强化学习算法比较
范围:PPO、DPO、GRPO
1. 不同算法简介
1.1 PPO

核心关注概率比例、优势函数。
① 概率比例很简单:就是每个token位置模型的输出概率。
② 优势函数
1.2 GRPO
https://github.com/deepseek-ai/DeepSeek-Math
https://arxiv.org/pdf/2402.03300
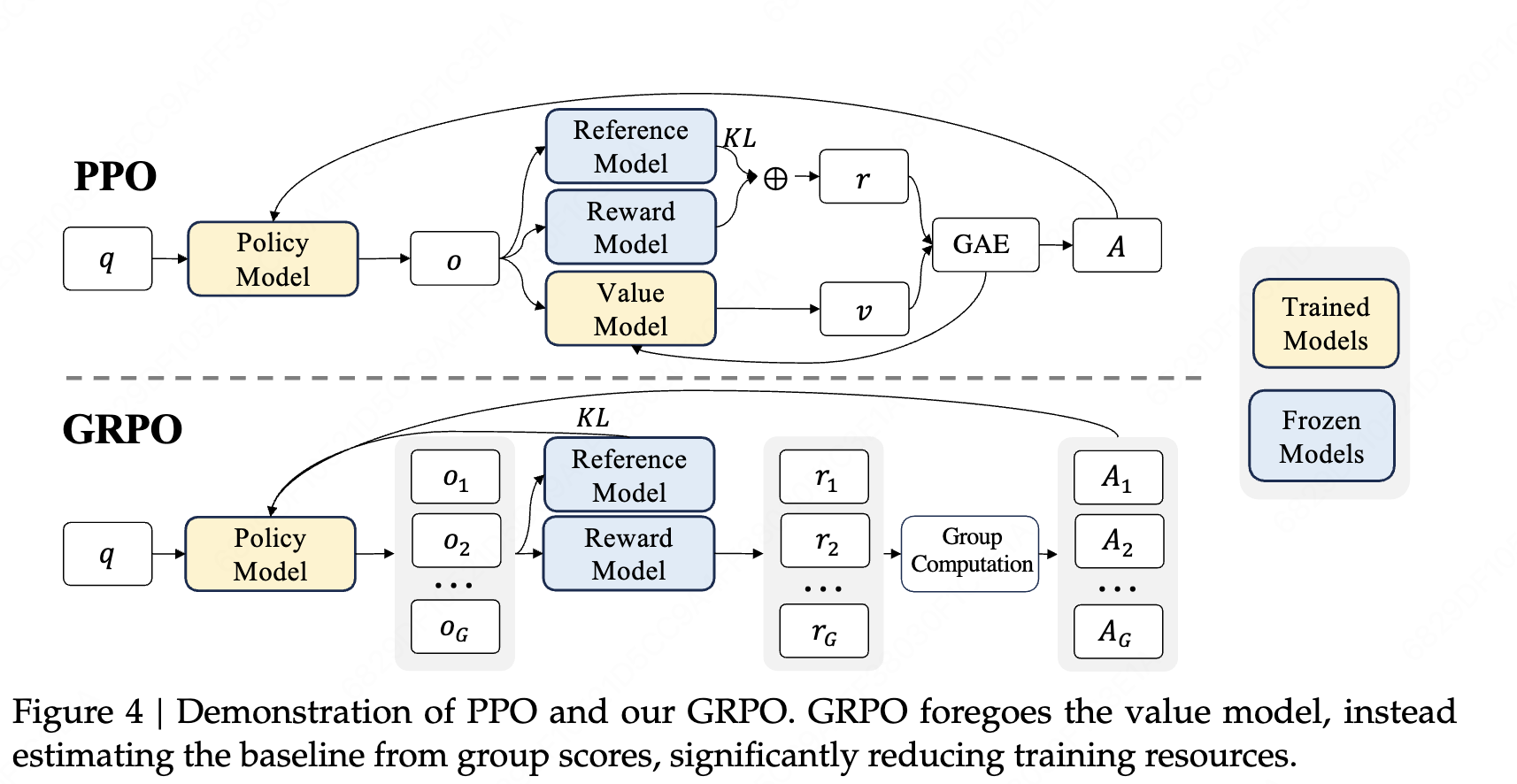
PPO算法:
输入query--策略模型采样输出得到o--分别给到参考模型、奖励模型、价值模型
基于价值模型v、奖励模型r的输出 计算GAE,GAE用于优化价值模型
基于GAE计算优势函数A,基于A优化策略模型。
参考模型和策略模型之间计算kl散度
加号是啥意思?
目标函数角度:最终奖励=kl奖励 + 奖励模型原始奖励。
GRPO具体公式
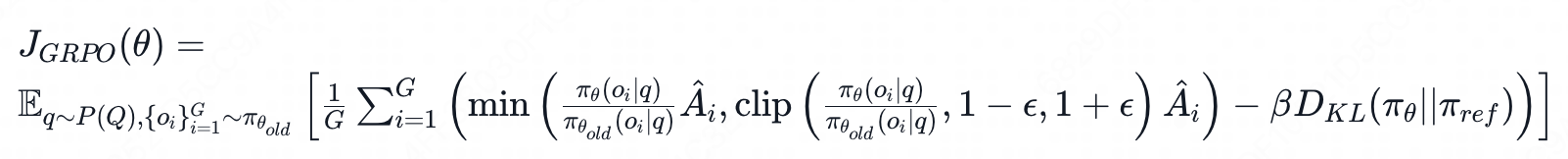
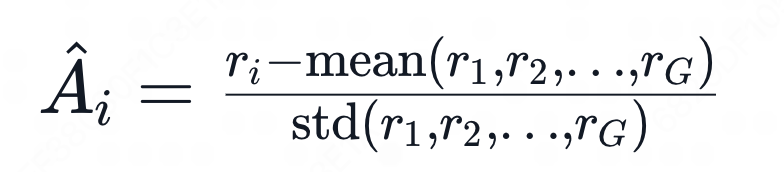
优势函数的计算不在依赖td、gae。
1.3 PPO、GRPO的对比

