大模型从基础到入门——入门知识二 相关工具
本文主要记录入门大模型学习的相关知识,以期为后续工作学习提供帮助。(除了我自己截图外,引用的我尽量标注来源,有些忘记来源了请告诉我orz)
更新ing
一、大模型相关工具
Flash Attn
为解决普通Transformer计算速度慢和存储占用高的问题,人们将优化方向分为两个大方向:FLOPS(floating point operations per second)、MAC(memory Access Cost)。其中,针对降低FLOPS的方法叫做Efficient Transformer,而已经有实验发现,只降低FLOPS并不能显著提升模型计算速度,因为此时MAC开销将成为瓶颈。
根据计算密集程度,我们可以将operator分为两类:
- 计算密集型-Computed-bound:包括大矩阵乘法、大卷积核卷积操作等;
- 存储密集型-Memory-bound:包括逐元素操作(ReLU、dropout)、Reduce归约操作(求和、softmax、batchNorm)等。
Flash Attention将优化重点放在了降低存储访问开销方面(MAC),而代价就是增加了一定的FLOPS。
首先,我们看看一次标准的Transformer计算包含八次显存(HBM)读写操作:
- 读Q、K并乘法计算,写回结果,共三次;
- softmax一读一写,共两次;
- 读中间结果、V并乘法计算,写回结果,共三次
其中矩阵乘法可以使用分块思想来加速计算,Flash Attention将参与计算的矩阵分块送入GPU静态缓存(SRAM)中,从而减少HBM的读写。
但难点在于优化第二步的softmax计算过程:普通的softmax是一个e的指数项分式,当指数过大时会引发溢出问题,所以在实际实现中,我们通常需要将指数减去所有数中的最大值,达到缩放目的。而最大值和求和就是优化的难点。
核心思想:Flash Attention采取了增量计算,在矩阵分块思想基础上,先对一个分块计算局部softmax值,并存储,在处理下一个分块时,再返回更新全局最大值、exp求和项、前面分块保存的旧softmax值。
该方法通过直接计算得到答案,避免中间矩阵attn的存储,在越长的文本上效果越好,可达到普通方法的3.5倍。
vLLM - Paged Attn
vLLM主要用于快速LLM推理和服务,具有最好的服务吞吐性能、Paged Attention优化KVcache、动态batch、优化CUDA kernels四个特点。
其技术核心就是Paged Attention,该方法将操作系统中虚拟内存分页思想引入到LLM中,可以在无需任何模型架构修改情况下提高速度。
对于普通KV cache来说,其具有显存占用大、动态变化的特性,所以管理KV cache难度较大。所以Paged Attention 允许在非连续的内存空间中存储连续的K、V,具体来说,其将每个序列的KV cache划分为块,每个块包含固定数量token的KV,在计算时根据需要去内存中高效调用对应块即可。
