AI笔记第一节:基础部分(向量、余弦相似度、神经网络)
不用学的知识点
SVM支持向量机;knn算法
一、前置知识点
向量,向量的模,归一化
余弦相似度
置信度、置信区间
神经、神经网络
sigmod、反向传播
自注意力机制,多头注意力
Transformer解决的问题
解决RNN,CNN的问题,提升速度。
MOE 混合专家系统
Transformer代码讲解
有空复现一下。
提示词
32比特的模型到8比特,量化与压缩技术
基于人类反馈的强化学习
NLP 自然语言处理
多模态
不仅仅是NLP任务,GPT,DS,都是大语言模型+ 多模态
神经网络的底层全部都是矩阵相乘。
举例:
正向传播、反向传播、损失函数
attention is all you need
https://arxiv.org/abs/1706.03762v7
回归
统计学中的重要概念,基于历史数据,来预测未来的值
【重要,需理解】最小二乘法
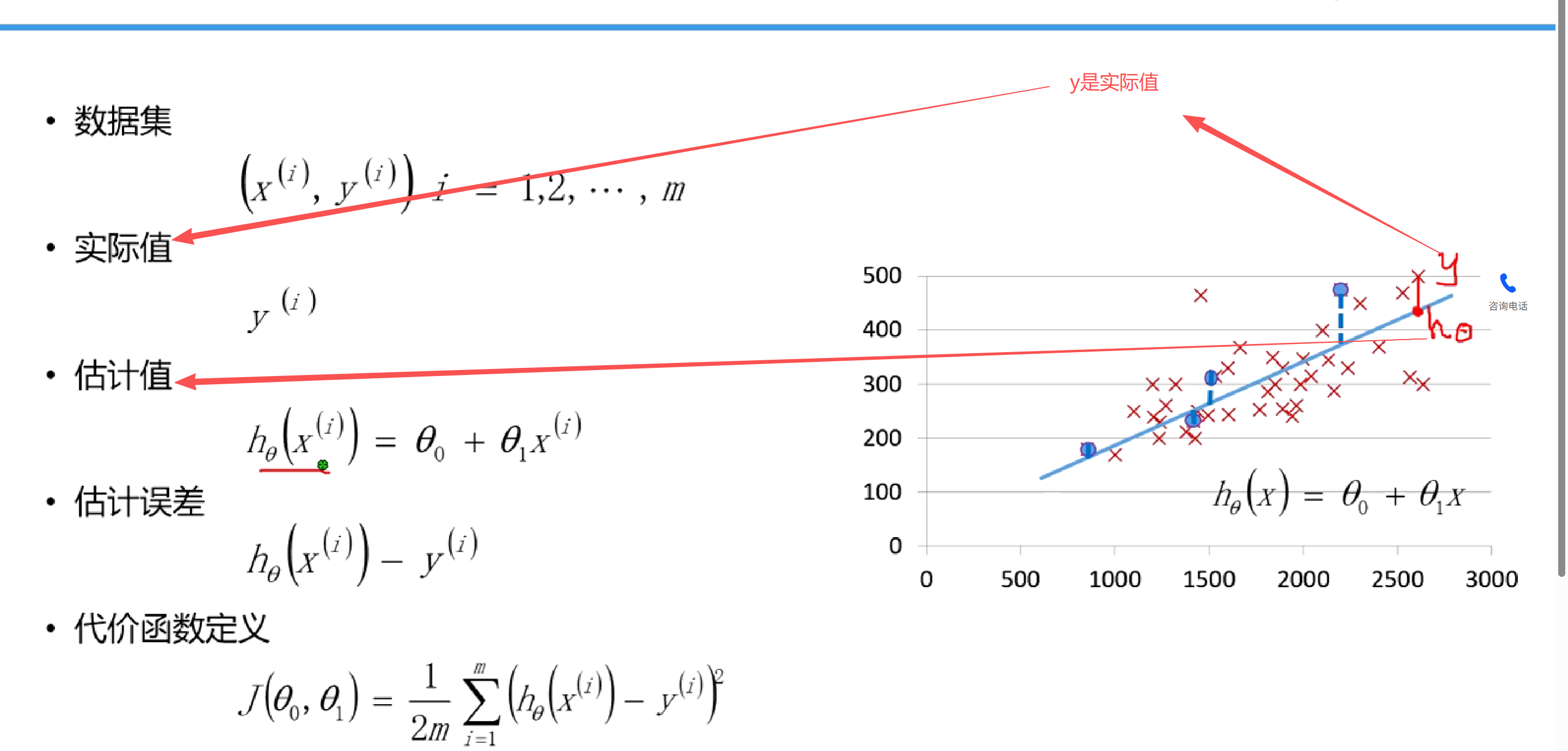
此图图例:红色叉是实际值,蓝色的线是预测曲线。
-
y和hθ 之间的那个玩意就是误差。
-
啥是最小二乘法,就是那个代价函数定义。代价函数定义公式,就是一大堆红色叉叉(图中的红色叉叉代表实际值)和hθ 之间的差值(误差),再来一个平方(所以叫最小二乘法,最小二乘就是最小平方),所有的误差值加总,就是那个西格玛求和符号,最后在除以m,m是m个红色叉叉的意思,意思就是取得一个平均值。
-
应该能讲清楚了。
-
将所有样本的误差的平方,求平均值。
-
根据这个公式算出来的代价值最终算出来越小,模型越好,说明误差越小。(模型就是蓝色线预测曲线)
代价值最终会组成代价函数,代价函数见下个部分有详细解释
看完上面这个,再看deepseek给出来的基础定义:


