【端侧部署yolo系列】yolo26部署至全志开发板T736
环境配置
关于参考之前部署yolox的文章【端侧部署yolo系列】yolox部署至全志开发板T736![]() https://blog.csdn.net/troyteng/article/details/155444386?spm=1011.2124.3001.6209
https://blog.csdn.net/troyteng/article/details/155444386?spm=1011.2124.3001.6209
下载镜像文件和AWNPU_Model_Zoo,创建自己的容器,进入容器完成后续的操作。
模型准备
下载 yolov26s.pt模型文件,导出onnx格式,代码如下:
from ultralytics import YOLO
model = YOLO('yolo26s.pt')
results = model.export(format='onnx', simplify=True, dynamic=False, opset=16)模型配置
# 进入模型转化的工作目录
cd /workspace/awnpu_model_zoo/examples/yolo26/convert_model
# 检查或修改config_yml.py文件的相关参数配置
vim config_yml.py将配置文件修改为如下图所示:
# "database"
DATASET = '../../dataset/coco_12/dataset.txt'
DATASET_TYPE = "TEXT"
# mean, scale
MEAN = [0, 0, 0]
SCALE = [0.0039216, 0.0039216, 0.0039216]
# reverse_channel: True bgr, False rgb
REVERSE_CHANNEL = False
# add_preproc_node, True or False
ADD_PREPROC_NODE = True
# "preproc_type"
PREPROC_TYPE = "IMAGE_RGB"
# add_postproc_node, quant output -> float32 output
ADD_POSTPROC_NODE = TrueDATASE:用于量化校准的数据集
DATASE_TYPE:数据集类型,一般是TEXT和NPY。
MEAN和SCALE根据不同模型的归一化来进行修改。
归一化计算公式为normalized = (img / 255.0 - mean) / std
SCALE =(1/std)*255
REVERSE_CHANNEL:是否通道转换。(根据前处理代码知道输入的图像格式是RGB,yolo26模型需要的格式是RGB,因此不需要进行通道转换)
ADD_PREPROC_NODE:是否打开前处理节点。False则表示对于转换后的nb模型,不使用通道转化和归一化操作
ADD_POSTPROC_NODE:是否打开后处理节点。True表示打开量化和反量化操作,最终输出的是float
模型简化
yolo26网络的后处理部分(输出head节点往后的layer)8bit量化会产生较大的精度损失, 裁剪掉网络后处理节点,使得后处理部分在cpu上运行。
cd ./convert_model/python/
python3 onnx_extract.py模型输出差异如下,左边是官方模型,右边是修改后的模型
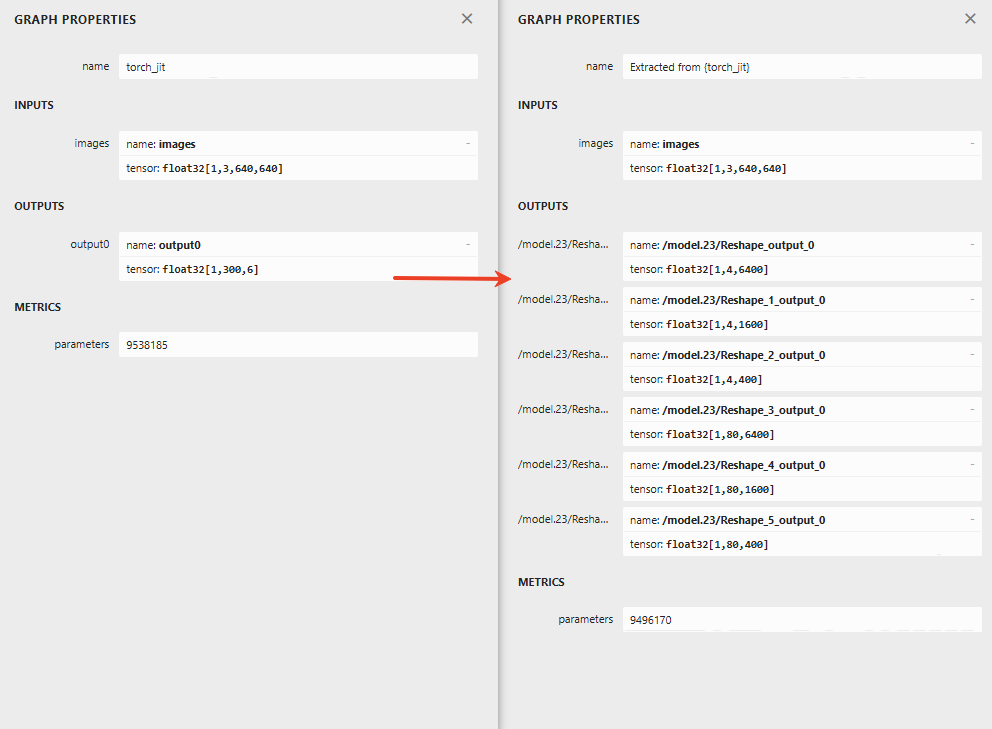
onnx_extract.py内容如下:代码中第一个参数是原始的模型,第二个参数是简化后模型,第三个参数是模型的输入名,第四个参数是模型的输出名,如果有多个输入输出,用逗号隔开。模型的输入输出名正好对应的是模型简化后的INPUTS和OUTPUTS中的name。
import onnx
onnx.utils.extract_model('./yolo26s.onnx', '../yolo26s_6.onnx', ['images'], ['/model.23/Reshape_output_0', '/model.23/Reshape_1_output_0', '/model.23/Reshape_2_output_0', '/model.23/Reshape_3_output_0', '/model.23/Reshape_4_output_0', '/model.23/Reshape_5_output_0']) 模型前后处理
这里最新版的AWNPU_Model_Zoo包里面已经有代码了,这里就不贴代码了。这里的代码是运行没有经过裁剪的后处理代码,也就是yolo26s.pt直接导出的onnx模型
未裁剪模型的后处理yolo26_postprocess.cpp
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/dnn.hpp>
#include <iostream>
#include <stdio.h>
#include <vector>
#include <cmath>
#include <random>
#include "model_config.h"
using namespace std;
struct Object
{
cv::Rect_<float> rect;
int label;
