一文讲透 Agent Skill:定义、目录结构、原理与实战思路
很多人第一次接触 Agent Skill,都会有一种感觉:
“这不就是把 prompt 存起来吗?”
“这和 MCP 到底有什么区别?”
“既然都能跑脚本了,为什么还要 MCP?”
“它到底是怎么节省上下文、减少 Token 消耗的?”
这些问题不搞清楚,Skill 很容易被用成“高级提示词文件夹”;而一旦搞清楚,你会发现它其实是在 AI Agent 时代非常重要的一种能力封装方式。
今天这篇文章,我想把 Agent Skill 从概念、用法、原理到边界一次讲清。你看完之后,至少会明白 8 件事:
-
Agent Skill 到底是什么
-
它为什么不是普通 prompt
-
它的基本目录结构怎么设计
-
SKILL.md 应该怎么写
-
Reference 和 Script 分别解决什么问题
-
什么叫“渐进式披露机制”
-
Agent Skill 和 MCP 的本质差异是什么
-
在真实项目里,到底该怎么组合它们
一、内容简介
Agent Skill 可以先理解成:给 AI Agent 写的一份可复用工作手册。
它不是一次性提示词,而是一套可以长期复用的任务说明、规则约束、参考资料和可执行资源。Anthropic 官方把它定义为一种“模块化能力封装”:每个 Skill 都可以打包元数据、指令,以及可选的资源文件,比如脚本、模板、参考资料等;Claude 会在合适的时候自动调用它。
如果用企业里的比喻来讲:
-
Prompt 像你临时口头交代一句话
-
Skill 像你给新同事的一份岗位 SOP
-
MCP 像把这个同事接入 ERP、CRM、数据库、工单系统
-
Subagent 像你再给他配几个分工明确的专业助手
所以,Skill 的核心价值,不是“让模型多知道一点”,而是:
把重复方法论、固定流程、组织知识和执行入口,封装成一个 AI 可以反复调用的标准化能力。
二、Agent Skill 是什么
先说最通俗的版本。
1)它是“说明文档”,但不只是说明文档
很多入门讲法会说:Agent Skill 就是一个大模型可以随时翻阅的说明文档。这个说法没错,而且很好懂。
例如:
你做智能客服,可以在 Skill 里写:遇到投诉先安抚,不得越权承诺退款
你做会议纪要,可以在 Skill 里写:输出必须包含参会人、议题、结论、待办
你做代码评审,可以在 Skill 里写:先看安全风险,再看性能,再看可维护性
这样你就不用每次都重新粘贴一大段提示词了。
但如果只把它理解为“说明文档”,还是低估了它。
因为一个完整的 Skill,除了主说明文件 SKILL.md,还可以带上参考资料、脚本、模板、资源文件。Anthropic 官方明确说明:Skill 是以文件夹形式组织的能力包,通常至少包含 SKILL.md,并可以扩展为脚本、参考文档、模板等资源。
my-agent-skill/
