(2026|MBZUAI,构建 PIXAR 基准,像素差异图和基于阈值的掩码,VLM,分类/分割/检测)从 Mask 到像素和意义:VLM 图像篡改的新分类法,基准和度量
From Masks to Pixels and Meaning: A New Taxonomy, Benchmark, and Metrics for VLM Image Tampering

论文地址:https://arxiv.org/abs/2603.20193
项目页面:https://github.com/VILA-Lab/PIXAR
进 Q 学术交流群:922230617 或加 CV_EDPJ 进 W 交流群
目录
1. 引言
生成式 AI 的进步使得创建逼真图像成为可能,这对数字媒体的真实性和信任度构成了严重威胁。
- 其中,细粒度篡改尤为隐蔽,它能在保持人眼和传统取证方法难以察觉的情况下,微妙地修改真实图像的局部区域。
- 因此,开发 稳健的细粒度篡改检测器 既是关键的研究挑战,也是社会需求。
然而,大多数现有基准仍 使用粗糙的目标掩码来标注 “编辑发生的位置”。
- 这种做法隐含地假设编辑在空间上局限于预设区域,且该区域内的所有像素都被同等篡改。
- 但实践中,编辑信号既非空间均匀也非强度一致:掩码内的许多像素未变或仅微小扰动,而视觉上显著的调整(如光晕、色彩溢出)常延伸到掩码之外。
- 因此,仅基于掩码的评估会混淆未编辑像素与真实篡改证据,并忽略掩码外的伪影,从而扭曲检测器的训练和评估结果。

本文通过对比原始图像与篡改图像之间的逐像素差异图,使像素级的真实篡改显式化,并揭示出人工定义的真值掩码与真实像素级篡改之间的广泛错位:掩码内部有大量未改动像素被错误标记为“篡改”,而掩码外部的编辑像素则被错误地当作“真实”。这些标注错误严重惩罚了那些检测到掩码边界外真实生成伪影的模型,反而奖励了那些过拟合于粗糙形状而非真实编辑足迹的模型。

