AI笔记第二节:RNN 循环神经网络
向量的概念:有大小,有方向
向量和矩阵之间有什么关系?当矩阵的行数或列数为 1 时,它可以被视为一个向量。但是向量的定义是有大小和有方向的,一个1行(或者一列)的矩阵,哪来的方向呢?
关键点:
-
向量的定义:在数学中,向量通常被定义为具有大小(长度)和方向的量。在几何中,向量可以用箭头表示,箭头长度表示大小,箭头指向表示方向。
-
向量的分量:在线性代数中,向量通常表示为一个有序列表数字,例如在二维空间中向量可以表示为 (x, y),在三维空间中为 (x, y, z)。这些数字称为分量或坐标。
-
矩阵与向量的关系:矩阵是一个二维数组。当矩阵只有一行时,它被称为行向量;当只有一列时,它被称为列向量。因此,向量可以看作是矩阵的特殊情况。
-
方向的理解:向量的方向是从其分量中推导出来的。例如,在二维空间中,向量 (3, 4) 的大小是 5(通过勾股定理),方向是相对于坐标轴的角度(例如,与x轴夹角为 arctan(4/3))。同样,对于行向量或列向量,方向是通过其分量在空间中的指向来定义的。
如何计算向量的大小:加强版勾股定理:

向量的方向:
例如,考虑一个列向量 [1, 2, 3]^T 在三维空间中。它表示从原点指向点 (1,2,3) 的箭头。这个箭头有明确的方向:它在x轴方向有1单位,y轴方向有2单位,z轴方向有3单位。方向可以通过方向余弦或与各轴的角度来计算。
余弦相似度
余弦相似度通过测量两个向量在方向上的差异,来评估它们之间的相似性。它关注的是方向,而不是绝对距离。
公式如下:

向量的点积,向量的模,向量的范数?
1、向量的点积
-
向量的点积,也叫数量积或内积,是一种将两个向量映射到一个标量(一个数字)的运算。
-
对于两个n维向量a和b,点积定义为对应分量的乘积之和。点积的结果是一个标量。
公式:a · b = a1b1 + a2b2 + … + an*bn -
如果 θ 是向量 a 和 b 之间的夹角,那么它们的点积也可以定义为:
a · b = ||a|| ||b|| cos(θ) 【就是余弦相似度公式的变形而已】
这里 ||a|| 和 ||b|| 分别表示向量 a 和 b 的模(长度)。 -
从这个几何定义可以推导出:
当两个向量方向相同时(θ=0°,cosθ=1),点积最大,为 ||a|| ||b||
当两个向量垂直时(θ=90°,cosθ=0),点积为 0
当两个向量方向相反时(θ=180°,cosθ=-1),点积最小,为 -||a|| ||b|| -
主要用途:投影计算:一个向量在另一个向量方向上的投影长度
机器学习中的应用:计算特征之间的相关性、神经网络的加权求和等
2、向量的模
向量的模就是向量的长度或大小。计算方法就是加强版勾股定理。

3、向量的范数:
范数是模的推广。当我们说“模”时,通常特指L2范数(即加长版勾股定理)。 而“范数”是一个更广泛的概念,它可以用不同的方式来度量向量的“大小”或“长度”。
简单来说范数包含了L1范数和L2范数。L1范数:

范数的主要作用就是正则化,防止过拟合的,这个之前讲过。
文本预处理、向量化,归一化
1、文本预处理
在文本向量化之前,通常需要对文本进行归一化处理,包括:
-
转换为小写:将文本中的所有字母转换为小写,避免同一单词因大小写不同而被视为两个词。
-
去除标点符号:移除文本中的标点符号。
-
去除停用词:移除常见的、对文本意义不大的词(如“的”、“是”、“在”等)。
-
词干提取(Stemming):将单词还原为词干形式,例如“running”变为“run”。
-
词形还原(Lemmatization):将单词还原为词典中的基础形式( lemma),例如“better”变为“good”。
2、文本向量化
文本向量化是指将非结构化的文本数据(单词、句子、文档)转换为计算机能够理解和处理的数值向量的过程。由于机器学习模型只能处理数字,而不能直接理解文字,因此文本向量化是构建任何文本AI应用的第一步。
想象一下,如果我们直接给计算机输入"猫"和"狗"这两个词,它无法理解它们的关系。但如果我们把它们转换为向量:
-
“猫” → [0.9, 0.2, 0.1]
-
“狗” → [0.8, 0.3, 0.1]
计算机就能通过计算向量之间的相似度来判断"猫"和"狗"的相似程度远大于"猫"和"汽车"的相似程度。
主要的文本向量化方法
有非常多,这里就介绍一个基于预测的方法(词嵌入):
Word2Vec:通过神经网络学习词的分布式表示,语义相似的词在向量空间中的位置也相近
经典例子:vec(“国王”) - vec(“男人”) + vec(“女人”) ≈ vec(“女王”)
3、归一化
归一化是将数据按比例缩放,使之落入一个特定的区间(通常是[0,1]或[-1,1])
为什么需要归一化?
考虑一个简单的例子:用身高(cm)和体重(kg)来预测健康指数
-
身高数据范围:150-200
-
体重数据范围:40-120
如果不归一化,身高的数值范围远小于体重,模型可能会给体重特征分配过高的权重。
主要的归一化方法
1. 最小-最大归一化
公式:X_normalized = (X - X_min) / (X_max - X_min)
将数据缩放到[0,1]区间
例子:将考试成绩[60, 75, 90, 85]归一化
最小值=60,最大值=90
-
60 → (60-60)/(90-60) = 0
-
75 → (75-60)/30 = 0.5
-
90 → (90-60)/30 = 1
-
85 → (85-60)/30 ≈ 0.83
- Z-score标准化
公式:X_normalized = (X - μ) / σ (μ是均值,σ是标准差)
将数据转换为均值为0,标准差为1的分布
例子:数据[1, 2, 3, 4, 5]
均值μ=3,标准差σ≈1.58
1 → (1-3)/1.58 ≈ -1.26
3 → (3-3)/1.58 = 0
5 → (5-3)/1.58 ≈ 1.26
3. L2归一化(向量单位化)
将向量的每个内容除以其L2范数,使向量的长度为1
例子:向量[3, 4]
L2范数 = √(3²+4²) = 5
归一化后:[3/5, 4/5] = [0.6, 0.8]
验证:√(0.6²+0.8²) = √(0.36+0.64) = √1 = 1
L2归一化挺好理解哈,就是相当于缩放一个向量,让其保留方向的同时,将它的模缩放成相同大小,也就是1,变成单位向量了
词向量,嵌入矩阵,潜空间
1、词向量
2、嵌入矩阵
通过词嵌入的方式可以得到一个合理的词向量,一大堆这样的词向量拼接成的矩阵,就叫做【嵌入矩阵】
嵌入矩阵是一个别人已经造好的轮子!别人使用 Word2Vec、GloVe 等算法在大规模语料上给你训练好了,你只需要加载使用就行了!
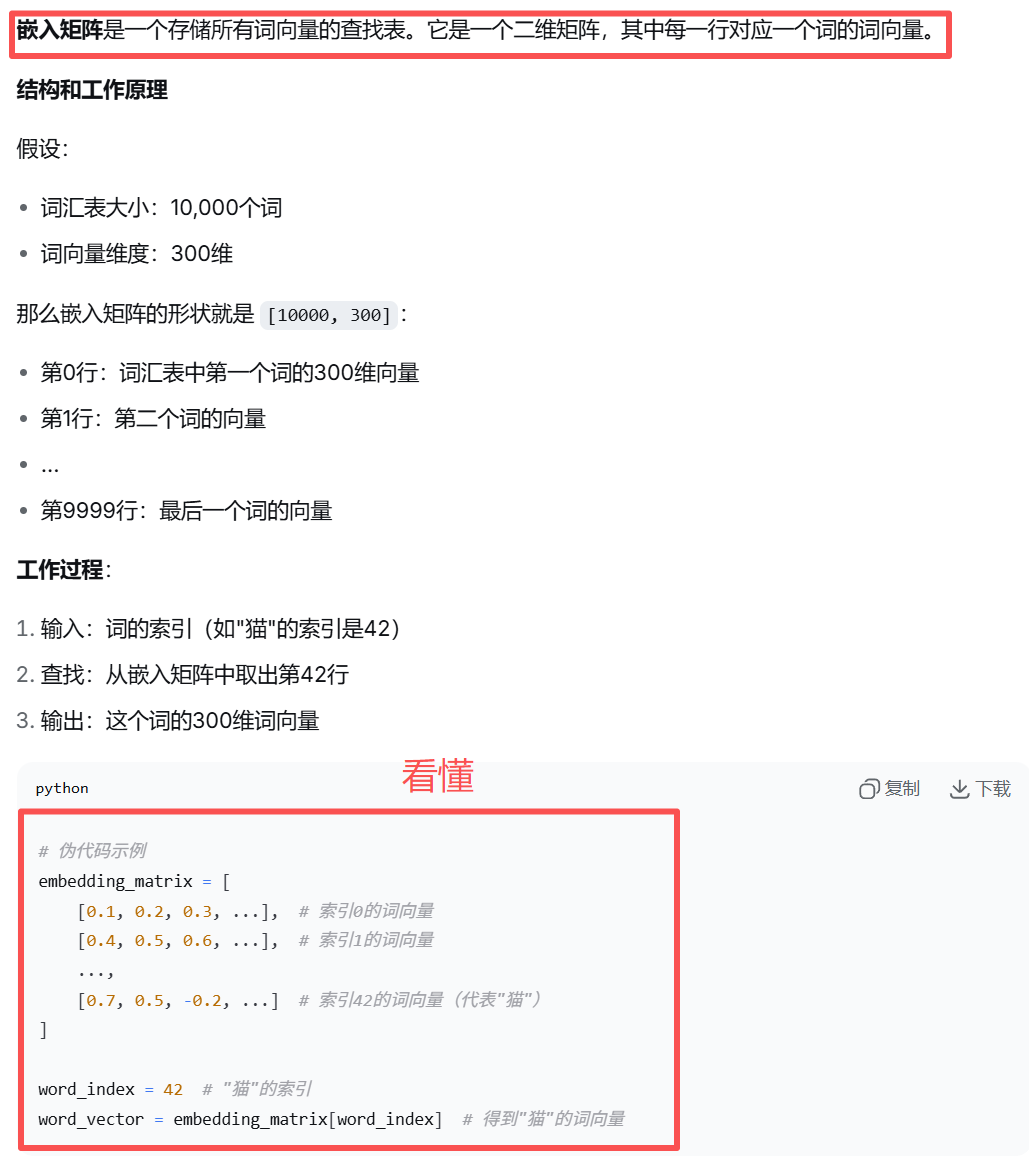
如何找两个词之间的相关性?