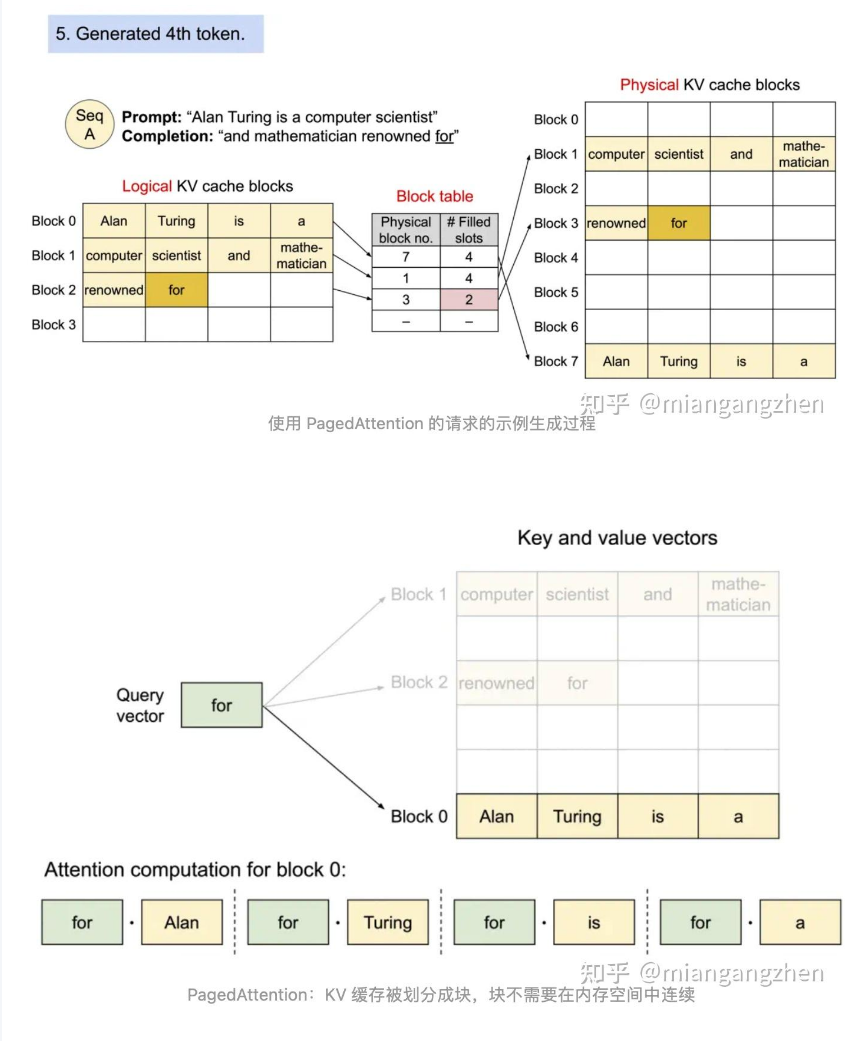
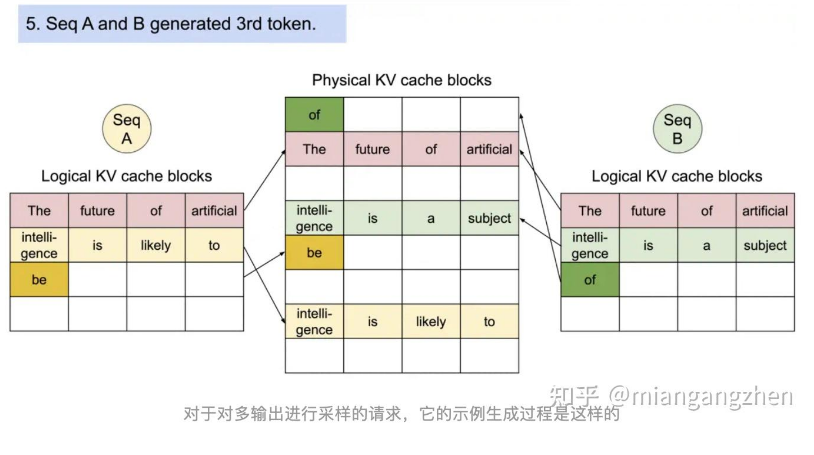
从上面的图可以看出,内存浪费只会发生在最后一个块中,从而让系统对更多序列进行批处理,提高GPU利用率与吞吐率;同时,在并行采样中,多个输出序列是由同一个prompt生成的,中间计算和内存可以在输出序列中共享,实现高效内存共享。
总的来说,vLLM通过调度器、显存管理、执行器,实现以下优点:
PagedAttention(分页注意力)
将传统的连续KV缓存拆分为非连续内存页管理,类似操作系统的虚拟内存机制。优势:相同前缀请求复用KV缓存连续批处理(Continuous Batching)
动态合并不同进度的请求,GPU空闲时间减少75%,对比传统静态批处理,吞吐量提升2-4倍量化与CUDA内核优化
支持FP8/INT8量化,集成FlashAttention等优化内核,多GPU分布式推理支持,通过张量并行拆分模型至多卡- 分块预填充chunked prefill:处理超长prompt的prefill,将其分块与其他请求一起处理,保证吞吐量
llama.cpp
Ollama底层调用就是llama.cpp,面向边缘计算的轻量化引擎,其核心技术原理:
分层量化技术
支持1.5~8位自适应量化,7B模型4-bit量化后仅需4GB内存,采用GGUF格式二进制存储,支持内存映射加载跨平台指令集优化
ARM NEON加速苹果芯片,AVX512优化x86架构,集成Metal框架实现M系列芯片原生加速混合推理模式
CPU+GPU协同计算,突破单一硬件显存限制,通过WebAssembly实现在浏览器端运行(如移动端)
KTransformer
存储优化
MoE架构的异构参数管理
稀疏MoE参数卸载:将模型中非Shared部分的稀疏MoE矩阵存储在CPU内存中,仅将稠密部分保留在GPU显存,显著降低显存需求。这种策略在DeepSeek-671B模型中实现显存占用降低60%以上 ;动态参数加载:根据当前激活的专家模块动态加载CPU中的参数,通过异步预加载机制减少延迟。例如在处理文本生成任务时,CPU参数加载与GPU计算并行执行 。KV Cache压缩与分层存储
MLA算子融合:通过将矩阵运算吸收到权重矩阵中,直接生成压缩后的KV Cache,减少序列长度对缓存空间的依赖。对比传统MHA实现,KV缓存体积压缩率达30%;分级缓存策略:高频访问的KV数据保留在HBM显存,低频数据放置于SSD/CPU,通过相似性检索(如PageAttention)实现按需加载 。动态量化与混合精度
分层量化策略:对激活函数采用动态INT8量化(通过SmoothQuant迁移异常值),权重则采用INT4分组量化(如GPTQ算法),综合压缩率达75% ;量化感知训练集成:支持训练时引入模拟量化噪声,提升低精度参数的鲁棒性 。
计算优化
算子的深度定制与融合