代价函数和梯度下降
接最小二乘法的例子。下面的左图:左图的x代表真实值,右边三条线代表三种预测线。根据最小二乘法,算出三种预测线的代价值。其中:
- 黄线的代价值是2多一点
- 红线的代价值是0
- 橙色线的代价值是十二分之七。
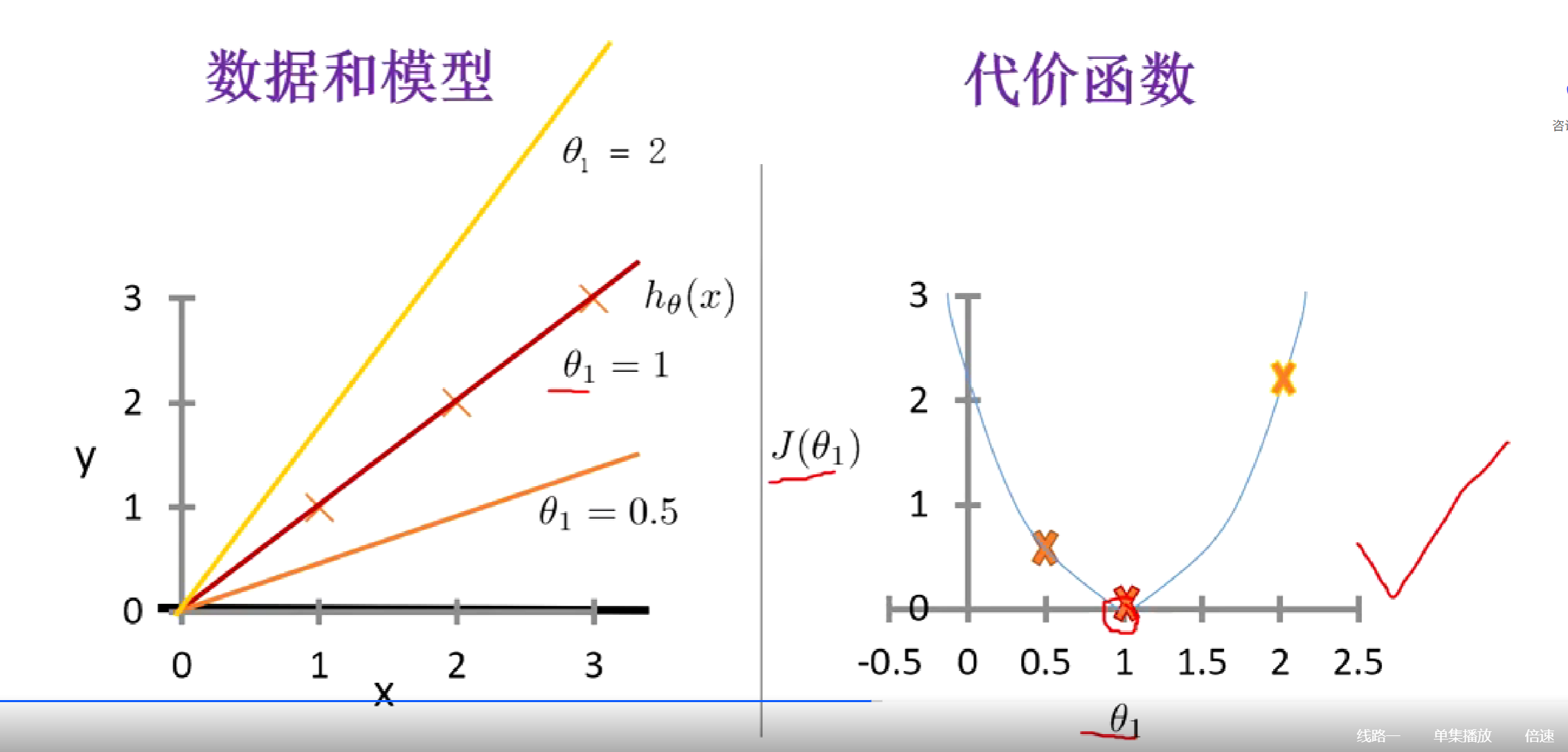
将三种线的代价值画在右图,右图就是代价函数。
代价函数的纵坐标很好理解,就是左图的那个代价值(也可以称作误差、损失值,预测值和真实值的误差大小,也可以称作 惩罚)。代价函数的横坐标是左边预测线的斜率(横坐标也可以叫 参数。也就是w weight 权重)。
代价函数在某点上的导数/偏导数 的实际意义,其实是损失函数的变化率(优化方向)。对于x的导数(偏导数),也就是指 最初始的 权重参数w 对于整个损失函数的变化快慢,和优化方向。
简单来说,导数的核心用途是描述一个东西变化的“快慢”和“方向”。就像汽车的时速表告诉你速度(距离变化的快慢)一样,导数告诉你函数值变化的“速率”。
左边三条预测线的斜率分别为:
- θ黄:y=2x ,斜率为2
- θ红:y=x,斜率为1
- θ橙:y=0.5x,斜率为0.5
因此,横纵坐标都知道了,可以绘制出来右图代价函数。
右图代价函数如果有更多的预测值,我们可以得出来一个预测曲线,类似于一个抛物线,这个玩意就是代价函数。代价函数的最小值是最好的(预测效果最好)。右图这个代价函数,当在抛物线最底端的时候,预测效果是最好的。(此时这个点的导数是0。因为求抛物线上某一点的切线斜率,实际上就是计算该点的导数。这是因为在微积分中,导数的几何意义就是函数曲线在某一点处的切线斜率。)
咱们求最小值的这样一个过程,在机器学习过程中,叫做【梯度下降】
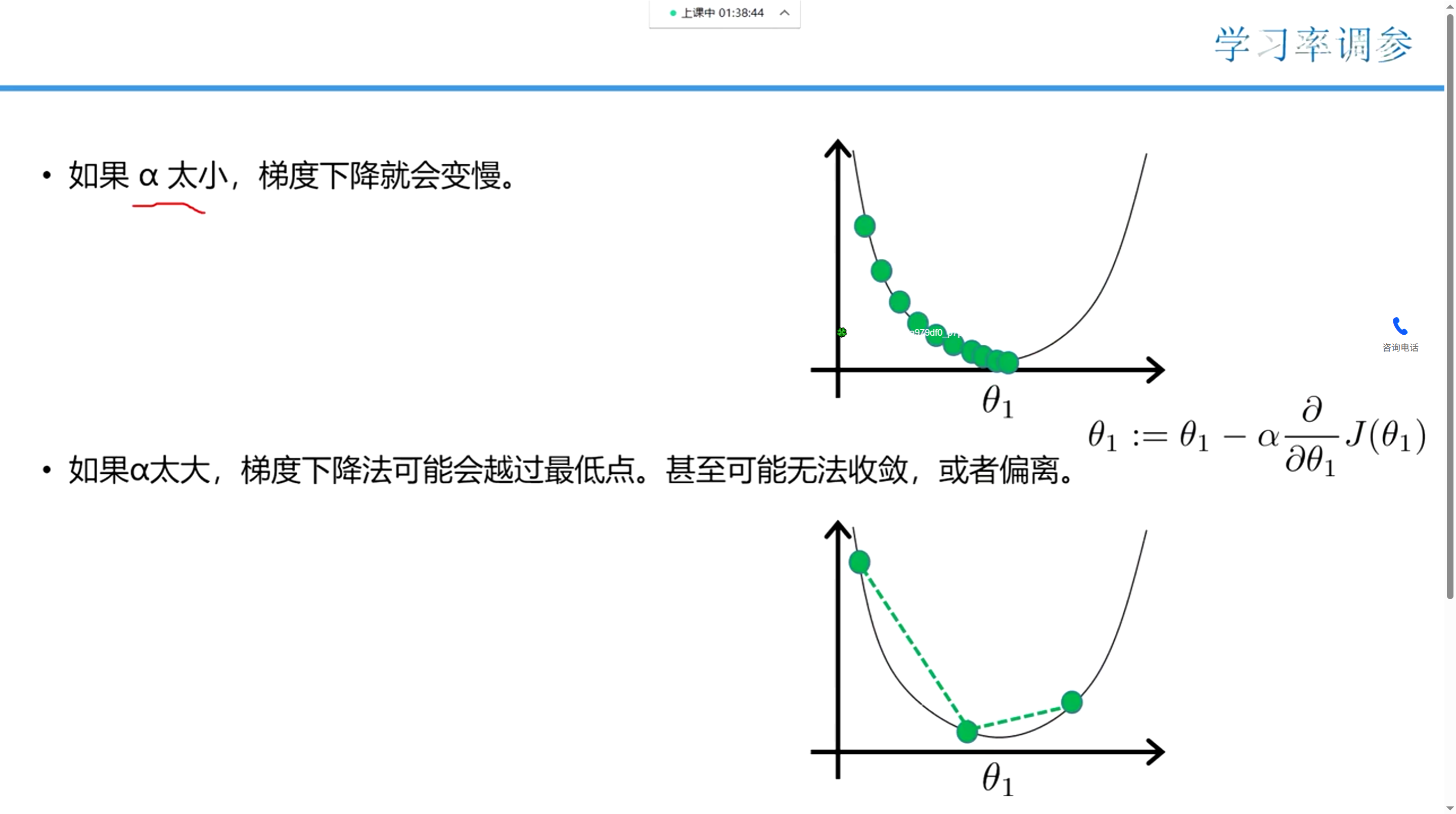
梯度下降的阿尔法,决定梯度下降的速度(这玩意也叫学习率)
导数有什么实际用处?
导数绝不仅仅是教科书里的一个数学符号,它是理解和分析“变化”的强大工具,其应用遍布科学、工程、经济学和我们的日常生活。
简单来说,导数的核心用途是描述一个东西变化的“快慢”和“方向”。就像汽车的时速表告诉你速度(距离变化的快慢)一样,导数告诉你函数值变化的“速率”。
以下是导数的一些主要用途,从直观到抽象:
- 几何学:求切线斜率
这是导数最直接的定义。
有什么用:有了切线斜率,我们就能知道曲线在某一点的精确变化趋势。
例子:在物理学中,抛体运动的轨迹是抛物线。我们可以通过求导来精确计算在某个时刻,物体的运动方向(即轨迹切线的方向)。
- 物理学:求瞬时变化率
物理学是研究变化的科学,导数是其天然的语言。
位移的导数 = 瞬时速度
速度的导数 = 瞬时加速度
质量的导数 = 流量(例如,水龙头流水的速率)
例子:当你开车时,时速表上瞬间跳动的数字,就是你的位移对时间的导数(瞬时速度)。
- 工程与优化:寻找最优解(极大值和极小值)
这是导数在现实世界中最重要、最广泛的应用之一。
原理:当一个函数达到最大值或最小值时,它在那一点的导数(斜率)通常为零。这被称为临界点。
有什么用:
企业:求如何安排生产能使利润最大化,或使成本最小化。
工程设计:求如何设计一个容器的尺寸,能在满足容量要求的前提下,使表面积最小(最省材料)。
机器学习:这正是你之前问的最小二乘法的核心!为了最小化“预测误差的平方和”,我们通过求导并令导数为零,来找到那个使误差最小的最佳模型参数。
- 经济学:求边际量
在经济学中,“边际”概念至关重要,它本质上就是导数。
边际成本:每多生产一单位产品,所带来的总成本的增加量。即 总成本函数对产量的导数。
边际收益:每多卖出一单位产品,所带来的总收益的增加量。即 总收益函数对销量的导数。
有什么用:企业通过比较边际收益和边际成本来决定最优产量。当边际收益等于边际成本时,利润最大化。
5. 机器学习与数据科学:梯度下降法
这是现代AI技术的基石之一。
有什么用:训练机器学习模型本质上就是一个不断的优化过程——找到一组模型参数,使得“预测误差”这个损失函数的值最小。
怎么做:导数(在多变量情况下称为梯度)指明了让误差增长最快的方向。那么,沿着其反方向(负梯度方向)调整参数,就能最有效地降低误差。这个一步步“下山”(寻找最小值)的过程就是梯度下降法。
- 其他科学领域
化学:反应物浓度随时间的变化率(反应速率)。
生物学:种群数量随时间的变化率。
医学:药物在血液中的浓度随时间的变化率。
一个简单的思维框架
你可以把任何你研究的系统想象成一条曲线:
导数 > 0:系统正在上升/增长。
导数 < 0:系统正在下降/减少。
导数 = 0:系统可能处于一个转折点(顶峰、谷底或平台期)。
导数的绝对值很大:系统正在剧烈变化。
导数的绝对值很小:系统变化缓慢/稳定。
总结一下:
导数是一个强大的“变化率测量仪”和“趋势探测器”。它让我们能够:
分析:精确描述事物在瞬间是如何变化的。
预测:基于当前的变化趋势,预测近期的未来。
优化:找到实现目标(最大化或最小化)的最佳路径。
从计算卫星轨道到推荐你可能喜欢的电影,背后都有导数的身影。它是连接静态世界与动态变化的关键桥梁。
我看到最简单的讲偏导数和梯度下降的视频:
https://www.bilibili.com/video/BV1NCgVzoEG9?spm_id_from=333.788.videopod.sections&vd_source=ee9913447b5b99684379c797a533b766&p=2
代价函数有啥用
为了求出线性模型y=wx+b中的 w 和b,求解最合适的 w 和 b 的值。我上面的例子只举了 y=wx,如果加上b,那么损失函数图像就是一个三维的:
(没加上b,也就是y=wx,损失函数图像就是个抛物线)
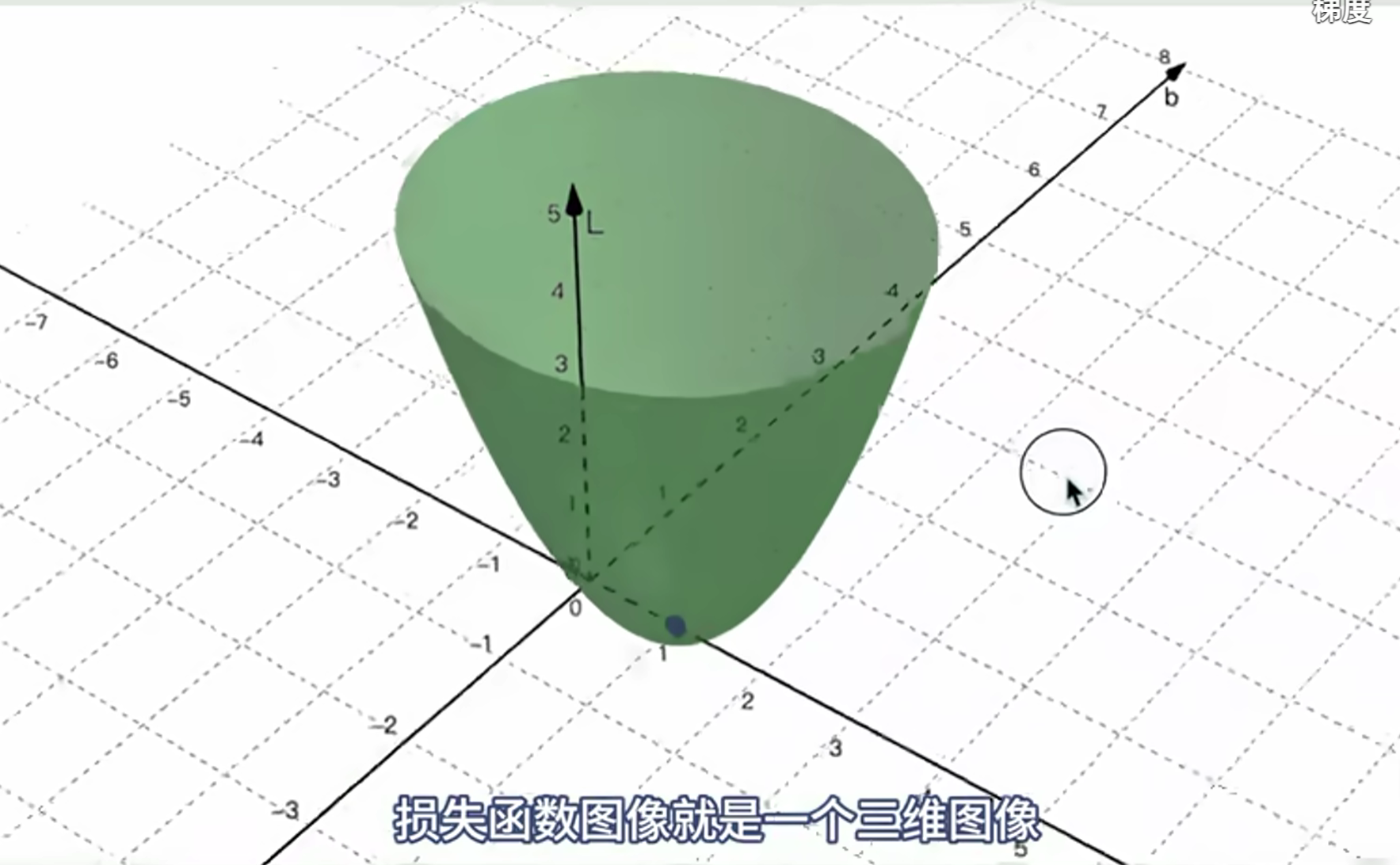
三维图像目标一样,也是找w和b
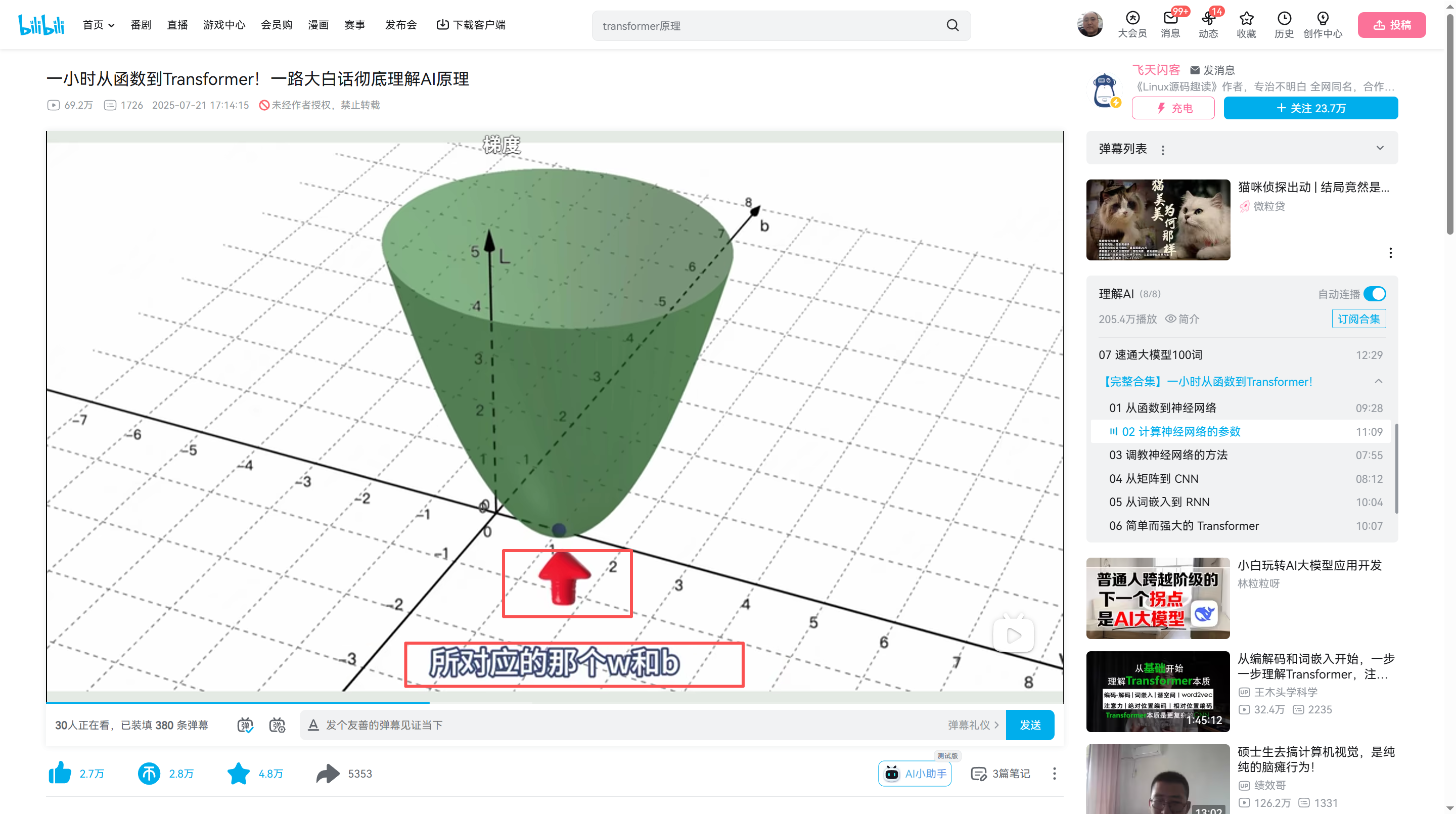
像这种多元函数求最小值=0的问题,就不再是求导数了,而是让每个函数的偏导数等于0