只需要把这两个词,从词向量中拿出来,拿出来这两个词向量之后,计算其余弦相似度,就能得到相关性。
(直接用点积其实也能算出来相似度。)

这就将两个词汇自然语言之间的联系,转化为了可以用数学公式计算出来的方式!!!
潜空间:有了嵌入矩阵就自动有潜空间了
通过训练(如Word2Vec、GloVe或Transformer),我们学习到一个嵌入矩阵。当所有词都被映射为向量后,它们共同存在于一个向量空间中,这就是我们的词向量潜空间。
原始数据空间(高维稀疏)
原始空间 = [0, 0, 1, 0, 0, 0, 0, 0, 0, 0, …] # one-hot编码,10000维
潜空间(低维稠密)
潜空间 = [0.7, 0.2, -0.1, 0.5, 0.3, …] # 300维
从高维稀疏到低维稠密,比如从one-hot编码,到Word2Vec处理过的词向量,这个词向量就是潜空间。现在大模型的潜空间还有归类特性:语义相似的词在向量空间中自动聚集
定义:潜空间是一个低维的、压缩的表示空间,其中数据的重要特征和模式被编码。它捕捉了数据的"本质",去除了噪声和冗余信息。
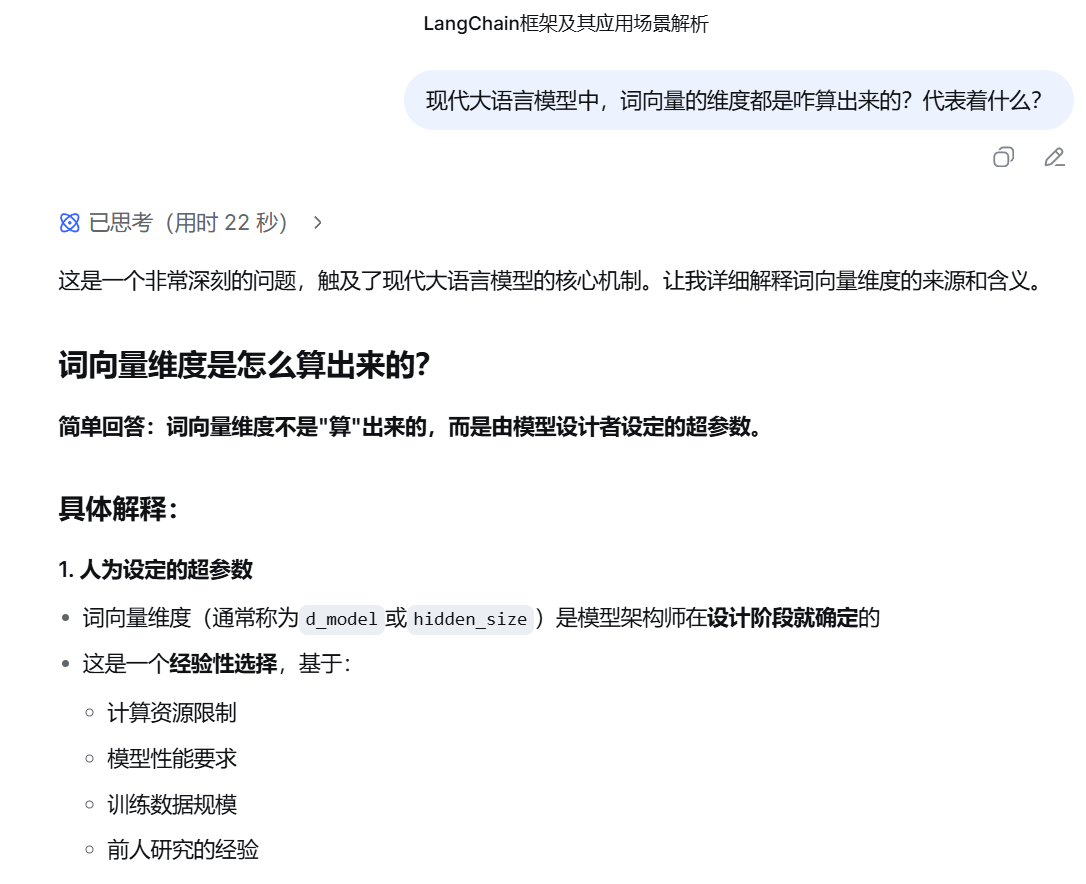
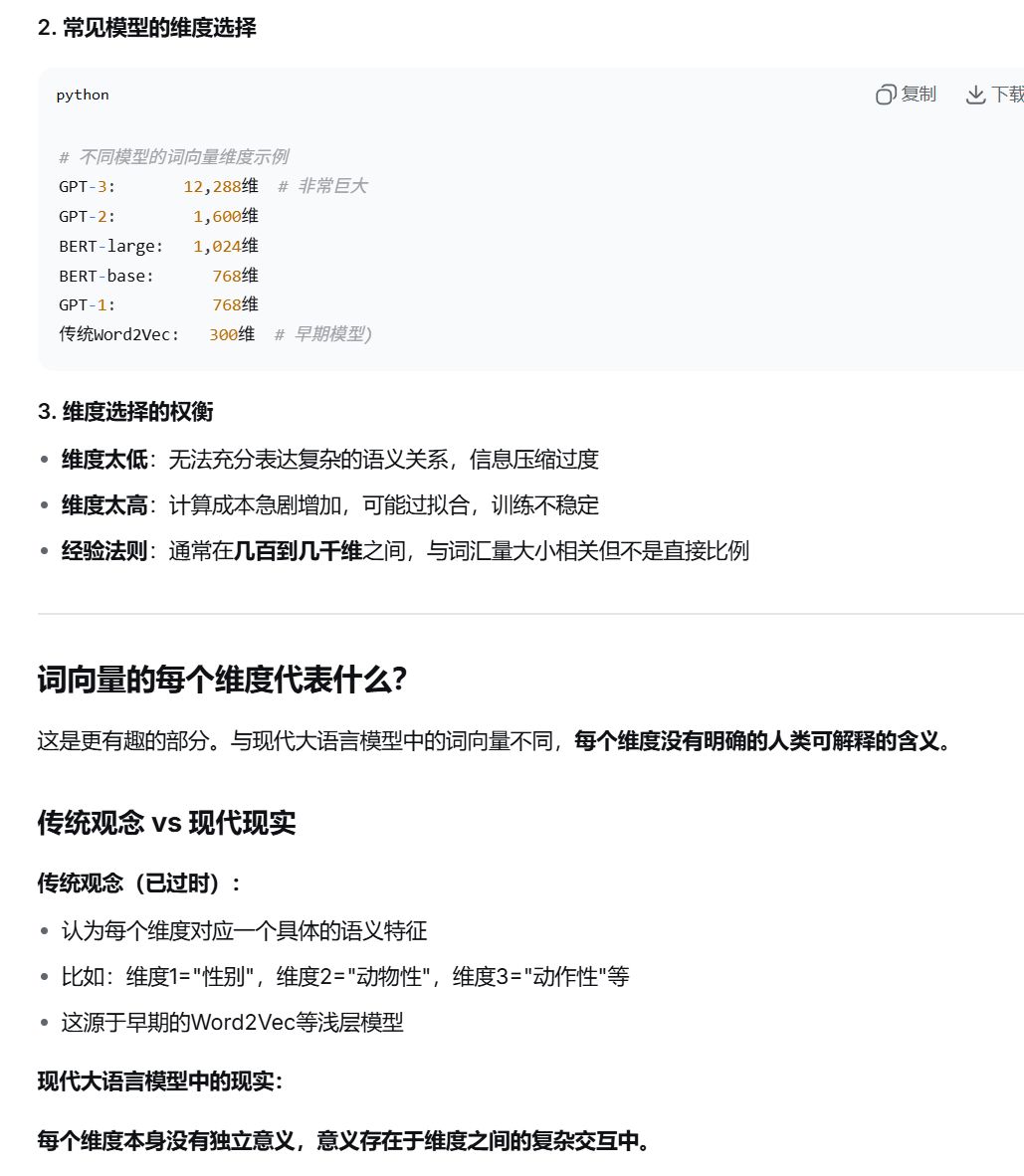
词向量的维度
词向量的每个维度并不直接对应人类可理解的语义特征(如“性别”、“时态”等)。 虽然早期的一些工作(如Word2Vec)试图解释每个维度的含义,但实际上,由于词向量是通过复杂的非线性模型学习得到的,每个维度可能代表一种混合的特征。
在深度学习中,词向量的每个维度是模型自动学习出来的特征,这些特征通常是人类难以直接解释的。



RNN 循环神经网络
实现RNN的前置条件:
每个词都可以编码成向量,然后送到神经网络输入端的神经元中了。
定义
