/activate # Linux/Mac
# venv\Scripts\activate # Windows
# 3. 安装依赖
pip install -e .
# 4. 安装额外依赖(用于特定任务)
pip install -e ".[sentencepiece]"
pip install -e ".[multilingual]"
方式二:直接安装
pip install lm-eval
验证安装
# 查看帮助
lm-eval --help
# 查看可用任务
lm-eval --tasks list
配置 Ollama 模型对接
lm-evaluation-harness 默认支持 HuggingFace 模型,但我们可以通过 本地 API 方式 或 自定义模型类 来对接 Ollama。
方案:使用本地 API 服务器(推荐)
创建一个简单的 API 适配器,让 lm-eval 通过 HTTP 调用 Ollama。
1. 创建 Ollama API 适配器
# ollama_lm_wrapper.py
import requests as req_lib
import json
import time
import math
import difflib
from typing import List, Optional, Union, Tuple
from concurrent.futures import ThreadPoolExecutor, as_completed
import lm_eval
from lm_eval.api.model import LM
from lm_eval.api.instance import Instance
from lm_eval.api.registry import register_model
class ProgressTracker:
"""
进度追踪器 - 用于显示任务进度和 ETA 预估
将进度显示逻辑从主业务逻辑中抽离,使代码更清晰。
"""
def __init__(self, total: int, print_interval: int = 5):
"""
初始化进度追踪器
Args:
total: 总任务数
print_interval: 打印间隔(秒),默认每 5 秒刷新一次
"""
self.total = total
self.completed = 0
self.start_time = time.time()
self.last_print_time = self.start_time
self.print_interval = print_interval
def update(self, increment: int = 1) -> bool:
"""
更新进度
Args:
increment: 本次完成的任务数,默认 1
Returns:
是否应该打印进度(达到间隔或完成时返回 True)
"""
self.completed += increment
current_time = time.time()
# 每 N 秒或完成时打印
if current_time - self.last_print_time >= self.print_interval or self.is_complete():
self.last_print_time = current_time
return True
return False
def is_complete(self) -> bool:
"""检查是否全部完成"""
return self.completed >= self.total
def get_progress_info(self) -> dict:
"""
获取当前进度信息
Returns:
包含进度、速度、已用时间、ETA 的字典
"""
elapsed = time.time() - self.start_time
progress_pct = self.completed / self.total * 100 if self.total > 0 else 0
# 计算速度
if elapsed > 0:
speed = self.completed / elapsed
else:
speed = 0
# 计算 ETA
if self.completed > 0 and not self.is_complete():
avg_time_per_item = elapsed / self.completed
remaining_items = self.total - self.completed
eta_seconds = avg_time_per_item * remaining_items
else:
eta_seconds = 0
return {
'completed': self.completed,
'total': self.total,
'progress_pct': progress_pct,
'speed': speed,
'elapsed': elapsed,
'eta': eta_seconds
}
def print_progress(self) -> None:
"""打印当前进度"""
info = self.get_progress_info()
print(f" 进度: {info['completed']}/{info['total']} ({info['progress_pct']:.1f}%) | "
f"速度: {self._format_speed(info['speed'])} | "
f"已用: {self._format_time(info['elapsed'])} | "
f"预计剩余: {self._format_time(info['eta'])}", flush=True)