啥是偏导数? 如果我只改变这一个因素,而保持其他所有因素不变,结果会如何变化?



梯度下降中的学习率,决定梯度下降的速度快慢
梯度下降的最终定义:
不断变化w和b,使得损失函数一点一点减小的过程,直到求出损失函数的极值点(最小值),继而求出最终的w和b的过程,这个过程就叫做梯度下降。
啥是链式法则
看视频:https://www.bilibili.com/video/BV1NCgVzoEG9?spm_id_from=333.788.videopod.sections&vd_source=ee9913447b5b99684379c797a533b766&p=2
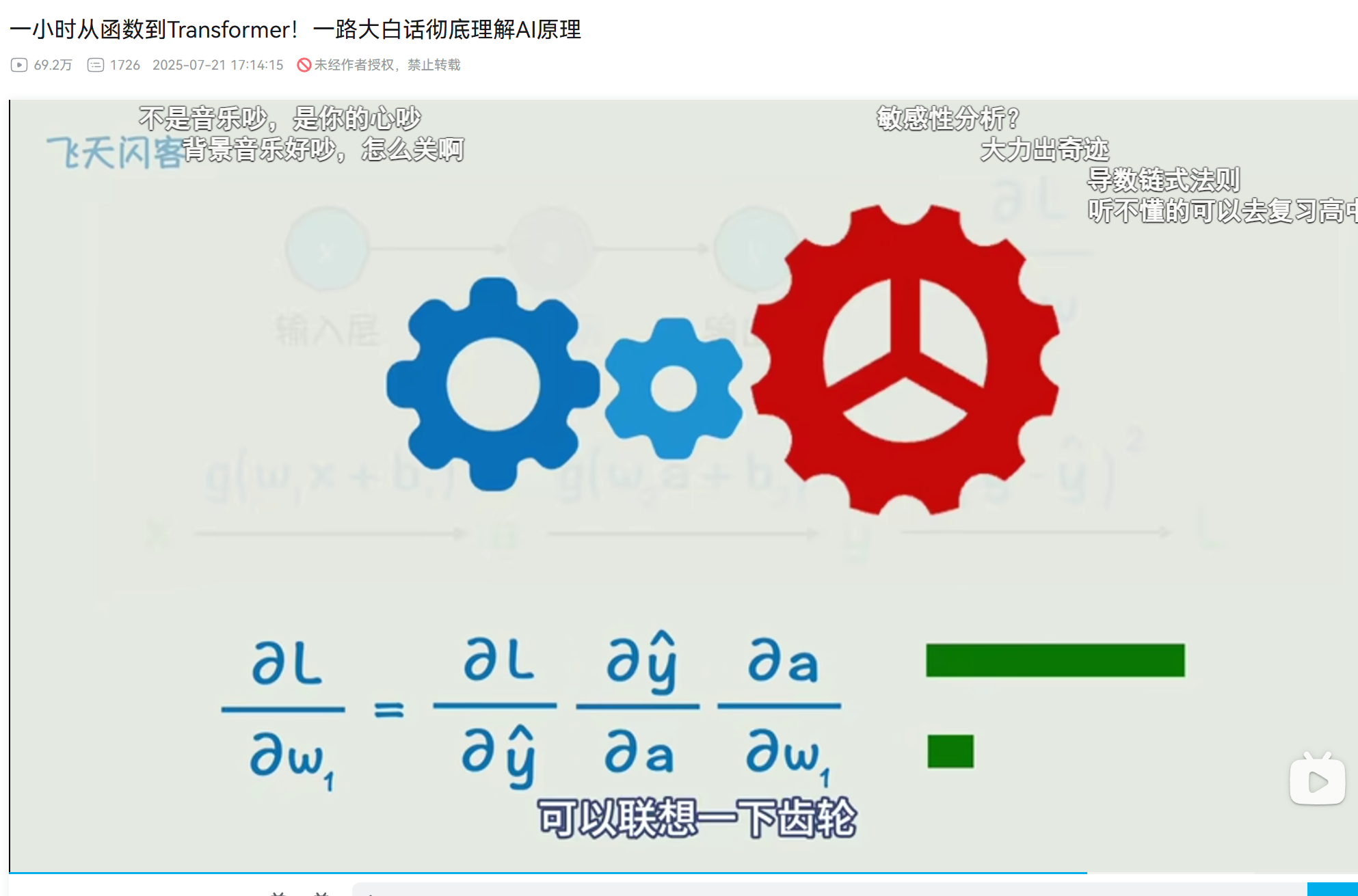
【待解决】啥是反向传播?
先解决复合函数的求导和链式法则,就可以解释啥是反向传播了
这俩玩意我高二下学期就会了,其实就是高中知识,太简单了。
【待解决】啥是神经网络的训练?
不断地前向传播和反向传播,就构成了神经网络的训练过程。
一次前向传播反向传播,就是一次训练
啥是线性回归
上面讲的一切就是线性回归。通过寻找一个线性函数来拟合x和y的关系,就叫线性回归。
那啥是非线性回归?
非线性回归就是通过“激活函数”吧线性变成非线性,来拟合曲线。
啥是过拟合?啥是泛化能力
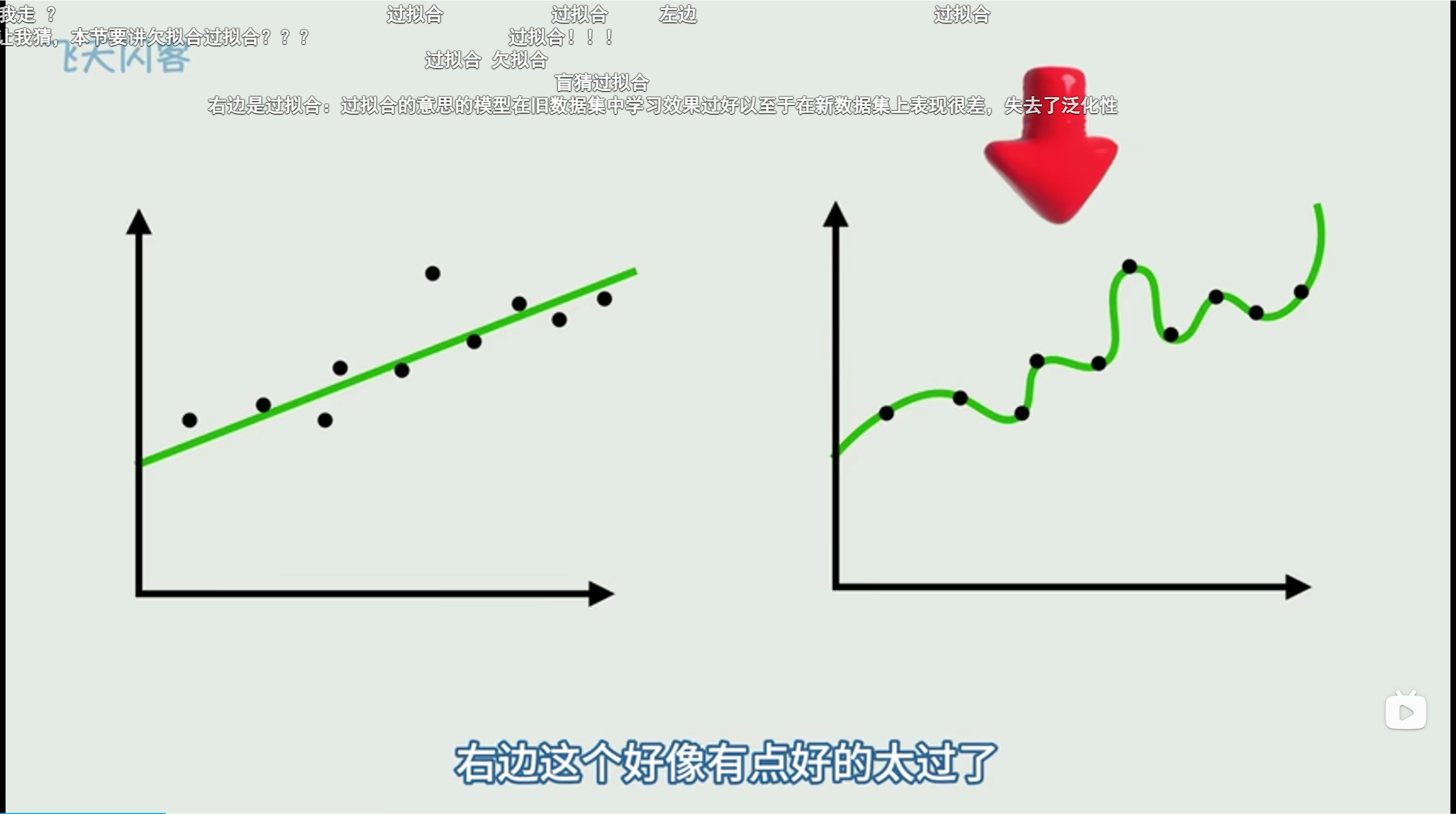
右边就是过拟合。过拟合就是在训练数据上表现完美,但是一旦 给他一个没见过的数据,就表现不好
泛化能力:一个模型在没见过数据上面的表现能力,就叫做泛化能力。
防止过拟合的几种办法
1、降低模型复杂度
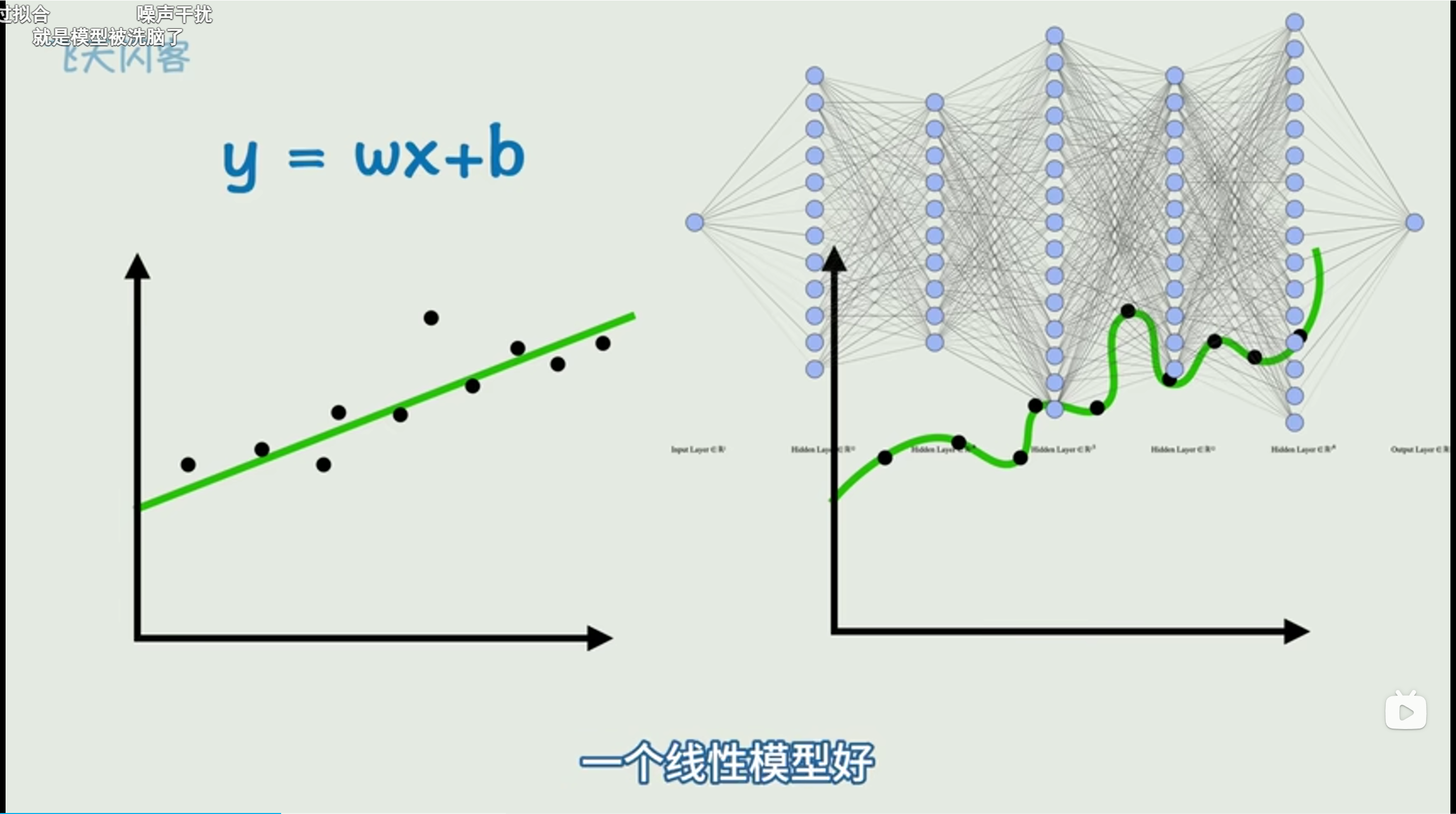
就以这一堆点为例,你用右边的复杂神经网络来拟合,效果还不如 y=wx+b 这个模型!!
2、【啥是数据增强?】就是增加训练数据的量,学名叫数据增强
也可以防止。
增加数据也可以对原有数据做处理来增加,比如下图这样:

翻转,裁剪、加滤镜、加噪声等操作,一张图片变成多张。
3、数据增强的好处
让模型不因为一点点小的变化,而对结果产生很大的波动,这还可以增加模型的鲁棒性!!非常重要!
4、提前终止训练过程(太糙了)
神经网络的训练过程就是不断调整模型参数的过程。只要不让参数继续过分的向着过拟合的方向发展,就可以了。所以最简单的方法就是提前终止训练过程。
5、正则化和惩罚项,正则化系数,超参数,范数。
5 是4的升级。了解了4,会发现4有点粗糙,所以有聪明的大脑就想出来了5.
从训练的角度出发,我们是通过调整参数w,让损失函数值最小;不断地增大和减少w,来想办法让损失函数最小(这个过程叫梯度下降),如下图所示:
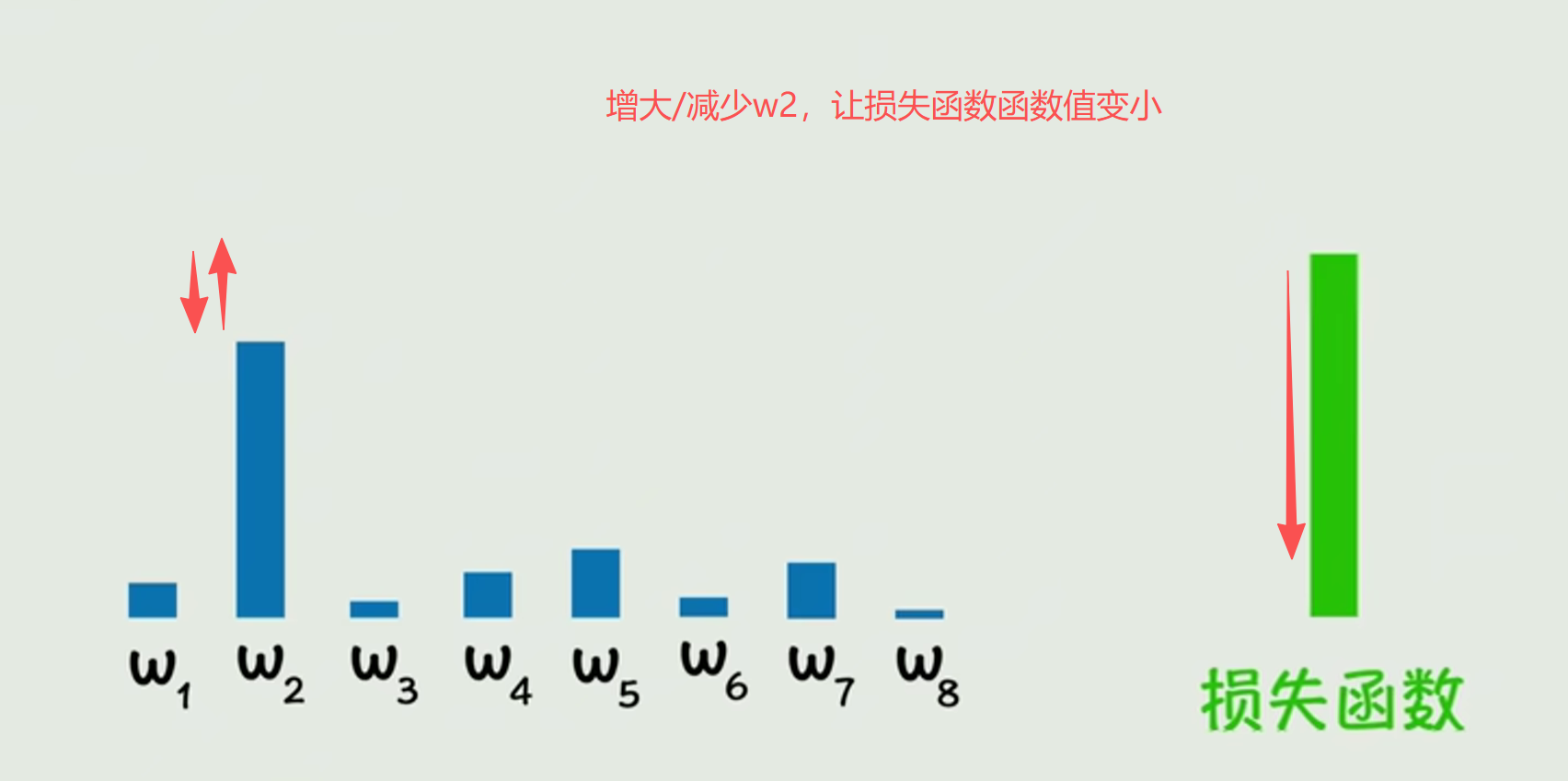
假如说通过疯狂训练,w2一直野蛮增长,w2无限增长,损失函数是也会下降的,但是随着w2越来越增长,损失函数的下降速度越来越慢,损失函数的下降速度对比w2的增长而言过于“慢”了。而如何判断这个“过于慢”,有一个牛逼的方法:
如下图所示:在损失函数中,吧参数w2本身的值加上:
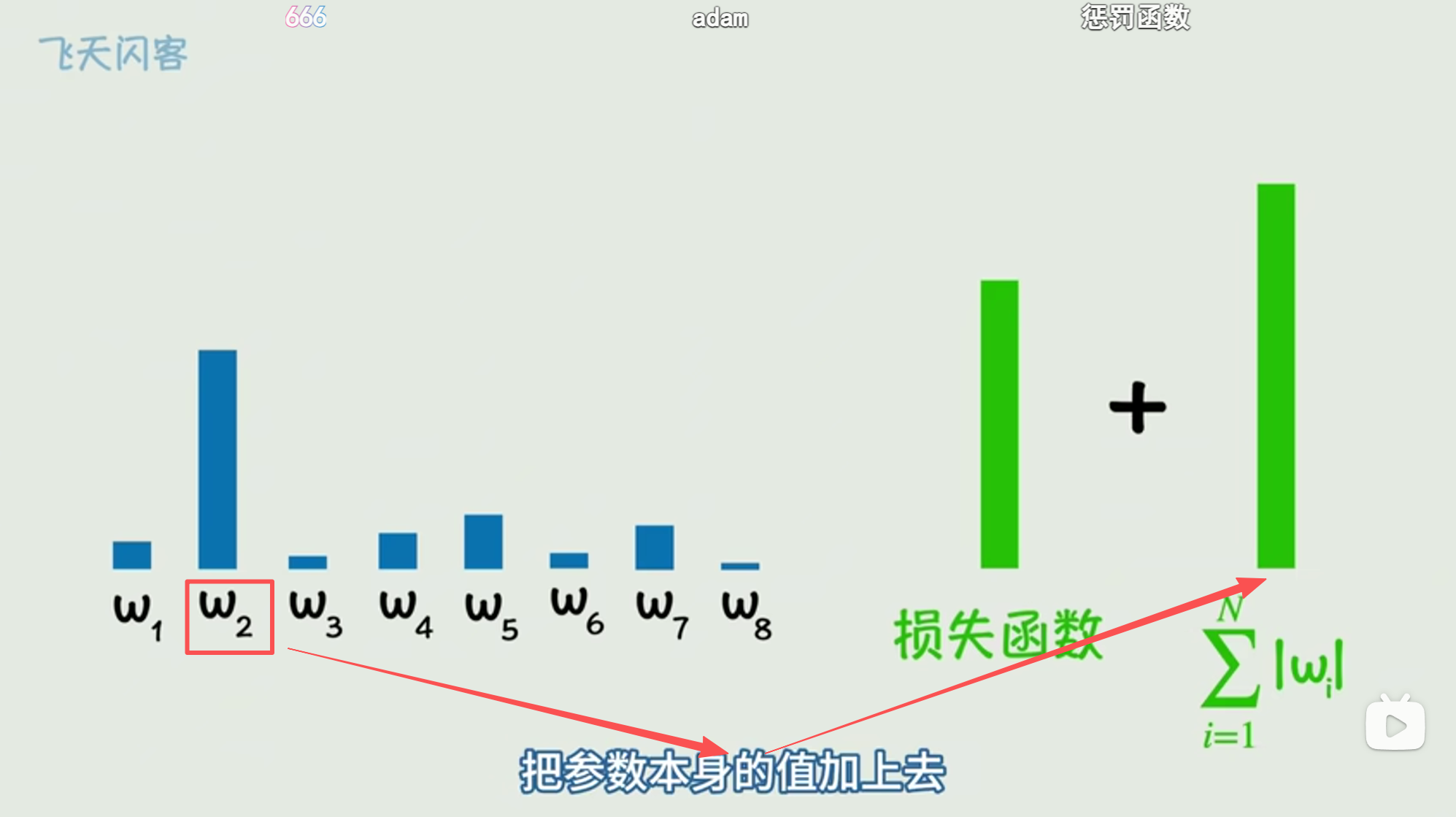
然后会得到一个新的损失函数(就是上图右边那个玩意)。
然后w2一直不断调整,w2如果一路增大,虽然损失函数减小,但是最右边的新损失函数却是增大的。如果我们发现损失函数下降的程度 小于 新损失函数上升的程度,那就说明w2过了。你w2别增长了,再增长就过拟合了!
吧参数w2本身的值加上,这个参数w2就是【惩罚项】
把通过这种向损失函数中添加惩罚项来抑制参数“野蛮生长”来防止过拟合的方法,叫做【正则化】

再下面就是玩儿概念了(概念有点多,但是很简单):
- w的绝对值相加的叫L1正则化
- w的平方相加的叫L2正则化
- 在w前面乘一个系数 入,这个 入, 就是正则化系数。
- 控制参数的参数,叫做超参数,比如说这个 入 ,就是超参数
- 绝对值之和叫做L1范数
- 平方和的平方根叫做L2范数 (加长版勾股定理)
范数的概念
啥是范数?范数这个概念在向量中还挺重要的:
范数是数学和机器学习中一个非常基础且重要的概念。它本质上是为向量(或矩阵)赋予一个“长度”或“大小”的度量方式。
简单来说,范数是一个函数,它接收一个向量作为输入,输出一个非负的实数,代表这个向量的“大小”。
直接举例:

范数的核心意义和应用 :

6、Dropout 丢弃
深度学习之父:辛顿提出来的。

每次训练随机丢弃一些参数。

这样可以有效防止某个参数过于牛逼,提高参数在没有这个参数下的表现能力。也就是平均能力。
避免了在某些关键参数上过分依赖的问题。比如认猫, 猫的耳朵很尖这个参数太强了,模型只需要 判断耳朵太尖,就知道这玩意是猫。但是突然给模型一个无耳猫,模型就傻眼了。
使用这个随机丢弃参数的办法就可以改善这个问题。
咋解决梯度消失、梯度爆炸、收敛速度过慢、计算开销过大等问题
分别用:梯度裁剪、残差网络、权重初始化、归一化、动量法、RMSProp、Adam、mini-batch等方法解决。

神经网络部分
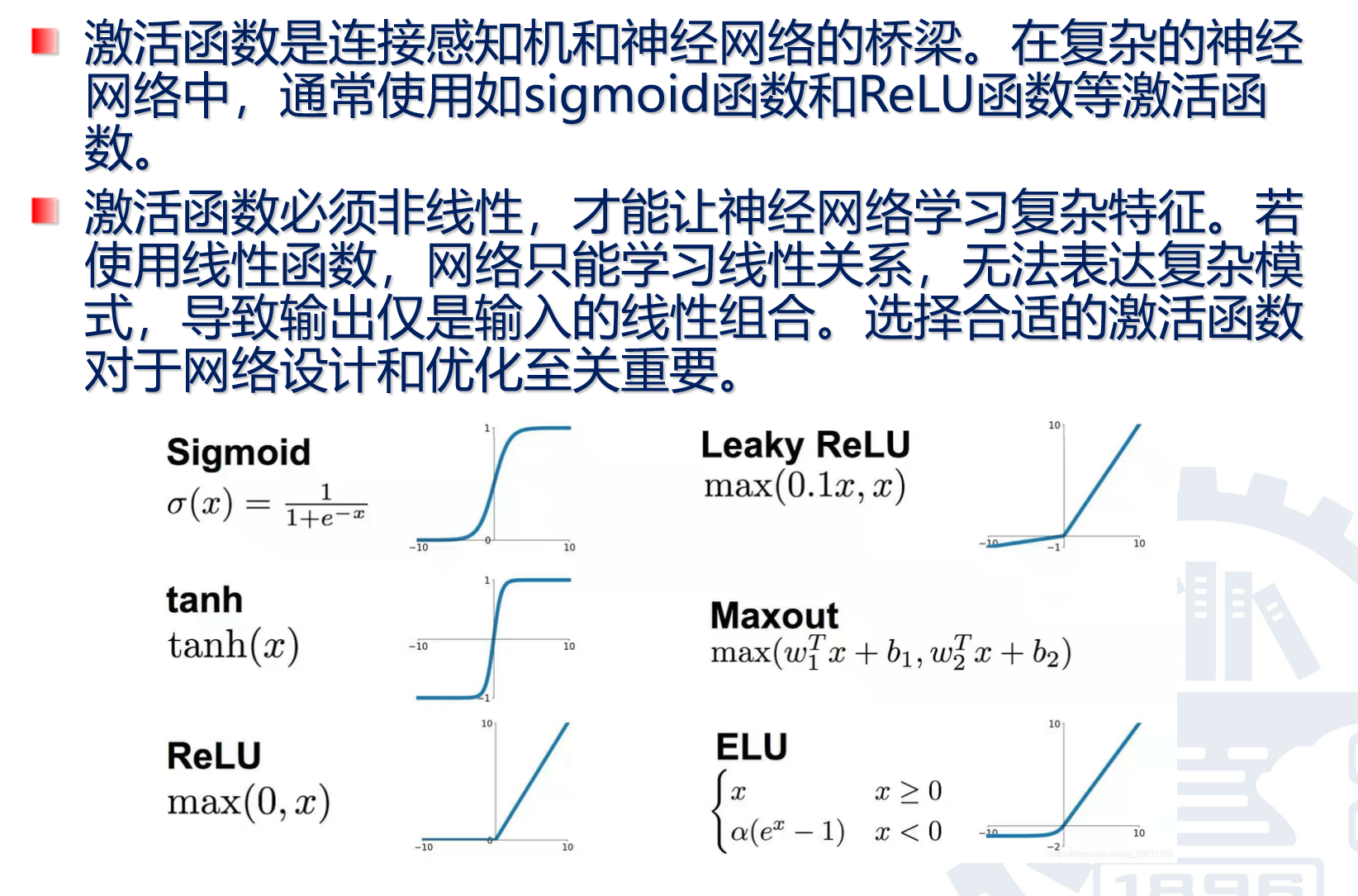
线性和非线性,以及激活函数
如果有这么一组数据没办法用一条线来拟合:
那我们把这个直线弄成弯的就是非线性了。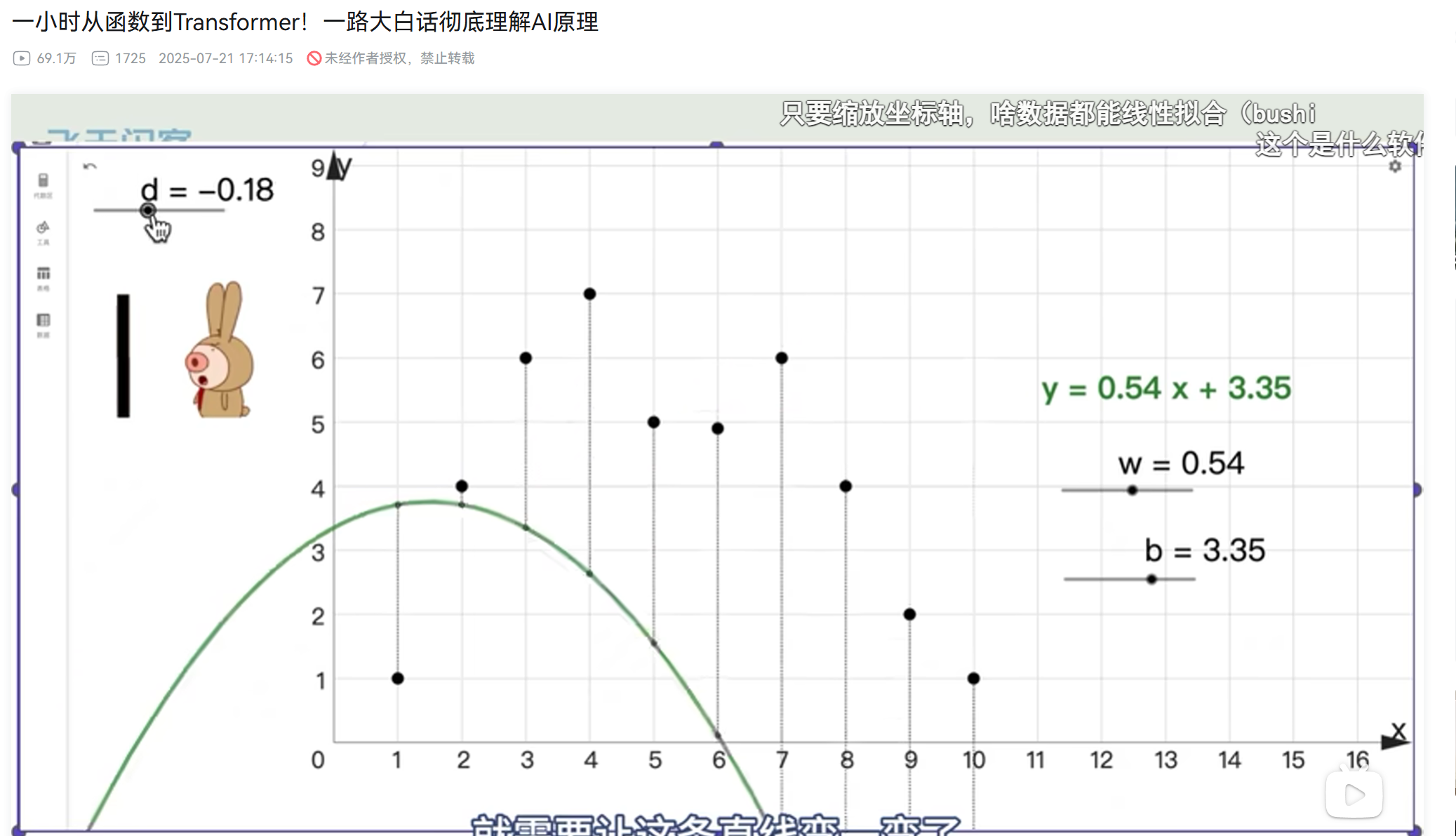
那咋吧一个线性函数弄成非线性函数呢?
很简单,给y=kx+b外面套一层非线性运算就行了,比如:

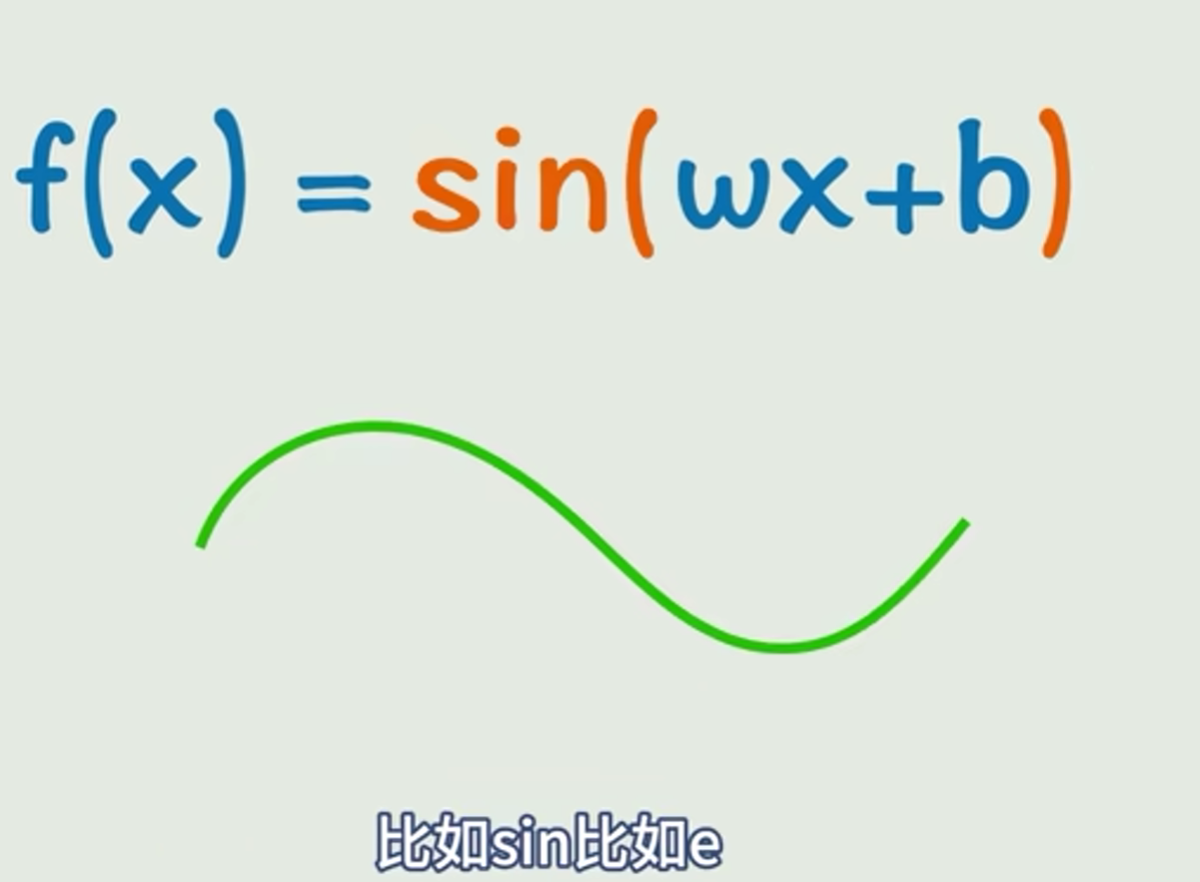
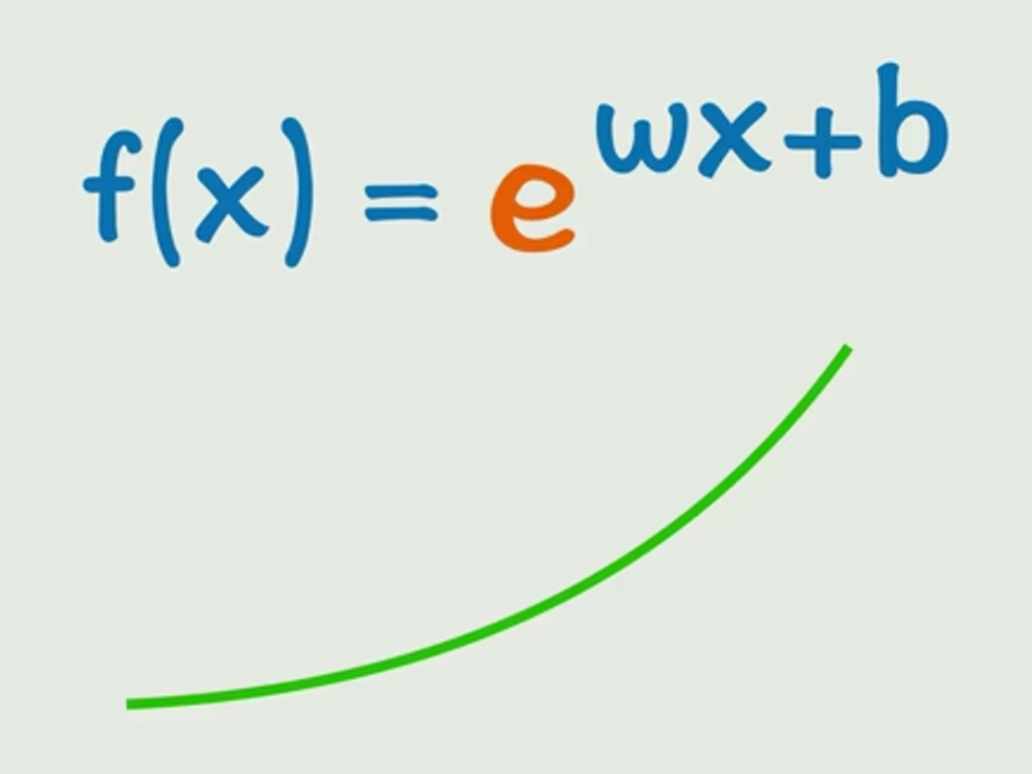
这几个玩意就是激活函数。激活函数 它是在神经网络中对输入信号进行非线性变换的函数。