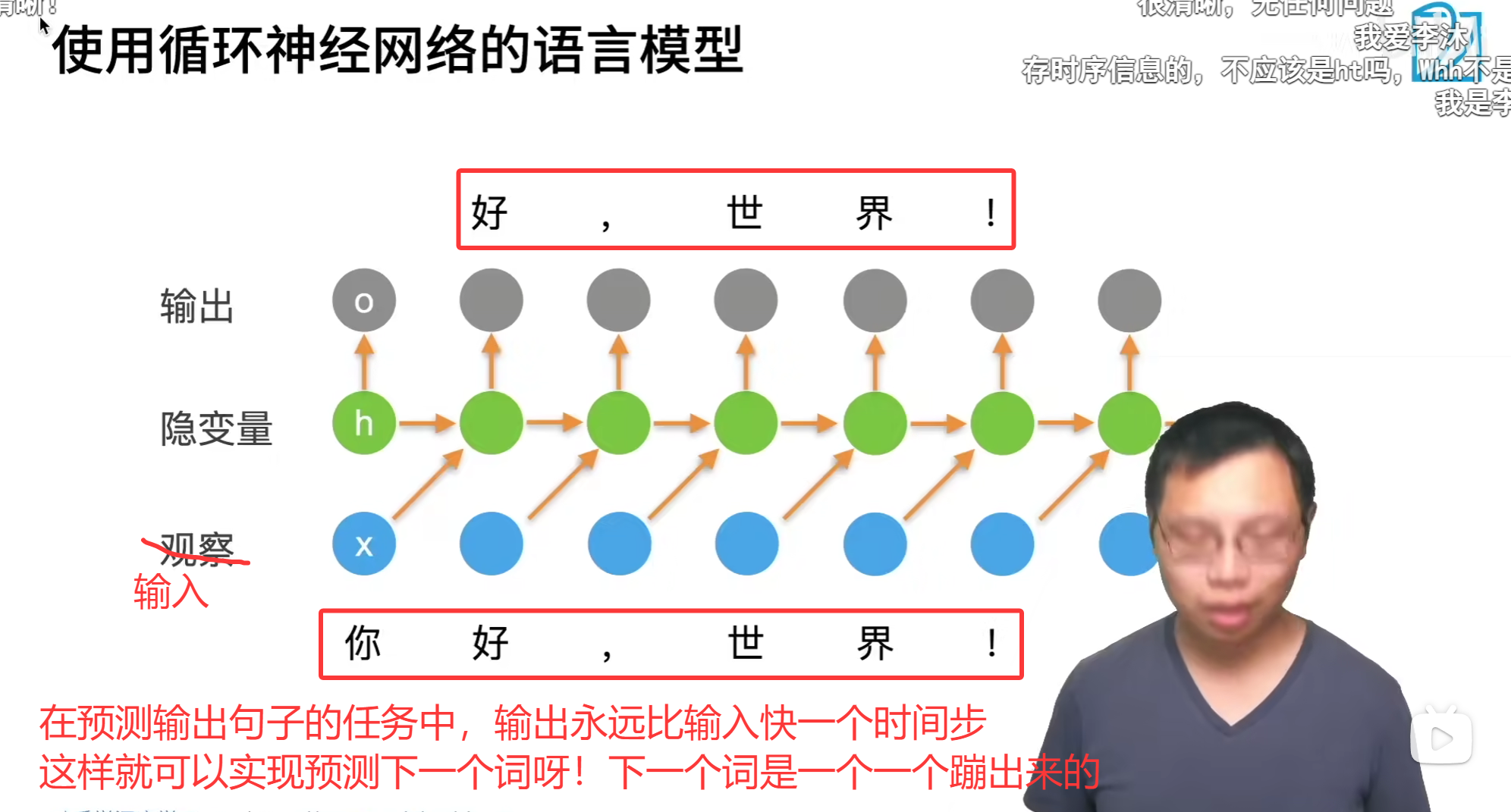
RNN(Recurrent Neural Network)是一类用于处理序列数据的神经网络。与普通的前馈神经网络不同,RNN具有循环连接,使得网络能够保持对之前信息的记忆。这意味着RNN能够利用序列中的历史信息来影响当前的输出。
循环神经网络可以理解词和词之间相互顺序的能力。
RNN的前置概念
时间步
时间步指的是序列模型处理一个输入序列时,每一个独立的、按顺序处理的步骤或位置。
你可以把它想象成 时间上的一个“节拍” 或者 序列中的一个“位置”。
想象你在逐词阅读下面这个句子:
“我” → “爱” → “北京” → “天安门”
这个过程可以分为4步:
-
第1步:你看到 “我”,大脑开始理解。
-
第2步:你看到 “爱”,大脑结合刚才的“我”,理解为“我爱”。
-
第3步:你看到 “北京”,大脑结合“我爱”,理解为“我爱北京”。
-
