【说话人日志】Benchmarking Diarization Models 当前说话人分离模型到底谁更强?
一文读懂《Benchmarking Diarization Models》:当前说话人分离模型到底谁更强?
论文标题:Benchmarking Diarization Models
作者:Luca A. Lanzendörfer, Florian Grötschl, Cesare Blaser, Roger Wattenhofer
单位:ETH Zurich
任务:Speaker Diarization(说话人分离,回答“谁在什么时候说话”)
评测规模:4 个数据集、5 种语言、196.6 小时音频
一、先说结论:这篇论文最值得记住什么?
如果你只想先抓住最核心的信息,这篇论文可以浓缩成 4 句话:
pyannoteAI是整体最强的方案,平均DER = 11.2%。DiariZen是最有竞争力的开源方案,平均DER = 13.3%。Sortformer v2 / v2-streaming在速度和流式部署上非常有优势,其中SF v2平均RTF = 214.3x。- 当前 diarization 模型最大的共性问题,不是“把人分错了”,而是漏检语音,并且很多错误本质上是语音起止边界不准。
这篇论文的价值不在于提出一个新模型,而在于回答两个非常工程化的问题:
- 如果我有一段会议、电话、开放环境的多人音频,应该优先选哪个 diarization 模型?
- 这些模型现在到底是怎么失败的,下一步优化该往哪里投精力?
二、论文在评测什么?
作者选了 5 个当前比较有代表性的系统:
| 模型 | 类型 | 论文中的定位 | 一句话理解 |
|---|---|---|---|
pyannote 3.1 |
开源模块化 pipeline | 经典强基线 | 分段 + 嵌入 + 聚类的典型流水线 |
pyannoteAI |
商业闭源 API | 整体效果最好 | 更强的工业化版本,但细节不公开 |
Sortformer |
端到端 EEND 类方法 | 原始版本 | 对 4 人以内场景更友好,但长音频和高说话人数有局限 |
Sortformer v2 |
