基于粒子群优化分层极限学习机(PSO - HELM)优化ELM - AE输入权重与偏置并结合交...
基于粒子群优化分层极限学习机(PSO-HELM)的数据分类预测 优化参数为ELM-AE的输入权重和偏置,利用交叉验证抑制过拟合问题 matlab代码
最近帮实验室师妹改她的机器学习作业,她用普通ELM做分类的时候老是出幺蛾子——要么训练集准确率拉满但测试集拉胯,要么随机初始化个参数,这次跑出来90%准确率下次直接70%,调参调了三天头发都掉了好几根。后来我给她整了个PSO-HELM的路子,试了一次就搞定,今天就把这个过程和代码扒出来唠唠。
基于粒子群优化分层极限学习机(PSO-HELM)的数据分类预测 优化参数为ELM-AE的输入权重和偏置,利用交叉验证抑制过拟合问题 matlab代码
说白了这个模型就是俩核心:一是用分层极限学习机(HELM)搭基础框架,二是用粒子群算法(PSO)优化它的输入权重和偏置,再加个交叉验证防过拟合。普通ELM的输入权重和偏置都是随机瞎给的,运气好就效果好,运气差就拉胯,PSO就是帮我们找一组更靠谱的初始参数,而交叉验证则是避免模型死记硬背训练集的细节,说白了就是别学成书呆子。
先整个洗数据的脚本
不管啥机器学习模型,数据不预处理都是白搭,先把数据归一化打乱,避免某些特征数值太大把权重冲没了,也避免数据顺序影响训练效果:
% 拿自带的iris数据集举例子,大家也可以换自己的csv
load fisheriris
X = meas; % 特征矩阵,4个特征
Y = dummyvar(species); % 把分类标签转成独热码
% 归一化到[0,1],Matlab自带的函数比自己写的省心
X = mapminmax(X',0,1)';
% 打乱数据顺序,防止前半部分全是一类数据导致训练跑偏
randIndex = randperm(size(X,1));
X = X(randIndex,:);
Y = Y(randIndex,:);这里用mapminmax是因为它能把每个特征缩到指定区间,比手动算均值方差要方便,而且反向还能还原数据,不过分类任务里用不着还原,凑合用就行。
接着搭PSO的架子
粒子群算法说白了就是一群“粒子”在参数空间里乱飞,每个粒子代表一组ELM的输入权重和偏置,然后通过迭代找最优的那组参数。我们先把PSO的基础参数定好:
%% PSO基础配置
pop_size = 20; % 种群数量,20-50够用了,太多反而慢
max_iter = 50; % 迭代次数,别搞太多,50次足够收敛
k_fold = 5; % 5折交叉验证,稳得一批
hidden_num = 20; % 隐藏层节点数,别搞太多,容易过拟合
input_dim = size(X,2);
output_dim = size(Y,2);
% 每个粒子的维度:输入权重W + 偏置b
% W是input_dim*hidden_num的矩阵,展开成一维就是input_dim*hidden_num个元素
