面向 AI 的多模态数据开发能力-算子任务
引言与背景
1. 数栈多模态数据智能平台
数栈多模态数据智能平台源于成熟的结构化数仓体系,并自然演进到多模态数据能力,旨在帮助企业统一解决多模态数据的采集、加工、治理与应用问题。
平台的核心理念是不围绕特定模型或AI框架,而是聚焦于数据本身,让多模态数据首次以"数据资产"形式进入企业数据体系,确保AI的每次使用都建立在可追溯、可解释的数据基础上。这一理念使得企业能够构建更加稳健、可靠的数据基础,支持各类AI应用的快速开发与部署。
2. 多模态数据开发引入Data-Juicer框架
为了进一步提升多模态数据处理能力,数栈平台引入了业界领先的开源框架 Data-Juicer。该框架由阿里巴巴通义实验室主导开发,专为大型基础模型(特别是大语言模型)设计,提供一站式的文本与多模态数据处理能力,涵盖数据清洗、增强、合成与分析等全流程。
选择 Data-Juicer,主要基于其在多模态数据处理领域的领先地位和丰富功能:
- 海量算子生态:内置 163 个注册算子,覆盖 6 大算子类型(如清洗、过滤、去重、格式化等),支持灵活编排组合,轻松应对复杂多变的数据处理需求。
- 多模态全面支持:统一处理文本、图像、音频、视频等多种数据类型,为多模态 AI 应用的开发提供坚实的数据基础。
- 灵活的执行模式:同时提供单机执行和基于 Ray 的分布式执行两种模式,既能满足快速原型验证的轻量需求,也能无缝扩展至超大规模数据集的处理。
- 配置驱动:采用 YAML 配置定义处理流程,使数据流水线清晰、可复用,便于团队协作与版本管理。
- 数据洞察能力:内置完整的数据分析与质量评估体系,帮助开发者深入理解数据分布、识别数据瓶颈,持续优化数据质量。
离线计算平台-新增"算子任务"
