告别AI“瞬时失忆“!打造你的专属“第二大脑“,实现持久化记忆与智能闭环
文章针对AI"瞬时失忆"痛点,提出构建长短期双层记忆架构的解决方案。核心内容包括:建立长期记忆(长期常青树)存储核心身份、技能与决策;设置短期记忆(流动意识流)记录临时信息;采用混合检索机制(BM25+向量检索)实现精准提取;通过静默代理自动评分与关键词触发实现记忆写入;引入时间权重与衰减算法进行记忆提纯。这套系统使AI能持久化记忆并形成逻辑闭环,最终实现简短指令即可触发复杂任务执行的"第二大脑"效果。
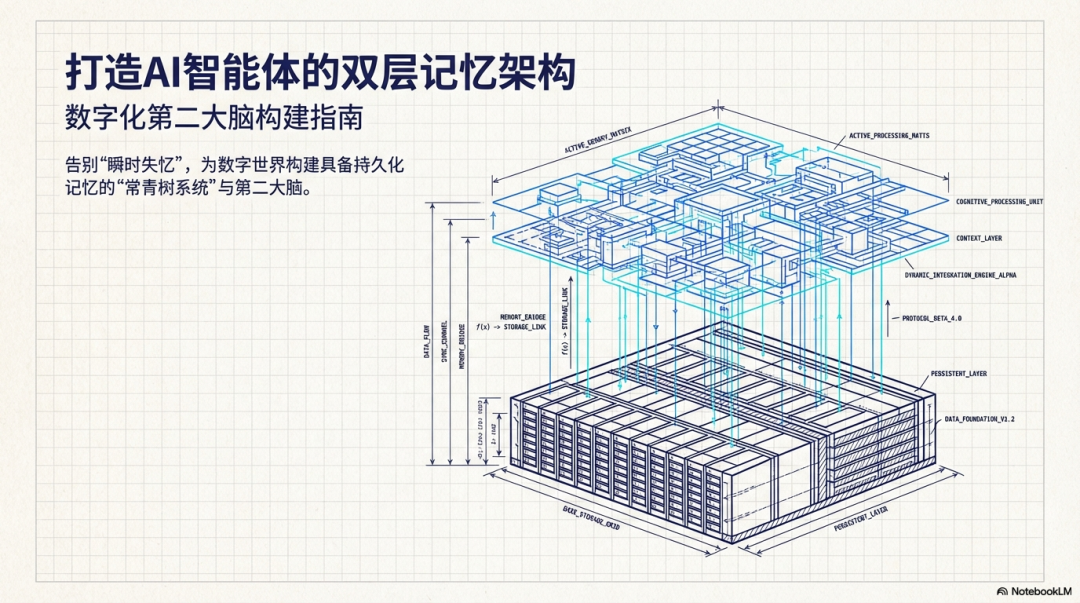
在当前的 Vibe Coding 时代,AI 最大的痛点是“瞬时失忆”,如果没有持久化记忆,每一次的重启或者宕机都会让人非常的崩溃。
那如何长时间有效的管理Agents的记忆呢?