def print_summary(self) -> None:
"""打印最终统计信息"""
elapsed = time.time() - self.start_time
avg_speed = self.total / elapsed if elapsed > 0 else 0
print(f"loglikelihood 计算完成!总计: {self._format_time(elapsed)}, "
f"平均速度: {avg_speed:.2f}条/秒")
@staticmethod
def _format_time(seconds: float) -> str:
"""将秒数格式化为易读的时间字符串"""
if seconds < 60:
return f"{int(seconds)}秒"
elif seconds < 3600:
minutes = int(seconds / 60)
secs = int(seconds % 60)
return f"{minutes}分{secs}秒"
else:
hours = int(seconds / 3600)
minutes = int((seconds % 3600) / 60)
return f"{hours}小时{minutes}分"
@staticmethod
def _format_speed(speed: float) -> str:
"""格式化速度显示"""
if speed >= 1:
return f"{speed:.1f}条/秒"
else:
return f"{speed:.2f}条/秒"
@register_model("ollama")
class OllamaLM(LM):
"""
Ollama API 模型封装类
该类将 Ollama 本地推理服务封装成 lm-evaluation-harness 框架可用的模型接口。
通过 HTTP API 调用本地 Ollama 服务,支持文本生成和 loglikelihood 计算。
使用方式:
from lm_eval import evaluator
results = evaluator.simple_evaluate(
model="ollama",
model_args={
"model_name": "gemma2:2b",
"api_url": "http://localhost:11434",
},
tasks=["hellaswag"]
)
"""
def __init__(self,
model_name: str = "gemma2:2b",
api_url: str = "http://localhost:11434",
batch_size: int = 1,
**kwargs):
"""
初始化 OllamaLM 模型封装
Args:
model_name: Ollama 中安装的模型名称,如 "gemma2:2b", "llama3.2:3b" 等
api_url: Ollama API 服务地址,默认本地 11434 端口
batch_size: 并发请求数,控制同时处理的样本数量
**kwargs: 其他参数,如 max_gen_toks (最大生成token数)
"""
super().__init__()
self.model_name = model_name
self.api_url = api_url
self._batch_size = batch_size
self._max_gen_toks = kwargs.get('max_gen_toks', 256)
# 检查 Ollama 是否支持 logprobs
self._supports_logprobs = self._check_logprobs_support()
def _check_logprobs_support(self) -> bool:
"""
检查 Ollama API 是否支持 logprobs 功能
通过发送一个测试请求来检测 API 能力。
Returns:
True 如果支持 logprobs,否则 False
"""
try:
response = req_lib.post(
f"{self.api_url}/api/generate",
json={
"model": self.model_name,
"prompt": "test",
"stream": False,
"options": {
"temperature": 0.0,
"num_predict": 1,
}
},
timeout=10
)
result = response.json()
# 检查响应中是否有 logprobs 相关字段
# Ollama 0.1.20+ 支持在 options 中设置 logprobs
# 但目前版本可能还不支持返回 logprobs 数据
print(f"Ollama API 检测: 模型 {self.model_name} 可用")
# 尝试检查版本信息
try:
version_resp = req_lib.get(f"{self.api_url}/api/version", timeout=5)
if version_resp.status_code == 200:
version_info = version_resp.json()
print(f"Ollama 版本: {version_info}")
except:
pass
return False # 目前 Ollama 还不支持返回 logprobs
except Exception as e:
print(f"检查 Ollama API 支持时出错: {e}")
return False
@property
def eot_token_id(self):
"""End-of-Text token ID"""