1.4 DPO又是什么
1句话总结:将人机对齐问题转化为了一个**二分类交叉熵(Binary Cross-Entropy)**问题。
局限性:需要有偏序训练数据
Loss:

2. 优势函数计算
在强化学习(尤其是 PPO 和 GRPO)中,优势函数(Advantage Function, AtAt) 的核心作用是衡量:“在当前状态下,采取这个特定动作比平均水平好多少?”
计算优势函数的方法主要有三种,分别对应不同的算法场景:
1. 基础定义:Q值与V值的差
从理论上讲,优势函数 A(s,a) 的定义非常简单:
A(s,a)=Q(s,a)−V(s)
- Q(s,a):在状态 s 下采取动作 a 的预期长期收益。
- V(s):在状态 s 下采取平均动作的预期长期收益(由 Critic 模型估计)。
2. PPO 中的主流方法:GAE (Generalized Advantage Estimation)
在 PPO 的实际工程实现(如你提到的 verl 框架)中,最常用的方法是 GAE。它通过平衡“偏差(Bias)”和“方差(Variance)”来稳定训练。【token粒度优势】
第一步:计算 TD 误差(Temporal Difference Error)
首先计算每一步的单步误差 δtδt:
δt=rt+γV(st+1)−V(st)
第二步:计算 GAE 优势
GAE 考虑了未来多步的误差,并引入了一个平滑参数 λ(通常 0.95):![]()
3. GRPO 中的创新方法:组相对优势 (Group Relative)
这是 DeepSeek-R1 爆火的原因之一。GRPO 不需要 Critic 模型(V值),它通过“群体对比”来计算优势。【句子粒度优势】
计算步骤:
- 采样:针对同一个问题(Prompt),让模型生成一组不同的回答。
- 打分:用奖励模型(Reward Model)或规则(如编译器检查)打分,得到一组奖励值。
- 标准化:直接计算这组分数的均值(mean)和标准差(std)。
- 计算优势
理解: 这种方法非常直观——如果你的分数比这组人的平均分高,你的优势就是正的;反之就是负的。它完全去掉了复杂的 Critic 模型,极大地节省了显存。
4. 在 LLM(大语言模型)中的特殊处理
在 verl 等框架处理 LLM 对齐时,优势函数的计算还有两个细节:
- Token 级别: 优势通常是针对每个生成的 Token 计算的。
- 白化处理(Whitening): 在得到一整个 Batch 的 At 后,通常会进行一次全局标准化(减均值除以标准差),确保该 Batch 的优势均值为 0。
- 原因:这能保证在一个 Batch 中,总有一半的动作被鼓励,一半的动作被抑制,从而让梯度更新更加稳定。
总结对比
| 方法 | 依赖模型 | 核心思想 | 适用场景 |
|---|---|---|---|
| 基础 TD | Critic 模型 | 实际收益 - 预测收益 | 简单强化学习 |
| GAE | Critic 模型 | 多步误差的加权指数平均 | PPO (主流标准) |
| Group Relative | 无 (只需 Reward) | 组内成员互相PK,高出平均分即为优 | GRPO (DeepSeek 方案) |
一句话总结: PPO 靠 Critic 模型 预判平均分来算优势;GRPO 靠 同组采样 的平均分来算优势。
3. 奖励白化问题