端到端改进版 | 速度极强 | 引入 AOSC,长音频处理与流式能力更强 |
DiariZen |
混合方法 | 最强开源选手 | EEND + WavLM + pyannote 聚类,精度和可扩展性较均衡 |
数据集覆盖也比较全面:
| 数据集 | 场景 | 语言 | 典型特点 |
|---|---|---|---|
CALLHOME |
电话通话 | 英/中/日/德/西 | 以双人对话为主 |
VoxConverse |
开放环境音频 | 英语 | 说话人数多,噪声和录音条件复杂 |
AMI |
英文会议 | 英语 | 4 人会议,重叠语音明显 |
AliMeeting |
中文会议 | 普通话 | 高重叠会议场景,对 diarization 很有挑战 |
作者统一采用 DER 作为评测指标,且 skip_overlap=False,也就是重叠语音也算进评测。这点很重要,因为真实多人对话里,重叠语音往往恰恰是最难的部分。
三、总体表现:谁是第一梯队?
论文的总体结论很明确:
pyannoteAI:整体第一,平均DER = 11.2%DiariZen:开源第一梯队,平均DER = 13.3%Sortformer v2-streaming:综合表现也很强,尤其适合低时延和流式场景
下面这张图是论文里最重要的一张总览图。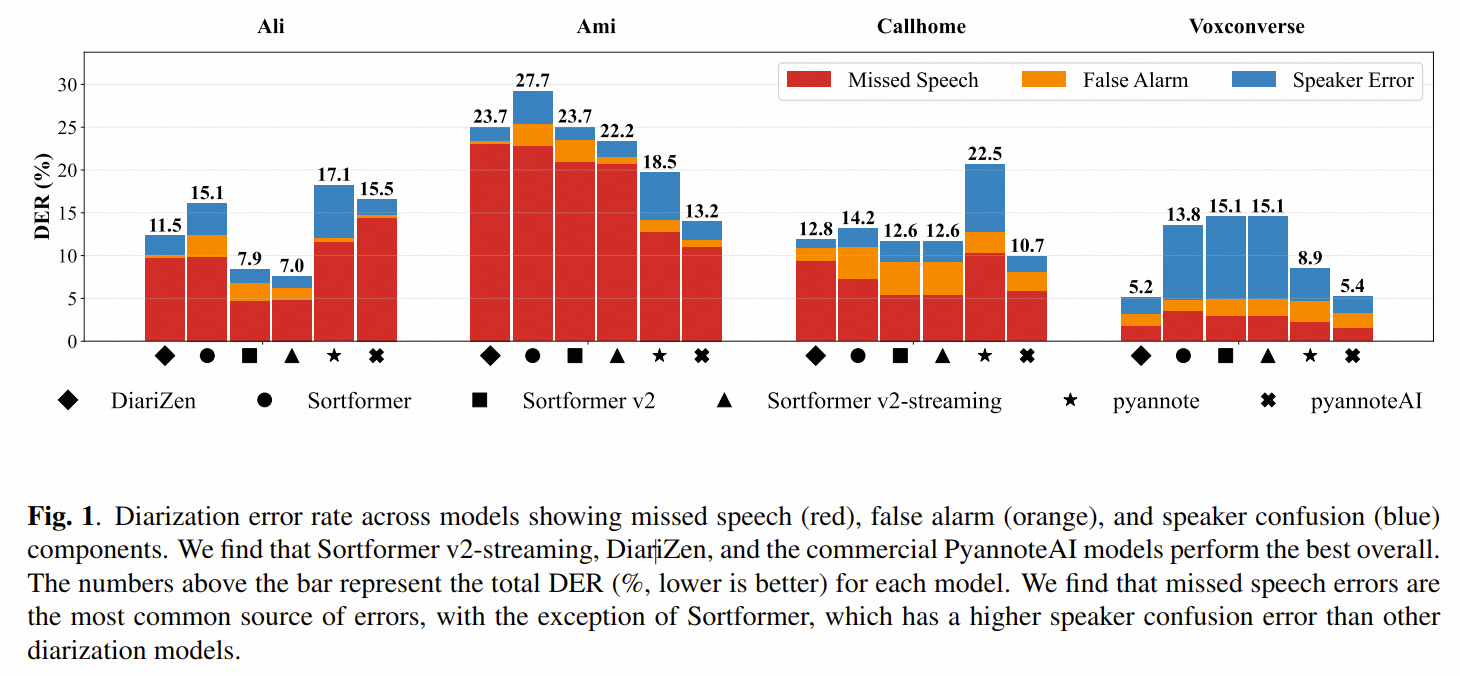
图 1 可以读出三个关键信号:
1. pyannoteAI 的综合稳定性最好
它不是只在某一个数据集上拿第一,而是整体都很稳。尤其在英语、德语、西班牙语、多说话人场景上,都表现得比较强。
2. DiariZen 是真正有竞争力的开源方案
论文中特别提到,DiariZen 在 VoxConverse 上表现突出,DER = 5.2%。
这说明它在高说话人数、开放环境、复杂录音条件下有明显竞争力。
3. Sortformer 系列的主要卖点是速度和流式,而不是绝对最优精度
尤其是 Sortformer v2-streaming,在 AliMeeting 上表现非常亮眼,DER = 7.0%,说明它很适合中文会议类、低时延场景。
四、最好几个模型怎么选?