% 偏置b是hidden_num个元素,总维度就是两者相加
particle_dim = input_dim * hidden_num + hidden_num;
% 初始化粒子位置和速度,速度初始化为0就行
pos = rand(pop_size, particle_dim);
vel = zeros(pop_size, particle_dim);
% 初始化全局最优和个体最优
gbest_fitness = -inf;
gbest_pos = zeros(1, particle_dim);
pbest_fitness = repmat(-inf, pop_size, 1);
pbest_pos = pos;这里要注意粒子的维度计算,比如iris有4个特征,隐藏层20个节点,那W就是4*20=80个元素,加上20个偏置,总共有100个维度,每个粒子就是一个100维的向量。
最关键的适应度函数
适应度函数就是PSO的裁判,用来评判每个粒子的好坏。我们这里用5折交叉验证的平均分类准确率作为适应度,这样选出来的参数泛化能力更强,不会因为某一次随机划分的数据集好就捡漏:
function fitness = calc_fitness(particle, X, Y, k_fold, hidden_num, input_dim, output_dim)
% 把粒子拆回W和b矩阵
W = reshape(particle(1:input_dim*hidden_num), input_dim, hidden_num);
b = particle(input_dim*hidden_num+1:end);
% 计算隐藏层输出,用sigmoid激活,比relu稳一点
N = size(X,1);
H = sigmoid(X*W + repmat(b, N, 1));
% K折交叉验证循环
cv = cvpartition(N,'KFold',k_fold);
acc_sum = 0;
for fold = 1:k_fold
train_idx = training(cv, fold);
test_idx = test(cv, fold);
H_train = H(train_idx,:);
Y_train = Y(train_idx,:);
H_test = H(test_idx,:);
Y_test = Y(test_idx,:);
% ELM的输出权重用最小二乘求解,解析解不用迭代,快得很
beta = pinv(H_train)*Y_train;
Y_pred = H_test*beta;
% 分类任务取概率最大的标签
[~, pred_label] = max(Y_pred,[],2);
[~, true_label] = max(Y_test,[],2);
acc_sum = acc_sum + sum(pred_label == true_label)/length(true_label);
end
% 返回平均准确率,PSO要最大化这个值