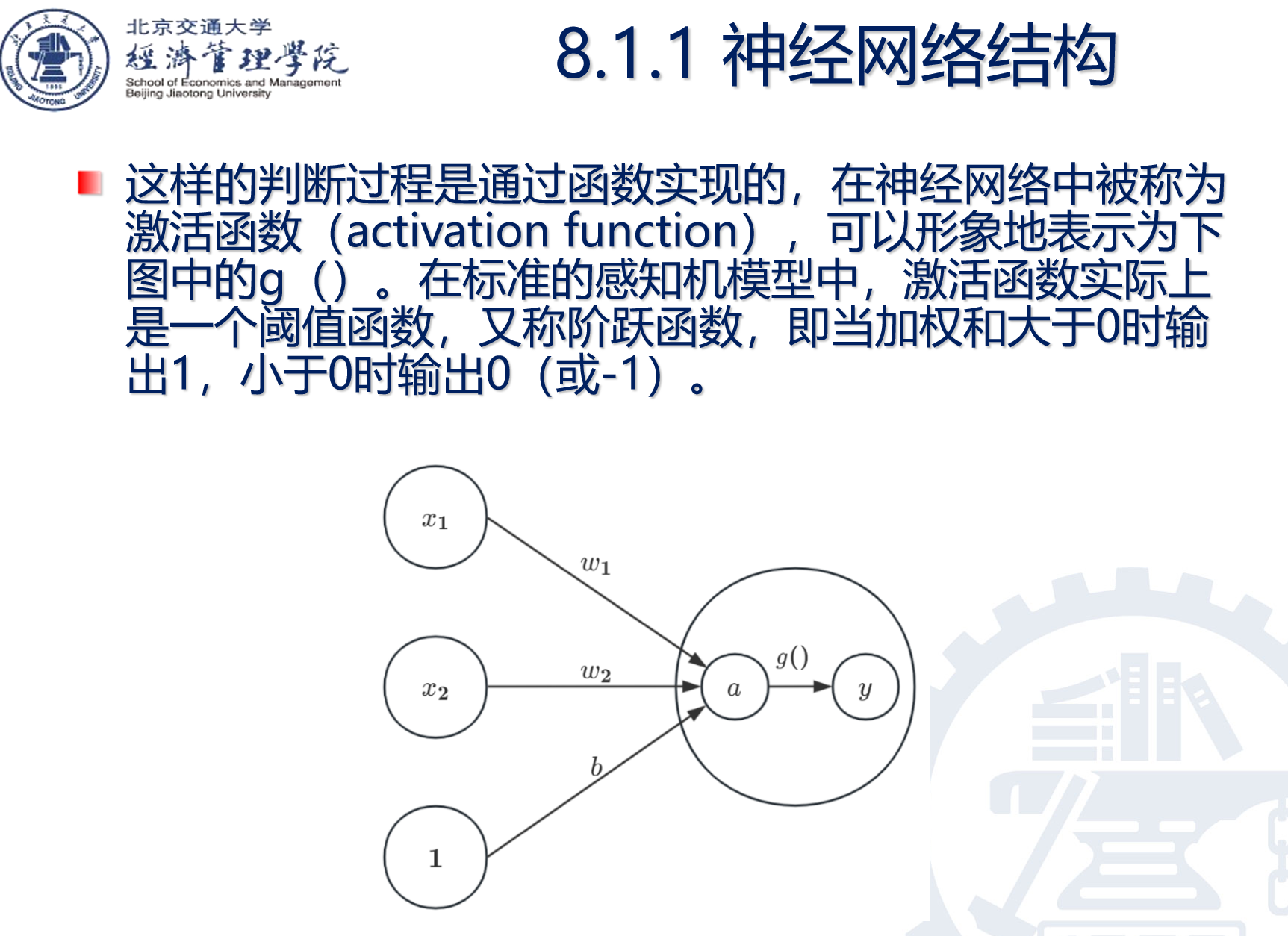
有时候,自变量x(可能是字段)不只是一个,她有可能是多个,所以函数关系就是下面这样了(g就是套了一层激活函数):
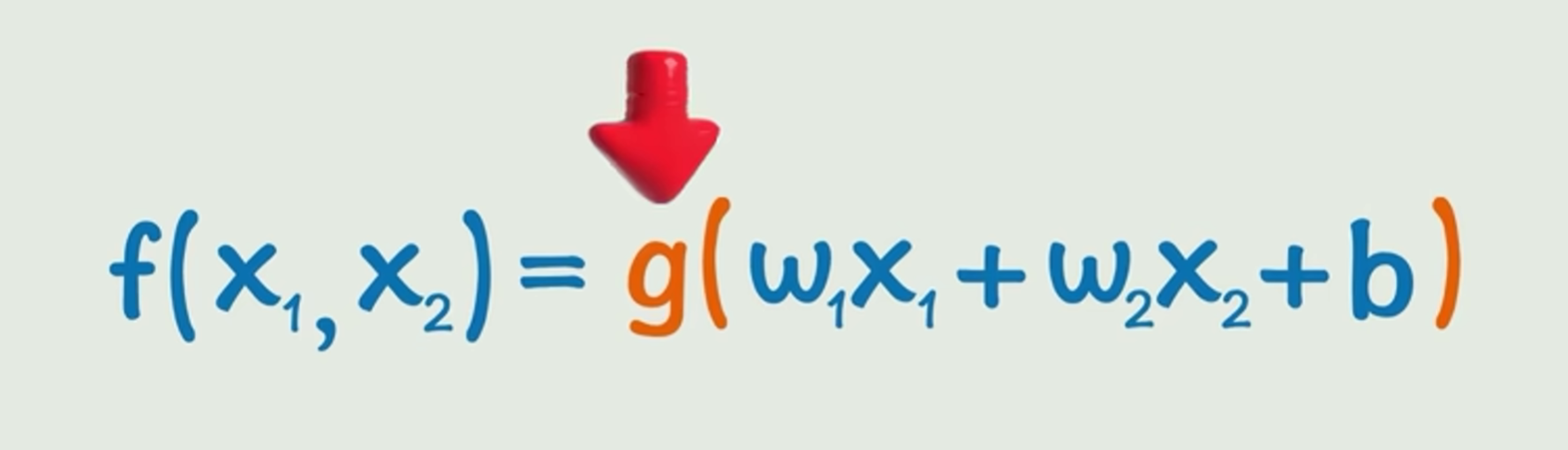
感知机入门概念:输入层,隐藏层,输出层
这玩意就是感知机。
输入层,就是接收原始数据的那一层,比如这个:就是输入层:
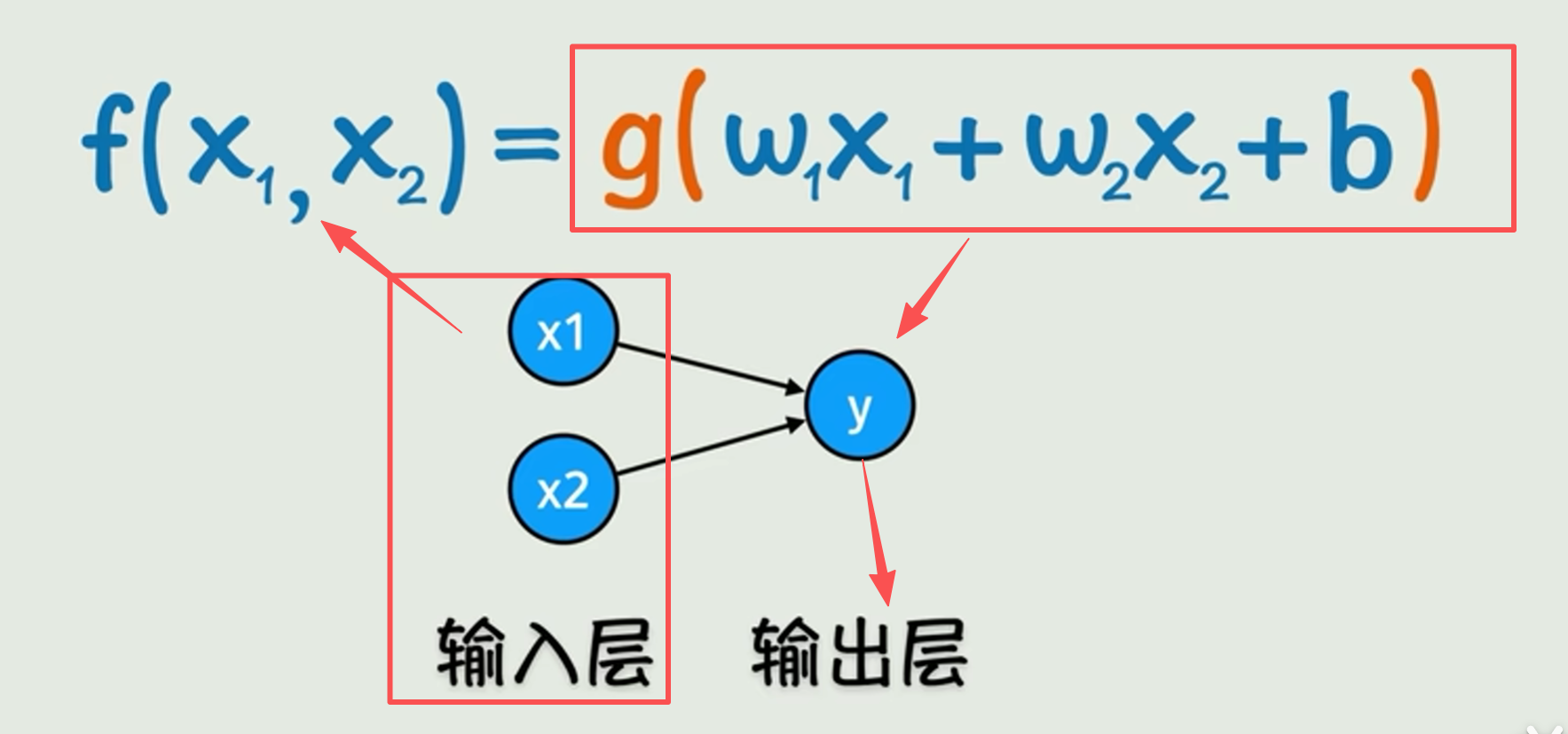
输出层实际上理解,以“认猫”举例:输入层有4个 x1,x2,x3,x4:分别代表:猫的眼睛半径,猫的胡须长度,猫的耳朵是否是尖的,猫的脸是否是圆的。
比如我输入一个 [0.5, 3 , true , true] 。代表这个东西的眼睛半径0.5cm,胡子长3cm,耳朵尖,脸圆。这玩意像是个猫。
又输入一个:[1.5, 3, false, false]。代表这个玩意眼睛半径1.5cm,胡子长3,耳朵不尖,脸不圆。这玩意像是个狗。
这就是输入层。
再举一个有三个输入层的例子: 预测房价:每个神经元可能代表一个特征,如“房屋面积”、“卧室数量”、“地理位置”。(x1,x2,x3)
输出层
根据某一个非线性函数,计算出来的一个结果。
比如经过里面一个很复杂的公式,算出来 [0.5, 3 , true , true] 为0.8;
算出来 [1.5, 3, false, false] 为0.1。
这就是输出层。
输出层其实也会套用一个激活函数,不只是隐藏层会用激活函数。输出层比如在认猫问题(二分问题)上,也会用一个激活函数 ( Sigmoid 函数,输出一个0到1之间的概率值。) 。
隐藏层
隐藏层就是将原本的输出层,先套一个线性变换,套完线性变换,再套一层激活函数。这样套个娃
这么看这个隐藏层其实就是原来的输出层。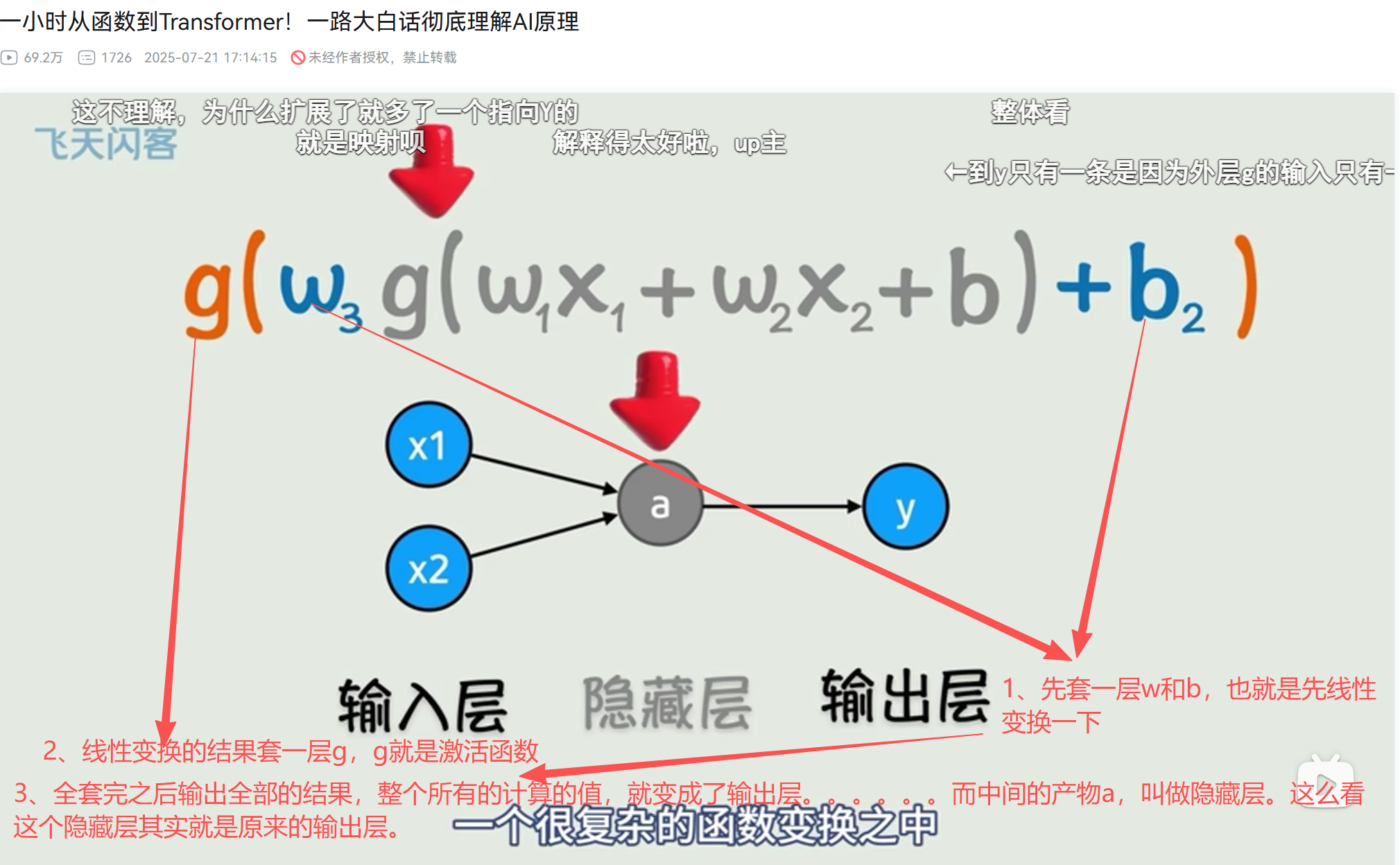
这么看这个隐藏层其实就是原来的输出层啊。。只不过就是套了一层娃.
位于输入层和输出层之间的所有层都称为隐藏层。
一个神经网络可以没有隐藏层(成为线性模型),也可以有几十、几百甚至上千层(成为“深度”学习)。
隐藏层的两大主要功能:自动特征提取与抽象:
- 第一层隐藏层可能会学习到一些基础特征(比如从每个像素点中识别出猫咪图片的边缘背景色和猫咪主体颜色的区别,如下图所示:)。