作为多模态数据智能平台的重要组成部分,离线计算平台通过新增"算子任务"类型,将Data-Juicer的强大能力无缝嵌入数栈平台,为用户提供更加全面的数据处理解决方案。
1. 算子任务概述
- 核心定位:离线计算平台新增的核心任务类型,专注于多模态数据处理,覆盖从原始数据到高质量训练集的全流程。
- 开发模式:同时支持向导模式与脚本模式。向导模式通过可视化界面引导配置,适合快速上手;脚本模式则开放自定义代码能力,满足复杂业务逻辑。
- 框架选型:基于业界领先的开源多模态数据处理框架 Data-Juicer。该框架内置丰富的算子库,支持灵活的算子编排,让数据处理既高效又简单。
- 数据来源:支持两种方式——直接对接原始数据源,或引入资产平台中已治理好的数据集,实现数据资产的高效复用,避免重复开发。
2. 核心功能与特性
开发模式
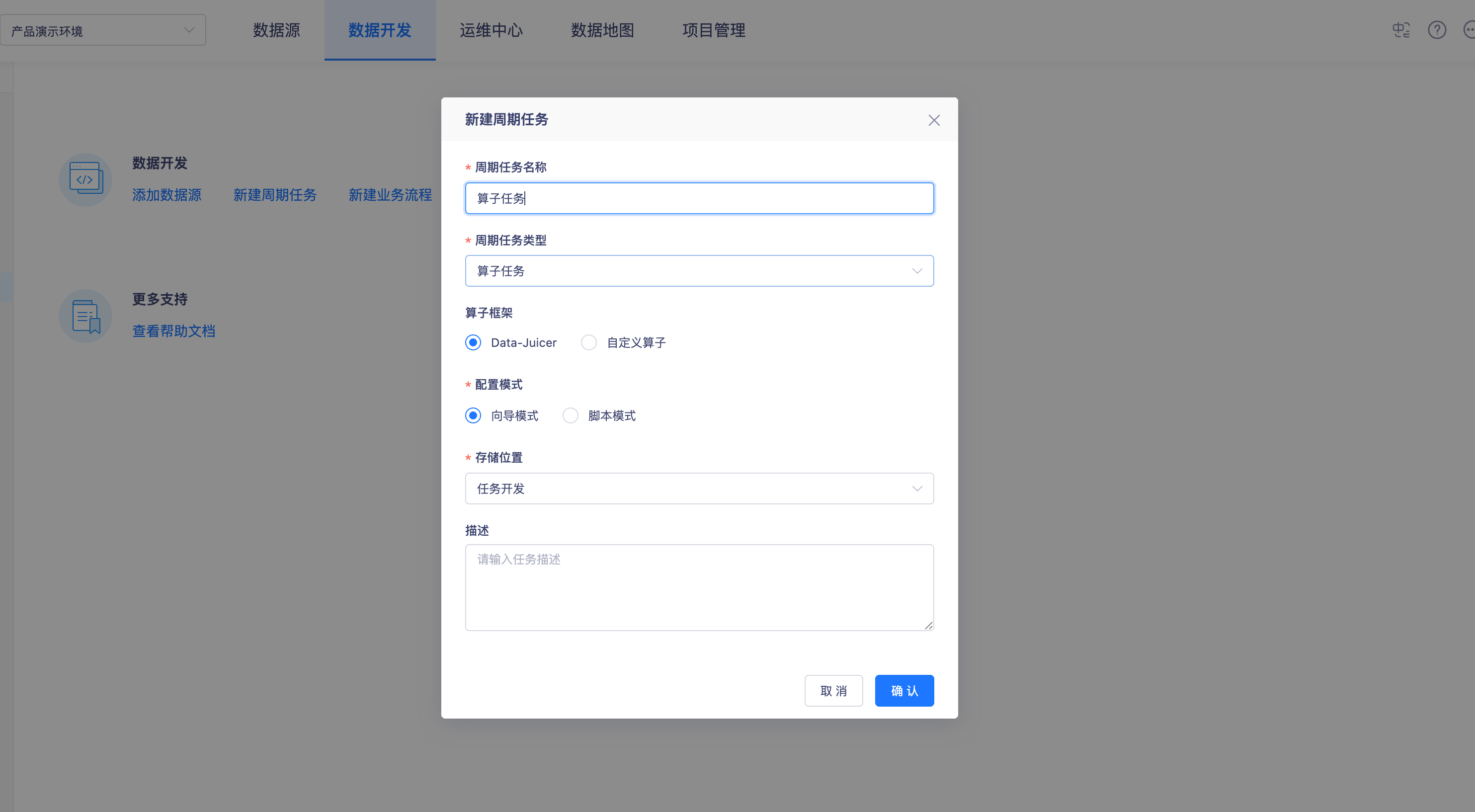