第4步:你看到 “天安门”,大脑结合“我爱北京”,最终理解整个句子“我爱北京天安门”。
在这个比喻中:
每一个步骤就是一个 时间步。
你阅读的每个词就是在该时间步的 输入。
你大脑中结合了之前所有词的理解就是该时间步的 隐藏状态。
权重矩阵
最简单RNN的应用类比:
输出一句话表达的情感(正面情感、负面情感)
RNN的工作流程
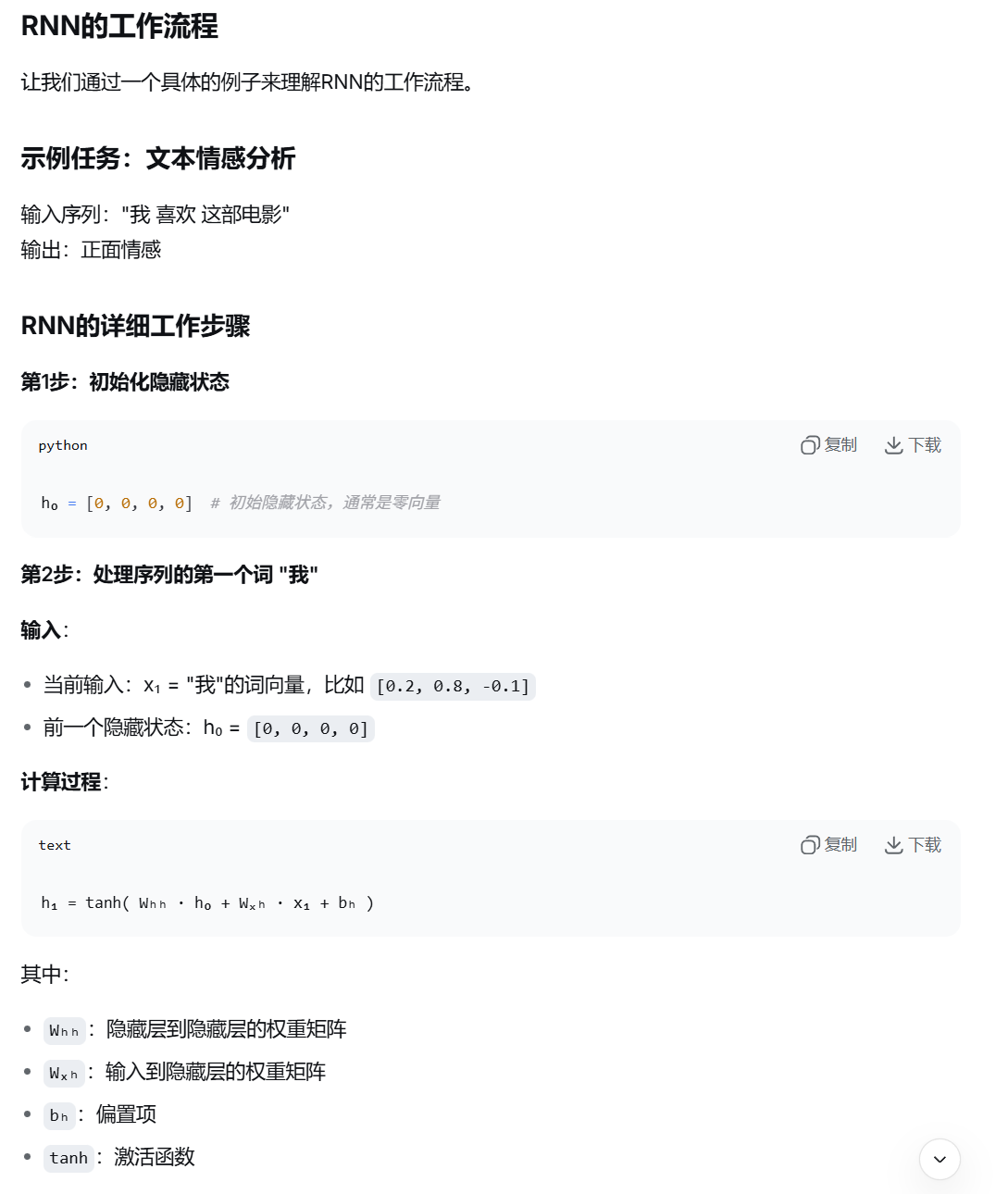

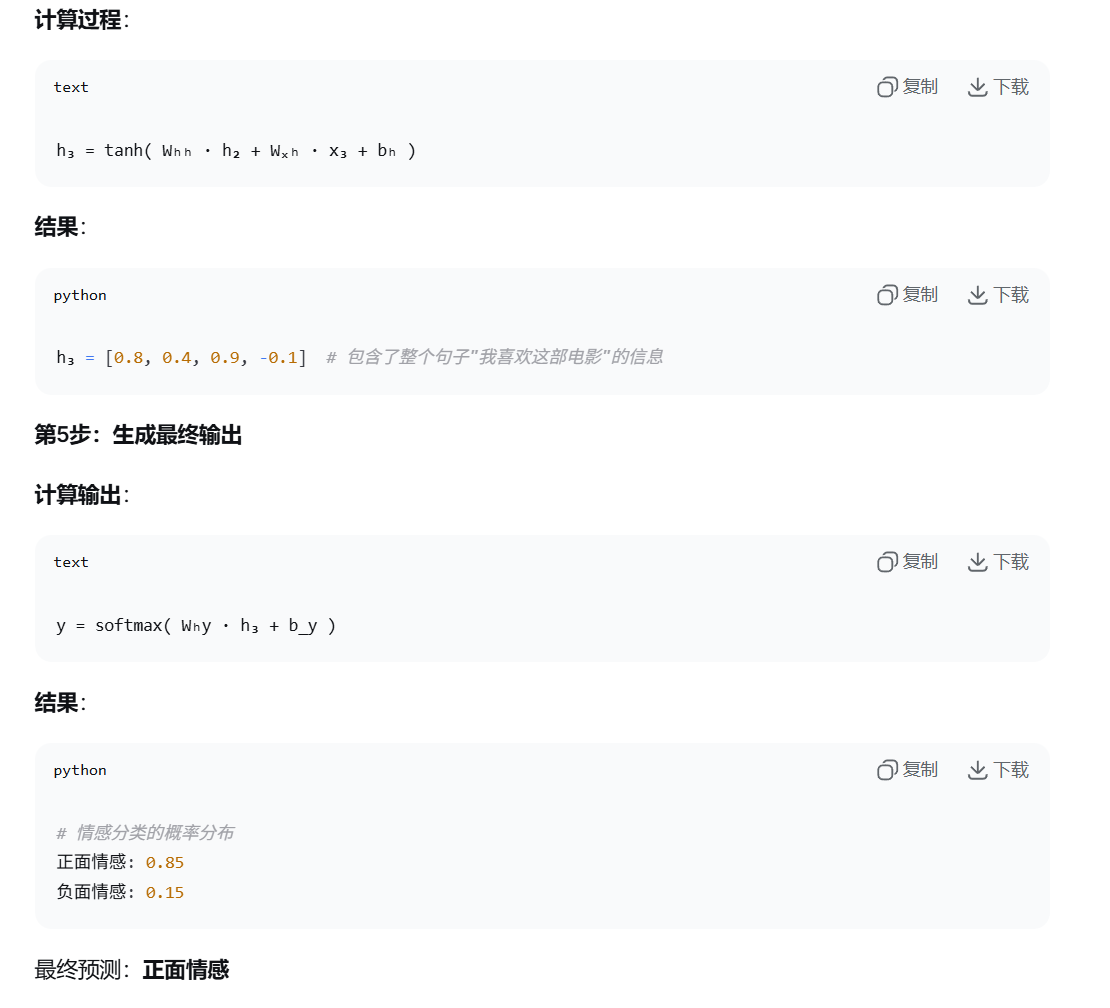
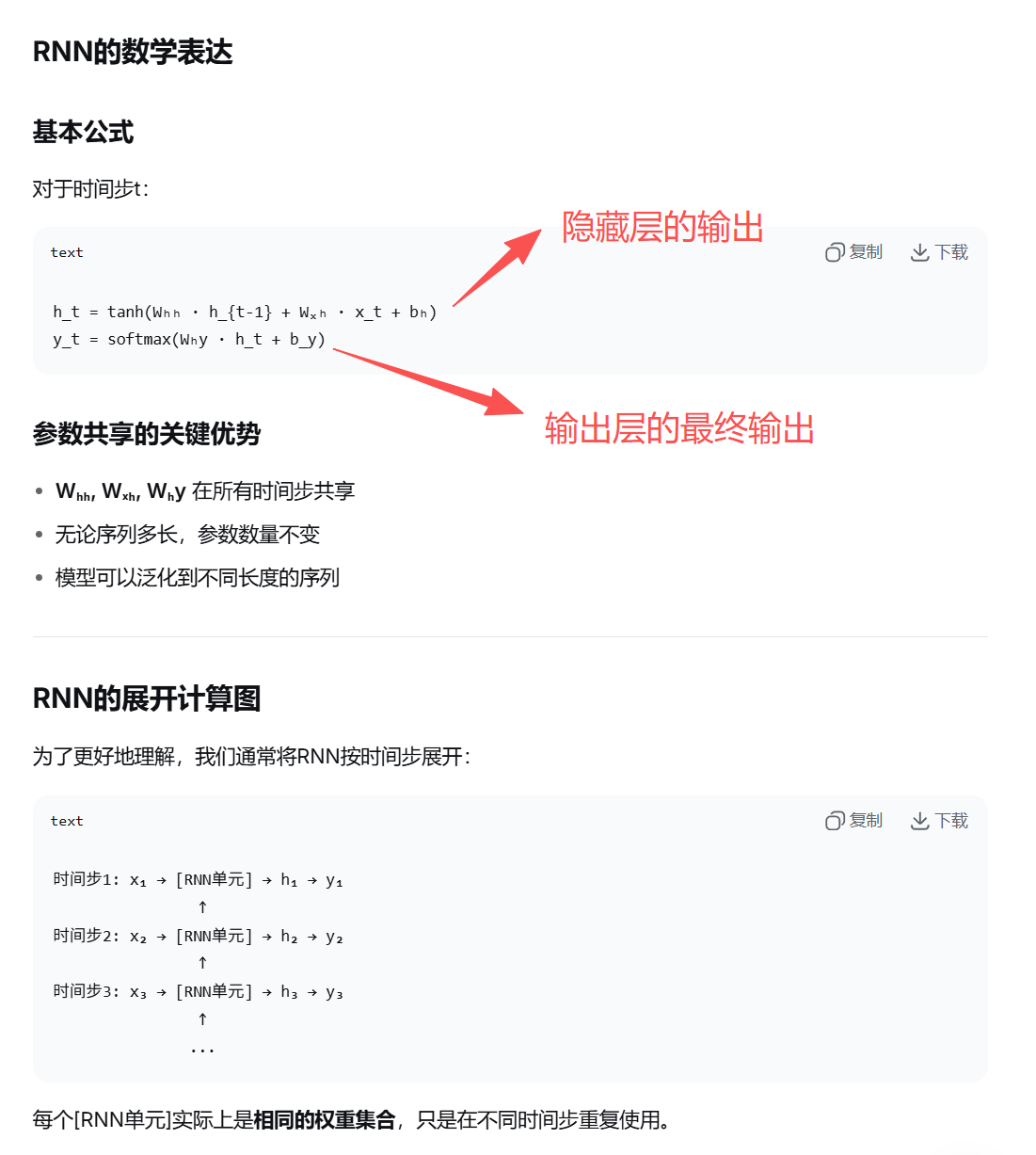
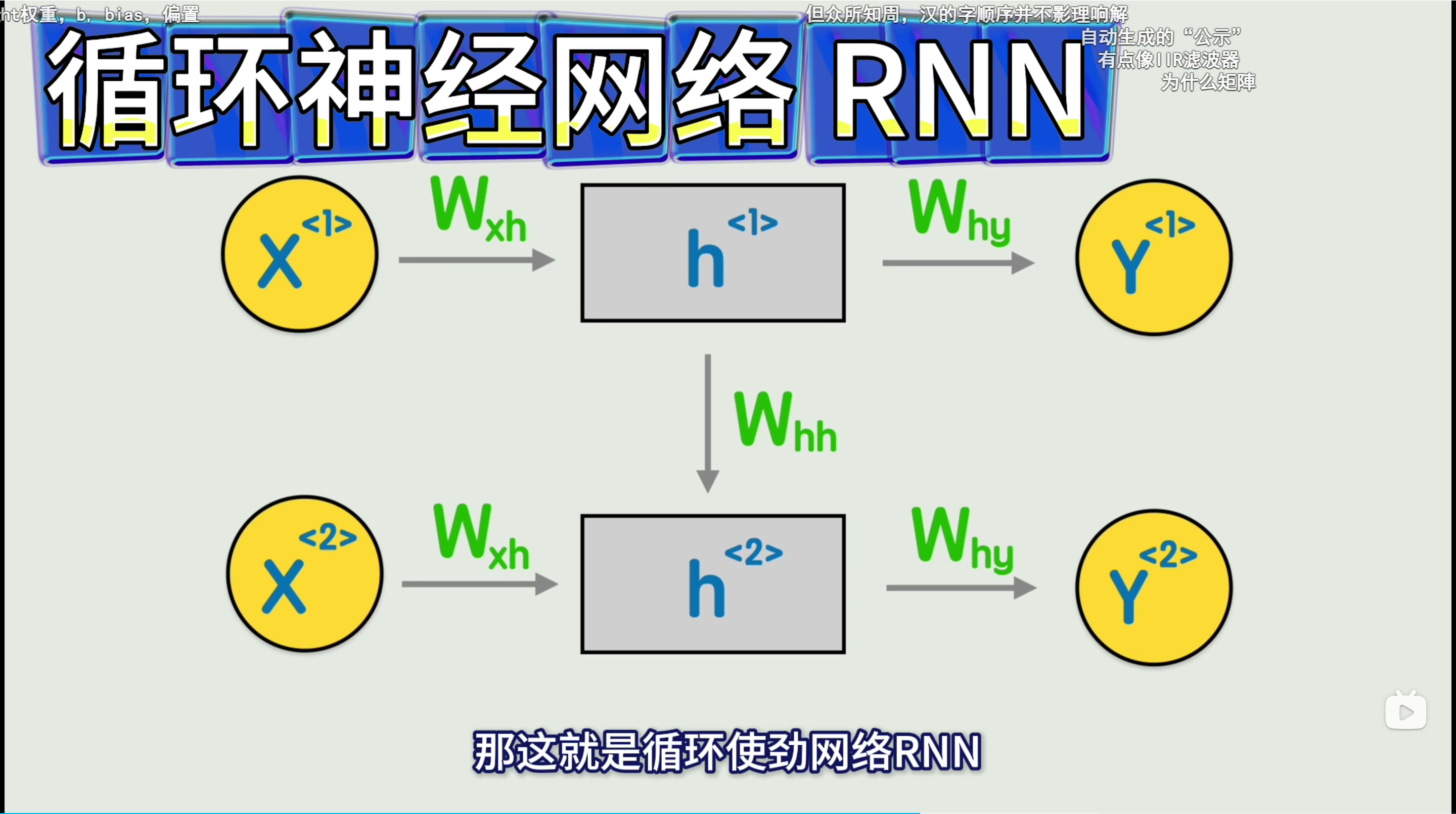
RNN的图例和官方公式
图例1:
更抽象的画法:
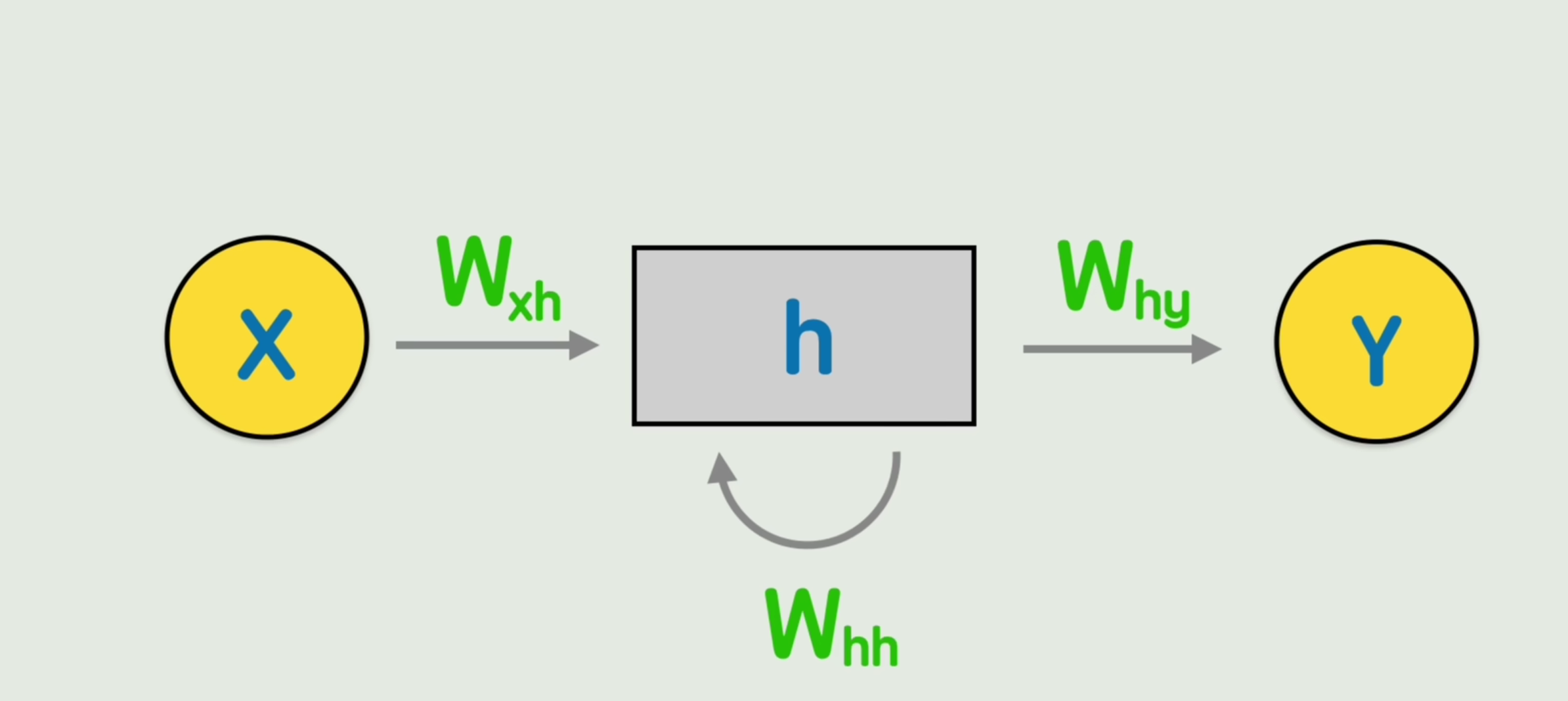

在RNN中,每一层的“权重矩阵”都是咋得出来的?