为解决此问题,本文将 VLM 图像篡改重新定义为基于像素、融合意义与文本感知的任务,并构建了一个名为 PIXAR 的新基准。
- 具体地,通过计算原始图像与编辑图像的差异图,并使用可调阈值 τ 将其转换为二值监督信号。得到的标签图 M_τ 以可控的强度级别捕捉了编辑的空间范围:小的 τ 强调对微小编辑的敏感性,大的 τ 则强调保守的高置信度变化。
- 这种基于阈值的构建方式将编辑发生的位置与其表现的强度解耦,使得评估与物理篡改信号而非代理几何形状对齐。
基于此,
- 本文引入了一个 大规模基准——超过 380K 对精心筛选的训练图像对,带有丰富的标准化元数据,以及一个包含 40K 对图像、具备像素级和语义级标签的平衡测试集。每对图像包含真实源图像、其篡改版本、推荐的默认 τ 下的二值像素标签 M_τ,以及原始的逐像素差异图(可从中推导出其他 τ 值的标签)。
- 为确保操作多样性,本文的流程整合了 八种编辑策略,并由包括 Flux.2、Gemini 2.5、Gemini 3、GPT-image 1.5、Qwen-Image、Seedream 4.5 在内的最先进开源和闭源生成模型实现。这些策略涵盖替换、移除、拼接、修复、属性修改、上色及相关基元,本文手动标注了被篡改目标的语义类别,以连接低级足迹与高级语义。
- 最后,本文设计了一个严格的 多阶段筛选流程,以保证篡改图像的保真度和相应标签的精度。
2. 相关工作
篡改图像数据集。
- 早期基准主要关注全图生成,训练检测器进行二分类(真实 vs 伪造)。随着操作变得日益精细,研究转向细粒度篡改检测。
- 最近的 SID-Set 使用基于 Stable Diffusion 的修复来构建社交媒体图像篡改定位基准。然而,现有数据集大多依赖目标掩码作为真值,导致与真实编辑信号严重错位,从根本上阻碍了检测器学习真正的篡改足迹。
- 相比之下,本文使用像素、意义和语言描述重新定义了篡改。
篡改图像检测。
- 检测通常被表述为基于 CNN 或 Transformer 的分类任务。
- 部分研究探索频域以捕捉生成特有伪影,或通过重建学习提升特征鲁棒性。但这些模型在未见过的生成模型上泛化能力有限。
- 最近,视觉-语言模型(VLM)被引入用于篡改检测,如 SIDA(微调LLaVA)、AntifakePrompt(提示调优)和 FakeShield(利用 VLM 和解释性检测)。
3. PIXAR 基准构建
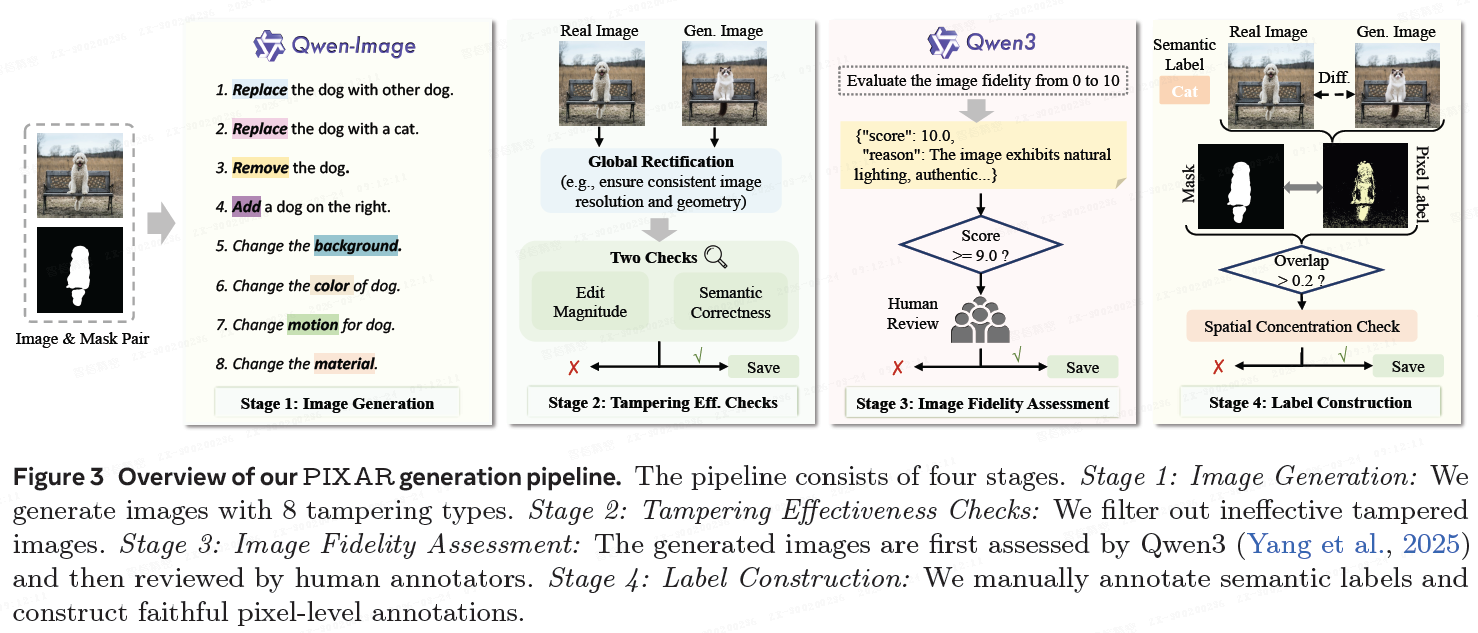
为全面训练和评估图像篡改检测器,本文构建了 PIXAR。其设计遵循三个原则:
- (i) 多样性:纳入 8 种符合现实场景的篡改类型;
- (ii) 保真度:实施严格的保真度检查以过滤低质量样本;
- (iii) 精确性:确保真实篡改的标签精确。本文提出了一个四阶段生成流程。
3.1 图像生成
数据源与生成模型: 使用来自 COCO 的真实源图像。训练集采用 Qwen-Image VLM(因其在复杂文本渲染和精确编辑方面的优势)。测试集使用多种开源和闭源模型。

多样且实用的篡改类型: 通过分析互联网图像,定义了 8 种操作类型:替换(类内/类间)、移除、添加、颜色/运动/材质改变、背景改变。

多样化的篡改尺寸与复杂度: 控制篡改像素占比(小/中/大)和复杂度(引入多对象顺序编辑)。
3.2 篡改有效性检查
实施过滤流程以移除无效篡改,包括:
-
全局校正: 解决生成图像与原始图像间的几何错位(如分辨率、位置),确保像素级差异图可靠。
-
编辑幅度与语义正确性检查: 排除接近零篡改、意外全局编辑或语义不符的情况。
3.3 图像保真度评估