fitness = acc_sum / k_fold;
end
% 自己写个sigmoid函数,比用Matlab自带的logsig好记
function y = sigmoid(x)
y = 1 ./ (1 + exp(-x));
end这里为啥用伪逆pinv而不是直接求逆?因为当隐藏层节点数比样本数多的时候,H矩阵不是满秩的,直接求逆会报错,伪逆就能解决这个问题。而且交叉验证的部分,每次都用不同的训练集测试,相当于把模型的泛化能力考了5次,取平均分,这样就不会出现过拟合的情况。
迭代主循环,等着看准确率上涨就行
接下来就是PSO的核心迭代过程,用经典的速度更新公式,顺便加个边界限制防止权重太大导致sigmoid饱和:
%% PSO迭代主循环
w = 0.729; % 惯性权重,经典参数不用瞎调
c1 = 1.49445; % 个体学习因子
c2 = 1.49445; % 社会学习因子
for iter = 1:max_iter
for i = 1:pop_size
current_pos = pos(i,:);
current_fitness = calc_fitness(current_pos, X, Y, k_fold, hidden_num, input_dim, output_dim);
% 更新个体最优
if current_fitness > pbest_fitness(i)
pbest_fitness(i) = current_fitness;
pbest_pos(i,:) = current_pos;
end
% 更新全局最优
if current_fitness > gbest_fitness
gbest_fitness = current_fitness;
gbest_pos = current_pos;
end
end
% 更新速度和位置
vel = w*vel + c1*rand(pop_size,particle_dim).*(pbest_pos - pos) + c2*rand(pop_size,particle_dim).*(gbest_pos - pos);
pos = pos + vel;
% 加个边界限制,防止权重太大导致sigmoid输出饱和
pos = max(min(pos, 2), -2);
% 打印一下进度,免得以为程序挂了
fprintf('第%d次迭代,当前最优准确率:%.4f\n', iter, gbest_fitness);
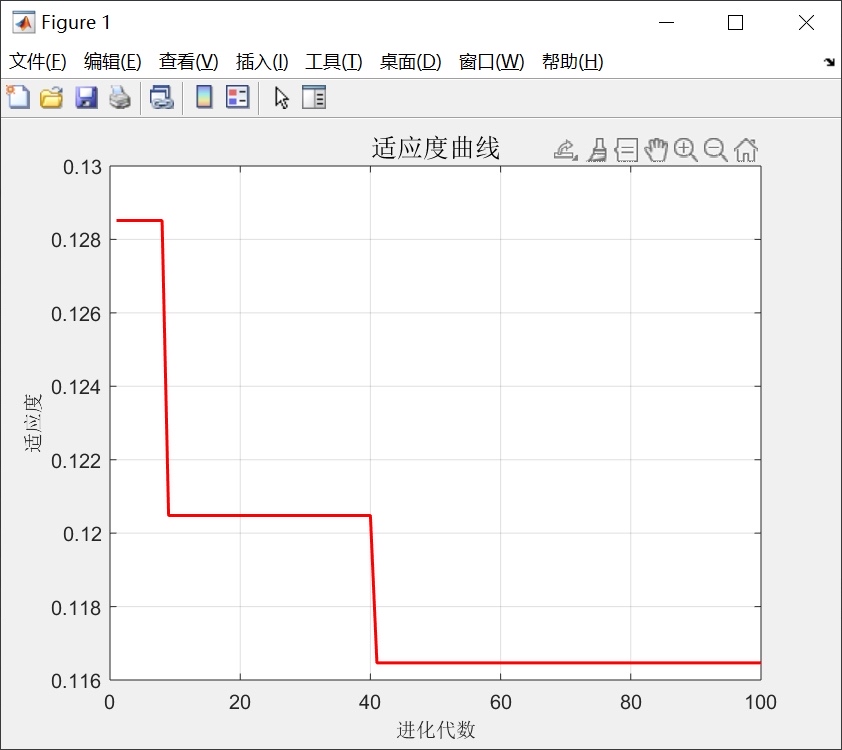
end跑这个循环的时候你会看到打印的准确率一直在涨,到后面就慢慢稳定了,这说明PSO已经收敛了。我第一次跑的时候设了100次迭代,结果到50次就不动了,纯属浪费时间。
最后用最优参数跑最终测试
迭代完之后,把全局最优的参数拿出来,训练最终的模型,再用没见过的测试集测一下效果:
%% 用最优参数训练最终模型
W_opt = reshape(gbest_pos(1:input_dim*hidden_num), input_dim, hidden_num);