这一部分最适合做工程选型。
| 模型 | 核心优点 | 核心缺点 | 适合场景 |
|---|---|---|---|
pyannoteAI |
综合精度最好;跨语言稳定;多说话人数扩展性最好 | 商业闭源;实现细节不公开;推理速度无法从 API 内部透明获取 | 优先追求最终效果,且可以接受 API/闭源依赖 |
DiariZen |
开源里最强;VoxConverse 和 5+ speaker 场景很强;整体比较均衡 |
速度明显慢于 Sortformer 系列;英文/德语/西语仍略弱于 pyannoteAI |
想要开源、可部署、可改造,同时精度不能太差 |
Sortformer v2-streaming |
流式能力强;中文/日文会议场景亮眼;适合低时延部署 | 高说话人数时退化仍明显;总体绝对精度不是第一 | 实时会议、边录边转写、在线 diarization |
Sortformer v2 |
全文最快,RTF = 214.3x;长音频能力比初版更好 |
高说话人数仍受限;英文/西语表现一般 | 更看重吞吐量、延迟和工程部署成本 |
如果把它们进一步压缩成一句话:
- 要最准:选
pyannoteAI - 要最强开源:选
DiariZen - 要实时/流式:选
Sortformer v2-streaming - 要极致速度:选
Sortformer v2
五、按语言看:不同模型真不是“一个模型打天下”
论文里给出了按语言汇总的 DER。
| 语言 | 最优模型 | 最优 DER | 观察 |
|---|---|---|---|
| 中文普通话 | Sortformer v2 |
9.2% |
中文上 SF v2 系列表现很强 |
| 英语 | pyannoteAI |
6.6% |
英语是最成熟、训练数据也最充足的语言之一 |
| 德语 | pyannoteAI |
8.3% |
pyannoteAI 跨语言稳定性明显更好 |
| 日语 | Sortformer v2 / v2-streaming |
12.7% |
SF v2 系列在日语上优于 pyannoteAI |
| 西班牙语 | pyannoteAI |
14.3% |
西语是全文最难的语言之一 |
这里有个很有意思的结论:
- 英语和普通话整体更容易做得好
- 西班牙语整体最难
作者认为一个很重要的原因是:不同语言可获得的标注数据量不一样。
这其实也提醒我们,做 multilingual diarization 时,模型结构未必是唯一瓶颈,训练数据分布和覆盖度同样关键。
六、按说话人数看:高 speaker count 仍然是难点
论文又专门把结果按说话人数分桶统计了一遍。
| 说话人数 | 最优模型 | DER | 结论 |
|---|---|---|---|
1 spk |
Sortformer |
1.5% |
单人场景大家都不难,差距意义有限 |
2 spk |
pyannoteAI |
9.9% |
双人对话里 pyannoteAI 最稳 |
3 spk |
pyannoteAI |
9.1% |
多人开始拉开差距 |
4 spk |
pyannoteAI |
10.1% |
会议场景下 pyannoteAI 仍领先 |
5+ spk |
pyannoteAI |
6.6% |
高说话人数场景可扩展性最好 |
不过有一个点也值得单独提出来:
DiariZen在5+ spk上也很强,DER = 7.1%Sortformer系列在高说话人数上会明显退化
这和论文对模型结构的分析是一致的。Sortformer 的设计本身就更偏向 4-speaker 场景,到了 VoxConverse 这种很多说话人的开放环境数据时,就容易出现更严重的 speaker confusion。
七、速度维度:为什么说 Sortformer v2 很有工程价值?
如果只看精度,Sortformer v2 不是最强。但如果把速度也放进来,它的价值就非常高了。
| 模型 | 平均 RTF | 速度解读 |
|---|---|---|
DiariZen |
20.2x |
可用,但不算特别快 |
pyannote |
45.0x |
比 DiariZen 快不少 |
Sortformer |
164.7x |
已经非常快 |
Sortformer v2 |
214.3x |
全文最快 |
Sortformer v2-streaming |
209.5x |
速度也极高,同时支持流式思路 |
这里的 RTF 是 “音频时长 / 处理时间”,数值越大越好。214.3x 的意思大致可以理解为:它处理音频的速度远高于实时。
这也是为什么我会认为这篇论文非常适合工程读者:它不是只告诉你“谁最准”,而是告诉你谁更适合部署。
八、错误分析:当前 diarization 最大的问题到底是什么?