结合自动化 VLM 评估(Qwen3 评分 ≥ 9/10)和人工专家审查(真实感评分 ≥ 4/5),确保样本高保真,过滤掉不真实的图像。
3.4 标签构建
像素级标签(掩码/mask): 计算差异图 D,
![]()
其中,(x,y) 是像素坐标。
通过阈值 τ 获得二值监督掩码 M_τ。M_τ 能根据 τ 值控制对编辑强度的敏感性。
![]()

语义级标签: 为每个被篡改对象手动标注其语义类别(如 “猫”)。
标签可靠性检查: 过滤掉两类低质量像素标签:

1)像素-语义不一致(如替换颜色纹理极相似的对象导致像素差异小,但语义变化大),通过计算篡改像素与输入掩码的重叠率(< 0.2 则丢弃)来确保;

2)空间分散(生成伪影导致标签呈散点状而非目标形状),通过计算以下两个指标来过滤,只保留空间集中的像素标签。
- (i)基于网格的集中比率,定义为覆盖 80% 篡改像素所需的网格单元的比例;
- (ii)局部密度分数,定义为小邻域内篡改像素的中位数密度。
3.5 元数据
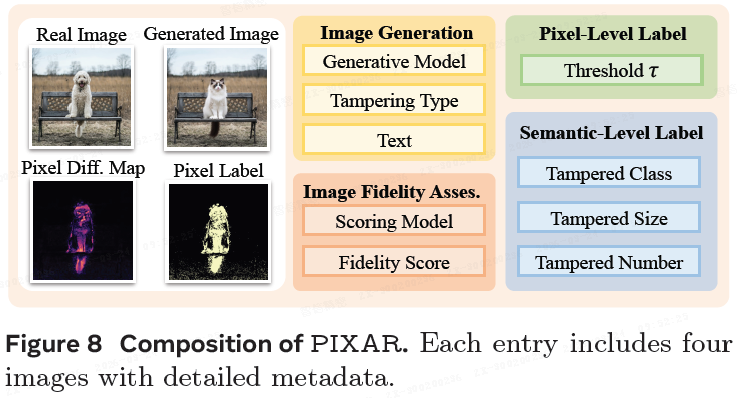
每个条目包含四张图像(原始、篡改、差异图、推荐像素标签)及丰富的标准化元数据,包括操作描述、篡改尺寸等。
4. 训练框架
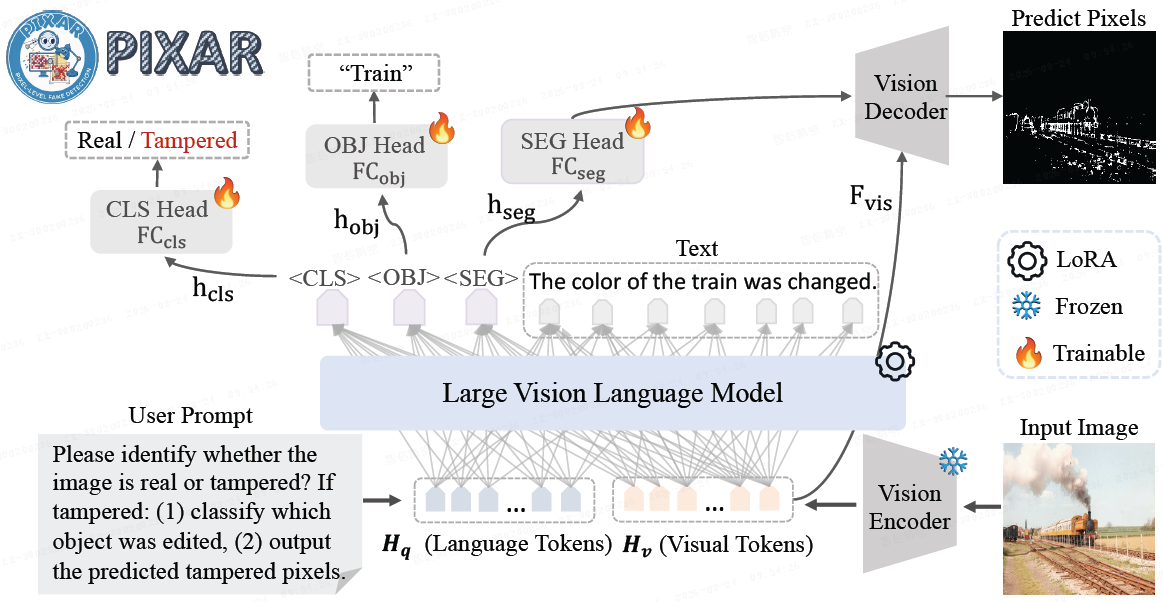
篡改检测器 f_θ 产生:
- (i) 逐像素篡改逻辑图 S 及概率 M̂ = σ(S);
- (ii) 多标签语义逻辑向量 z 及概率 ŷ = σ(z);
- (iii) 描述篡改伪影的自然语言描述。
其中,σ(·) 是按元素 sigmoid,也是用于真实或篡改检测的全局向量。
框架采用以下损失函数:
1)多标签语义损失 L_sem: 使用 Sigmoid 交叉熵进行语义类别分类。
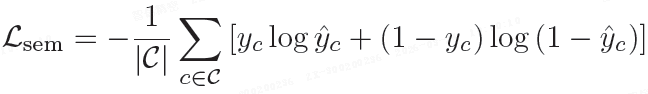
其中 y_c ∈ {0,1} 表示类别 c 的真值,^y_c 表示篡改区域语义标签的预测概率。
2)像素级 BCE 损失 L_bce: 对像素级标签 M_τ 进行逐像素二值交叉熵监督。
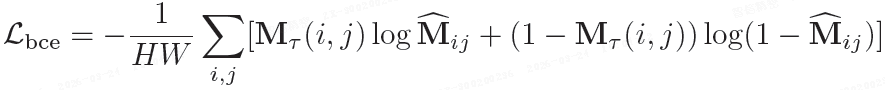