奖励白化会带来“跨任务不公平”问题,这也是GRPO兴起的原因之一。因为GRPO在同一个组内进行白化最大程度避免白化带来的问题。
奖励白化具体例子
一句话总结: 白化就是把“考了 80 分”转换成“你在班级里排前 10%”,这比绝对分数更能有效地指导模型进步。
场景设定
- 任务:让模型解一道数学题。
- 组大小 (Group Size, G):G=5G=5(即针对这道题,模型生成了 5 个不同的回答)。
- 奖励模型 (RM):给每个回答打分,分值范围 [0,1][0,1]。
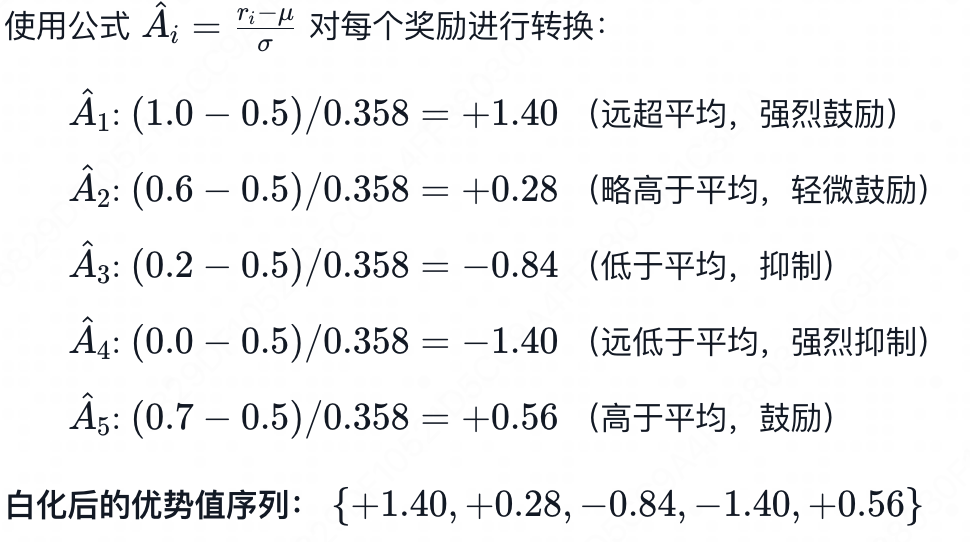
第一步:获取原始奖励 (Raw Rewards)
假设 5 个回答得到的原始分数如下:

原始奖励序列: {1.0,0.6,0.2,0.0,0.7}
第二步:计算均值 (μμ) 和 标准差 (σσ)
白化的核心是计算这组数据的统计特征。
- 计算均值 (Mean):
- 计算标准差 (Std Dev)
第三步:执行白化 (Whitening)
第四步:理解白化的“范围” (Scope)
白化的效果取决于你选择在多大范围内计算均值和标准差。这是 PPO 和 GRPO 的核心区别:
1. 组内白化 (Group-level) —— GRPO 的做法
- 范围:仅针对同一个 Prompt 生成的 GG 个样本。
- 特点:数学题只跟数学题比。即使这组题很难,大家的原始分都很低(比如最高才 0.2),白化后那个 0.2 的样本依然会得到一个很高的正向优势值(比如 +1.5)。
- 优点:极其公平,精准区分同一题目下的好坏回答。
2. 批次白化 (Batch-level) —— 标准 PPO 的常见做法
- 范围:针对整个训练 Batch(可能包含 10 道数学题、10 道语文题、10 道代码题)。
- 特点:跨题目对比。如果数学题普遍难拿分,语文题普遍好拿分,那么数学题的样本在白化后可能全是负数。
- 缺点:容易产生你之前提到的“任务歧视”问题。
3. 全局白化 (Running Mean/Global)
- 范围:针对整个训练历史。
- 特点:维护一个全局的均值和方差。
- 优点:解决了 Batch 内部的任务偏差,但计算稍复杂,且训练初期由于全局统计量不稳定,收敛较慢。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)