├── SKILL.md
├── references/
│ ├── finance-policy.md
│ ├── meeting-template.md
│ └── product-guide.md
├── scripts/
│ ├── upload.py
│ ├── summarize.py
│ └── validate.sh
└── assets/
├── example-input.txt
└── example-output.md
说明
SKILL.md:核心入口,定义 Skill 的名称、描述、规则、步骤与触发条件references/:放参考资料,供模型在特定场景下按需读取scripts/:放可执行脚本,供模型在需要时触发执行assets/:放示例、模板、样例输入输出,帮助模型更稳定地理解任务
也就是说,Skill 更准确的定义应该是:
一种面向 Agent 的能力封装单元:它既能教模型“怎么做”,也能在需要时为模型提供“参考什么”和“执行什么”。
2)它解决的核心痛点是什么
Skill 解决的,不是模型“不会说”,而是模型“不会稳定地按你的方式做”。
真实工作里,最麻烦的并不是让模型回答一个问题,而是让它:
-
长期遵循同一套格式
-
遵循组织规范
-
在恰当的时候查恰当的资料
-
在恰当的时候执行恰当的脚本
-
不要每次都把几千字要求重新塞进上下文
这就是 Skill 的意义。
它把“方法论”和“组织知识”从零散 prompt,升级成了可复用能力。
三、Agent Skill 的基本用法
先讲最基础的使用方式。
在 Claude Code 文档中,Skill 的基本形式是一个目录,核心文件是 SKILL.md。Claude 会在相关请求中自动使用 Skill,也可以通过命令直接调用。
1)最小可用结构
一个最简 Skill,通常长这样:
~/.claude/skills/
└── 会议总结助手
└── SKILL.md
在 Claude Code 场景里,用户可以把 Skill 放在相应的 skills 目录下进行管理;官方文档说明,Skill 以
SKILL.md 为核心,Claude 会将其纳入工具箱,并在请求相关时自动使用。
2)SKILL.md 的基本组成
一个典型的 SKILL.md,通常包含两部分:
第一部分:元数据
也就是 frontmatter / metadata。
例如:
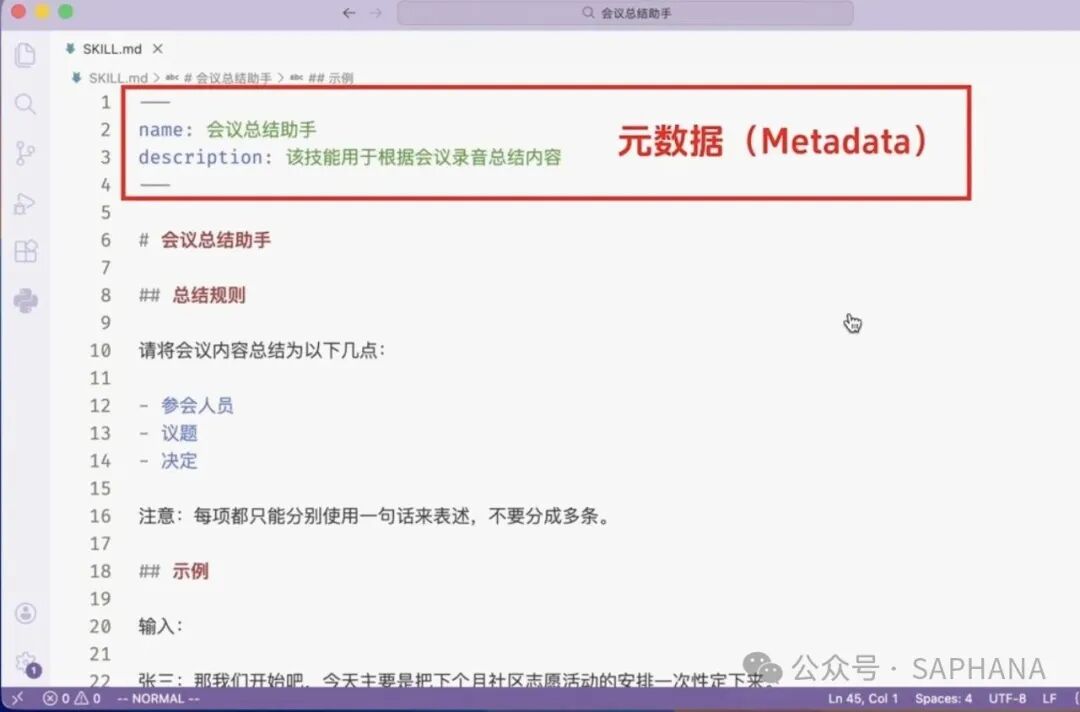
它的作用不是直接约束回答细节,而是告诉模型:
-
这个 Skill 叫什么
-
它适合处理什么任务
这部分非常关键,因为模型一开始看到的,往往就是这些“轻量级索引信息”。
第二部分:正文指令
这部分才是真正告诉模型“怎么做”的规则。
例如:
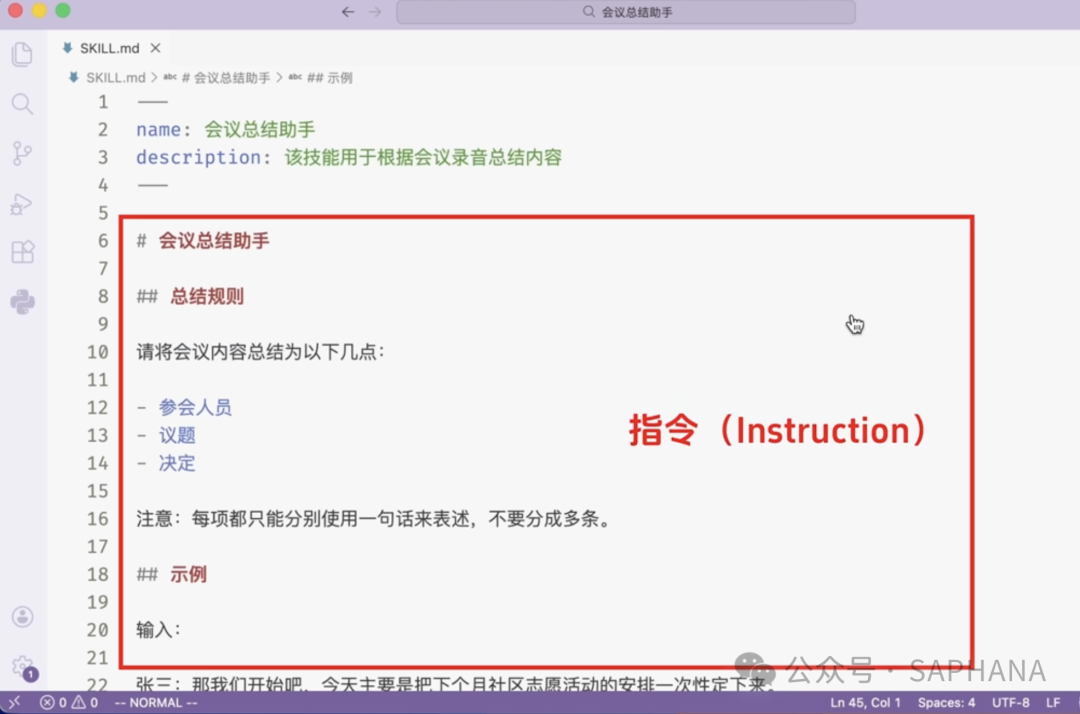
