AI笔记第三节:Transformer的注意力机制和多头注意力
单头注意力

/根号dk
一句话:为了缓解梯度消失或爆炸。使点积的值保持在可控范围内
详细:https://zhuanlan.zhihu.com/p/503321685
除以k矩阵的维度。这里面代码k.shape[1]就是矩阵的列数
k.shape[0] 是矩阵的行数,k.shape[1] 是矩阵的列数。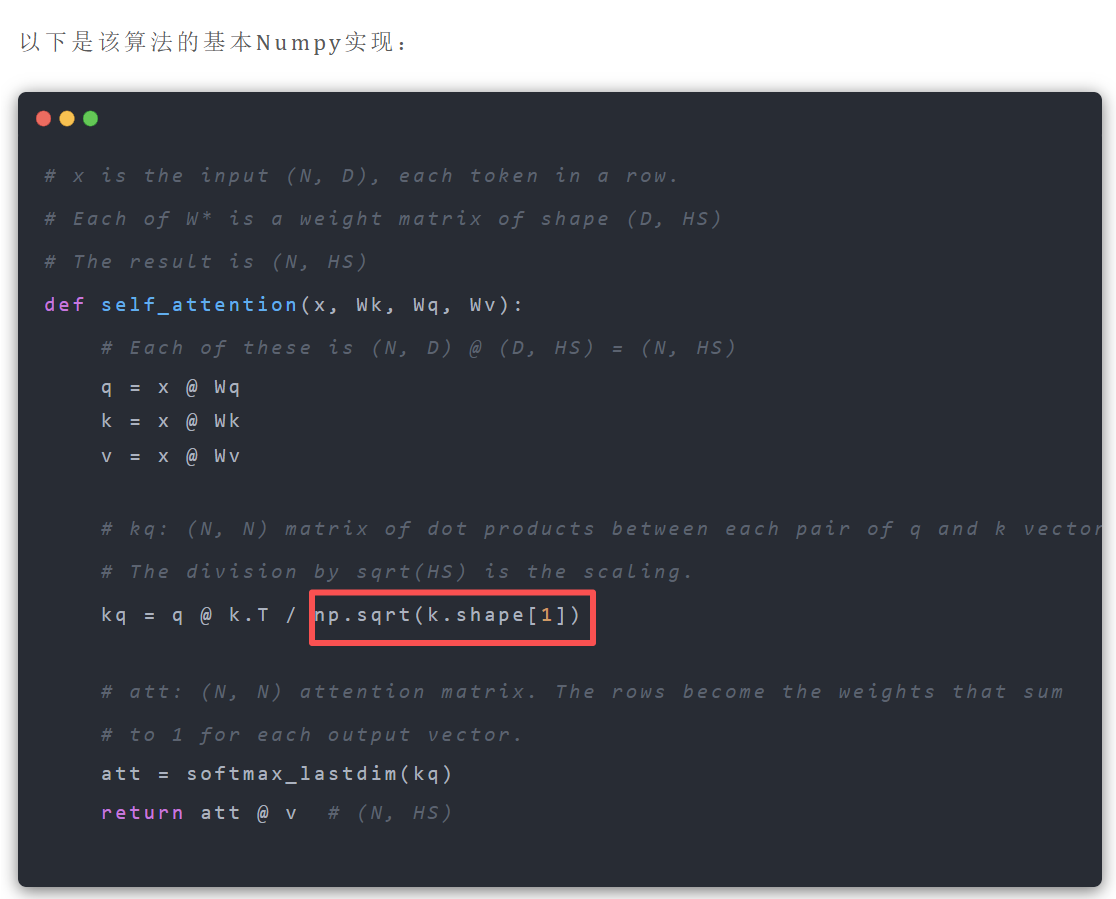
所以由上面代码知道,这个 除以根号dk,就是直接除以矩阵K的维度。
多头注意力
多头注意力的拆分是 Q, K, V 三个矩阵。即:原始输入 X → 线性变换 → Q, K, V → 拆分 → 多个头的Q_i, K_i, V_i
定义
先看比较官腔的定义:
在《Attention Is All You Need》论文中,多头注意力是通过将查询(Q)、键(K)和值(V)线性投影到多个子空间,然后在每个子空间上分别执行注意力函数,最后将结果合并起来而实现的。
具体来说,多头注意力的计算过程如下:
- 将Q、K、V通过不同的线性变换(即不同的权重矩阵)投影到多个子空间,每个子空间称为一个“头”。
- 对每个头,计算缩放点积注意力。
- 将每个头的输出拼接起来。
- 再通过一个线性变换(输出权重矩阵)得到最终输出。
那么,多头注意力确实需要拆分Q、K、V矩阵。拆分是在特征维度(即词向量的维度)上进行的。
看不懂吧,没关系,我第一次看也看不懂。因为很多前置概念不知道。
空间投影和投影矩阵
这是理解多头注意力的基础。


拆分后的每个头都关注什么?