这里我们就需要为 AI 构建一套有持久化记忆的“常青树系统”,从而让 AI 拥有真实的“经验”与逻辑闭环。
从我们长时间一次次崩溃的修正中给到您下面的经验。我们可以从记忆的物理结构、检索机制以及写入与提纯策略这三个核心维度,来构建这套长短期双层记忆架构:
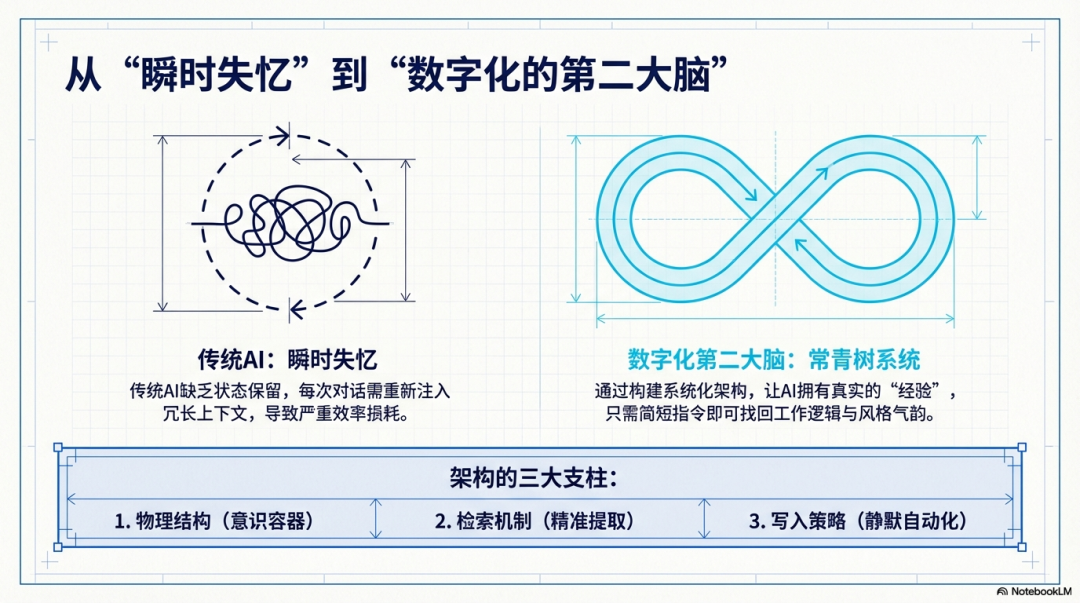
一、 意识的容器:双层记忆结构 (The Memory Layer)**
**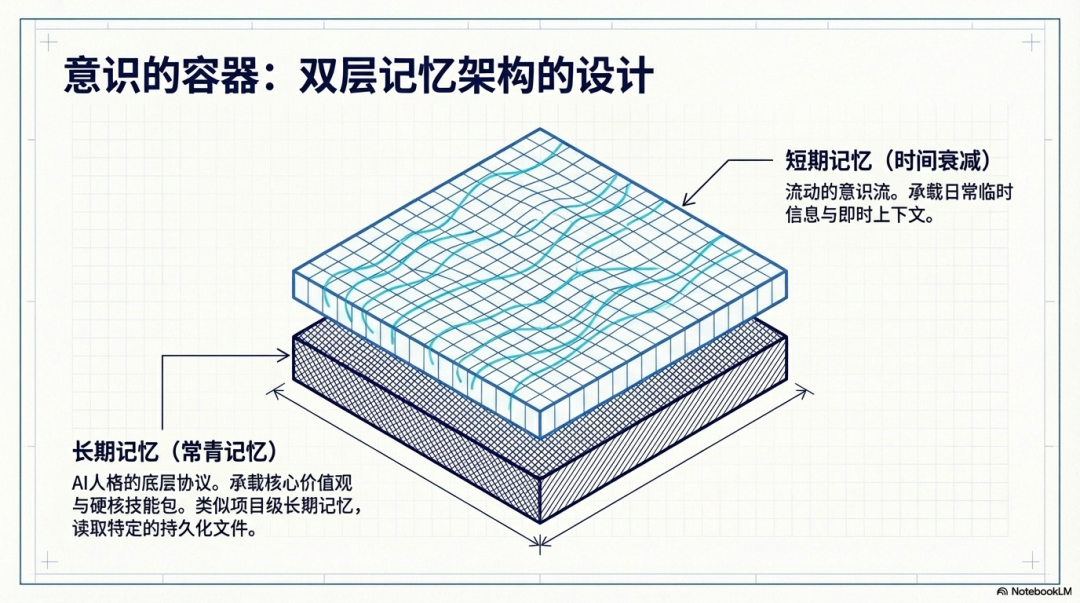
这套架构将记忆从物理层面分为作为底层的“长期常青树”和作为表层的“流动意识流”。
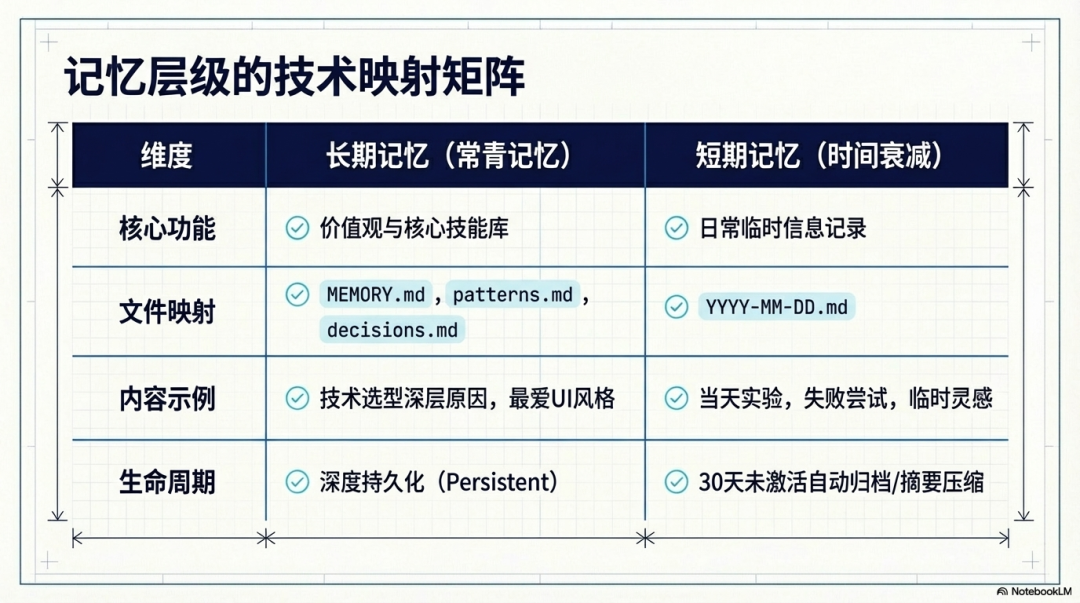
- 长期记忆(常青记忆):人格的底层协议长期记忆不仅仅是数据的堆积,它承载了 AI 的“价值观”与“硬核技能包”。我们可以通过建立特定的 Markdown 文件来实现深度持久化:
- MEMORY.md:用于存储核心身份认同、核心使命与长期愿景。
- patterns.md:作为代码基因库,记录你最喜欢的 UI 风格(如 Tailwind 配置、动效参数等)。
- decisions.md:用于逻辑复盘,记录诸如“为什么当时选择了 Trae 而不是 Cursor”等核心决策背后的深层原因。
- 参考案例:这就类似于 Claude Code 在项目根目录读取的 .claudecode.md 指南,它能记住项目结构、编码禁忌和特定 API 的调用偏好,形成一种“项目级长期记忆”。
- 短期记忆(时间衰减):流动的意识流短期记忆用于承载日常的临时信息与工作记录。
- 记录格式:日常采用 YYYY-MM-DD.md 的格式,记录当天的实验、失败的尝试和临时的灵感。
二、 检索的精度:混合检索机制 (Retrieval Logic)**
**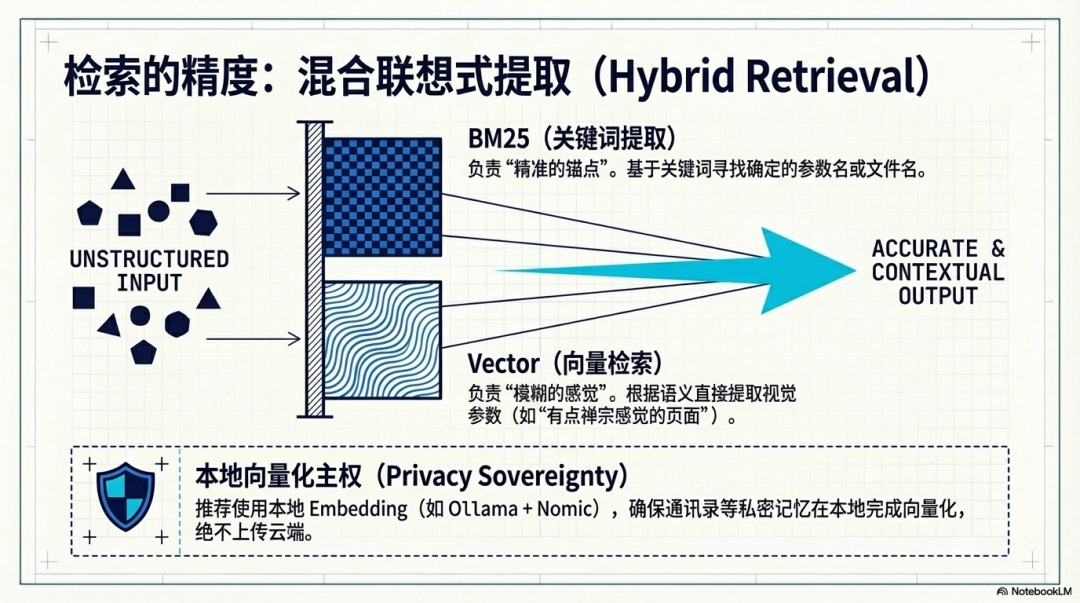
记忆如果不能被精准提取,就会变成数字垃圾,因此需要配置一套高精度的“联想式检索”机制。
- 混合检索 (Hybrid RAG):系统应结合 BM25(关键词检索)和 Vector(向量检索)。BM25 负责寻找确定的参数名或文件名;而向量检索负责寻找“模糊的感觉”,能直接跳过关键词,根据语义(如“那个有点禅宗感觉的页面”)从 patterns.md 中提取对应的视觉参数。
- 保障隐私的本地向量化:推荐使用本地 Embedding 技术(如 Ollama + Nomic)。这能确保所有的记忆向量化都在本地完成,像通讯录(contacts.md)等私密数据不会上传云端,从而最大程度保障隐私主权。
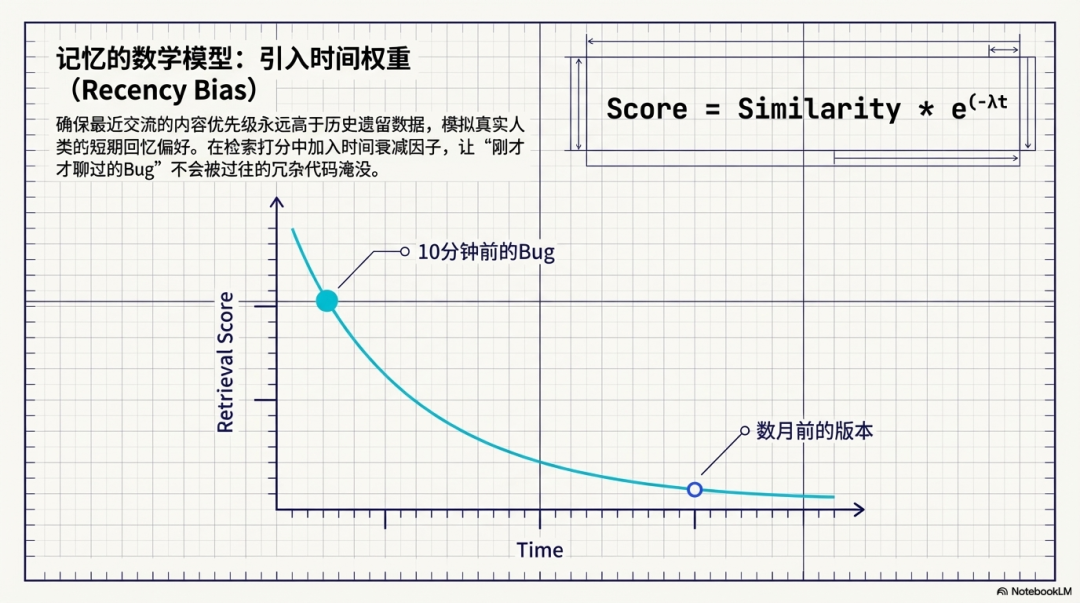