你也可以在这里补充:
-
输出格式
-
风格要求
-
错误处理
-
禁止事项
-
示例输入输出
3)一个直观例子:会议总结助手
假设你想做一个“会议总结助手”。
那么这个 Skill 的目标就不是“帮我总结”,而是更具体:
-
输入:会议录音转写文本
-
输出:参会人员、议题、结论、待办事项
-
风格:简洁、商务化
-
规则:不能臆造缺失信息
---
name: 会议总结助手
description: 该技能用于根据会议录音总结内容
---
# 会议总结助手
## 总结规则
请将会议内容总结为以下几点:
- 参会人员
- 议题
- 决定
注意:每项都只能分别使用一句话来表述,不要分成多条。
## 示例
输入:
张三:那我们开始吧,今天主要是把下个月社区志愿活动的安排一次性定下来。
李四:我建议活动放在公园,人多也方便组织。
王五:可以,不过要提前申请场地,不然可能有风险。
赵六:场地申请我可以负责,这周内给大家结果。
孙七:人数最好先有个范围,方便准备物资。
张三:那就先按 50 人左右来估算吧。
李四:上次的手套还能用,但垃圾袋需要再买。
王五:预算要不要设个上限,避免超支。
张三:预算控制在 1000 以内,优先用现有物资。
孙七:时间我建议周六上午,天气也不会太热。
李四:九点集合应该比较合适。
赵六:我周三前把申请结果同步到群里。
张三:好,那报名截止时间定在周四晚上。
王五:周五可以统一分组和采购。
孙七:我来负责写报名文案和活动当天的合影安排。
张三:安全方面提醒大家带水,活动结束简单总结一下就行。
张三:那今天就到这,大家按分工推进。
输出:
- 参会人员:张三、李四、王五、赵六、孙七
- 议题:统一确定下个月社区志愿活动的地点、时间、人数、预算及分工安排。
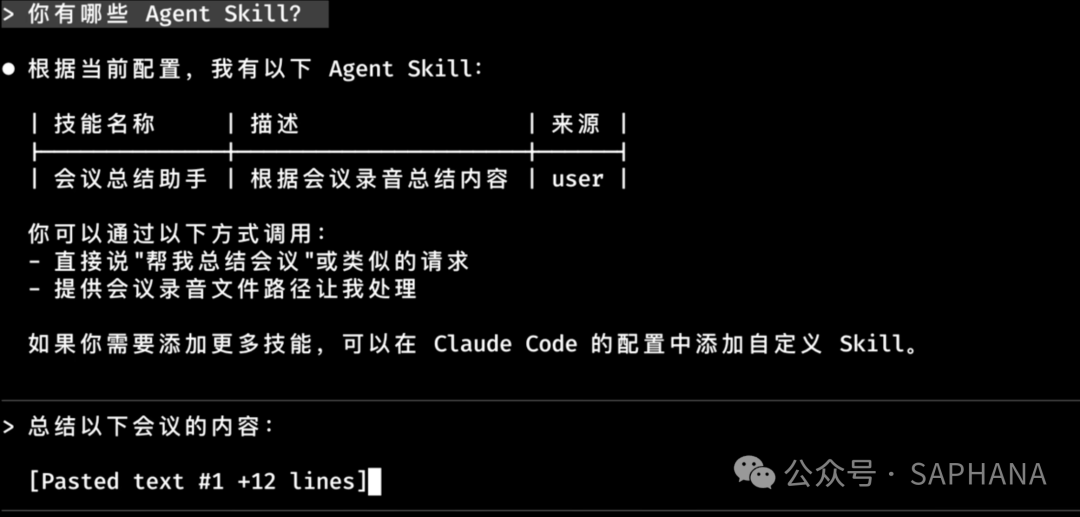
- 决定:活动定在公园并于周六上午九点举行,按约 50 人规模和 1000 预算执行,由赵六负责场地申请,孙七负责宣传及合影,其余成员配合物资和分组。这时候,Skill 就是把这些规则固化下来。之后你每次只需要说:
“总结以下会议的内容:”
Claude 检测到你的请求和这个 Skill 相关,就会自动把这套规则用起来。官方文档也明确提到:Skill 的价值之一,就是创建一次,自动反复使用。
四、Agent Skill 的基本用法,背后到底发生了什么
这一步很重要。很多人会用 Skill,但不知道它为什么“省 Token”。本质上,Skill 不是把所有内容一上来全塞给模型,而是分层加载。
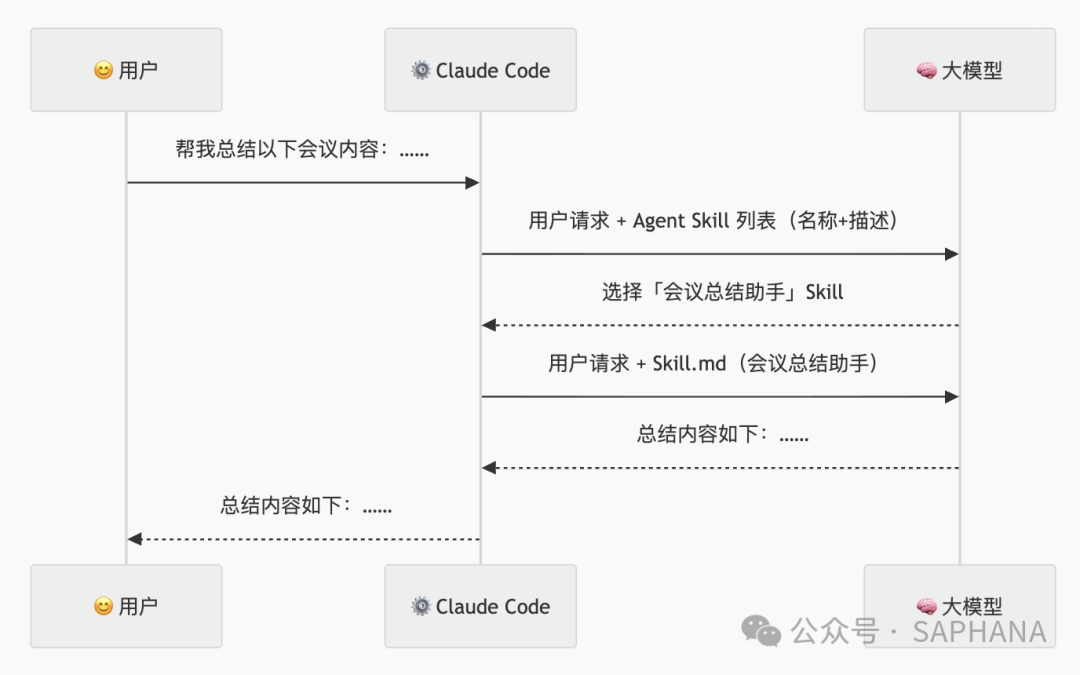
即:
一开始给模型看的,通常只是 Skill 的名称和描述;只有模型判断相关时,才会继续读取完整的
SKILL.md。
这和 Anthropic 官方强调的方向是一致的:Skill 是按需使用的,相关时自动调用,而不是默认把全部能力细节硬塞进上下文。