模型如何解决分歧?
最终,模型会根据更大的上下文(如果有)和其他头的综合意见来决定。如果没有更多上下文,可能选择更常见的解释。
多头注意力的精髓之处
如果两个头学习了完全不同的注意力模式,它们可能对同一对词给出不同的注意力权重。因此,每个头最终产生的表示是从不同角度对输入的处理。拆分后的每个头,有可能得到不一样甚至截然相反的词与词之间的关系。
比如

如果所有头都给出完全一致的注意力模式,那么多头注意力就退化为单头注意力,失去了其核心优势。正是这种"和而不同"的设计,让Transformer能够处理语言的复杂性和歧义性,成为如此强大的模型。
这种设计哲学类似于:
议会制度:不同党派代表不同利益,通过辩论达成共识
科学共同体:不同假设竞争,最终最符合证据的胜出
大脑模块:不同脑区处理不同信息,综合产生认知
FFN(Feed-Forward Network)层
https://zhuanlan.zhihu.com/p/1891081572305846495
Attention本质
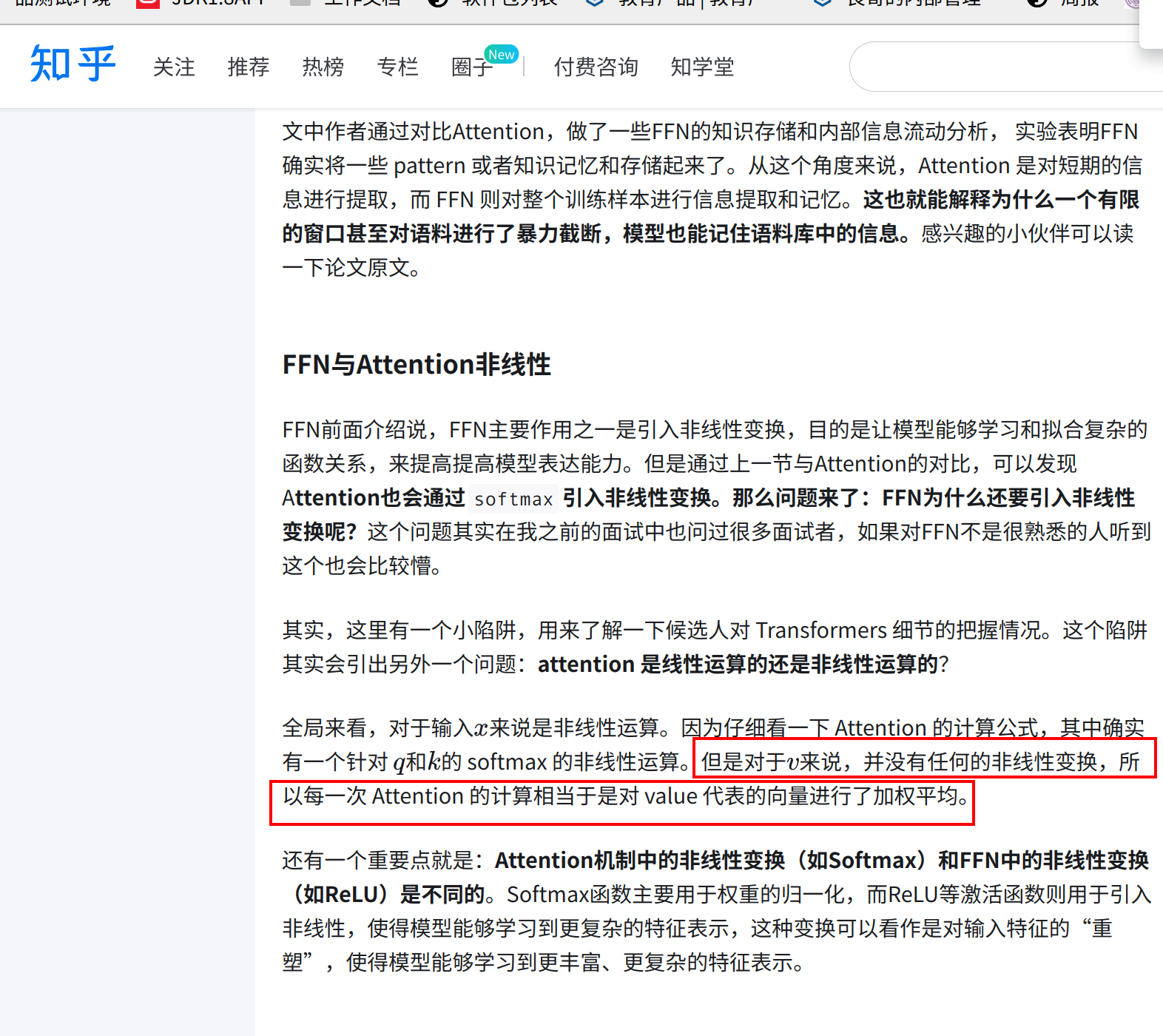