- 引入时间权重 (Recency Bias):在检索打分时引入时间衰减因子,计算公式为:Score=Similarity×e−λtScore = \text{Similarity} \times e^{-\lambda t}Score=Similarity×e−λt。这种机制确保了近期记忆的优先级永远高于远期记忆,例如 10 分钟前聊过的 Bug 优先级一定会高于 10个月前的版本,让陈旧的短期记忆在检索系统中自然衰退。
三、 写入的哲学:自动化与记忆提纯 (Writing Strategy & Compression)**
**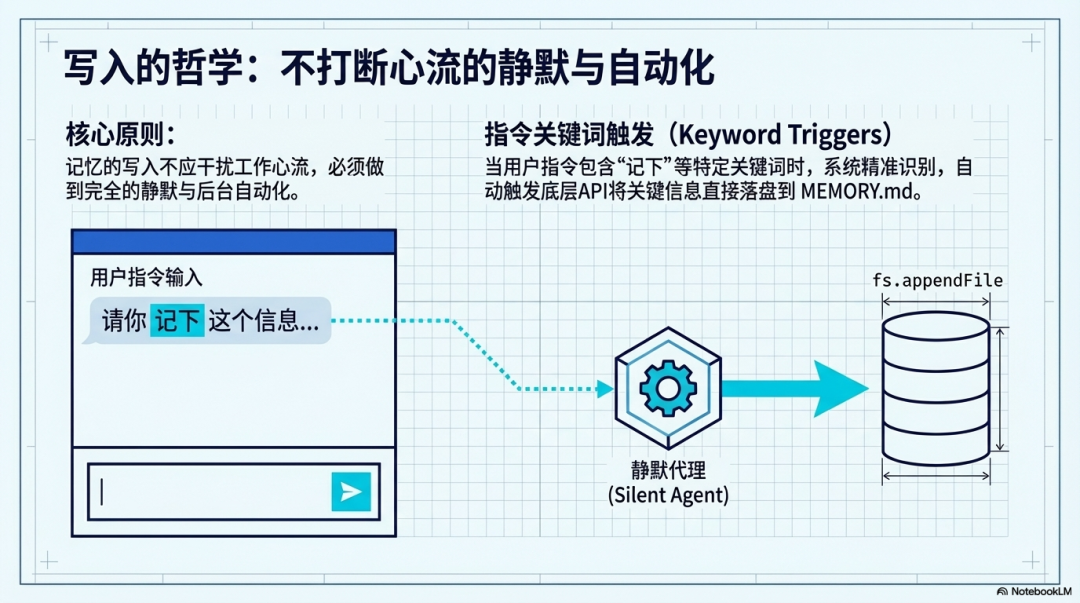
记忆的写入应当是静默且自动化的,绝不能干扰开发者的工作心流(Vibe)。
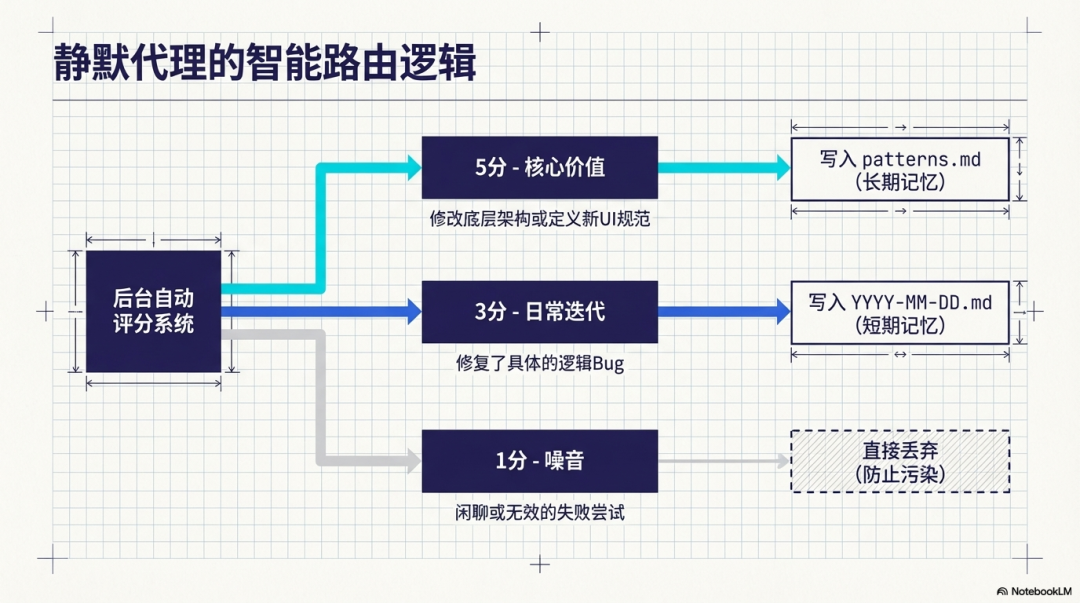
- 静默代理自动评分 (Silent Agent):通过内置代理在后台对每轮对话进行价值评分和初步的分类拦截。