这是全文最值得细读的部分。
作者把 DER 拆成三类:
missed speech:漏检语音false alarm:误检非语音speaker confusion:说话人分错
图 1 已经能看出来,大多数模型的主导误差都是 missed speech。
论文接着又画了下面这张图来分析,漏检到底发生在什么样的语音段上。
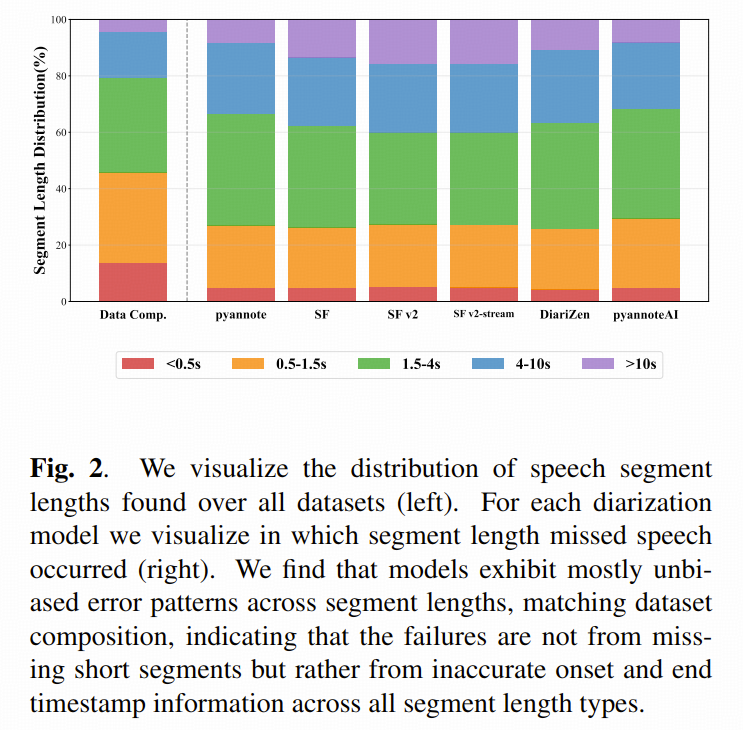
这张图传递出的信息很重要:
1. 模型不是只会漏掉很短的语音段
很多人直觉上会以为,模型漏检主要因为短语音太短、太碎、太难听清。
但论文发现,错误分布和真实数据里的语音长度分布大体一致,说明问题并不是“模型只看不见短 segment”。
2. 更像是边界不准
作者统计后发现,各模型漏检片段的平均长度大约只有 350 ms。
这意味着很多错误并不是“整句话完全没检测到”,而是:
- 开始点偏晚了
- 结束点偏早了
- 边界切得不准
换句话说,当前 diarization 的改进空间很可能更多在boundary precision,也就是语音起止时间戳的精细定位能力。
3. 会议场景尤其容易出现漏检
AMI 和 AliMeeting 这类会议场景里,重叠语音更强、说话节奏更密,missed speech 也更突出。
这对会议转写、会议纪要系统很关键,因为 diarization 一旦漏掉边界,后续 ASR 和说话人归属都会连锁出错。
九、我对这篇论文的三点理解
1. 选模型时,不能只看平均 DER
如果你的场景是:
- 双人电话
- 中文会议
- 开放环境多人访谈
- 在线流式转写
那么最优模型很可能根本不是同一个。
这篇论文的一个重要价值,就是把“平均分”拆成了:
- 场景差异
- 语言差异
- 说话人数差异
- 速度差异
这比单纯给一个 leaderboard 更有实际意义。
2. diarization 的瓶颈不只在聚类
很多工程调参会把重点放在:
- embedding 模型
- clustering threshold
- speaker number estimation
但这篇论文说明,至少在当前 SOTA 系统里,一个很大的问题来自语音边界与漏检。
也就是说,前端 segmentation 没做好,后面聚类再强也救不回来。
3. 开源系统和闭源工业系统的差距,已经不是“能不能用”,而是“在哪些场景还能更稳”
DiariZen 已经证明,开源系统并不是完全不能打。
尤其当你要私有化部署、可控可改、支持本地推理时,它其实很有现实价值。
真正的差距在于:
- 跨语言的稳定性
- 高说话人数时的泛化
- 极端场景下的鲁棒性
十、如果我是工程负责人,我会怎么选?
| 业务目标 | 推荐方案 | 原因 |
|---|---|---|
| 先把精度做到最好 | pyannoteAI |
综合 DER 最优,跨语言和多 speaker 稳定 |
| 必须开源且可私有化 | DiariZen |
开源阵营中最均衡,复杂场景能力也不错 |
| 做在线会议转写 | Sortformer v2-streaming |
速度快、流式友好、中文会议表现亮眼 |
| 大规模离线批处理 | Sortformer v2 |
极高吞吐量,算力利用率优秀 |
十一、最后总结
这篇论文不是在争论“哪个模型 SOTA”这么简单,它真正告诉我们的是:
- 没有一个模型在所有维度都绝对占优
- 工程选型必须看场景,而不是只看平均分
- 当前 diarization 的核心痛点是漏检和边界不准
- 高说话人数与多语言泛化仍然是最值得继续攻克的问题
如果你正在做:
- 会议转写
- 说话人归属
- 多人语音分析
- 语音大模型前处理
那么这篇 benchmark 值得认真读一遍,因为它提供的不是“理论最好”,而是更接近真实部署的判断依据。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)