每一次Attention,就是对V矩阵进行一个加权平均而已。
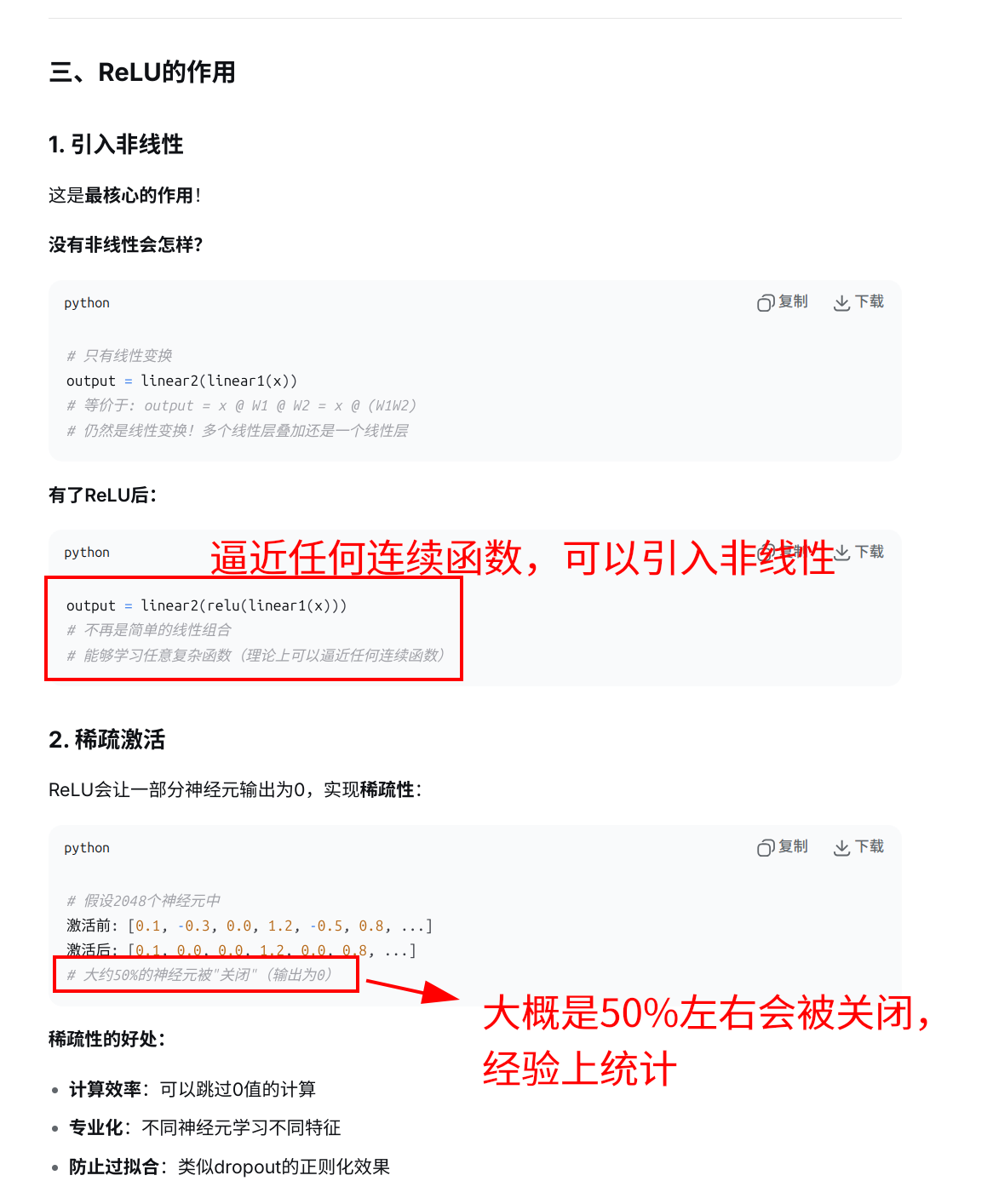
所以引入一个FFN,可以对Attention进行非线性变换。FFN的RELU函数就是干这个的
为什么已经有了Softmax还要再来一个Relu来为其引入非线性表达?
Attention也会通过softmax引入非线性变换。那么问题来了:FFN为什么还要引入非线性变换呢?这个问题其实在我之前的面试中也问过很多面试者,如果对FFN不是很熟悉的人听到这个也会比较懵。
其实,这里有一个小陷阱,用来了解一下候选人对 Transformers 细节的把握情况。这个陷阱其实会引出另外一个问题:attention 是线性运算的还是非线性运算的?
仔细看一下 Attention 的计算公式,其中确实有一个 针对q和k的 softmax 的非线性运算。通过softmax计算结果其实是一个概率矩阵,用这个概率矩阵与V相乘。但是对于v来说,并没有任何的非线性变换,所以每一次 Attention 的计算相当于是对 value 代表的向量进行了加权平均。