return None
@property
def max_length(self):
"""模型支持的最大上下文长度"""
return 8192
@property
def max_gen_toks(self):
"""单次生成最多 token 数"""
return self._max_gen_toks
@property
def batch_size(self):
"""并发处理的请求数量"""
return self._batch_size
@property
def device(self):
"""模型运行设备"""
return "cpu"
def tok_encode(self, string: str, **kwargs) -> List[int]:
"""编码文本"""
return list(string.encode('utf-8'))
def tok_decode(self, tokens: List[int], **kwargs) -> str:
"""解码 tokens"""
try:
return bytes(tokens).decode('utf-8')
except:
return ""
def _model_call(self, inps):
"""模型调用(lm-eval 内部使用)"""
raise NotImplementedError("使用 _model_generate 方法")
def _model_generate(self, context: str, max_length: int, **kwargs) -> str:
"""生成文本"""
data = {
"model": self.model_name,
"prompt": context,
"stream": False,
"options": {
"temperature": kwargs.get('temperature', 0.0),
"top_p": kwargs.get('top_p', 1.0),
"num_predict": max_length,
"stop": kwargs.get('stop_sequences', [])
}
}
try:
response = req_lib.post(
f"{self.api_url}/api/generate",
json=data,
timeout=120
)
result = response.json()
return result.get('response', '')
except Exception as e:
print(f"生成失败: {e}")
return ""
def generate_until(self, requests: List[Instance]) -> List[str]:
"""生成直到满足条件"""
results = []
for req in requests:
context = req.args[0]
gen_kwargs = req.args[1] if len(req.args) > 1 else {}
max_gen_toks = gen_kwargs.get('max_gen_toks', self.max_gen_toks)
temperature = gen_kwargs.get('temperature', 0.0)
result = self._model_generate(
context,
max_length=max_gen_toks,
temperature=temperature
)
results.append(result)
return results
def loglikelihood(self, requests: List[Instance]) -> List[tuple]:
"""
计算对数似然 - 多选题评测的核心方法
计算 P(continuation | context) 的对数概率,返回 (log_prob, is_greedy) 元组。
Args:
requests: 请求列表,每个请求是 (context, continuation) 元组
context: 问题上下文
continuation: 候选答案
Returns:
结果列表,每个元素是 (log_prob, is_greedy) 元组
"""
total = len(requests)
tracker = ProgressTracker(total, print_interval=5)
results = [None] * total
print(f"开始计算 {total} 个请求的 loglikelihood...")
if self._supports_logprobs:
print("使用 Ollama logprobs 功能")
else:
print("使用改进的文本匹配算法计算 logprob")
def process_single(idx_req) -> Tuple[int, tuple]:
"""处理单个请求"""
idx, req = idx_req
context, continuation = req.args
try:
log_prob, is_greedy = self._compute_loglikelihood_single(
context, continuation
)
return idx, (log_prob, is_greedy)
except Exception as e:
print(f"计算 loglikelihood 失败 (idx={idx}): {e}")
return idx, (0.0, False)
with ThreadPoolExecutor(max_workers=self._batch_size) as executor:
futures = {executor.submit(process_single, (i, req)): i
for i, req in enumerate(requests)}
for future in as_completed(futures):
idx, result = future.result()
results[idx] = result
# 更新并显示进度
if tracker.update():
tracker.print_progress()
tracker.print_summary()
return results
def _compute_loglikelihood_single(self, context: str, continuation: str) -> Tuple[float, bool]:
"""
计算单个请求的对数似然 - 使用多次采样获取更可靠的分数
改进策略:
1. 多次调用 API 获取平均结果
2. 同时生成 continuation 和对比文本
3. 使用更精确的相似度计算
Args:
context: 问题上下文
continuation: 候选答案
Returns:
(log_prob, is_greedy) 元组
"""
continuation_stripped = continuation.strip()
if not continuation_stripped:
return (0.0, True)
cont_words = continuation_stripped.split()
num_predict = min(len(cont_words) + 5, 30)
# 策略1:直接生成,看是否匹配
scores = []
# 多次采样取平均(减少随机性影响)
for _ in range(1): # 改为 1 次,减少耗时
gen_response = req_lib.post(
f"{self.api_url}/api/generate",
json={
"model": self.model_name,
"prompt": context,
"stream": False,
"options": {
"num_predict": num_predict,
"temperature": 0.0, # 确定性生成
"top_k": 1,
}
},
timeout=30
)
gen_result = gen_response.json()
generated = gen_result.get('response', '').strip()
# 计算匹配分数
score = self._compute_semantic_similarity(generated, continuation_stripped)
scores.append(score)
# 使用最高分(最乐观估计)
best_score = max(scores)
# 转换为 logprob
if best_score >= 0.95:
log_prob = 0.0
is_greedy = True
elif best_score > 0.8:
log_prob = math.log(best_score) * 0.5
is_greedy = False
elif best_score > 0.5:
log_prob = -1.0 + math.log(best_score)
is_greedy = False
elif best_score > 0.3:
log_prob = -3.0 + math.log(best_score) * 2
is_greedy = False
else:
log_prob = -5.0 - (0.3 - best_score) * 10
is_greedy = False
log_prob = max(log_prob, -10.0)
log_prob = min(log_prob, 0.0)
return (log_prob, is_greedy)
def _compute_semantic_similarity(self, generated: str, continuation: str) -> float:
"""
计算两个文本的语义相似度(0-1之间)
使用多种指标综合评估:
1. 前缀匹配
2. 包含关系
3. 词重叠
4. 编辑距离
5. 首词匹配
Args:
generated: 生成的文本
continuation: 期望的候选答案
Returns:
相似度分数(0-1)
"""
generated = generated.strip().lower()
continuation = continuation.strip().lower()
if not continuation:
return 1.0
# 1. 完全匹配或前缀匹配(最高优先级)
if generated == continuation:
return 1.0
if generated.startswith(continuation):
return 0.95
# 2. continuation 是 generated 的子串
if continuation in generated:
position = generated.find(continuation)
# 越靠前分数越高
position_score = 1.0 - (position / max(len(generated), 1))
return 0.8 + position_score * 0.15
# 3. 词级别分析
gen_words = generated.split()
cont_words = continuation.split()
if not cont_words:
return 1.0
