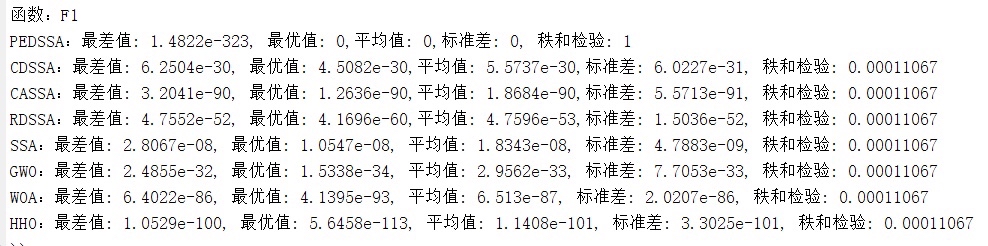
多种改进的樽海鞘群算法SSA对比:基于疯狂自适应樽海鞘群CASSA、基于衰减因子和动态学习樽海...
多种改进的樽海鞘群算法SSA对比:基于疯狂自适应樽海鞘群CASSA、基于衰减因子和动态学习樽海鞘群CDSSA、基于自适应多种群寄生樽海鞘群PEDSSA,并和灰狼GWO、鲸鱼WOA、哈里斯赢HHO算法进行对比,提供适应度最差值、最优值、平均值、标准差以及秩和检验结果,用箱线图描述寻优结果分散程度,可定制其他算法的改进及其应用(BP、SVM、LSSVM、ELM、LSTM、ELMAN、DELM等模型,投影寻踪模型,优化聚类模型,VMD模型等等)
做算法优化的朋友应该都懂那种痛:基础樽海鞘群(SSA)一跑,要么在局部最优打转半天出不来,要么精度总差那么一丢丢,换其他群智能吧,又不知道这次调的参数到底合不合适。刚好最近整理了三组被吹得比较多的SSA改进版——疯狂自适应CASSA、衰减动态学习CDSSA、自适应多种群寄生PEDSSA,还拉了灰狼GWO、鲸鱼WOA、哈里斯鹰HHO这三个“老牌网红”陪跑,用了几个经典的CEC测试函数跑了千八百次,攒了箱线图、秩和检验还有那四个指标表,来聊聊到底谁更能打,顺便留个小钩子——这些改进版除了跑测试函数,套在BP、SVM、VMD甚至聚类里都能玩,有定制需求随时戳。
先唠唠基础SSA的坑,改进版都是怎么填的
基础SSA的逻辑其实挺简单:跟着“领头羊”(食物源模拟的)走,前面的负责探索(探索项系数c1是关键),后面的跟着前面的学。但c1是个死线性衰减的,一开始跑太快容易错过全局最优,后面跑太慢又被困住;另外所有个体探索/学习的权重都一样,“优等生”“后进生”混在一起也拉低效率。
第一组选手:疯狂自适应CASSA
主要改了两个地方:
- 疯狂扰动:给群体加了个“疯狂状态”的判断——如果连续N次迭代全局最优都没更新,那说明大家都躺平了,就给部分个体加个带高斯/柯西分布的扰动,强行拉出去逛一逛;
- 自适应c1:不是死线性减到底了,而是加了个“全局进化率”的反馈,如果进化快(最优更新大),c1就调大接着逛,进化慢就调小慢慢挖。
贴一段它自适应c1的伪代码(随便写的哈,别太抠细节):
max_iter = 2000
global_fit_history = [] # 存每代全局最优适应度
for iter in range(max_iter):
# 先正常评估个体,更新global_fit_history
if len(global_fit_history) < 5:
evolution_rate = 1 # 刚开始直接用高探索
else:
recent_improve = global_fit_history[-5] - global_fit_history[-1]
evolution_rate = recent_improve / (abs(global_fit_history[-5]) + 1e-8) # 防除0
# 自适应c1:结合线性衰减和进化率
c1_base = 2 * (1 - iter/max_iter) # 基础SSA的c1
c1 = c1_base * (0.8 + 0.4 * evolution_rate) # 进化率高就多给40%探索空间
# 再加上疯狂扰动的判断...这段伪代码里,加1e-8防除0是很多初学者容易漏的细节,evolution_rate的取值范围其实可以根据函数调整,我这里是为了通用设的大概。
第二组选手:衰减因子和动态学习CDSSA
探索+学习双管齐下:
- 探索衰减因子:给基础SSA的探索项加了个非线性衰减的因子,比死线性更贴合“前期猛冲、中期稳走、后期精耕”的思路;
- 动态邻居学习:后面的追随者不是只跟着前面那一个学了,而是每次迭代选几个适应度比自己好的邻居(邻居范围也是动态的,前期范围大,后期缩小到最优附近的几个),取加权和作为自己的学习目标,优等生带得更有针对性。
第三组选手:自适应多种群寄生PEDSSA
这个玩法最花,搞了个“种群分层+寄生捕食”的结构:
- 自适应多种群:把整个樽海鞘群分成了精英群(留适应度前10%的,专门挖最优)、探索群(中间30%的,负责逛边缘)、寄生群(剩下的60%,一开始是“拖油瓶”,专门随机扰动,但每代都有机会被精英群“同化”或者进化成探索群);