向导模式通过可视化界面引导配置,适合快速上手;脚本模式则开放自定义代码能力,满足复杂业务逻辑。
可视化编排
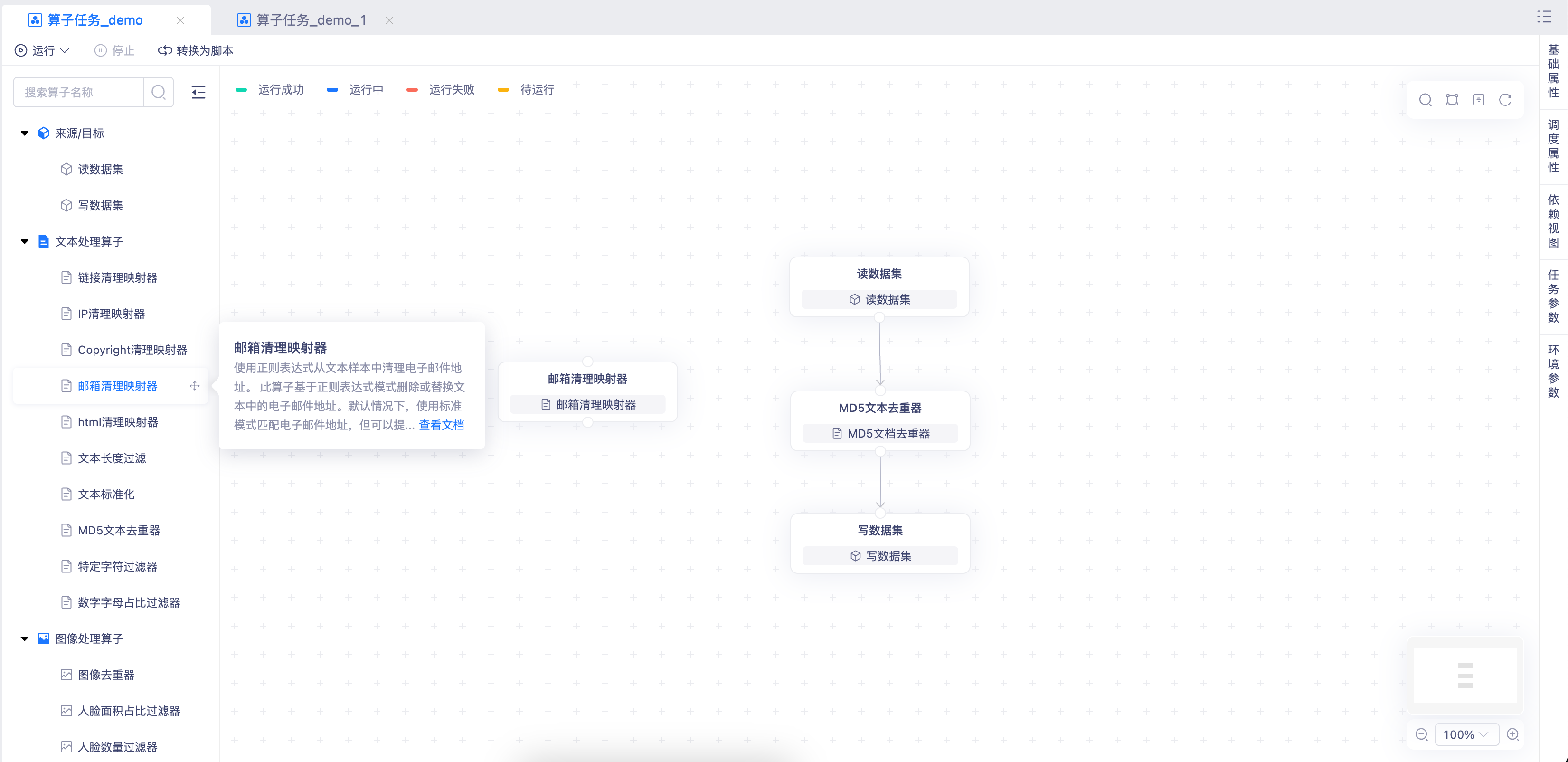
通过拖拉拽的方式构建算子任务的上下游工作流,界面直观、操作简便。即使是非技术背景的运营人员也能轻松上手,大幅降低学习成本,提升工作效率。
灵活的调试运行
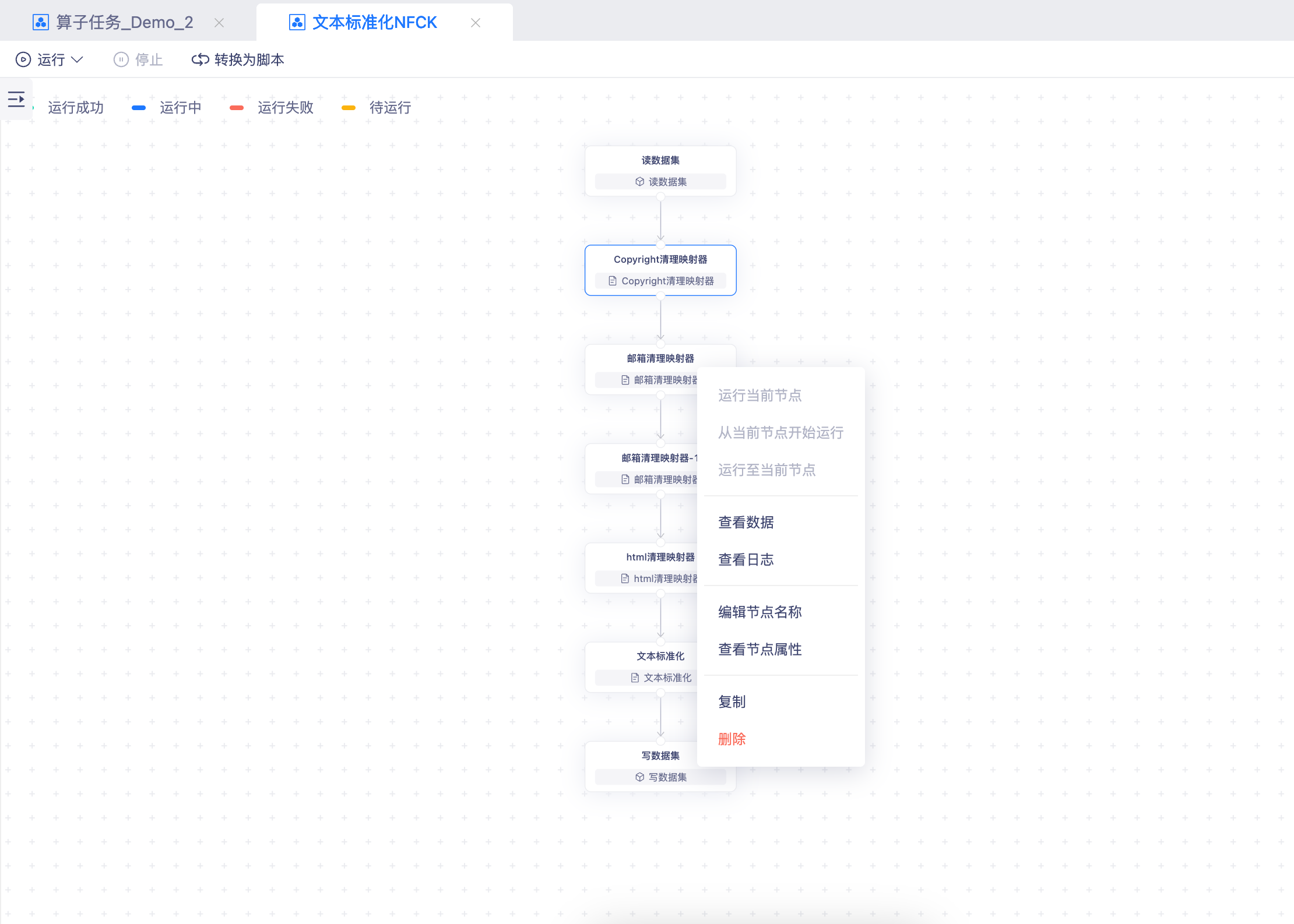
- 全量运行:可随时触发整个算子任务的执行,验证整体流程。
- 局部调试:右键单击单个或局部节点,灵活选择“运行当前节点”“从当前节点开始执行”或“运行至当前节点”,便于分阶段调试。
- 状态反馈:运行成功或失败时,节点图标会实时变化,一目了然,帮助开发者快速掌握任务进展。
日志与结果