你可以把过程理解成三步:
第一步:先看目录
模型先看到所有 Skill 的“名字 + 描述”。
这相当于一本工具手册的目录页。
第二步:选中后再读正文
如果模型判断这个请求和某个 Skill 有关,Claude 才去读取对应 Skill 的 SKILL.md 正文。
第三步:需要更深资源时,再继续加载
如果正文里又提到需要查参考资料,或者需要执行脚本,那么系统再去读取 Reference 或执行 Script。
这一层层往下走,就是 Skill 真正厉害的地方。
五、Agent Skill 的高级用法(Reference)
这是很多人第一次真正意识到 Skill 很强的地方。
1)Reference 是什么
Reference 可以理解为:
这个 Skill 在特定条件下,才会去读取的参考材料。
它可能是:
-
财务制度
-
法务条款
-
品牌规范
-
会议模板
-
产品手册
-
项目实施说明
-
API 说明文档
这些内容不一定适合全塞进 SKILL.md,因为太长、太杂,而且很多时候根本用不上。所以更合理的做法是:
-
在
SKILL.md里先写清楚触发条件 -
真正需要的时候,再去读取具体的 Reference 文件
这就是“按需中的按需”。这个文件 集团财务手册.md 放在 references/ 目录下。
# 集团财务手册
## 第一章:办公设备采购(IT Assets)
1. **更换周期**:笔记本电脑、显示器等固定资产的最低使用年限为 3 年。
2. **采购限额**:
- 标准办公电脑:单价不得超过 10,000 元。
- 高性能工作站:单价 10,000 - 20,000 元,需部门总监(Director)审批。
- 特殊定制设备:单价超过 20,000 元,必须由 IT 总监特批,并提交 CFO 最终签字。
3. **招标要求**:单笔采购总额超过 50,000 元时,必须启动至少三方参与的公开招标流程。
---
## 第二章:国内差旅标准(Domestic Travel)
1. **住宿补贴(按城市等级)**:
- 一线城市(北京、上海、广州、深圳):800 元/晚。
- 新一线及二线城市:500 元/晚。
- 其他城市:350 元/晚。
2. **交通工具**:
- 飞行时长 4 小时以内仅限经济舱。
- 高铁限二等座(部门副总及以上级别可选一等座)。
---
## 第三章:商务招待与餐饮(Entertainment)
1. **招待标准**:
- 普通客户:人均不超过 150 元。
- 重要客户:人均不超过 300 元,需提前报备。
2. **酒水规定**:
- 原则上不报销酒精类饮品。
- 特殊情况需部门负责人审批。
---
## 第四章:日常零星报销
1. **自主额度**:单笔 500 元以下的办公杂费支出可由员工自主报销。