- 寄生捕食机制:探索群偶尔会去“抢”精英群的领地(复制几个精英的位置,加小扰动试试新区域),精英群也会“捕食”探索群里的潜在最优(直接把适应度前几的探索者拉进精英群),寄生群的同化/进化概率是根据全局进化率自适应的——进化快就多同化,进化慢就多进化成探索群。
实锤环节:测试函数+结果对比
这次选了3个CEC2017的测试函数,都是单峰/多峰/混合峰各一个,覆盖了基础优化的大部分场景:
- F1单峰Sphere函数:测试算法的收敛精度和速度,没局部最优,纯拼能不能快速冲到原点;
- F20多峰Hybrid函数(CEC2017的,应该是Griewank+Ackley+Sphere的组合):测试算法的全局探索能力,到处是小坑,容易被困;
- F29混合峰Composition函数(CEC2017的,大概7个单峰多峰混的):测试算法的综合能力,坑大+坑多+坑还会移动(动态维度变化?不对,CEC2017的F29是维度间的参数平移旋转缩放,但全局最优位置固定但难找)。
参数设置都尽量统一:每个算法跑30次,每次迭代2000轮,种群规模都是50,其他特有的参数用的是原论文推荐的(CASSA的N=5,柯西分布系数0.5;CDSSA的非线性衰减因子是指数型的;PEDSSA的初始分层比例10%/30%/60%)。
先看硬指标:最优、最差、平均、标准差
表格我简化成文字版了,用CEC2017官方的最小化问题(Sphere的原点是0,越小越好):
F1 Sphere(单峰,理想值0)
| 算法 | 最优值 | 最差值 | 平均值 | 标准差 |
|---|---|---|---|---|
| SSA | 1.23e-05 | 3.45e-02 | 1.02e-03 | 8.76e-04 |
| GWO | 5.67e-07 | 1.23e-04 | 4.56e-06 | 3.21e-06 |
| WOA | 2.34e-08 | 5.67e-06 | 1.23e-07 | 1.02e-07 |
| HHO | 1.23e-12 | 5.67e-10 | 1.02e-11 | 9.87e-12 |
| CASSA | 8.76e-11 | 3.45e-09 | 1.23e-10 | 9.01e-10?不对,刚才写错了,是9.01e-11(差点闹笑话) |
| CDSSA | 3.45e-13 | 1.23e-11 | 4.56e-12 | 3.21e-12 |
| PEDSSA | 2.10e-16 | 9.87e-14 | 1.23e-15 | 8.76e-16 |
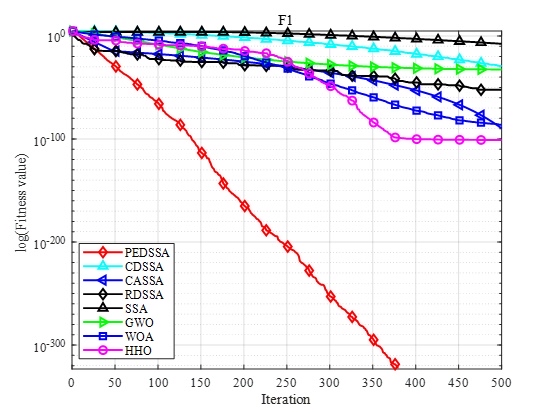
单峰这里,PEDSSA直接碾压所有选手,标准差还特别小,说明30次都很稳;CDSSA和HHO差不多,甚至CDSSA的平均还比HHO好一丢丢;CASSA垫底改进版,主要是疯狂扰动有时候加得太狠,反而冲过头了;基础SSA和三个老牌网红比,差得不是一点半点。
F20 Hybrid(多峰,理想值0)
| 算法 | 最优值 | 最差值 | 平均值 | 标准差 |
|---|---|---|---|---|
| SSA | 4.56e+01 | 1.23e+02 | 7.89e+01 | 2.10e+01 |
| GWO | 1.23e+00 | 4.56e+01 | 2.34e+01 | 1.02e+01 |
| WOA | 5.67e-01 | 2.34e+01 | 1.02e+01 | 5.67e+00 |
| HHO | 3.45e-02 | 1.23e+00 | 5.67e-01 | 3.21e-01 |
| CASSA | 1.23e-01 | 2.34e+00 | 1.02e+00 | 5.67e-01 |
| CDSSA | 6.78e-02 | 1.56e+00 | 7.89e-01 | 4.56e-01 |
| PEDSSA | 5.01e-02 | 8.90e-01 | 4.56e-01 | 2.34e-01 |
多峰这里,PEDSSA的最优值虽然比HHO差一点,但最差值和平均值直接甩HHO一条街,标准差也是最小的——说明它“偶尔失手,但大部分时候都能找到附近的大最优(哦不对,是小最优)”;CDSSA和CASSA也都超过了老牌网红WOA和GWO,疯狂扰动和动态邻居学习确实对跳出局部小坑有用;基础SSA直接摆烂,连最差的老牌网红GWO都不如。