float prob;
};
int detect_yolo26_post(const cv::Mat& bgr, std::vector<Object>& objects, float **output)
{
std::chrono::steady_clock::time_point Tbegin, Tend;
Tbegin = std::chrono::steady_clock::now();
int img_w = bgr.cols;
int img_h = bgr.rows;
// set default letterbox size
int letterbox_rows = LETTERBOX_ROWS;
int letterbox_cols = LETTERBOX_COLS;
const float prob_threshold = SCORE_THRESHOLD;
const float* detections = output[0];
const int num_detections = 300;
float scale = std::min(static_cast<float>(letterbox_rows) / img_h,
static_cast<float>(letterbox_cols) / img_w);
int new_w = static_cast<int>(img_w * scale);
int new_h = static_cast<int>(img_h * scale);
int pad_w = (letterbox_cols - new_w) / 2;
int pad_h = (letterbox_rows - new_h) / 2;
fprintf(stderr, "Debug: scale=%.4f, new_w=%d, new_h=%d, pad_w=%d, pad_h=%d\n",
scale, new_w, new_h, pad_w, pad_h);
std::vector<Object> proposals;
int valid_detections = 0;
int low_score_count = 0;
int invalid_coords_count = 0;
for (int i = 0; i < num_detections; i++) {
const float* det = detections + i * 6;
float x1 = det[0];
float y1 = det[1];
float x2 = det[2];
float y2 = det[3];
float score = det[4];
int class_id = static_cast<int>(det[5]);
bool valid_coords = (x1 < x2) && (y1 < y2);
if (score < prob_threshold) {
low_score_count++;
continue;
}
if (!valid_coords) {
invalid_coords_count++;
continue;
}
float orig_x1 = x1;
float orig_y1 = y1;
float orig_x2 = x2;
float orig_y2 = y2;
x1 = (x1 - pad_w) / scale;
y1 = (y1 - pad_h) / scale;
x2 = (x2 - pad_w) / scale;
y2 = (y2 - pad_h) / scale;
x1 = std::max(0.0f, x1);
y1 = std::max(0.0f, y1);
x2 = std::min(static_cast<float>(img_w), x2);
y2 = std::min(static_cast<float>(img_h), y2);
if (x1 >= x2 || y1 >= y2) {
invalid_coords_count++;
continue;
}
Object obj;
obj.rect.x = x1;
obj.rect.y = y1;
obj.rect.width = x2 - x1;
obj.rect.height = y2 - y1;
obj.label = class_id;
obj.prob = score;
proposals.push_back(obj);
valid_detections++;
}
objects = std::move(proposals);
Tend = std::chrono::steady_clock::now();
float f = std::chrono::duration_cast <std::chrono::milliseconds> (Tend - Tbegin).count();
// std::cout << "post process time : " << f << " ms" << std::endl;
fprintf(stderr, "detection num: %d\n", static_cast<int>(objects.size()));
return 0;
}
static void draw_objects(const cv::Mat& bgr, const std::vector<Object>& objects, const char *imagepath)