2. **主管审批**:500 元至 5,000 元的支出由部门直接主管在系统内审批。
---
## 第五章:市场活动与公关
1. **预算申报**:所有涉及品牌推广、市场活动的预算需提前 14 天提交 OA 流程申报。
2. **礼品采购**:单份赠礼价值上限为 300 元。
---
*注:以上所有金额单位均为人民币(CNY)。违反以上限额且未获得特批的申请,财务部将予以退回。*2)为什么要这样设计
假设你做的是“会议总结 Skill”,但你希望它在涉及预算、采购、报销时,顺带做合规提醒。这时你当然可以直接把财务制度全文塞进 SKILL.md。
问题是:
-
文件会变得很臃肿
-
普通会议也要白白加载这些内容
-
上下文被污染
-
Token 消耗明显增加
所以更优雅的方案是:
在 SKILL.md 里写:
-
当会议内容涉及预算、费用、采购、报销时
-
读取
集团财务手册.md -
根据里面的规则判断是否超标
-
标出审批要求或风险提示
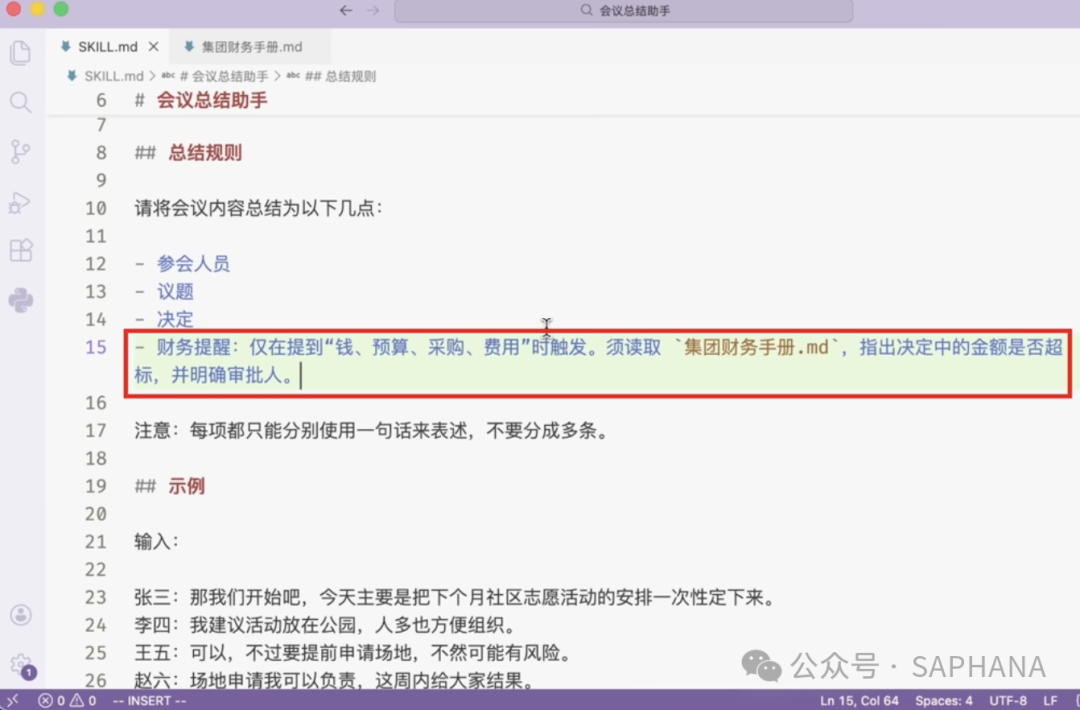
这样一来,不涉及财务的会议,就不会读这个文件;只有真正相关时,才加载它。
这正是 Skill 的设计精髓之一:让知识不是“常驻内存”,而是“按需取用”。
3)Reference 的本质:读
这里一定要抓住一个关键词:
Reference 的动作是“读”。
也就是说,Reference 文件内容会被读取,进入模型的上下文,成为回答依据的一部分。因此它会消耗 Token。官方也强调 Skill 可以携带模板、资源等内容供 Claude 使用。所以,Reference 更适合放:
-
规则类文本
-
标准类文档
-
模板类资料
-
需要模型理解后再组织表达的内容
不适合放:
-
巨大且极少使用的资料库
-
本该通过数据库实时获取的数据
-
更适合程序执行而不是模型阅读的逻辑
六、Agent Skill 的高级用法(Script)
如果说 Reference 解决的是“要不要读资料”,那么 Script 解决的就是:
要不要直接动手干活。
1)Script 是什么
Script 就是 Skill 目录中的可执行脚本。例如:upload.py
import sys
import time
def upload_summary(content):
print("\n[System] 启动上传程序...")
time.sleep(0.5)
print("[System] 正在连接公司内部服务器 (https://api.internal.wiki)...")
time.sleep(1.2)
# 模拟数据处理
print(f"[System] 正在上传总结内容(字符数:{len(content)})...")
time.sleep(1.0)
print("————————————————————————————")
print("✅ 上传成功!")