在RNN中,权重矩阵不是通过公式计算出来的,而是通过训练过程学习出来的。
这点和普通的神经网络非常像,普通神经网络的目标就是通过训练学习得到最佳拟合度的w和b。那么RNN同理呀,一样的道理。
权重矩阵的初始值是随机的(也可能全是0),然后通过反向传播和梯度下降算法,让模型自动学习出最优的权重值。可以看下面的步骤,太简单了:


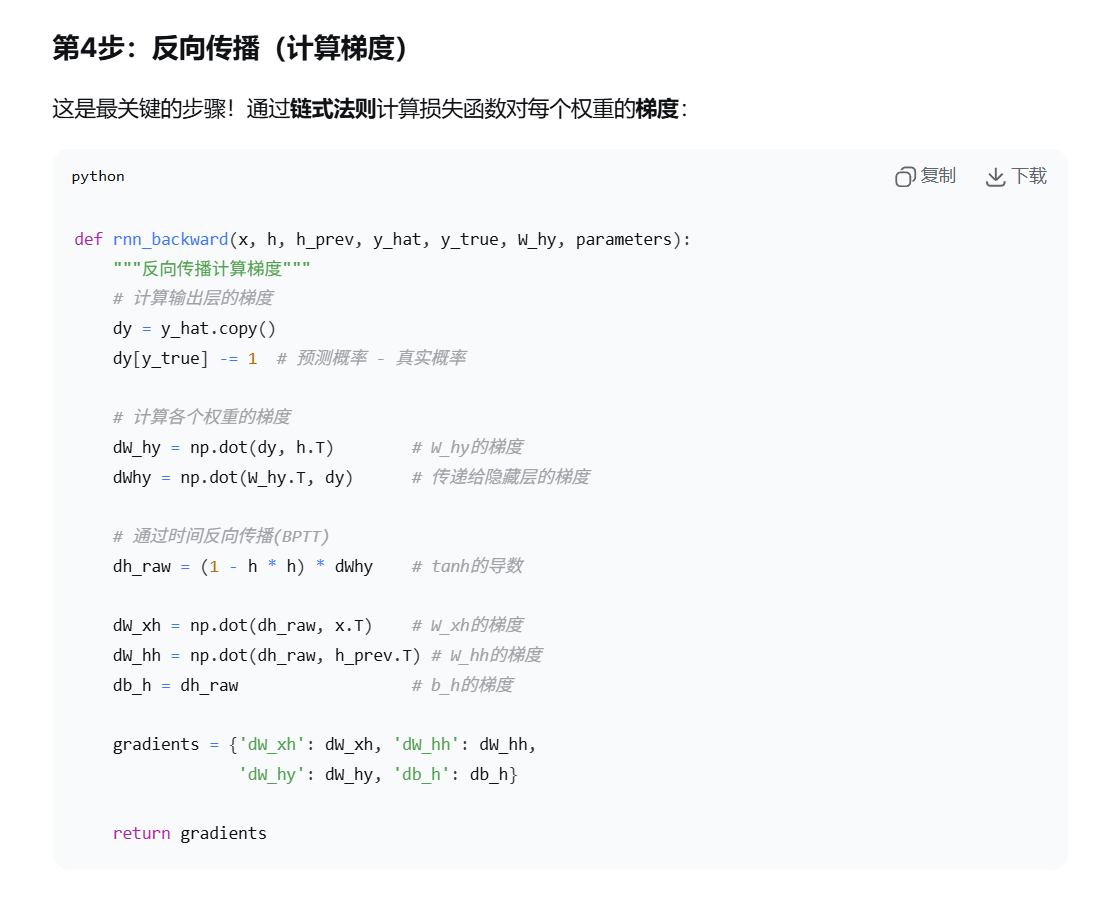


大吉的总结:隐藏状态和一次RNN的训练流程【重要】
h就是隐藏状态
我们需要把隐藏状态+下一个“时间步”的输入 同时作为一个全新的输入,传递到下一个神经节点里面去。
用大白话解释:如果h是第一个词的隐藏状态,当计算到第二个词的时候,要将第二个词的输入和第一个词的隐藏状态加起来,作为一个全新的输入向量;与此同时原有权重矩阵w也要相应扩展(矩阵相乘必须保证行列相等,所以w也要变),这样就可以算出第二个词的h,以此类推。
最终到最后一个结果,通过输出层,再通过输出层的激活函数,最终算出y hat 这个预测值。
算出完成y hat 这个预测值,然后与实际值y对比,产生损失,然后带入损失函数,梯度下降,反向传播,链式法则这一套,把所有的w权重矩阵都给更新了。
这就完成了一次RNN的训练流程。

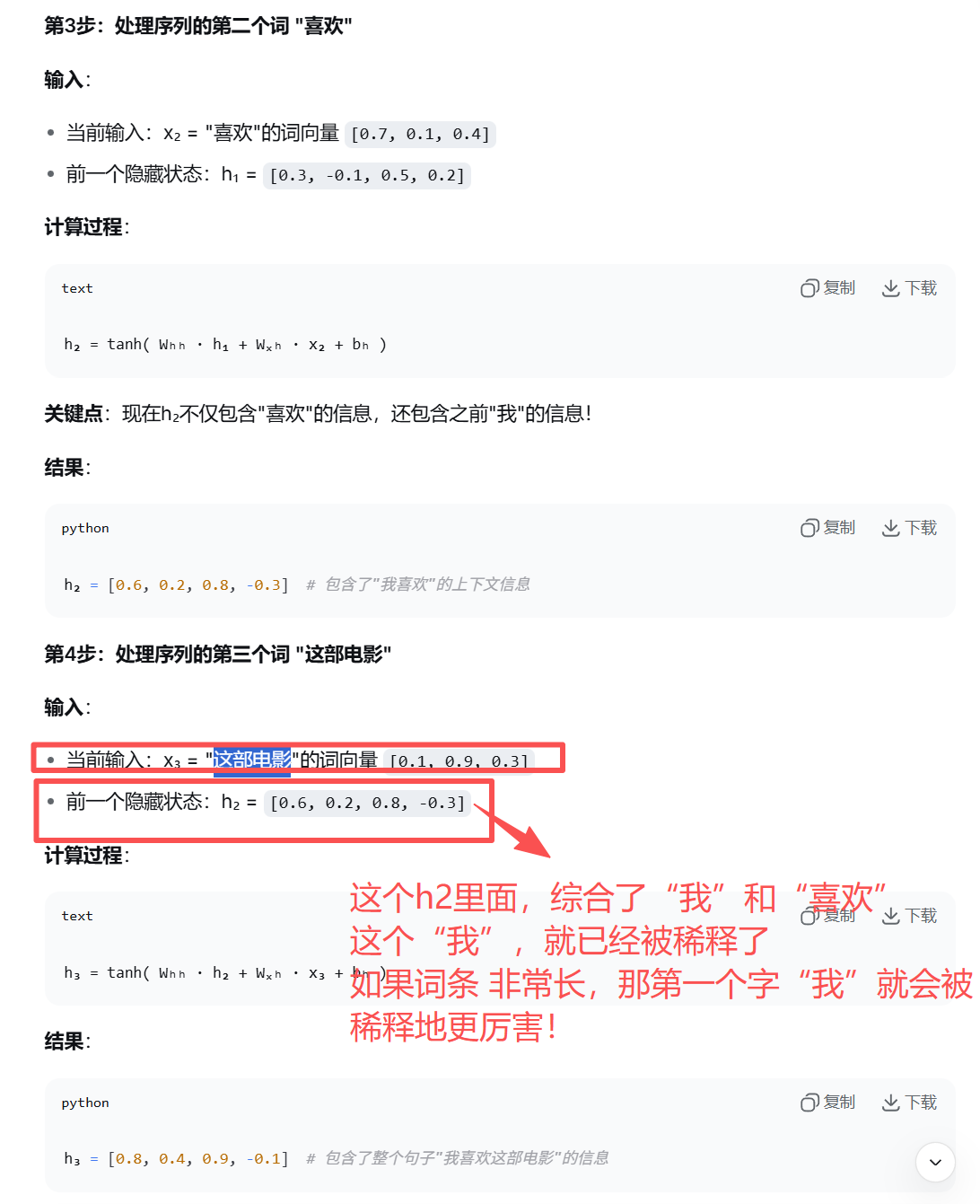
RNN的缺陷:
一:无法捕捉长期依赖
- 信息会随着时间步的增多而逐渐丢失;
- 这个很好理解,早先的信息可能会被稀释掉。
关于稀释的解释:
二:RNN必须顺序处理,无法并行运算。
每个时间步(输入)都依赖上一个时间步的h(结果)
Rnn的编码器-解码器 机制 : seq2seq
https://www.bilibili.com/video/BV16g411L7FG
任务目标
实际应用RNN来机器翻译 : 输入:今天天气很好
输出: Today weather is nice.
编解码器机制的概念
在Transformer出现之前,编码器-解码器架构已经存在,并且通常由循环神经网络(RNN)或其变体(如LSTM、GRU)来实现。
编码器-解码器是一种用于解决序列到序列任务的通用框架。所谓Seq2Seq,就是模型的输入是一个序列,输出是另一个序列。
核心思想:
-
编码器:将输入序列(如一句英文)压缩成一个包含所有重要信息的、固定维度的上下文向量。
-
解码器:根据这个上下文向量,逐步生成输出序列(如对应的中文)。
一个简单的比喻:
想象一个懂多国语言的人在做翻译。
编码器 就像他的听和理解过程:他听完整个英文句子,在脑子里理解了其含义(形成了一个“思想”或“语义”)。
上下文向量 就是他脑子里的那个“思想”。
解码器 就像他的表达和输出过程:他根据这个“思想”,用中文词汇和语法规则,重新组织并说出一句意思相同的中文。
编码器
编码器就是上面学的那个玩意,已经学完编码器了。这里着重讲述解码器。
准备工作:编码器已完成
首先,编码器(一个RNN,如LSTM)已经处理了完整的中文输入序列:
输入序列:[“我”, “今天”, “很”, “开心”]
编码器最终【隐藏状态】 h_enc:这是一个浓缩了整个中文句子语义信息的向量,它将成为解码器的初始状态。
解码器的初始输入:在训练和推理的初始时刻,解码器的输入都是起始符号(Start Of Sequence)。
解码器中,初始【隐藏状态】和【初始输入】不是一个东西!