其中,H 和 W 为图像的高度和宽度。
3)像素级 DICE 损失 L_dice: 通过 DICE 分数进一步提升篡改像素的定位精度。
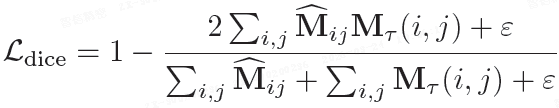
其中,较小的 ε > 0 用于数值稳定性。
在训练期间,用像素级标签 M_τ 替换这个替代掩码,以更准确地反映真实的编辑足迹。
【注:Dice Loss 的定义源自 Dice 系数。
- Dice 系数用于衡量两个样本的相似度,值域为 [0, 1],值越高代表两者越相似。
- Dice Loss 的目标是最小化这个值,即最大化预测与真实标签的重叠。
】
4)全局图像级检测损失 L_cls: 使用 <CLS> token 特征判断图像是真是假。
从主干获得最后的隐藏状态 H^hid ∈ R^{N×d},提取 ⟨CLS⟩ 表示
![]()
并将其提供给检测头 F_cls 以获得全局类别逻辑值 u 和概率 p:
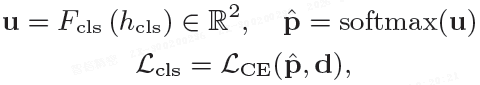
其中 L_cls 为全局检测损失,d ∈ {0,1}^2 是 {真实,篡改} 上的 one-hot 真值。
5)篡改描述生成损失L_text: 使用多模态因果语言模型,基于输入图像 I 和文本提示 P 生成篡改内容的自然语言描述 token 序列的自回归似然 T:
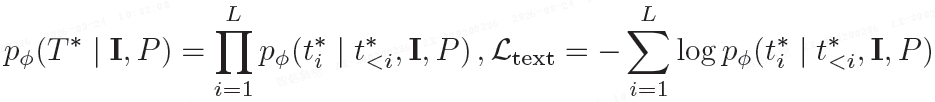
总损失 L_total: 加权组合上述五种损失。
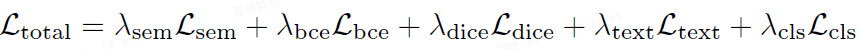
【注:该框架使用较多的损失,且图像相关损失基于像素,当输入图像分辨率增大时,会面临计算量剧增的问题。
然而本文并未给出在训练和测试期间耗时的实验结果。
】
5. 实验
5.1 实验设置
数据: 默认阈值 τ=0.05。测试集(40K 张)在篡改类别、类型和尺寸上保持平衡。
模型: 基于 SIDA 和 LISA 在 PIXAR上 进行微调。
指标: 像素级定位(Recall, F1, AUC, g-IoU, IoU)和语义分类(Top-1/Top-5准确率)。