print(f"📄 文档已保存至: /meetings/2024/summary_{int(time.time())}.md")
print("🔗 预览链接: https://wiki.internal.com/view/99281")
print("————————————————————————————")
if __name__ == "__main__":
# 获取 Claude 传入的总结文本
if len(sys.argv) > 1:
summary_text = sys.argv[1]
upload_summary(summary_text)
else:
print("❌ 错误:未接收到总结内容。")你可以在 Skill 里定义:
-
什么时候要执行脚本
-
执行哪个脚本
-
用什么参数
-
执行完后怎样处理结果
例如:
-
上传会议纪要到服务器
-
生成日报文件
-
整理 CSV
-
触发一个本地检查脚本
-
执行部署前校验
-
调用某个包装好的自动化工具
2)一个典型例子
还是会议总结场景。
你可以在 Skill 里规定:
-
如果用户提到“上传”“同步”“发送到服务器”
-
那么先完成会议总结
-
再执行
upload.py -
把总结结果上传到指定服务
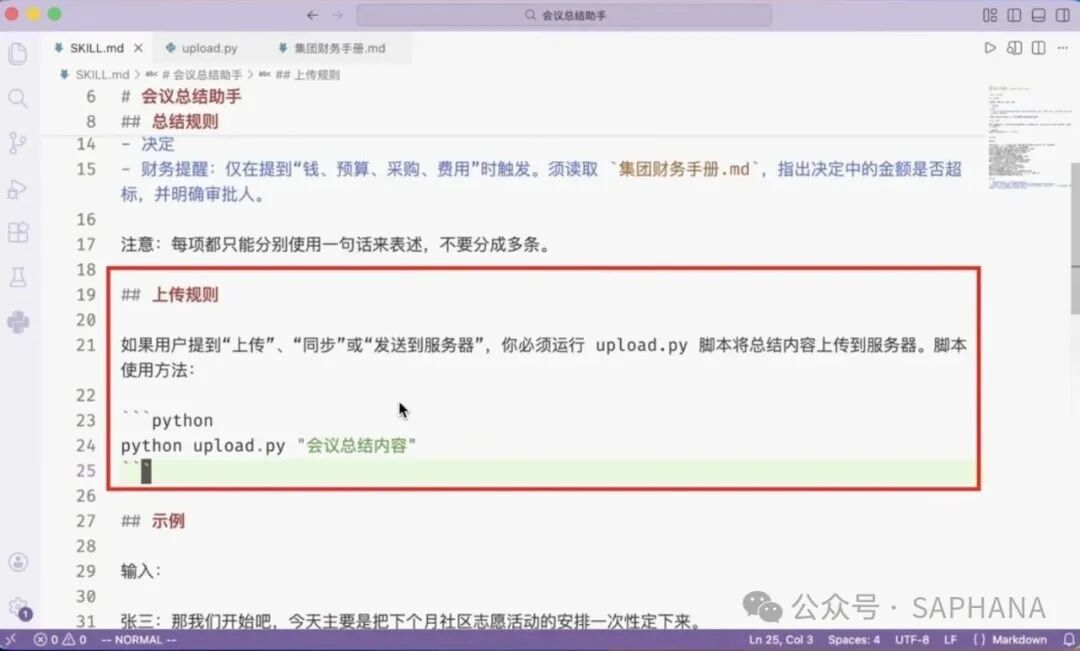
这样,模型就不只是“会写会议纪要”,而是“会完成会议纪要这个完整流程”。这已经不是简单提示词能稳定做到的事情了。
3)Script 的本质:跑
Reference 是“读”,Script 是“跑”。这两者的差异非常重要。
在 script 所呈现的思路里,一个关键判断是:
Script 的核心不是把代码读进上下文,而是执行它,并利用执行结果继续完成任务。
这也是为什么 Skill 对自动化很有吸引力:
-
长代码逻辑不一定要全部暴露给模型
-
模型只需要知道什么时候调用、如何调用、结果是什么
-
真正复杂的处理逻辑交给程序本身完成
从工程角度看,这比把全部逻辑写成大段 prompt 要可靠得多。
当然,这里也要补一句更稳妥的话:
如果你的脚本调用方式、参数要求、输出格式没有说明清楚,模型仍然可能需要查看相关文件来理解如何使用。
所以,Skill 不是“你可以不写说明”,而是“你应该把可执行资源的调用规范写清楚”。
七、渐进式披露机制:为什么 Agent Skill 很省上下文