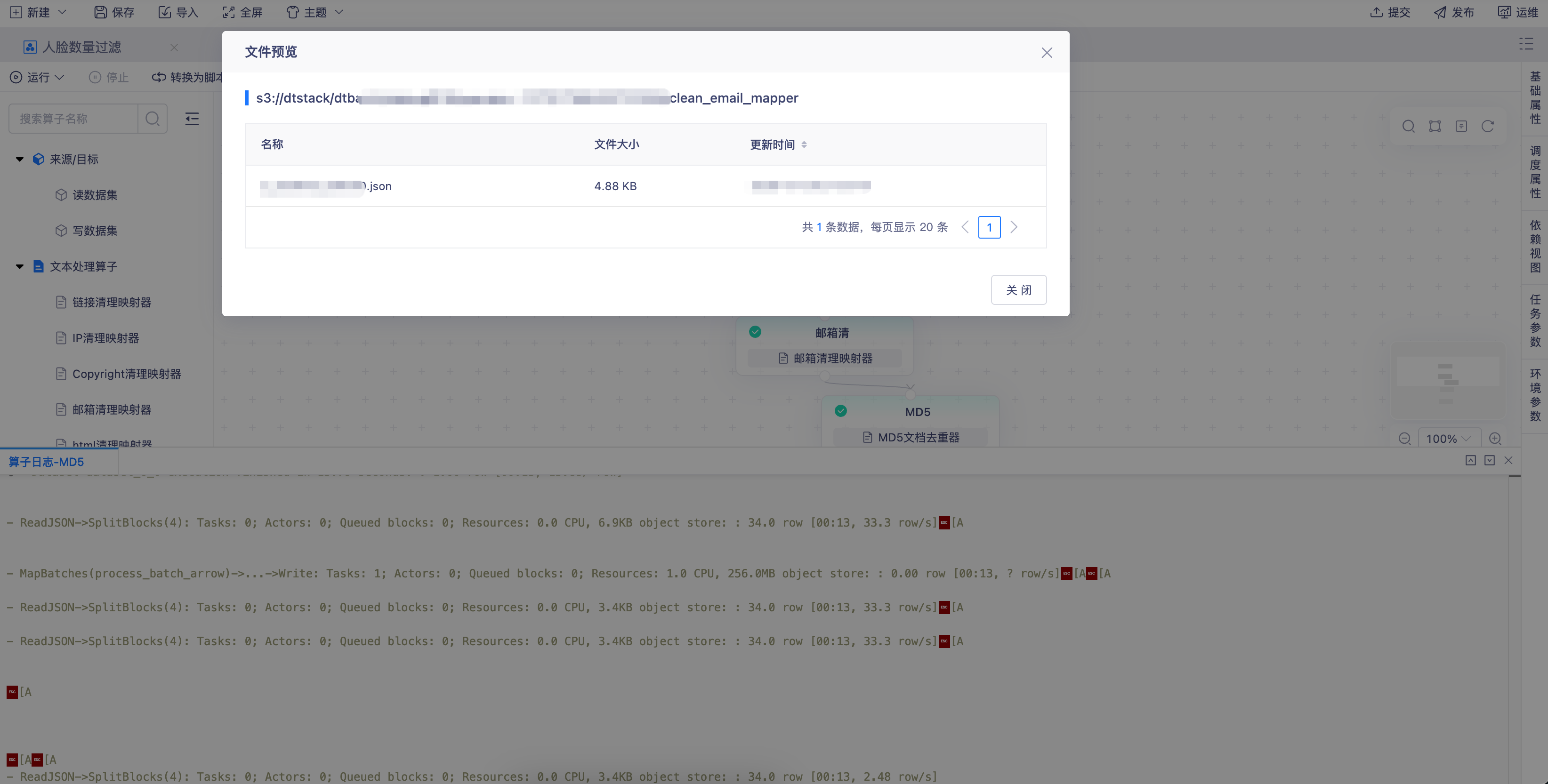
- 成功时:右键节点即可查看产出的数据样例,快速验证结果是否符合预期。
- 失败时:一键查看日志,系统内置的智能分析引擎会自动解析日志内容,高亮关键错误信息,并给出可能的原因及修复建议,帮助开发者快速定位问题,极大缩短排查时间。无论是依赖缺失、资源不足还是数据格式异常,智能分析都能提供清晰的指引。
离线调度
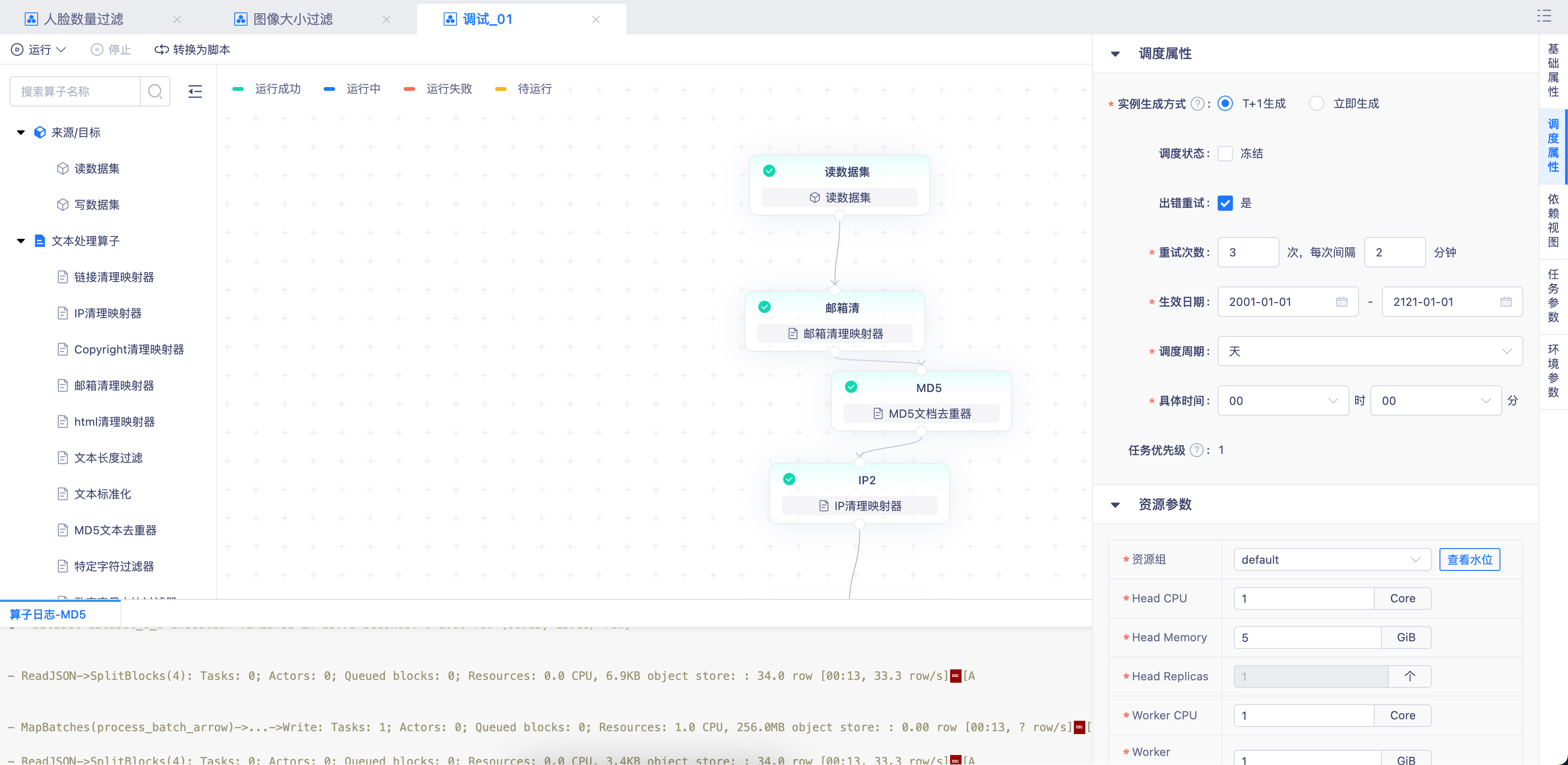
支持配置周期性调度,将算子任务纳入自动化工作流。无论是每日定时执行,还是与模型训练Pipeline无缝衔接,都能实现零人工干预,让数据处理完全自动化运行。
基于Ray的分布式资源配置
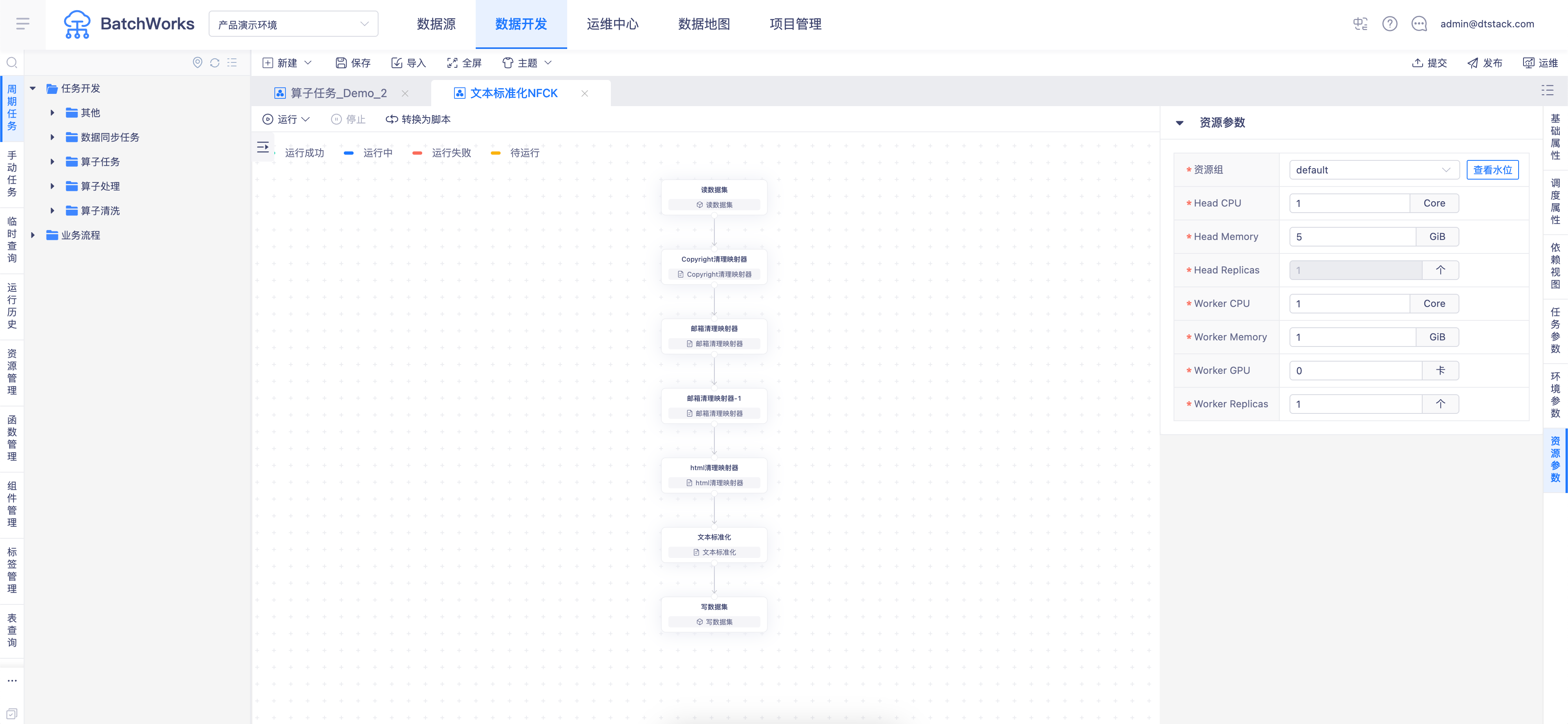
算子任务底层基于 Ray 分布式框架构建,赋予任务强大的分布式计算与弹性调度能力。