所以只有Attention进行Softmax,输出还是个线性的。
还有一个重要点就是:Attention机制中的非线性变换(如Softmax)和FFN中的非线性变换(如ReLU)是不同的。Softmax函数主要用于权重的归一化,而ReLU等激活函数则用于引入非线性,使得模型能够学习到更复杂的特征表示,这种变换可以看作是对输入特征的“重塑”,使得模型能够学习到更丰富、更复杂的特征表示。
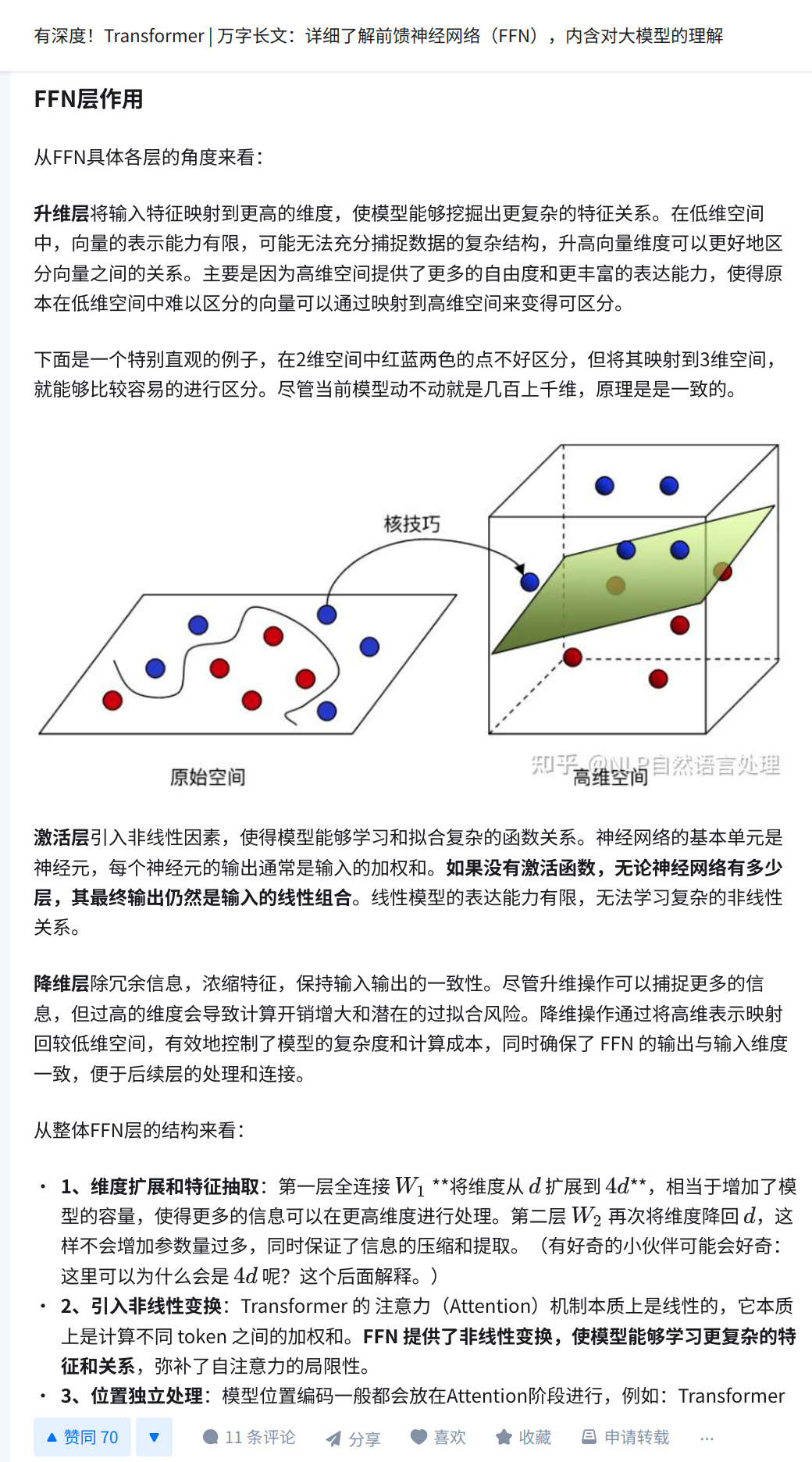
FFN核心作用
注意力已经建立了词与词之间的关系,FFN负责深化每个词的内部表示(基于上下文)
FFN主要作用之一是引入非线性变换,目的是让模型能够学习和拟合复杂的函数关系,来提高提高模型表达能力。
- 信息融合与知识应用、FFN把注意力收集的上下文信息"消化"成更高级的表示。
示例:处理"not happy"
注意力之后:"not"和"happy"建立了强关联 (注意力只是让v矩阵做加权平均)
FFN处理"happy"的向量:
输入:[happy的基本含义, 与not的关联强度, …] (FFN的输入就是Attention的输出)
经过FFN变换:
最终输出表示:[积极情感×0.3, 否定标记×0.8, 组合特征×0.9, …] FFN负责深化每个词的内部表示(基于上下文)
FFN占据了Transformer的大部分参数!
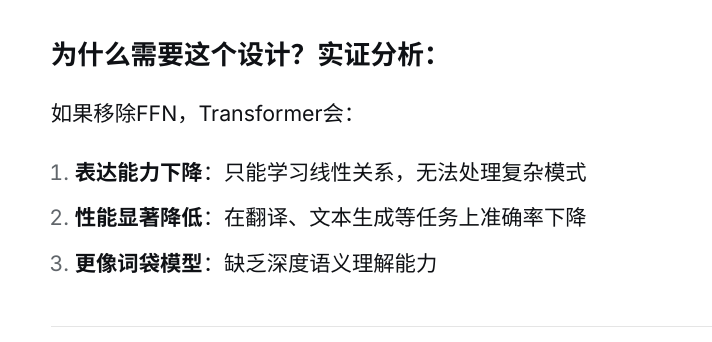
举一个实例说明FFN的作用

工作流程
扩展维度(512维 → 2048维) -> ReLU -> 压缩回原维度(2048维 → 512维)
伪代码:
# Transformer中前馈网络的典型结构
class FeedForward(nn.Module):
def __init__(self, d_model=512, d_ff=2048):
super().__init__()
self.linear1 = nn.Linear(d_model, d_ff) # 扩展维度
self.relu = nn.ReLU() # ← ReLU在这里!