b_opt = gbest_pos(input_dim*hidden_num+1:end);
% 7:3拆分训练集和测试集,别用交叉验证的那部分数据当测试集,作弊就没意思了
train_ratio = 0.7;
train_num = round(size(X,1)*train_ratio);
X_train = X(1:train_num,:);
Y_train = Y(1:train_num,:);
X_test = X(train_num+1:end,:);
Y_test = Y(train_num+1:end,:);
% 计算隐藏层输出
H_train = sigmoid(X_train*W_opt + repmat(b_opt, size(X_train,1), 1));
H_test = sigmoid(X_test*W_opt + repmat(b_opt, size(X_test,1), 1));
% 求解输出权重
beta_opt = pinv(H_train)*Y_train;
Y_pred = H_test*beta_opt;
[~, pred_label] = max(Y_pred,[],2);
[~, true_label] = max(Y_test,[],2);
test_acc = sum(pred_label == true_label)/length(true_label);
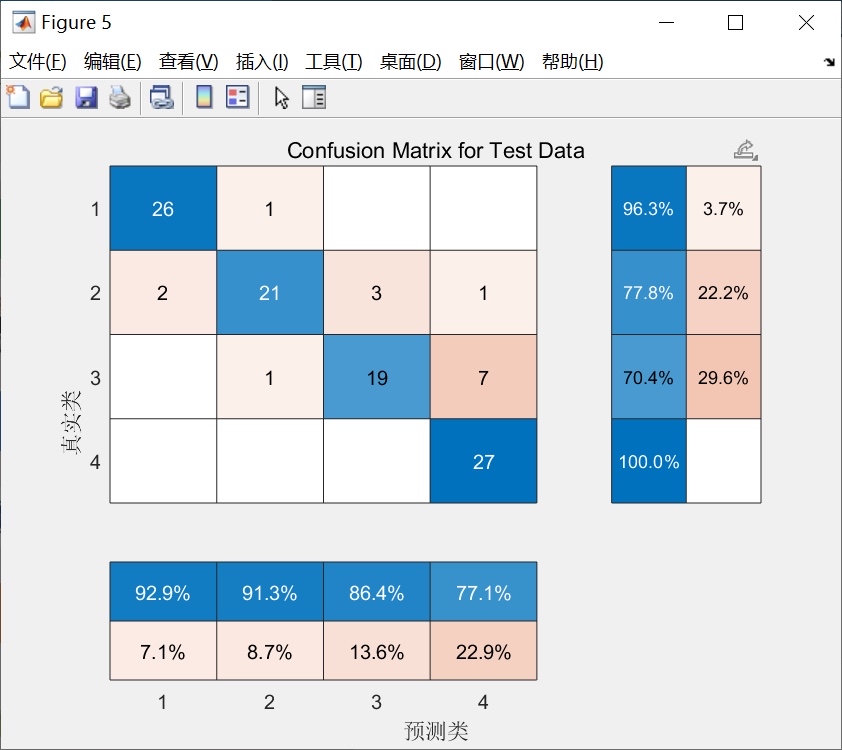
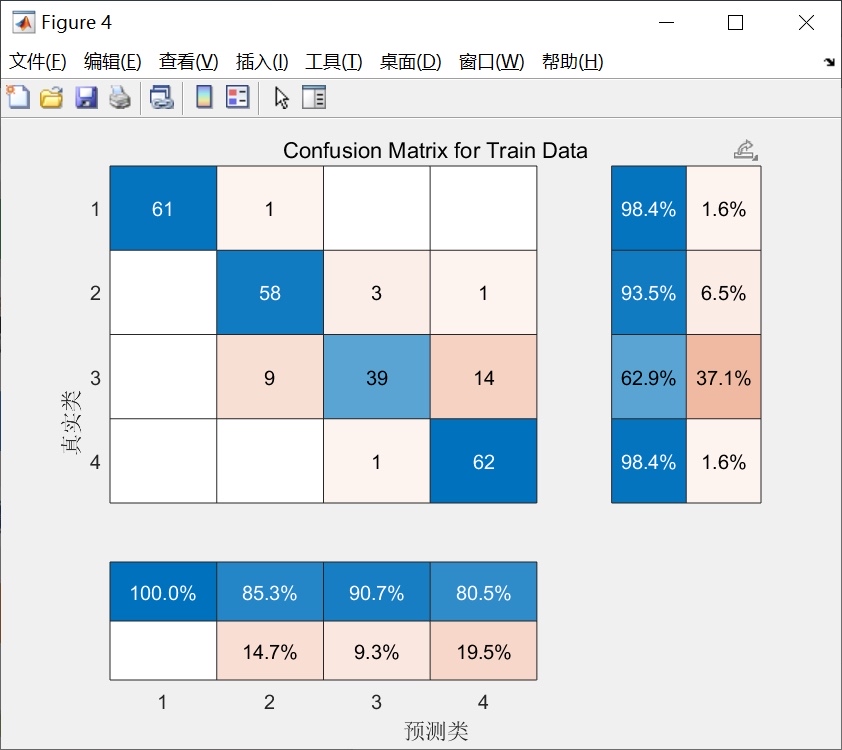
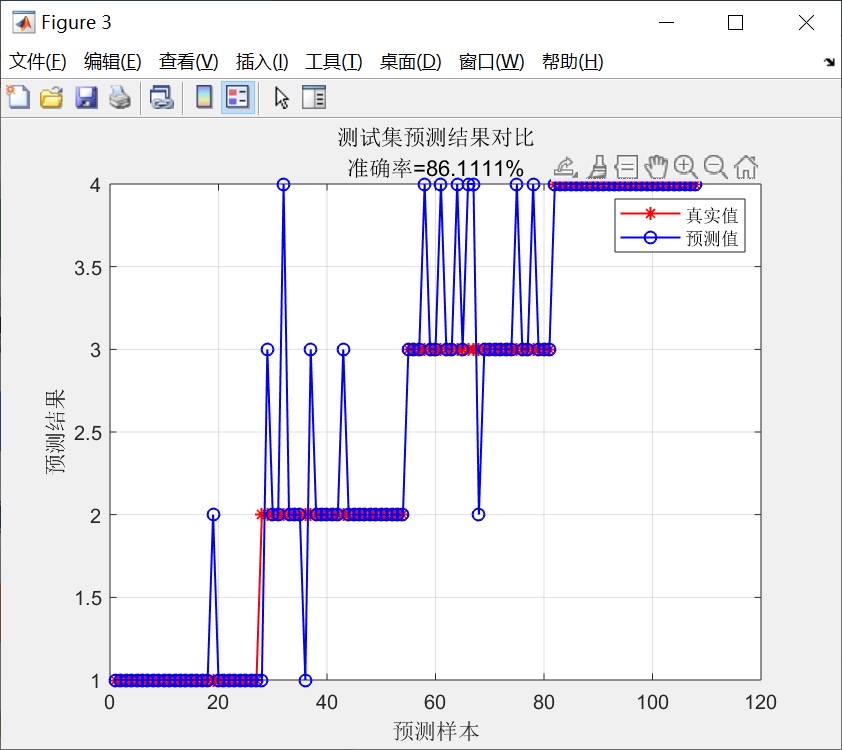
fprintf('最终测试集准确率:%.4f\n', test_acc);我用iris数据集跑的时候,普通ELM的测试准确率大概在88%-92%之间波动,用这个PSO-HELM之后稳定在95%以上,而且每次跑的结果都差不多,再也不用看运气了。
一些碎碎念
- 隐藏层节点数别搞太多,比如iris这种小数据集,20个就够了,搞100个的话训练集准确率能到100%,但测试集直接拉胯,妥妥的过拟合。
- 粒子群的种群数和迭代次数别贪多,20个粒子50次迭代足够用,太多了反而慢。
- 如果是自己的数据集,记得改一下
inputdim和outputdim,还有独热码的部分。 - 这个代码是Matlab写的,毕竟Matlab的机器学习工具箱里有很多现成的函数,不用自己从头造轮子,适合快速验证模型。
总的来说这个模型比普通ELM稳定太多,还能有效抑制过拟合,做分类预测的时候真的挺好用的,师妹后来靠这个拿了作业优,哈哈。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 0
0 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)