最新综述 | 遥感中的基础模型:从单模态到多模态的演进
最新综述 | 遥感中的基础模型:从单模态到多模态的演进

题目: Foundation Models in Remote Sensing: Evolving from Unimodality to Multimodality
论文: https://arxiv.org/pdf/2603.00988
作者:Danfeng Hong (IEEE Senior Member), Chenyu Li, Xuyang Li, Gustau Camps-Valls (IEEE Fellow), Jocelyn Chanussot (IEEE Fellow)
单位:东南大学,、空天院、国科大等
年份:2026.3
核心摘要
随着遥感数据量和多样性的指数级增长,传统模型已难以应对高维、多源数据处理的挑战 。本文对遥感领域的基础模型进行了全面的技术综述,首次从单模态到多模态演进的全新视角切入 。文章不仅回答了什么是遥感大模型、为什么需要它们,还为初学者提供了一套从预训练到下游任务微调的实操指南 。
研究背景与动机
数据的爆发与局限:传统地球观测(EO)技术在监控地表、环境和气候变化方面至关重要,但遥感数据具有高维度、时空耦合和多传感器(光学、SAR、LiDAR等)的复杂性,传统方法难以捕捉其丰富的语义信息 。
标注成本瓶颈:遥感图像的像素级标注极其耗时耗力,导致大规模标注数据集匮乏 。
大模型的优势:基础模型通过在大规模无标签数据上进行自监督预训练,学习通用特征表示,再通过少量标注数据即可在下游任务(分类、分割、检测等)中获得极佳表现 。
核心范式演进:从传统到大模型
传统范式:主要依靠手动提取特征或端到端学习,极度依赖有标签数据 。
大模型范式(自监督学习 + 微调):
-
预训练(Pretraining):利用对比学习(Contrastive
Learning)或生成式/掩码图像建模(MAE/MIM)损失,在海量无标签遥感图像上训练 。 -
微调(Fine-tuning):将预训练好的参数转移到下游任务,通过冻结部分权重或使用Adapter/LoRA等技术进行高效迁移 。
遥感大模型分类解析
- 单模态基础模型(Unimodal FMs)
专注于处理单一类型的数据源:
-
光学/RGB数据:如 Scale-MAE(关注跨尺度泛化)、SatMAE++(增强分辨率感知特征提取)、RingMo-Aerial(针对航空影像)。
-
光谱数据:SpectralGPT 是首个专为光谱遥感设计的模型,利用3D掩码策略建模空间-光谱耦合 。
-
合成孔径雷达(SAR):如 FG-MAE(利用HOG特征进行SAR重建)、SAR-JEPA(预测梯度信息)。
-
多模态基础模型(Multimodal FMs)
这是当前的最前沿趋势,旨在整合多源异构数据: -
时序模态:如 SeCo(季节性对比学习),处理卫星图像的时间序列变化 。
-
视觉-地理位置(Geo-Vision):如 GeoCLIP,将遥感图像与全球GPS坐标对齐 。
-
视觉-语言模型(VLM/VQA):如 SkySenseGPT(引入地理交互推理)、Text2Earth(基于文本生成的全球遥感场景建模)。
-
视觉-音频:SoundingEarth 通过对齐遥感图像与对应音频进行预训练 。
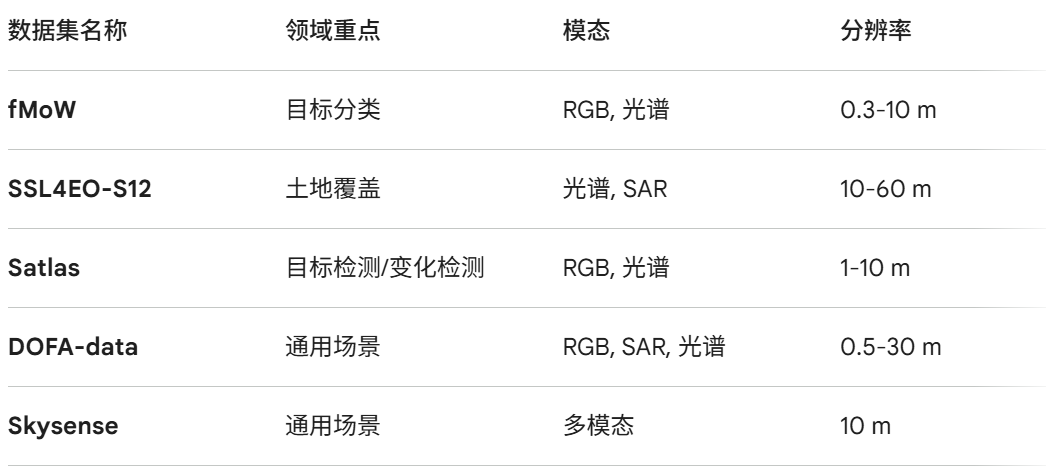
关键数据集汇总
实践操作指南:如何应用遥感大模型
- 步骤1:任务分析与准备:明确下游任务(如森林火灾检测),收集并预处理特定数据。
- 步骤2:模型选择:根据算力资源和任务类型选择Backbone(如CNN, ViT, Swin-Transformer) 。
- 步骤3:模型加载与微调:全参数微调:数据量大时使用。参数高效微调(PEFT):如使用 LoRA 仅训练极少量参数,适合计算资源有限的场景。
- 步骤4:部署与提示工程:对于视觉-语言模型,设计结构化提示语(Prompt),如“你是一个遥感分析专家,给定这张Sentinel-2图像…”以减少幻觉。
挑战与未来研究方向
- 知识鸿沟:遥感研究者普遍缺乏对基础模型(如自监督学习)的底层理解 。
- 分类与评估标准缺失:缺乏统一的模型评估框架和基准数据集 。
- 未来方向:
- 时空建模:更深入地整合遥感的时间动态特性。