- 5分:当修改了项目底层架构或定义了新 UI 规范时,直接写入 projects.md 或 patterns.md,沉淀为长期记忆。
- 3分:当修复了具体的逻辑 Bug 时,写入 YYYY-MM-DD.md 日志,成为短期记忆。
- 1分:对于闲聊或无效尝试,系统会直接丢弃以避免产生数字垃圾。
- 指令关键词触发:可以参考 OpenClaw 平台的“记忆节点”配置。当用户说出带有“记下”(如“记下这个 API 的正式环境地址”)等特定关键词的指令时,系统识别并触发底层 API(如 fs.appendFile),将关键信息直接落盘到 MEMORY.md 中。
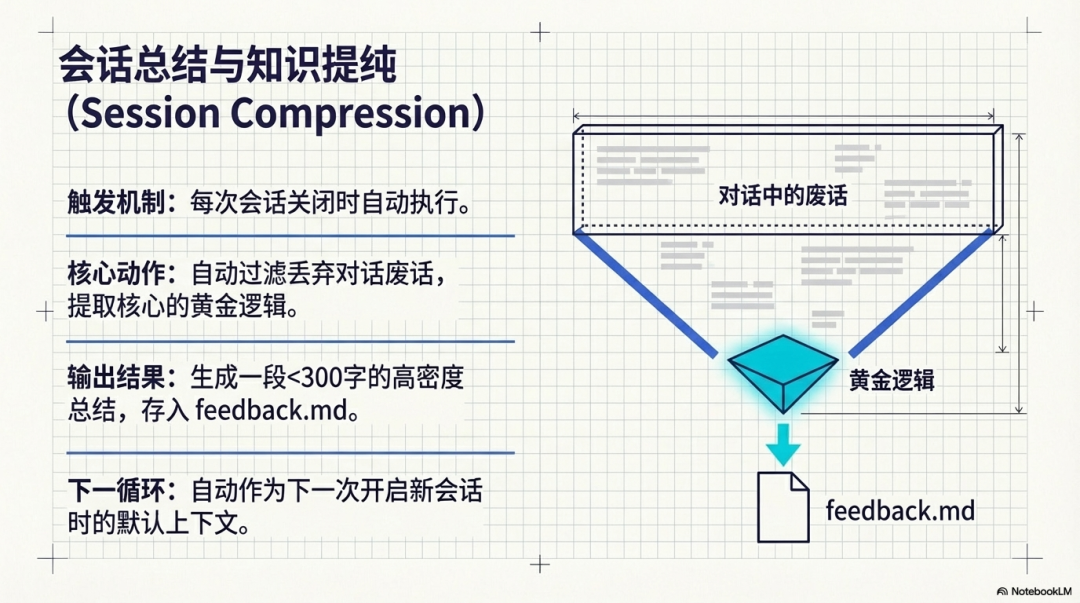
- 衰减算法与知识提纯 (Session Compression):