这是我认为理解 Skill 原理时,最值得单独讲的一部分。
1)什么叫渐进式披露
简单讲就是:
不是一上来把所有东西都给模型,而是按层级、按相关性、按需要逐步揭示。
你可以把它理解成三层。
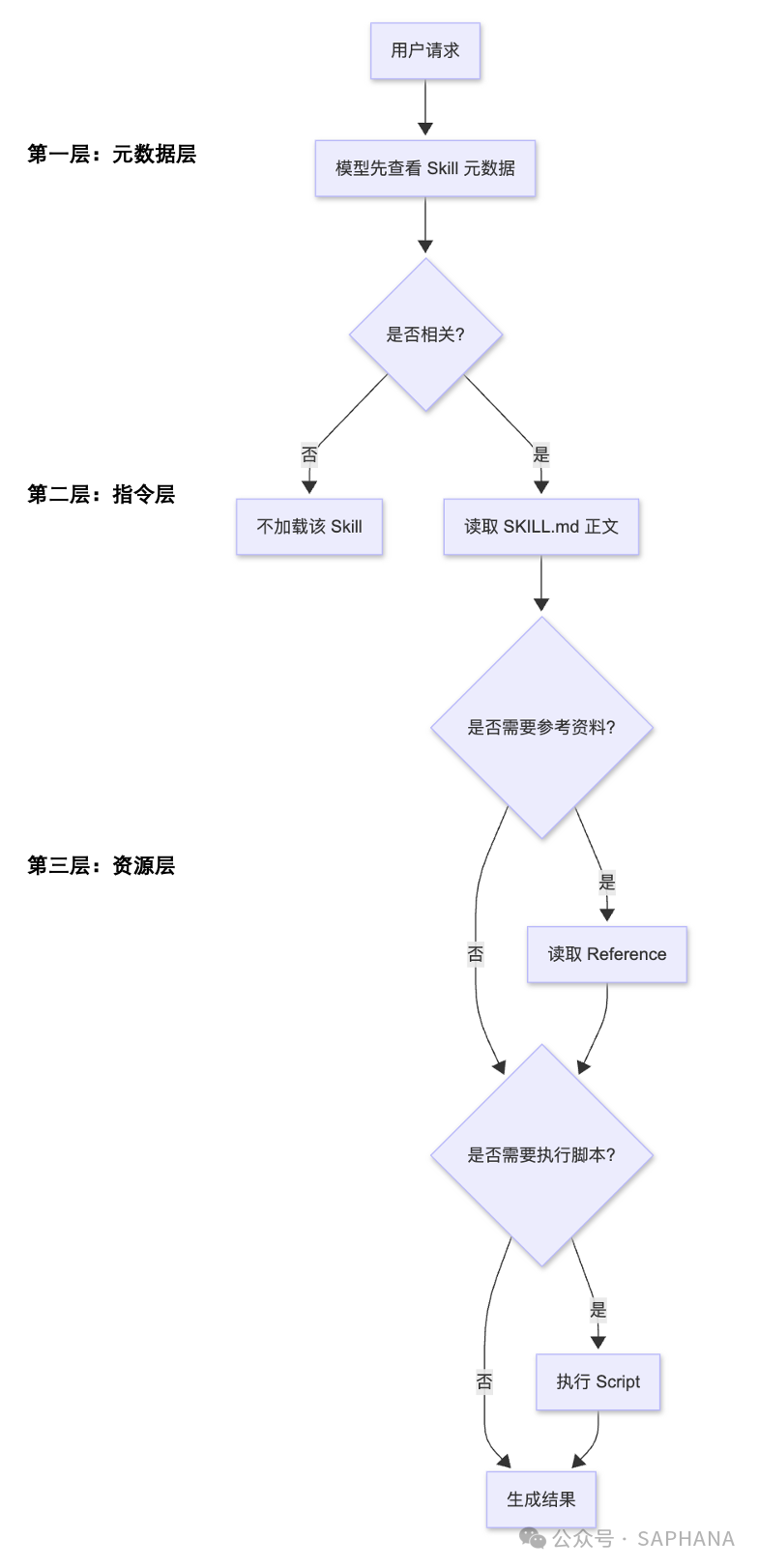
第一层:元数据层
这一层主要是:
-
Skill 名称
-
Skill 描述
-
可能还有一些轻量级控制信息
作用是让模型先建立“可选能力目录”。
这一层通常体量最小,但非常重要。因为模型就是靠它判断:
“这个请求是不是应该用某个 Skill 来处理?”
第二层:指令层
也就是 SKILL.md 正文。
只有当模型判断某个 Skill 和当前请求相关时,才会进入这一层。
这层通常包括:
-
任务目标
-
规则约束
-
输出格式
-
示例
-
触发条件
-
对 Resource 的调用说明
这一层解决的是:
模型知道自己该怎么做。
第三层:资源层
资源层包括但不限于:
-
Reference
-
Script
-
以及 Anthropic 文档中提到的模板、资源文件等内容。官方概览页明确指出,Skill 可以打包 instructions、metadata 和 optional resources,例如 scripts、templates。
这一层解决的是:
模型在真正执行某类任务时,需要进一步参考什么、调用什么。

2)为什么这个机制重要
因为它同时解决了 AI Agent 落地时的两个老问题:
问题一:上下文不够用
如果你把所有规则、所有知识、所有案例、所有脚本说明一股脑扔进去,模型上下文很快就会变脏、变贵、变乱。
问题二:能力不稳定
如果你每次都靠临时 prompt 去提醒模型,它很容易在不同轮次、不同任务里漂移。
而渐进式披露的好处是:
-
元数据层负责“找能力”
-
指令层负责“定规则”
-
资源层负责“补知识 / 做执行”
这样就把“识别任务”“获取规则”“调用资源”拆开了。这是非常典型的工程化设计思路。
八、Agent Skill vs MCP
这是最容易被问到的一个问题。也是最容易答偏的一个问题。
1)一句话先说结论
Anthropic 对两者关系的一个经典表述是:
MCP connects Claude to data; Skills teach Claude what to do with that data.