self.linear2 = nn.Linear(d_ff, d_model) # 压缩回原维度
def forward(self, x):
# x形状: [batch_size, seq_len, d_model]
# 1. 第一次线性变换:512维 → 2048维
hidden = self.linear1(x) # [batch, seq, 2048]
# 2. ReLU激活函数
hidden = self.relu(hidden) # 负值变0,正值保留
# 3. 第二次线性变换:2048维 → 512维
output = self.linear2(hidden) # [batch, seq, 512]
return output
下图非常核心。X代表原始输入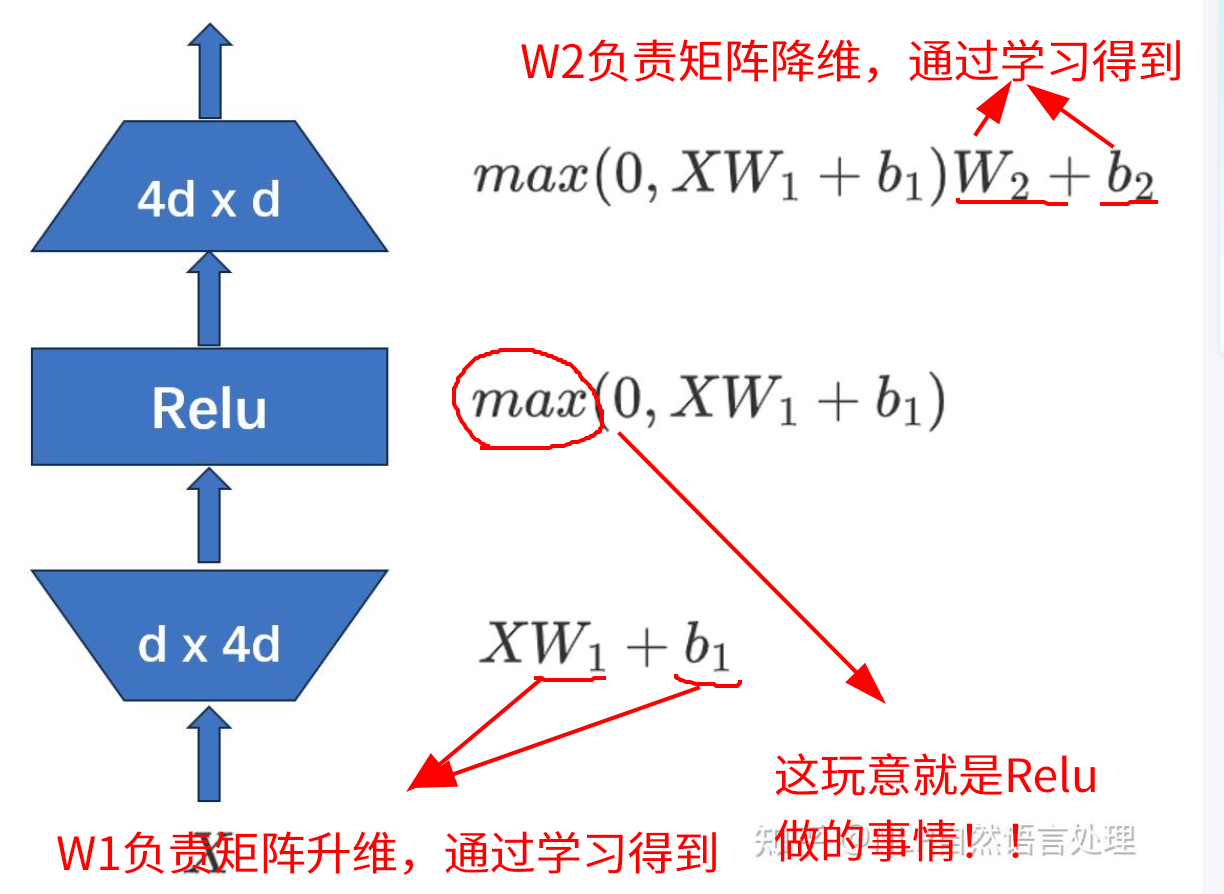
FFN 核心公式:
看懂上面那个图,下面看FFN核心公式,发现它太简单了!