- 30天衰减机制:为短期记忆设定明确的生命周期,如果内容超过 30 天未被激活使用,系统将自动将其归档或压缩为摘要。
- 会话压缩:每次会话关闭时,AI 会自动丢弃对话中的废话,提取出“黄金逻辑”,生成一段 300 字以内的“知识提纯”总结,存入 feedback.md,作为下次开启会话的默认上下文。
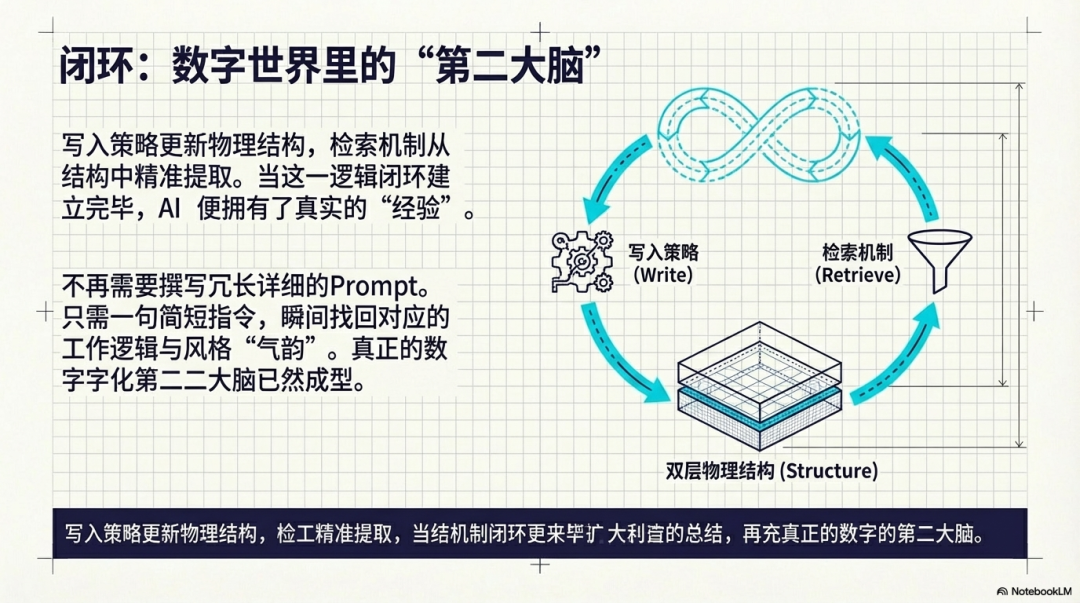
当这套双层架构和逻辑闭环建立完毕后,你不再需要每次都撰写冗长详细的需求描述(Prompt)。你只需要给出简短的指令,例如:“按上次那个风格,帮我加个页面”,AI 就能通过记忆网络瞬间找回对应的工作逻辑和风格“气韵”。这套架构不仅是技术的组合,它更是你在数字世界里为自己留下的“第二大脑”。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献165条内容
已为社区贡献165条内容

所有评论(0)