# 3.1 首词匹配(很重要)
first_word_match = 0.0
if gen_words and cont_words and gen_words[0] == cont_words[0]:
first_word_match = 0.2
# 3.2 词集合重叠(Jaccard 相似度)
gen_word_set = set(gen_words)
cont_word_set = set(cont_words)
if cont_word_set:
intersection = len(gen_word_set & cont_word_set)
union = len(gen_word_set | cont_word_set)
jaccard = intersection / union if union > 0 else 0.0
else:
jaccard = 0.0
# 3.3 词序匹配(最长公共子序列)
lcs_length = self._lcs_length(gen_words, cont_words)
lcs_ratio = lcs_length / len(cont_words) if cont_words else 0.0
# 3.4 编辑距离相似度
edit_dist = self._levenshtein_distance(generated, continuation)
max_len = max(len(generated), len(continuation))
edit_similarity = 1.0 - (edit_dist / max_len) if max_len > 0 else 0.0
# 综合评分
combined_score = (
first_word_match * 0.3 + # 首词匹配很重要
jaccard * 0.25 + # 词集合重叠
lcs_ratio * 0.25 + # 词序匹配
edit_similarity * 0.2 # 字符级编辑距离
)
return min(combined_score, 0.79) # 最高不超过 0.79(避免与完全匹配混淆)
def _levenshtein_distance(self, s1: str, s2: str) -> int:
"""
计算两个字符串的编辑距离(Levenshtein distance)
Args:
s1: 第一个字符串
s2: 第二个字符串
Returns:
编辑距离
"""
if len(s1) < len(s2):
return self._levenshtein_distance(s2, s1)
if len(s2) == 0:
return len(s1)
previous_row = range(len(s2) + 1)
for i, c1 in enumerate(s1):
current_row = [i + 1]
for j, c2 in enumerate(s2):
insertions = previous_row[j + 1] + 1
deletions = current_row[j] + 1
substitutions = previous_row[j] + (c1 != c2)
current_row.append(min(insertions, deletions, substitutions))
previous_row = current_row
return previous_row[-1]
def _compute_match_score_v2(self, generated: str, continuation: str) -> Tuple[float, bool]:
"""
【方案A】改进的匹配分数计算 - 使用多层相似度评估
相比 v1 的改进:
1. 使用 difflib.SequenceMatcher 计算字符串相似度
2. 考虑最长公共子序列 (LCS)
3. 考虑词序匹配
4. 更平滑的 logprob 转换函数
Args:
generated: 模型实际生成的文本
continuation: 期望的候选答案
Returns:
(log_prob, is_greedy) 元组
"""
generated = generated.strip()
continuation = continuation.strip()
if not continuation:
return (0.0, True)
generated_lower = generated.lower()
continuation_lower = continuation.lower()
# 情况1:完全匹配(包括前缀匹配)
if generated_lower.startswith(continuation_lower):
return (0.0, True)
# 情况2:continuation 是 generated 的子串
if continuation_lower in generated_lower:
# 计算相对位置(越靠前分数越高)
position = generated_lower.find(continuation_lower)
position_ratio = 1.0 - (position / len(generated_lower))
log_prob = -0.1 * (1.0 - position_ratio)
return (log_prob, False)
# 计算多层相似度
# 2.1 字符级相似度 (SequenceMatcher)
char_similarity = difflib.SequenceMatcher(
None, generated_lower, continuation_lower
).ratio()
# 2.2 词级相似度
gen_words = generated_lower.split()