MLA算子重构:将原始MLA展开的MHA计算流合并为单次矩阵运算,算术强度提升2.3倍。例如在A100显卡上,Attention计算耗时从5.2ms降至2.1ms ;CPU-GPU协同计算:设计异构算子(如GELU反向传播),将部分计算任务分配给CPU(如稀疏矩阵乘法),利用CPU多核并行性分担GPU负载 。并行化与内核加速
张量并行扩展:支持跨多GPU的权重分片,通过QPI总线实现层间参数的动态迁移(如每层参数分布在不同的CPU插槽本地内存);CUDA Graph优化:预编译高频计算路径(如Attention-MLP计算流),减少内核启动开销。实测在长序列生成场景下延迟降低18% 。计算强度敏感的任务调度
基于ROI的Offload策略:根据算子计算强度(Ops/Byte)自动决策是否将任务卸载到CPU。例如Softmax等低计算强度操作优先卸载 ;动态批处理合并:结合EffectiveTransformer的连续序列打包技术,消除Padding带来的冗余计算,吞吐量提升40% 。
deepspeed ZeRO
ZeRO优化就是针对数据并行所需的庞大显存,让每张卡/节点只存储模型的一部分,实现优化目的。其将训练时显存占用分为两种:
- 模型状态:参数+梯度+优化器状态,优化器状态占75%
- 剩余状态:激活值、缓冲区、显存碎片等
核心就是将显存中的数据分片,系统维护一份模型状态,超过显存的offload到内存,CPU reduce梯度并辅助更新常数,GPU异步计算前向、后向传播。
ZeRO 1、2、3分别代表对模型状态占用进行优化:优化器状态、梯度、参数
此外,DeepSpeed Inference也对多GPU下的推理进行了优化:维护多GPU通信、算子融合减少内核调用次数(降低主存访问延迟)、INT8量化混合精度推理
二、其他扩展
梯度消失与梯度爆炸
深度学习方法主要分为forward和backward两个步骤,后者需要根据损失函数计算误差,再通过梯度反向传播更新参数,而根据求导的链式法则,求导的公式是一个连乘,如果梯度过大,则将以指数形式增加,导致梯度爆炸;如果梯度过小,则也会以指数形式衰减,导致梯度消失。
照成这两个现象的原因就是反向传播法则,在网络结构过深、激活函数选择不当时最为明显,有以下几种解决方案:
- 梯度裁剪+正则化
- 激活函数swish
- 归一化
- 残差连接
熵、交叉熵、KL散度
1.信息熵:表示系统的不确定性或信息量,用于衡量一个随机变量的平均信息量,公式为
2.交叉熵定义与信息熵类似,但其用于衡量两个概率分布间的区别,值越小,两个分布的差异也越小,所以一般用于损失函数,表示模型预测分布与真实分布间的差距,公式为:
其中y为真实概率分布,y‘为模型预测概率分布。
3.KL散度(相对熵)则强调两个概率分布间不对称差异(没有交换律,即用a算b的结果不等于用b算a),即评估两者之间的信息损失,一般用于强化学习阶段衡量两个不同模型间预测分布差距,公式为
当使用one-hot编码时,KL退化为交叉熵,此时他们相等。
参考

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)