SoftMax激活函数 - 归一化
Softmax层是神经网络中的一种激活函数,它可以将任意实数向量转换为概率分布。 换句话说,它把一组数字变成一组概率,这些概率之和为1。





解码器的训练流程
训练阶段和推理阶段完全不是一回事;
训练阶段:
Teacher Forcing是一种通过使用真实标签代替预测值来训练序列生成模型的技术,主要用于加速收敛和抑制误差累积。
Teacher Forcing的技术原理
1. 核心定义与数学表达
在序列生成任务(如机器翻译)中,模型训练时使用真实标签 作为当前步骤输入,而非前一步的预测值
该方法通过切断错误传播路径,显著提升训练的稳定性。

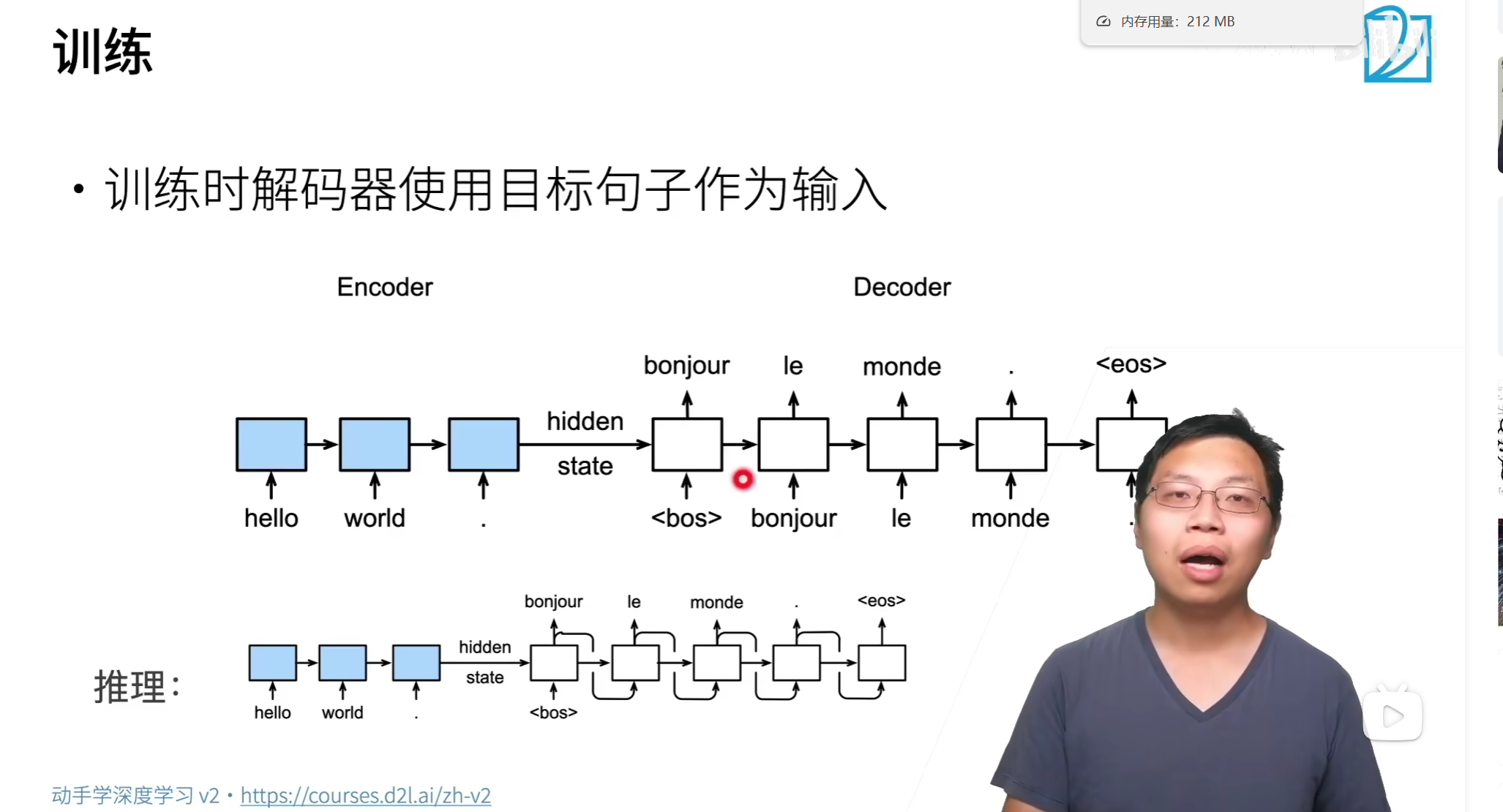
为啥训练时候给真实的结果作为输入?是为了避免“输出一错全错”的情况,方便模型收敛,加快训练,就算有一个错了也没事,后面的对的概率更大。
解码器工作(推理)流程
解码器也是一个RNN,它负责逐词生成英文输出序列。推理过程的核心是自回归生成:解码器使用自己前一步的预测结果作为下一步的输入,逐步构建整个输出序列。
-
解码器初始状态 (s₀) 的来源
是的,解码器的初始状态 s₀ 确实来自编码器的隐藏状态。 -
解码器后续状态 (s₁, s₂, s₃…) 的来源
s₀ = 基于编码器状态初始化
s₁, s₂, s₃… = 基于解码器自身的前一状态 + 当前输入计算得出 -
解码器初始输入的来源:
一般是一个起始符号<bos>begin-of-Sequence ; -
解码器后续输入的来源:
上一个词的预测结果(如果你是训练,那就是)

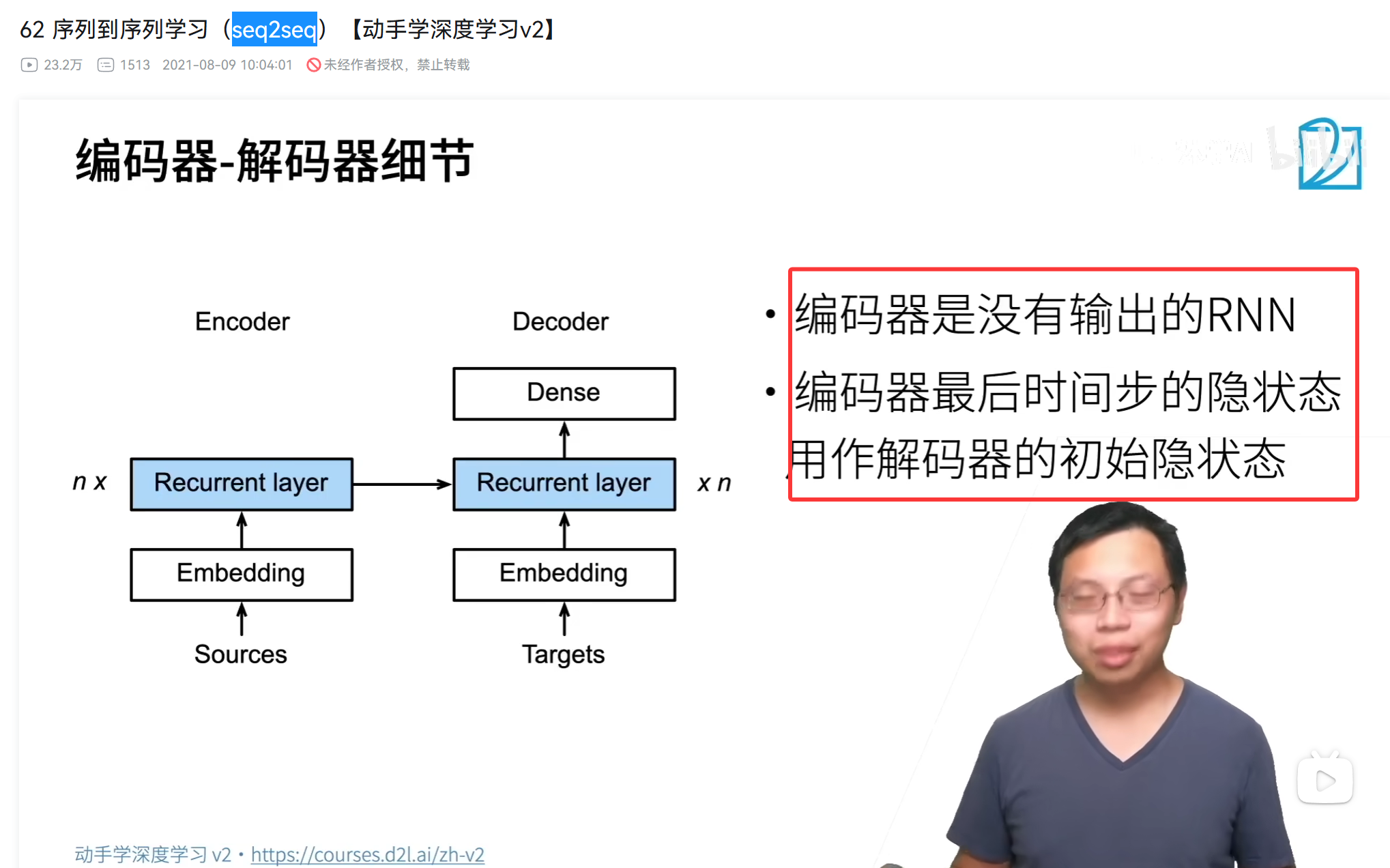
编码器的输入,和解码器的输出,可以不等长!!! 所以我们说这个编码器和解码器还可以做问答模型(QA模型)
直到结束标记 <eos>(end of sequence) 时候才会结束。
比如翻译任务:
从概率分布中选择下一个词的方法
接上图的推理过程: 输出y2,是"t’aime"的概率分布,这个y2应该是一个通过softmax激活函数算出来的矩阵,"t’aime"只是概率最大,我最有可能选择 “t’aime” 而已。选择 “t’aime” 的方法都有什么呢?