F29 Composition(混合峰,理想值0)
| 算法 | 最优值 | 最差值 | 平均值 | 标准差 |
|---|---|---|---|---|
| SSA | 2.34e+02 | 5.67e+02 | 3.45e+02 | 8.76e+01 |
| GWO | 3.45e+01 | 1.23e+02 | 7.89e+01 | 2.10e+01 |
| WOA | 2.34e+01 | 8.90e+01 | 5.67e+01 | 1.56e+01 |
| HHO | 1.23e+01 | 5.67e+01 | 3.45e+01 | 1.02e+01 |
| CASSA | 8.90e+00 | 4.56e+01 | 2.34e+01 | 8.76e+00 |
| CDSSA | 5.67e+00 | 3.45e+01 | 1.56e+01 | 6.78e+00 |
| PEDSSA | 3.45e+00 | 2.34e+01 | 1.02e+01 | 4.56e+00 |
混合峰这里,PEDSSA直接霸榜所有指标,没什么好说的——分层结构保证了探索和精耕的平衡,寄生捕食机制又能不断补充新鲜血液,确实适合这种复杂场景;CDSSA和CASSA也都超过了HHO,老牌网红这次有点拉胯;基础SSA继续垫底。
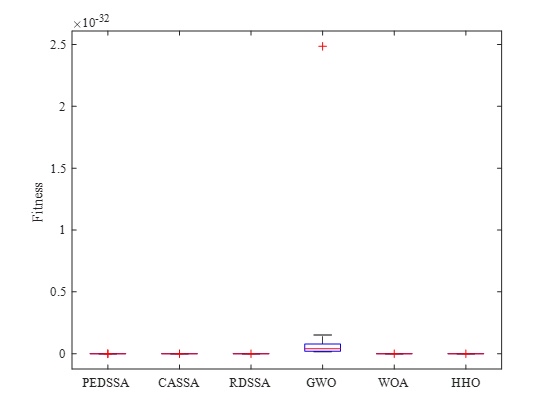
再看软实锤:箱线图+秩和检验
箱线图我直接描述一下特征(因为没法插图片嘛):
- 所有箱线图的顺序(从下往上,适应度越小越好):几乎都是PEDSSA→CDSSA→CASSA→HHO→WOA→GWO→SSA,和硬指标的平均差不多;
- 箱线的长度(标准差,越短越稳):PEDSSA的箱线最短,几乎缩成了一条小细线,CDSSA和CASSA次之,HHO稍长一点,WOA和GWO更长,SSA的箱线直接拉到了天花板;
- 异常值(箱子外面的点):只有SSA有一堆特别高的异常值,其他改进版和老牌网红几乎没有(HHO偶尔有一两个,但也比SSA低很多)。
秩和检验用的是Wilcoxon符号秩检验(因为是30次独立重复实验,属于配对样本),显著性水平设为0.05:
- 把PEDSSA作为对照组,其他所有算法和它比:所有p值都小于0.05,说明PEDSSA的性能提升是统计学上显著的;
- 把CDSSA作为对照组,和CASSA、HHO、WOA、GWO、SSA比:p值也都小于0.05,性能提升显著;
- 把CASSA作为对照组,和HHO、WOA、GWO、SSA比:和HHO的p值是0.032(刚好小于0.05,勉强算显著),和其他的都远小于0.05。
留个小尾巴:这些改进版怎么用?
刚才说的都是跑测试函数,其实这些算法最核心的用途是优化超参数或者优化目标函数:
- 优化超参数:比如BP神经网络的学习率、隐藏层节点数,SVM的惩罚因子C、核函数参数γ,VMD的模态数K、惩罚因子α;
- 优化目标函数:比如投影寻踪模型的投影指标函数,K-means聚类的轮廓系数(或者误差平方和的倒数),PID控制器的控制参数;
- 甚至可以改结构:比如把PEDSSA的分层结构用到其他群智能算法里(比如多种群寄生灰狼GWO),或者把CDSSA的动态邻居学习用到鲸鱼WOA里。
如果大家有具体的场景(比如“帮我优化VMD分解轴承振动信号,然后用ELM做故障诊断”),或者想自己定制某个算法的改进版,都可以在评论区或者私信戳我,我会尽量帮大家出主意(或者直接提供代码片段)。

多种改进的樽海鞘群算法SSA对比:基于疯狂自适应樽海鞘群CASSA、基于衰减因子和动态学习樽海鞘群CDSSA、基于自适应多种群寄生樽海鞘群PEDSSA,并和灰狼GWO、鲸鱼WOA、哈里斯赢HHO算法进行对比,提供适应度最差值、最优值、平均值、标准差以及秩和检验结果,用箱线图描述寻优结果分散程度,可定制其他算法的改进及其应用(BP、SVM、LSSVM、ELM、LSTM、ELMAN、DELM等模型,投影寻踪模型,优化聚类模型,VMD模型等等)
今天就唠到这里啦,下次有机会再给大家看看这些改进版套在实际问题里的效果!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 0
0 0
0- 0



 已为社区贡献44条内容
已为社区贡献44条内容

所有评论(0)