5.2 主要结果
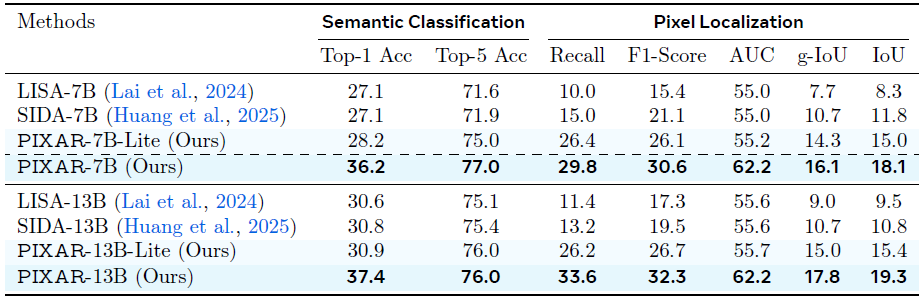
基线对比:在 PIXAR 测试集上,本文的 PIXAR-7B/13B 模型在所有像素定位和语义分类指标上均显著优于 LISA 和 SIDA 等基线模型,证明了基于像素监督的有效性。
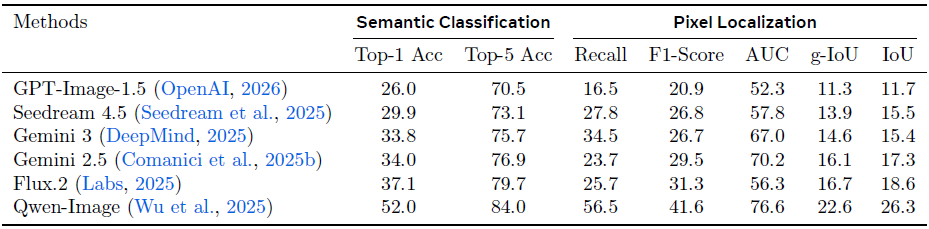
泛化能力:在由 6 种不同生成模型生成的测试集上,本文的模型在所有模型类型上都取得了较高的分数,展示了良好的泛化能力。
5.3 消融研究
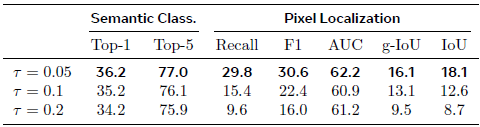
τ 值:较低的 τ 值(如 0.05)能提供更丰富、更具区分性的监督信号,获得更好的像素定位性能。
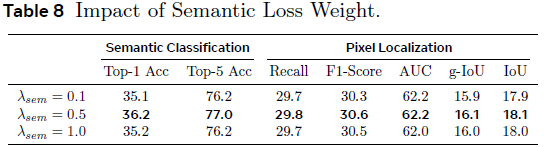
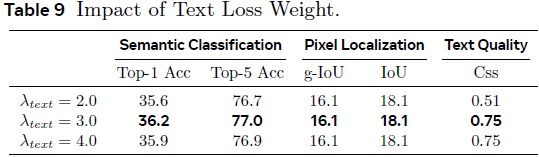
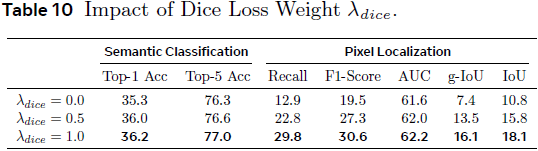
损失权重: λ_sem = 0.5、λ_text = 3.0 能平衡语义、文本生成与定位性能;加入 Dice 损失(λ_dice)能同时提升定位精度和语义分类准确率。
5.4 可视化与用户研究

可视化显示,基于掩码的监督(如 SIDA)难以准确恢复真实篡改区域,而本文的模型能精确定位。

用户研究表明,PIXAR 中的篡改图像具有很高的视觉真实性,人类难以准确分类或定位。
6. 结论
本文将 VLM 篡改检测重新定义为基于像素、融合意义与语言的任务,通过逐像素差异图获取可控标签 M_τ;发布了高保真、大规模的 PIXAR 基准(超 420K 对图像),提供原始/篡改图像、丰富元数据、差异图、推荐像素标签及语言描述;引入了一个像素感知的训练框架,用于定位、语义分类和自然语言描述生成。
实验证明,当前最先进的检测器在仅使用掩码的协议下评估不准确,尤其是在微小编辑和掩码外变化上。本工作为细粒度篡改检测与理解建立了一个更现实、可靠的标准。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)