cont_words = continuation_lower.split()
if not cont_words:
return (0.0, True)
# 计算词集合重叠
gen_word_set = set(gen_words)
cont_word_set = set(cont_words)
if cont_word_set:
word_overlap = len(gen_word_set & cont_word_set) / len(cont_word_set)
else:
word_overlap = 0.0
# 2.3 最长公共子序列 (LCS) 相似度
lcs_length = self._lcs_length(gen_words, cont_words)
lcs_similarity = lcs_length / len(cont_words) if cont_words else 0.0
# 2.4 首词匹配奖励
first_word_bonus = 0.0
if gen_words and cont_words and gen_words[0] == cont_words[0]:
first_word_bonus = 0.1
# 综合评分(加权平均)
combined_score = (
char_similarity * 0.3 +
word_overlap * 0.3 +
lcs_similarity * 0.3 +
first_word_bonus
)
# 转换为 logprob(更平滑的映射)
# 使用 sigmoid 风格的映射,避免极端值
if combined_score > 0.9:
log_prob = math.log(combined_score) * 0.3
elif combined_score > 0.7:
log_prob = -0.5 + math.log(combined_score) * 0.5
elif combined_score > 0.5:
log_prob = -1.5 + math.log(combined_score) * 1.0
elif combined_score > 0.3:
log_prob = -3.0 + math.log(combined_score) * 2.0
elif combined_score > 0.1:
log_prob = -5.0 + math.log(combined_score) * 3.0
else:
# 极低相似度,给予较大惩罚但不到 -20
log_prob = -8.0 - (0.1 - combined_score) * 20.0
# 限制在合理范围内
log_prob = max(log_prob, -15.0)
log_prob = min(log_prob, 0.0)
return (log_prob, False)
def _lcs_length(self, seq1: List[str], seq2: List[str]) -> int:
"""
计算两个序列的最长公共子序列 (LCS) 长度
使用动态规划算法。
Args:
seq1: 第一个词序列
seq2: 第二个词序列
Returns:
最长公共子序列的长度
"""
if not seq1 or not seq2:
return 0
m, n = len(seq1), len(seq2)
# 使用滚动数组优化空间
prev = [0] * (n + 1)
curr = [0] * (n + 1)
for i in range(1, m + 1):
for j in range(1, n + 1):
if seq1[i-1] == seq2[j-1]:
curr[j] = prev[j-1] + 1
else:
curr[j] = max(prev[j], curr[j-1])
prev, curr = curr, prev
return prev[n]
def loglikelihood_rolling(self, requests: List[Instance]) -> List[tuple]:
"""滚动对数似然计算"""
return self.loglikelihood(requests)
2. 创建评测脚本
# run_ollama_eval.py
import sys
import json
import os
# 设置 HuggingFace 镜像
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
# 需要导入 wrapper 以注册 ollama 模型
import ollama_lm_wrapper
from lm_eval import evaluator
from lm_eval.tasks import TaskManager
def main():
# 定义要评测的任务
tasks = ["hellaswag_local"]
print(f"开始评测模型: gemma2:2b")
print(f"评测任务: {tasks}")
# 创建 TaskManager,通过 include_path 加载本地任务
task_manager = TaskManager(
include_path="/Users/hongshao/dataset/tasks"
)
# 运行评测 - 使用 Ollama API 模型
results = evaluator.simple_evaluate(
model="ollama",
model_args={
"model_name": "gemma2:2b",
"api_url": "http://localhost:11434",
},
tasks=tasks,
batch_size=6,
device="cpu",