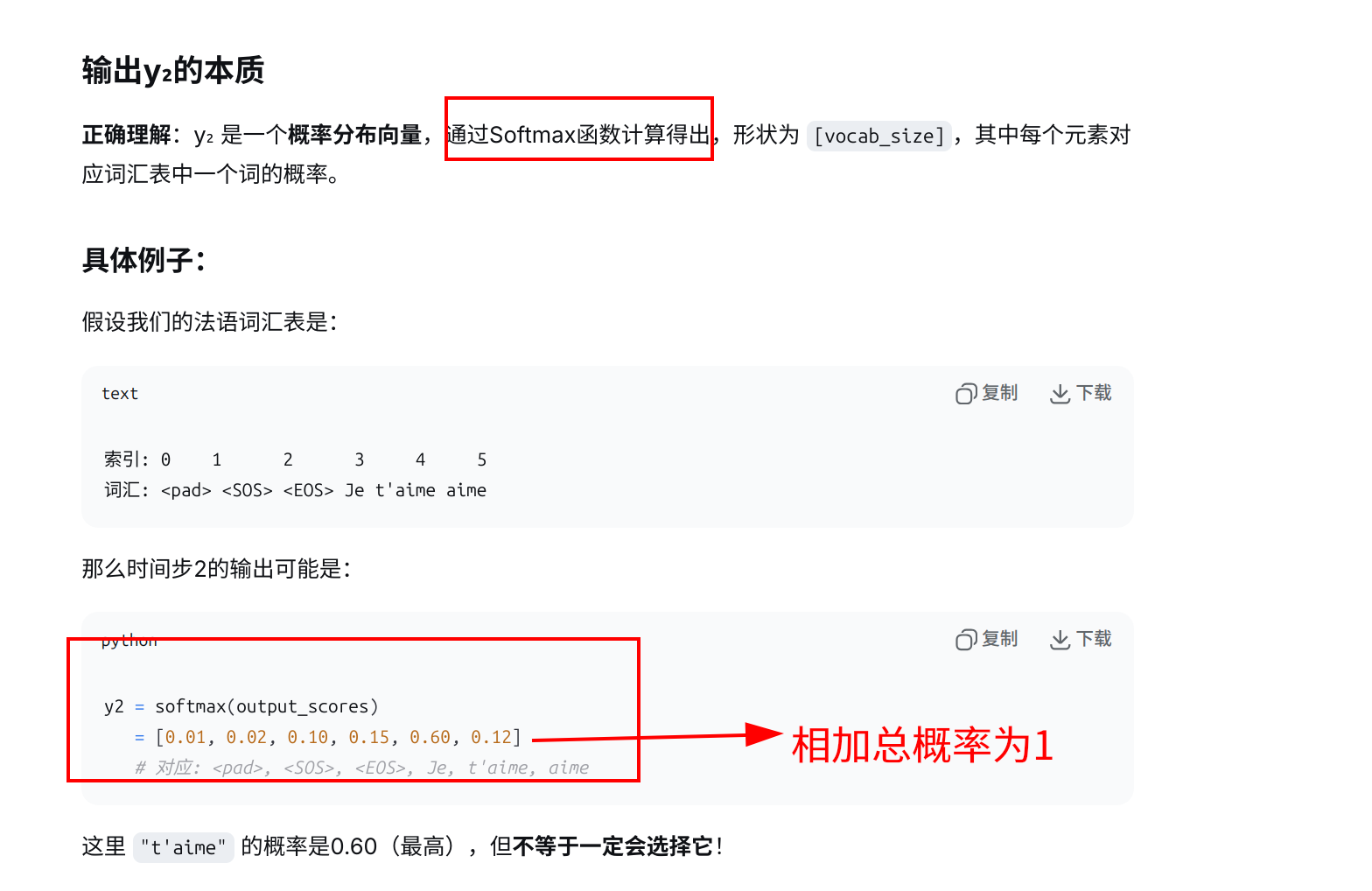
在序列生成任务中,解码器会通过softmax激活函数,在每一步会输出一个大小为V(词汇表大小)的概率分布,然后我们根据这个分布选择下一个词。> 选择的方式主要有:
-
贪婪搜索(Greedy Search)
- 总是选择概率最高的词
- ✅ 简单快速
❌ 容易陷入局部最优,可能错过更好的全局序列
-
束搜索(Beam Search)
- 维护多个候选序列,不是单个词的选择,可以更好兼顾全局上下文
-
随机采样(Sampling)
最终总结:
解码器的工作流程(推理流程)和训练流程,是两码事。
训练阶段使用Teacher Forcing,即每一步的输入是真实目标序列(ground truth)
RNN的典型应用 文本生成任务:预测一句话的下一个词是什么。
案例:
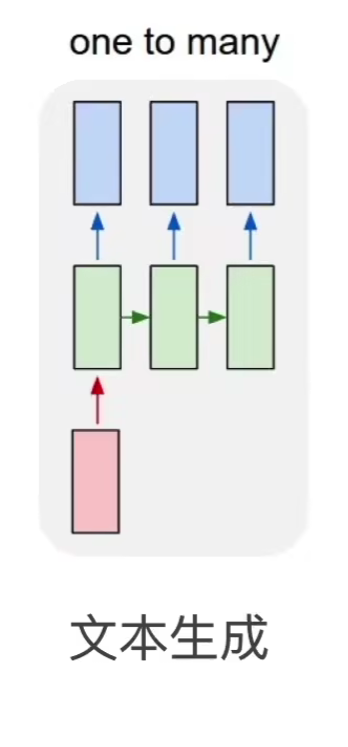
one to many ,指的是一个输入(也可以理解为小部分输入),能够预测出来很大一坨输出。
典型应用2: 文本分类(认猫也算这个应用)
输入一篇文章或是一句话,只输出一个标签,说明这篇文章属于什么类别:
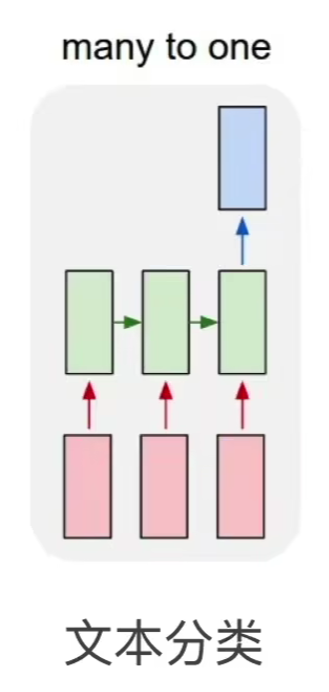
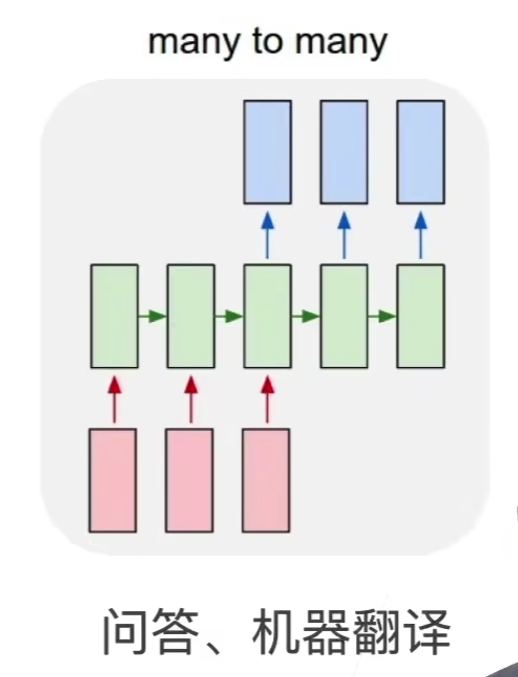
只有这种 many to many 的任务,会用到编码器-解码器:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)