{
cv::Mat image = bgr.clone();
for (size_t i = 0; i < objects.size(); i++)
{
const Object& obj = objects[i];
if (obj.prob > 1.0) {
fprintf(stderr, "%2d: %3.0f%%, [%4.0f, %4.0f, %4.0f, %4.0f], score is illegal ........ \n", obj.label, obj.prob * 100, obj.rect.x,
obj.rect.y, obj.rect.x + obj.rect.width, obj.rect.y + obj.rect.height);
continue;
}
fprintf(stderr, "%2d: %3.0f%%, [%4.0f, %4.0f, %4.0f, %4.0f], %s\n", obj.label, obj.prob * 100, obj.rect.x,
obj.rect.y, obj.rect.x + obj.rect.width, obj.rect.y + obj.rect.height, g_classes_name[obj.label].c_str());
cv::rectangle(image, obj.rect, cv::Scalar(255, 0, 0));
char text[256];
sprintf(text, "%s %.1f%%", g_classes_name[obj.label].c_str(), obj.prob * 100);
int baseLine = 0;
cv::Size label_size = cv::getTextSize(text, cv::FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
int x = obj.rect.x;
int y = obj.rect.y - label_size.height - baseLine;
if (y < 0)
y = 0;
if (x + label_size.width > image.cols)
x = image.cols - label_size.width;
cv::rectangle(image, cv::Rect(cv::Point(x, y), cv::Size(label_size.width, label_size.height + baseLine)),
cv::Scalar(255, 255, 255), -1);
cv::putText(image, text, cv::Point(x, y + label_size.height),
cv::FONT_HERSHEY_SIMPLEX, 0.5, cv::Scalar(0, 0, 0));
}
cv::imwrite("out_yolo26.png", image);
}
int yolo26_postprocess(const char *imagepath, float **output)
{
cv::Mat m = cv::imread(imagepath, 1);
if (m.empty()) {
fprintf(stderr, "cv::imread %s failed\n", imagepath);
return -1;
}
std::vector<Object> objects;
detect_yolo26_post(m, objects, output);
draw_objects(m, objects, imagepath);
return 0;
}1.模型导入
重点说明:由于模型是没有进行简化的,采用uint8和pcq量化精度会丢失,因此只能采用int16量化策略。如果要使用uint8或者pcq量化策略(对于yolo26,经测试pcq量化效果比uint8效果要好),则需要简化模型。
# 导入
# pegasus_import.sh <model_name>
./pegasus_import.sh yolo26s2.模型量化
# 量化
# pegasus_quantize.sh <model_name> <quantize_type> <calibration_set_size>
./pegasus_quantize.sh yolo26s int16 123. 仿真(可选)
# 仿真(可选)
# pegasus_inference.sh <model_name> <quantize_type>
./pegasus_inference.sh yolo26s int164.模型导出
# pegasus_export_ovx_nbg.sh <model_name> <quantize_type> <platform>
./pegasus_export_ovx_nbg.sh yolo26s int16 t736
# 导出的模型文件存放在../model目录
# 例如 ../model/yolo26s_int16_t736.nb交叉编译
由于一般都是在服务器上编译,再把模型发送至板端进行推理,所以需要用到交叉编译。如果直接在板端编译,直接进行推理即可。解压文件需要退出docker(Ctrl + d)
1.解压opencv压缩包