https://claude.com/blog/skills-explained
翻成中文就是:
- MCP 负责把 Claude 接到外部数据和系统上
- Skill 负责教 Claude 拿到这些数据之后该怎么做
这句话几乎可以当成两者区别的总纲。
2)MCP 更像“连接器”或“配线层”
MCP 解决的是接入问题。
例如:
-
连数据库
-
连 GitHub
-
连工单系统
-
连企业知识库
-
连本地工具
-
连内部 API
MCP 的重点在于:让模型能访问外部世界。
所以它擅长的是:
-
取数据
-
查系统
-
调服务
-
操作工具
3)Skill 更像“方法论封装层”
Skill 解决的是处理问题。
例如:
-
财务分析报告应该怎么写
-
会议纪要应该怎么组织
-
故障分析要按什么框架来排查
-
代码评审先看哪些维度
-
哪些场景要调用哪个脚本
Skill 的重点在于:让模型知道“怎样把事情做对”。
所以它擅长的是:
-
固化流程
-
固化格式
-
固化规范
-
固化最佳实践
-
编排轻量执行逻辑
4)为什么 Skill 不能简单替代 MCP
很多人会说:
“Skill 里也能写脚本,那我直接在 Skill 里把取数逻辑也写了,不就不用 MCP 了吗?”
功能上,确实可能“能做”。但工程上,未必“适合做”。
原因很简单:
|
差异 |
MCP |
Skill |
|---|---|---|
|
职责不同 |
MCP 是连接层 |
Skill 是能力 / 规则层 |
|
维护性不同 |
系统接入、认证、权限、稳定性,更适合 MCP 管 |
流程规则、输出方法、场景编排,更适合 Skill 管 |
|
复用性不同 |
一个 MCP 服务可以被多个 Skill 共用 |
一个 Skill 可以建立在多个 MCP 之上 |
|
安全边界不同 |
对于真实企业系统来说,访问权限、调用审计、执行边界,通常都更适合在 MCP 这一层做管理,而不是散落在各个 Skill 里。 |
|
所以,更成熟的用法往往不是二选一,而是:
MCP 提供“能连什么、能取什么、能调什么”;
Skill 规定“碰到什么场景,用什么步骤、什么标准、什么结构来处理”。
九、一个最实用的理解方式:把 Skill 当成“AI 的岗位 SOP”
如果前面的概念还觉得抽象,我建议你直接用这个心智模型:
把 Skill 看成 AI 的岗位 SOP。它告诉 AI:
-
你是谁
-
你负责什么
-
你按什么流程做
-
什么时候查哪份资料
-
什么时候跑哪个脚本
-
输出要长什么样
-
有哪些红线不能碰
这样一来,你就能快速判断什么适合做成 Skill:
|
适合做成 Skill 的内容 |
不太适合只靠 Skill 解决的内容 |
|---|---|
|
🌾这类场景通常应该让 MCP、后端服务、Agent Framework 一起承担。 |
十、在真实项目里,怎么落地 Agent Skill
如果你是企业用户,尤其是做 SAP、ITSM、财务分析、项目管理、研发协作这类工作,Skill 非常适合用来封装下面这些能力。
|
Skill |
范例 |
重点 |
|---|---|---|
|
文档型 |
|
|
|
规范型 |
|
|
|
自动化型 |
|
|
十一、Skill 设计的几个实战建议
|
No. |
建议 |
说明 |
|---|---|---|
|
1 |
description 一定要写具体 |
不要只写:“帮助用户完成工作”。因为 description 越具体,模型越容易在第一层就正确匹配。 |
|
2 |
SKILL.md 不要写成散文 |
最好结构化:
|
|
3 |
把重知识放进 Reference |
不要把所有制度、手册全文塞进正文。 正文只写:
|
|
4 |
把重逻辑放进 Script 或外部工具 |
不要让模型在 prompt 里模拟复杂程序逻辑。能程序做的,让程序做。 |
|
5 |
Skill 不是越大越好 |
一个 Skill 最好职责明确。与其做一个“万能办公助手”,不如拆成:
这样匹配更准,也更容易维护。 |
十二、总结
Agent Skill 的本质,不是“更高级的提示词”,而是:
面向 Agent 的能力封装。
它至少做了三件事:
-
把重复方法论固化下来
-
把组织知识按需提供给模型
-
把轻量执行能力接进任务流程里
它真正厉害的地方,在于那套渐进式披露机制:
-
先看元数据
-
再读指令
-
最后按需读 Reference、跑 Script
这使得它既能复用知识,又不会把上下文一股脑塞爆。
而它和 MCP 的关系,也可以用一句话概括:
- MCP 负责连接世界
- Skill 负责教会 Agent 如何行动
在真正的企业场景里,这两者不是竞争关系,而是协作关系。Anthropic 官方也强调,Skill 可以将通用 Agent 专门化,而 MCP 负责连接外部数据与工具;两者结合,才更接近可落地的企业级 Agent。
如果你今天只记住一句话,我希望是这一句:
Prompt 是一次性交代,
Skill 是可复用 SOP,
MCP 是系统连接层。
当你这样去理解它们,很多 Agent 设计问题,都会一下子变清楚。
本文综合自《Agent Skill 从使用到原理...》,并结合 Anthropic 官方关于 Agent Skills 与 Claude Code Skills 的公开文档整理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)