- 分布式调度:自动将算子任务拆分为多个子任务,并分发到不同节点并行执行,显著提升大规模数据处理效率。
- 弹性伸缩:根据实际数据量动态调整Worker节点数量,资源利用率最大化,同时降低成本。
- 异构资源支持:无缝融合CPU与GPU资源,满足多模态处理中图像、视频等计算密集型任务的硬件需求。
- 容错与可靠性:当某个Worker节点失败时,Ray会自动重新调度失败的任务,确保整个数据处理流程的稳定性。
基于Ray的底层能力,算子任务提供了灵活的资源组配置。资源组基于Kubernetes Namespace进行隔离,确保多租户环境下的资源安全。每个资源组包含一个负责协调调度的Head节点(固定为一个,保证集群管理稳定性)和若干个实际执行计算任务的Worker节点。用户可以根据数据处理规模,灵活调整Worker节点的CPU、内存、GPU卡数以及节点数量,轻松应对从轻量级采样到TB级全量处理的各种场景。
版本与任务管理
- 历史版本:支持查看、回滚至任意历史版本,避免因误操作导致的工作丢失。
- 版本对比:可直观对比两个版本的差异,协作开发时清晰透明。
- 克隆至工作流:一键将算子任务克隆到其他工作流,实现快速复用。
依赖关系管理
算子之间支持定义明确的上下游依赖,确保数据处理遵循正确的顺序。无论是简单的线性流程还是复杂的DAG,都能精准控制执行逻辑。
总结与未来
"算子任务"功能的引入,为数栈多模态数据智能平台注入了强大的多模态数据处理能力,赋能企业更高效、更规范地进行多模态数据处理。通过可视化编排、灵活调试、完善的资源配置和调度机制,企业能够构建起标准化的数据处理流程,为AI大模型应用打下坚实的数据基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)