# 进入目录
cd ../../../3rdparty/opencv/
# 解压,选择对应平台,这里选择linux aarch64
# armhf, eg: V85x, R853
unzip opencv-3.4.16-gnueabihf-linux.zip
# linux aarch64, eg: T527/MR527/MR536/T536/A733/T736
unzip opencv-4.9.0-aarch64-linux-sunxi-glibc.zip
# android aarch64, eg: T527/A733/T736
unzip opencv-4.9.0-android.zip2.准备交叉编译工具链
# 进入目录
cd ../../0-toolchains/
# 解压
# aarch64, MR527, T527, MR536
tar xvf gcc-arm-10.3-2021.07-x86_64-aarch64-none-linux-gnu.tar.xz3.开始编译
# 进入examples目录
cd ../examples
chmod +x build_linux.sh
# ./build_linux.sh -t <platform> -p <model>
./build_linux.sh -t t736 -p yolo26
# 编译完成之后会在yolo26文件夹内生成一个install目录
tree yolo26/install/-- yolo26_demo_linux_t736
|-- model
| |-- dog.jpg
| `-- yolo26s_int16_t736.nb
`-- yolo26_demo_t736
模型推理
将上述生成的文件推送至开发板,方式不限于adb这一种
# 这里是采用ADB的方式发送至板端。
adb push Z:\projects\docker_data\awnpu_model_zoo\examples\yolo26\install /mnt/UDISK/
# 在板端进入yolo26_demo_linux_t736目录
cd /mnt/UDISK/install/yolo26_demo_linux_t736/
# 推理
./yolo26_demo_t736 -nb model/yolo26s_int16_t736.nb -i model/dog.jpg
# 运行后,打印log输出,能看到检测信息输出,并将检测结果画框保存为图片out_yolo26.png,可以通过adb pull的方式在服务器端进行查看。运行后,打印log输出,能看到检测信息输出;
model_file=model/yolo26s_int16_t736.nb, input=model/dog.jpg, loop_count=1, malloc_mbyte=10
VIPLite driver software version 2.0.3.2-AW-2024-08-30
input 0 dim 3 640 640 1, data_format=2, quant_format=0, name=images_394_out0, none-quant
output 0 dim 6 300 1 0, data_format=0, name=attach_output0/out0_0_out0, none-quant
nbg name=model/yolo26s_int16_t736.nb, size: 17443936.
create network 0: 14395 us.
prepare network: 11167 us.
buffer ptr: 0x1b308600, buffer size: 1228800
feed input cost: 23958 us.
network: 0, loop count: 1
run time for this network 0: 6533531 us.
Debug: scale=0.8333, new_w=640, new_h=480, pad_w=0, pad_h=80
detection num: 4
1: 97%, [ 125, 133, 566, 420], bicycle
16: 94%, [ 132, 222, 310, 541], dog
7: 62%, [ 466, 74, 690, 171], truck
2: 50%, [ 466, 74, 690, 171], car
destory npu finished.
~NpuUint.
板端的运行结果: 有细心的同学就会发现一个问题,打印log的检测nums多了一个目标,两个目标的框是重叠的,但是类别不一样。使用yolo模型检测这张图片常有的问题,图中的目标类别既可以是car也可以是truck。一般正常模型会识别成其中一个类别,这里正好是两个类别的框重叠了,truck标识被覆盖掉了。总结,还是要对模型进行裁剪才能保证精确问题。
有细心的同学就会发现一个问题,打印log的检测nums多了一个目标,两个目标的框是重叠的,但是类别不一样。使用yolo模型检测这张图片常有的问题,图中的目标类别既可以是car也可以是truck。一般正常模型会识别成其中一个类别,这里正好是两个类别的框重叠了,truck标识被覆盖掉了。总结,还是要对模型进行裁剪才能保证精确问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)