Relu函数
ReLU(x)=max(0,x)

大于0返回原样,小于0返回0 。负值全部归零,正值保持原样
增加模型的非线性表达能力,稀疏激活。

升维和降维的核心作用
https://zhuanlan.zhihu.com/p/1891081572305846495
升维4d和降维4d (4是个经验结果。)

升维是为了投影到高维以增强信息的分离能力,再降维是回到原空间对齐下一步计算维度。而之所以选择4倍是经验性的,它在计算成本、参数规模、表达能力之间达到了较好的平衡。这样的回答其实并没有抓住事情的本质。其实升维的根本原因是非线性激活函数,它会导致50%左右的信息丢失,而在使用激活函数前升维是为了补偿这个损失。
首先要明白激活函数本质是通过“丢失”某些信息,让数据的结构变得非线性,从随机信号处理的角度来看,50% 是一个自然的最优点
FFN层的升维矩阵和降维矩阵是如何获得的?
核心答案:通过随机初始化 + 梯度下降算法自动学习获得

解码器
解码器中“编码序列与解码序列交叉注意力机制”(encoder-decoder cross attention)
1、 交叉注意力的KV矩阵来源:就来源于下图,也就是ENCODER中的输入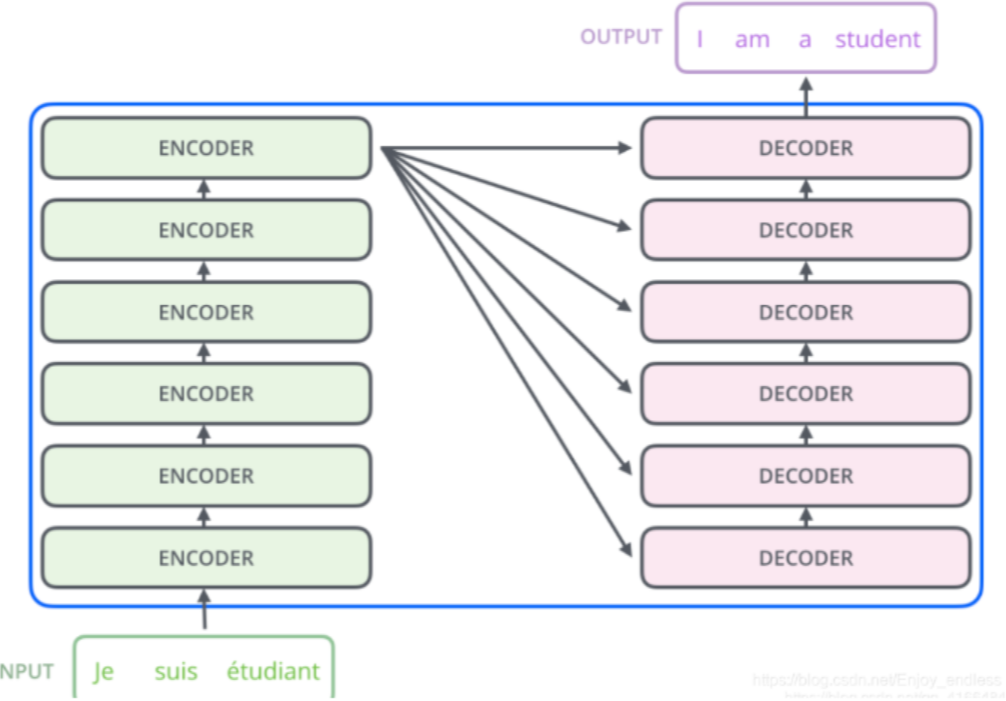
Add & Norm(残差连接和层归一化)
LayerNorm 和 BatchNorm

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)