task_manager=task_manager
,
limit=100, # 只评测 100 条样本,测试链路
)
# 保存结果
output_file = "/Users/hongshao/ollama_gemma2_results.json"
# 自定义 JSON 序列化函数,处理无法序列化的类型
def json_serializer(obj):
if callable(obj):
return str(obj) # 将函数转为字符串
raise TypeError(f"Object of type {type(obj).__name__} is not JSON serializable")
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2, default=json_serializer)
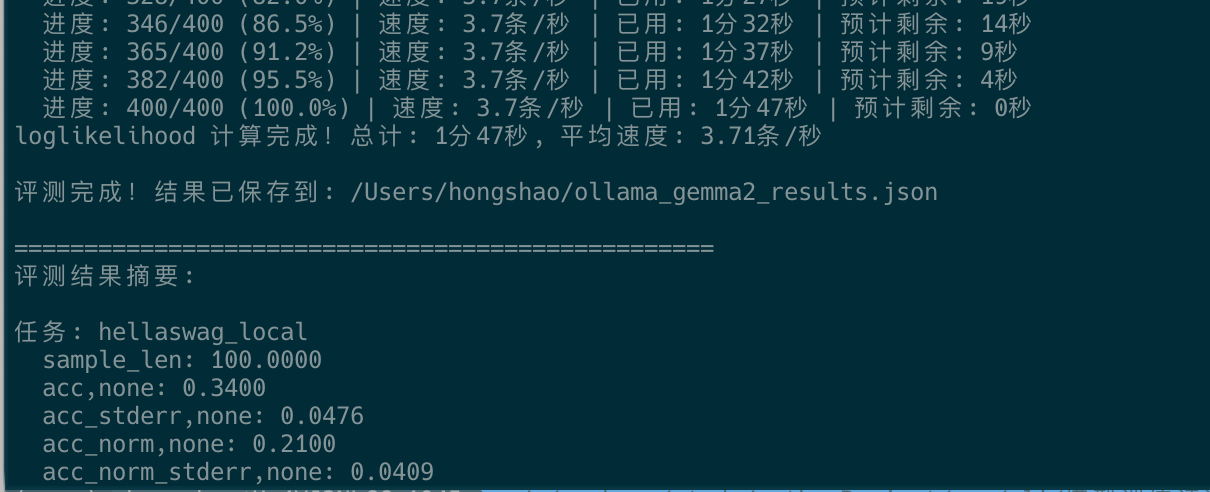
print(f"\n评测完成!结果已保存到: {output_file}")
# 打印关键指标
if 'results' in results:
print("\n" + "="*50)
print("评测结果摘要:")
for task_name, task_results in results['results'].items():
print(f"\n任务: {task_name}")
for metric, value in task_results.items():
if isinstance(value, (int, float)):
print(f" {metric}: {value:.4f}")
if __name__ == "__main__":
main()
运行评测
# 1. 确保 Ollama 服务运行
ollama serve
# 2. 启动适配器
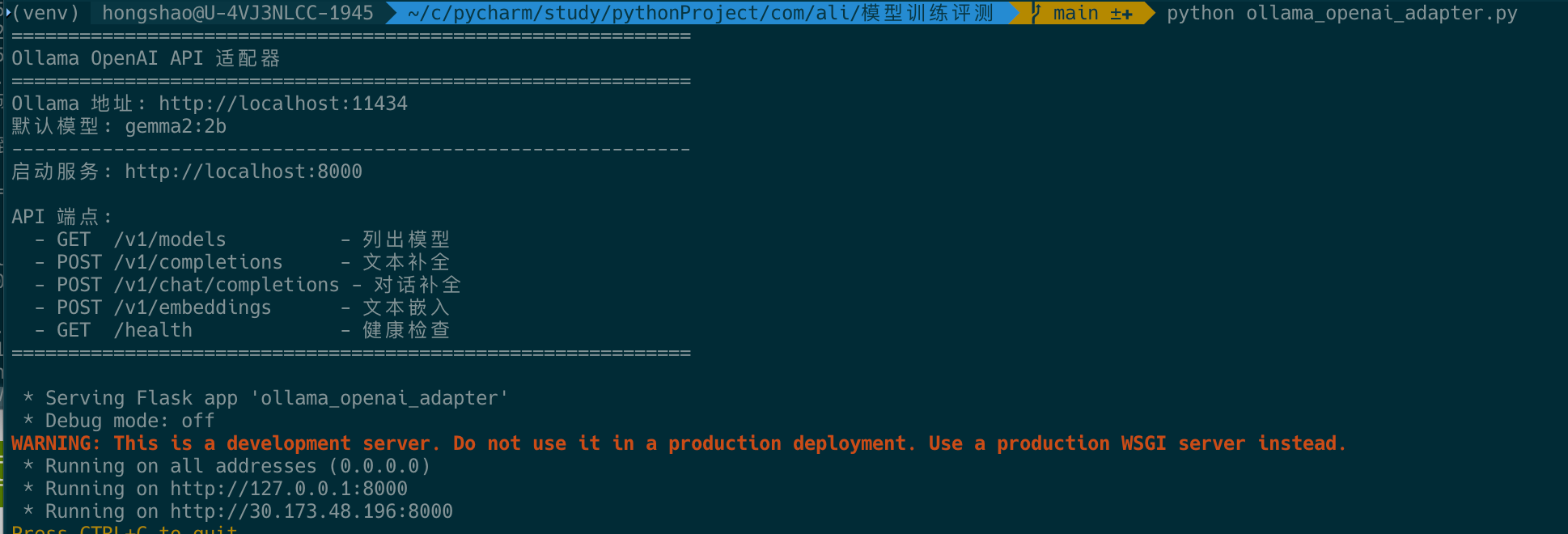
python ollama_openai_adapter.py
# 3. 在另一个终端运行评测
python run_ollama_eval.py
相关过程截图
示例中:只修改了本地调用100条样本,实际测试可以放大到全量,去掉limit参数。
查看和分析结果
结果文件结构
results/
├── results.json # 汇总结果
├── samples_*.json # 详细样本结果
└── hashes.json # 配置哈希
结果分析脚本
# analyze_results.py
import json
import pandas as pd
import matplotlib.pyplot as plt
def load_results(result_file: str):
"""加载评测结果"""
with open(result_file, 'r') as f:
return json.load(f)
def print_summary(results: dict):
"""打印结果摘要"""
print("="*60)
print("评测结果摘要")
print("="*60)
if 'results' not in results:
print("没有找到结果数据")
return
for task_name, metrics in results['results'].items():
print(f"\n任务: {task_name}")
print("-" * 40)
# 过滤出数值指标
for metric_name, value in metrics.items():
if isinstance(value, (int, float)) and not metric_name.startswith('_'):
print(f" {metric_name:20s}: {value:.4f}")
def compare_models(result_files: list, model_names: list):
"""对比多个模型的结果"""
comparison = []
for result_file, model_name in zip(result_files, model_names):
results = load_results(result_file)
if 'results' in results:
for task_name, metrics in results['results'].items():
row = {'model': model_name, 'task': task_name}
row.update({k: v for k, v in metrics.items()
if isinstance(v, (int, float))})
comparison.append(row)
df = pd.DataFrame(comparison)
print("\n模型对比:")
print(df.to_string(index=False))
return df
def plot_results(results: dict, output_file: str = "results.png"):
"""可视化结果"""
tasks = []
accuracies = []
for task_name, metrics in results.get('results', {}).items():
if 'acc' in metrics or 'accuracy' in metrics:
tasks.append(task_name)
acc = metrics.get('acc', metrics.get('accuracy', 0))
accuracies.append(acc)
if tasks:
plt.figure(figsize=(10, 6))
plt.bar(tasks, accuracies)
plt.xlabel('任务')
plt.ylabel('准确率')
plt.title('Gemma 2 2B 评测结果')
plt.xticks(rotation=45, ha='right')
plt.tight_layout()
plt.savefig(output_file)
print(f"\n图表已保存: {output_file}")
if __name__ == "__main__":
# 加载并分析结果
results = load_results("ollama_gemma2_results.json")
print_summary(results)
plot_results(results)
完整评测流程示例
# 1. 准备环境
ollama serve &
cd lm-evaluation-harness
source venv/bin/activate
# 2. 准备自定义任务
cp /path/to/hellaswag_local.yaml lm_eval/tasks/
cp /path/to/my_data.json /path/to/data/
# 3. 运行评测
python run_ollama_eval.py
# 4. 分析结果
python analyze_results.py
# 5. 查看详细结果
cat ollama_gemma2_results.json | jq '.results'
常见问题
1. Could not automatically map gemma2:2b to a tokeniser’
KeyError: ‘Could not automatically map gemma2:2b to a tokeniser’
**原因**:lm-eval 默认使用 tiktoken 进行分词,但 tiktoken 只支持 OpenAI 官方模型(如 gpt-3.5-turbo, gpt-4),不认识 `gemma2:2b`。
#### 解决方法(修改 2 行代码)
**文件位置**:`lm-evaluation-harness/lm_eval/models/api_models.py`
**第 214 行**,将:
```python
self.tokenizer = tiktoken.encoding_for_model(self.model)
修改为:
try:
self.tokenizer = tiktoken.encoding_for_model(self.model)
except KeyError:
self.tokenizer = tiktoken.get_encoding("cl100k_base")
完整上下文:
elif self.tokenizer_backend == "tiktoken":
try:
import tiktoken
# 修复:支持非 OpenAI 模型
try:
self.tokenizer = tiktoken.encoding_for_model(self.model)
except KeyError:
self.tokenizer = tiktoken.get_encoding("cl100k_base")
except ModuleNotFoundError as e:
raise ModuleNotFoundError(
"Attempted to use 'openai' LM type, but the package `tiktoken` is not installed. "
"Please install it via `pip install lm-eval[api]` or `pip install -e .[api]`."
) from e
备选:使用 HuggingFace Tokenizer
如果你不想修改源码,可以使用 HuggingFace tokenizer:
lm_eval \
--model openai-completions \
--model_args model=gemma2:2b,base_url=http://localhost:11434/v1,tokenizer_backend=huggingface,tokenizer=google/gemma-2b-it \
--tasks hellaswag \
--batch_size 1
注意:这需要下载 HuggingFace 的 tokenizer,可能需要网络代理。
2. Ollama 响应超时
# 在 OllamaLM 类中增加超时重试
import time
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
def _model_generate_with_retry(self, context, max_length, retries=3):
for i in range(retries):
try:
return self._model_generate(context, max_length)
except Exception as e:
if i < retries - 1:
time.sleep(2 ** i) # 指数退避
else:
raise e
3. 批量评测太慢
# 使用多进程并行
# 修改 run_ollama_eval.py 中的 batch_size
# 或者启动多个 Ollama 实例(需要不同端口)
4. 内存不足
# 减小上下文窗口
# 在 OllamaLM 中设置更小的 max_length
参考资源
如有问题,欢迎交流讨论!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)