- 可解释性AI:让黑盒大模型的决策过程对地球科学研究更透明 。
- 高效部署:如何将数十亿参数的模型应用到实时监测任务中。
结论与启发
- 核心启发:遥感领域正处于从“为每个特定任务训练一个小模型”转向“在一个通用大模型基础上进行微调”的范式革命 。
- 多模态融合是关键:仅靠单一的光谱或光学信息已无法满足精准观测的需求,融合SAR、文本描述乃至音频的多模态模型(如DOFA, Skysense)将是未来的主流 。
另外本人最近正在研究如何解决处理遥感视觉语言模型的多模态问题,特此单开一小章节,用于记录学习
多模态问题解决措施
针对遥感领域日益复杂的多模态(Multimodal)场景,本文详细梳理了学术界主流的解决思路和具体技术手段。总的来说,专家们认为解决多模态问题的核心在于**“如何弥合异构数据间的语义鸿沟并实现高效融合”** 。
- 多模态场景的两大基本对策
根据数据源的相似性,专家们提出了两种截然不同的处理逻辑:
-
同质数据(Homogeneous Data)的直接融合:
- 场景:来自相同来源但不同传感器的数据(如 Sentinel-2 和 Landsat) 。
- 解决方法:通常采用数据级融合(Data-level fusion),通过波段堆叠(Band
Stacking)、重采样或分辨率增强技术直接合并 。
-
异构数据(Heterogeneous Data)的特征融合:
- 场景:成像原理完全不同的数据,如光学(Optical)与雷达(SAR)、光学与高程模型(DEM) 。
- 解决方法:由于物理特性差异巨大,无法在原始像素级合并,因此推荐特征级融合(Feature-level fusion)。具体包括:
- 早期特征拼接:在特征提取初期进行叠加。
- 中期特征交互:在模型中间层进行信息交换。
- 后期决策融合:在模型输出端进行组合。
-
核心技术架构与算法手段
文中提到,为了让模型真正理解多模态信息,目前主流采用了以下进阶技术 : -
跨模态注意力机制(Cross-modal Attention):这是目前最火的方案,通过注意力权重动态捕捉不同模态间的互补信息,实现“1+1>2”的效果 。**
-
对比学习对齐(Contrastive Alignment)**:
- 视觉-文本对齐:如 RS-CLIP 和 RemoteCLIP,通过对比损失函数,让图像特征和对应的文本描述在向量空间中靠近 。
- 视觉-地理位置对齐:如 SatCLIP 和 GeoCLIP,将遥感图像与全球 GPS 坐标对齐,赋予模型地理空间感知能力 。
-
多条件控制扩散模型(Multi-condition Diffusion):在生成场景下(如 CRS-Diff),通过同时输入文本、元数据和图像作为控制条件,实现精准的多模态数据生成 。
-
知识注入与适配器(Adapters/LoRA):如
MAF-SAM,利用轻量化的适配器(Adapters)将特定领域知识(如农作物特性)注入到预训练好的图像编码器中,解决模态失配问题 。
3. 不同场景的具体解决路径 -
时序模态(Temporal/Time-Series):针对季节变化导致的数据差异,专家提出“季节感知”策略,如 SeCo 和 Seamo 方案,通过时间序列建模来学习地物的动态演变特征 。
-
视觉-语言交互(Vision-Language / VLFMs):
-
解决思路:将光谱/空间特征(Tokens)与文本描述符进行对齐 。
-
防幻觉策略:在提示工程(Prompt Engineering)中加入明确的遥感上下文(如:“你是一个遥感分析专家,给定一张 10m 分辨率的 Sentinel-2 图像…”),以减少模型由于多模态理解不足产生的“幻觉” 。
-
视觉-音频融合:如 SoundingEarth,尝试通过对齐卫星图像与地面环境音,挖掘跨模态的相关性 。
-
常见关键步骤
-
构建可靠的配对数据集:高质量的“图像-文本”或“图像-地理坐标”对是基础。
-
选择合适的连接器(Connector):根据模态差异选择合适的跨模态注意力模块或融合架构。
-
精细化对齐:必须将遥感特有的光谱/空间信息(Tokens)与文本描述符精准匹配。
-
资源敏感型微调:考虑到多模态大模型的计算压力,推荐使用参数高效微调(PEFT)策略 。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)