他的输入可能是每一个像素点,x1 , x2 … x4800 等等等等,假设这个图是800*600 px ,一共有4800个像素点。然后第一层只判断黑白。比如背景色是白的,猫咪是黑的。
-
中间层隐藏层会组合基础特征,形成更复杂的特征,比如猫头的位置到底在哪儿
-
更深层的隐藏层会进一步组合,识别出更高级、抽象的概念,(比如识别出 猫的眼睛半径,猫的胡须长度,猫的耳朵是否是尖的,猫的脸是否是圆的)。
-
以此类推继续叠加无数个隐藏层。
引入非线性能力:通过激活函数,隐藏层让网络能够学习极其复杂的非线性关系,这是神经网络强大的根源。
特点:
“隐藏”的意思是,这一层不与外界直接交互,我们只能看到它的输入和输出,但很难直观理解它中间具体做了什么。
它是网络的“大脑” ,负责思考和内部计算。
隐藏层对于我们来说是一个黑盒。
激活函数的概念和用处
激活函数的官方概念和几个基本用处:
想象一下,我们大脑中的神经元:它接收来自其他神经元的信号,只有当信号强度超过某个“阈值”时,这个神经元才会被“激活”,并向下一个神经元传递信号。
激活函数在人工神经网络中扮演的正是这个“开关”或“阀门”的角色。 它是在神经网络中每个神经元的输出端,对输入信号进行非线性变换的函数。
基本用处:
-
1、引入非线性因素 - 这是最根本的作用!
- 这个在之前说过,y=kx+b ,就是条直线。但是你在外面套个sin,就变成非线性了。
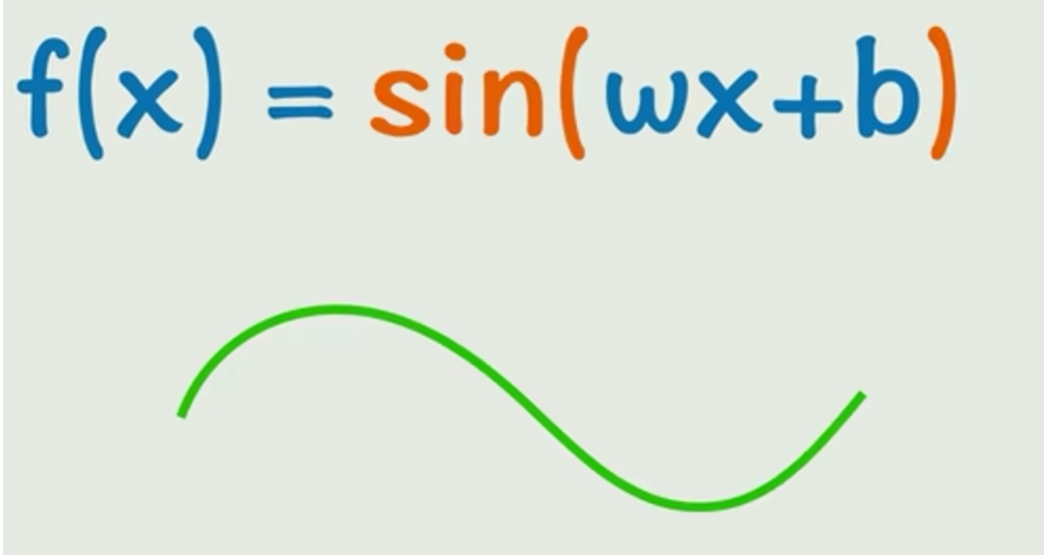
- 如果没有激活函数,无论神经网络有多少层,它都等价于一个单层的线性模型。现实世界中的绝大多数问题都是非线性的(比如识别猫狗、理解语言、预测股票)。线性模型(比如一条直线)根本无法拟合这些复杂模式。每个激活函数都是一个非线性变换。当这些非线性变换一层层堆叠起来时,神经网络就获得了逼近任意复杂非线性函数的强大能力。这使得网络可以学习数据中极其复杂和抽象的模式。通过激活函数生成的任意曲线,可以拟合任何复杂的点
-
2. 决定神经元是否应该被“激活”
- 激活函数决定了来自上层神经元的加权求和信号,有多少应该被传递到下一层。它像一个过滤器,可以:
完全激活:将信号完整传递下去。
部分激活:只传递一部分信号。
完全抑制:阻止任何信号通过。
- 激活函数决定了来自上层神经元的加权求和信号,有多少应该被传递到下一层。它像一个过滤器,可以:

这个Sigmoid很少用于隐藏层,这个激活函数多用于输出层,举例如下:

激活函数在输出层和隐藏层的作用不同
激活函数在输出层和隐藏层的作用有本质区别。虽然它们都是非线性函数,但它们被赋予的“使命”完全不同。
在隐藏层最主要的作用就是引入非线性:

在输出层,作用就比较简单了,比如格式化输出结果:


上面说的一切,就是感知机。回到感知机本身,看感知机的基础概念:
感知机是由美国神经学家Frank Rosenblatt在1957年提出的,用于解决二分类的线性问题。理解感知机是理解神经网络的重要前提。在感知机中,输入是实例的特征向量,输出是实例的类别,其目的是找到一个能够将不同类别的样本分开的超平面。
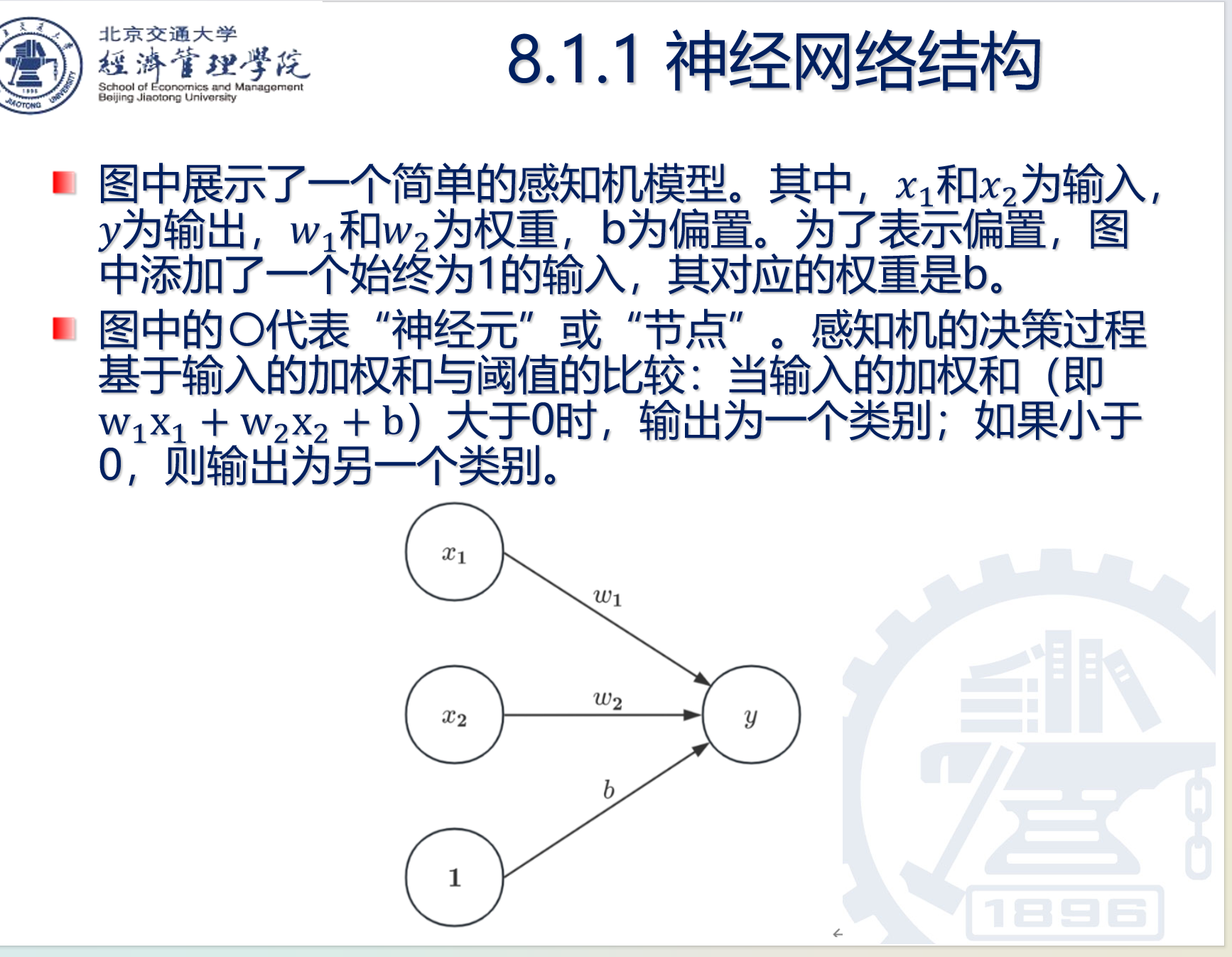
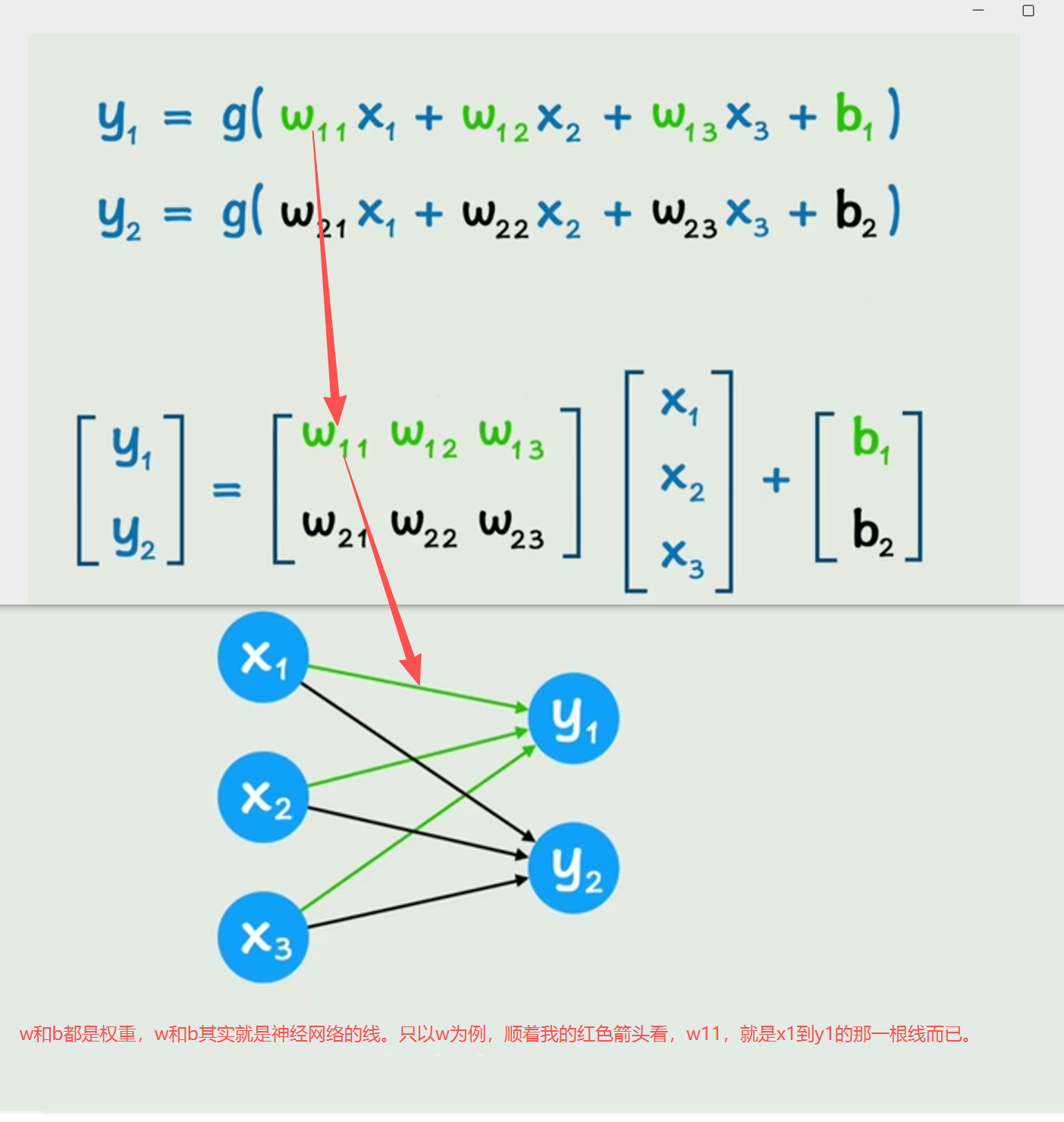
神经网络的那根线,就是权重。
怎么理解连接神经网络中间的线?
可以这样理解:
神经网络的核心目标:
接【神经网络的那根弦,就是权重】的图来讲:
在认猫问题上,比如x1代表猫的眼睛半径的输入(猫眼半径是1cm),那么绿色的箭头,也就是权重w11,就代表着
猫眼睛半径的重要性。比如我们随机设置w11为100000(当然这个值错得很离谱),那么就可以得到y1=w11 * x1 + b 。
y1再继续往后传播,一直传递到【输出层】最终的输出,最终的输出就是【预测值】。
由于我前面设置的w11为10000,错的非常离谱,导致输出的预测值是【0.98】,代表有98%的概率是猫。但是它根本不是猫,因为半径1cm眼球的生物非常多,我的眼球半径也是1cm。 此时真实值是【0】,真实值不是猫。
我们得到真实值和预测值了,这两个值都得到了,于是就可以算出【误差】。之前我们知道,误差(损失)值,在【代价函数】(损失函数)里,就是【代价函数的函数值】,也就是纵坐标。
此时,神经网络的前向传播彻底完成。前向传播的任务就是:得到当前参数w11的预测结果 和 误差。接下来进入反向传播:
我们知道损失函数的横坐标就是参数值,也就是那个w11,w11在损失函数里面体现就是损失函数的横坐标。
损失函数的横纵坐标都知道了,反向传播的目的是计算参数w,对于损失函数值(其实就是纵坐标【误差】)的导数(偏导数),这样可以反映w的变化率 对于整个【误差】的变化率。知道了这样一个导数关系,我们就知道w该如何调整,才能使得误差最小。
此时忽略复合函数求导,链式法则10000字。
总之反向传播的根本目的:得到每个参数应该如何调整才能减小误差的精确【指导】,这个【指导】又被称为【梯度】
通过反向传播拿到这个精确【指导】(梯度)之后,进入最后一步【参数更新】,又被称为【梯度下降】,更新参数值w11,完成一次训练过程。
更新完毕的w11,比之前的w11又稍微拟合了一点点。也就是说,我们完成了一次“训练”。
通过这个过程,神经网络的核心目标,就是根据已知的 x1, x2 , x3 ,和y,来求出w和b。换句话说求出最拟合的w和b,得到最拟合的一个非线性函数,从来描述(预测)真实的,复杂的数据
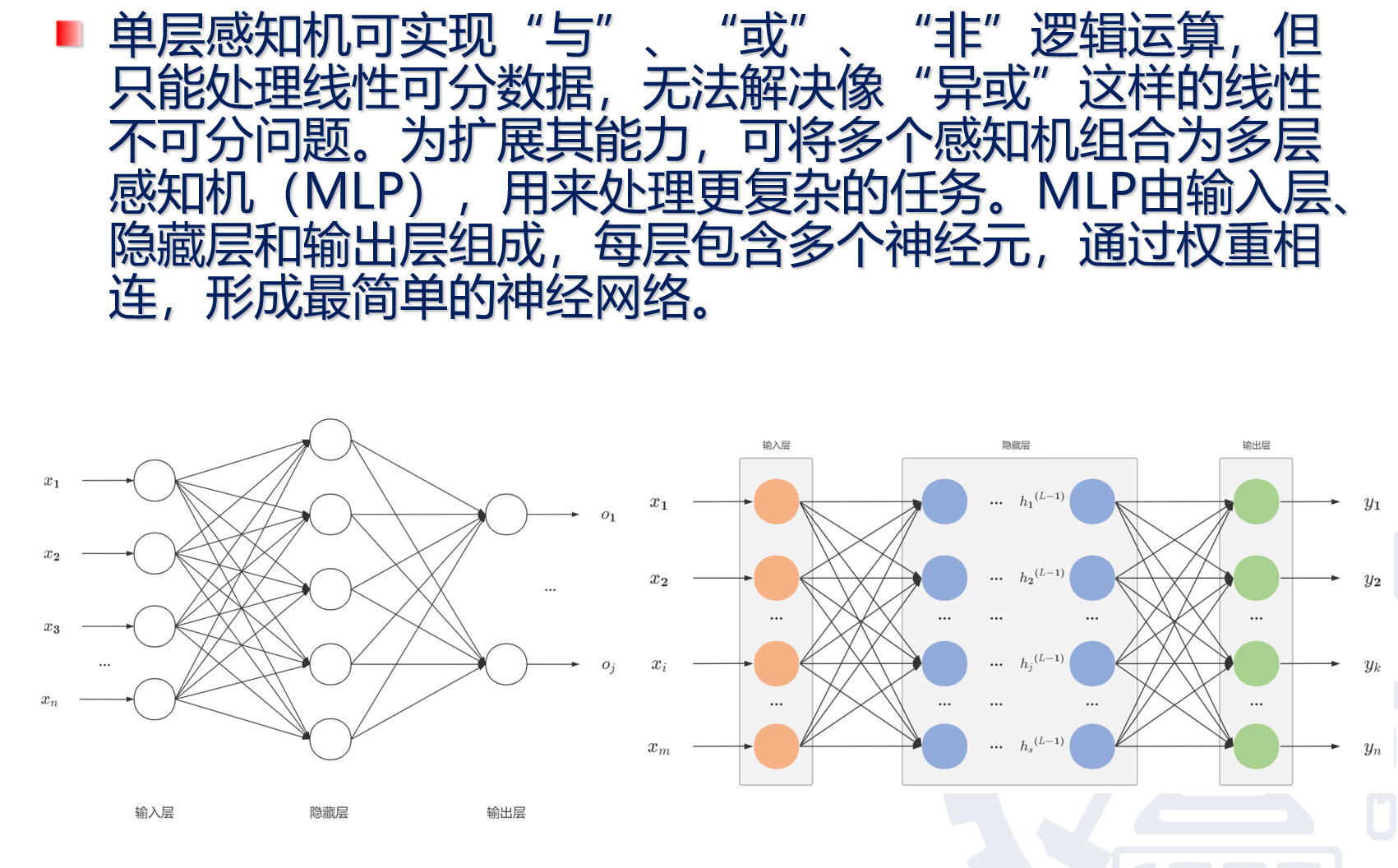
多层感知机(MLP)就是最经典、最基础的一种神经网络。
下面的图也表示“多层感知机”:
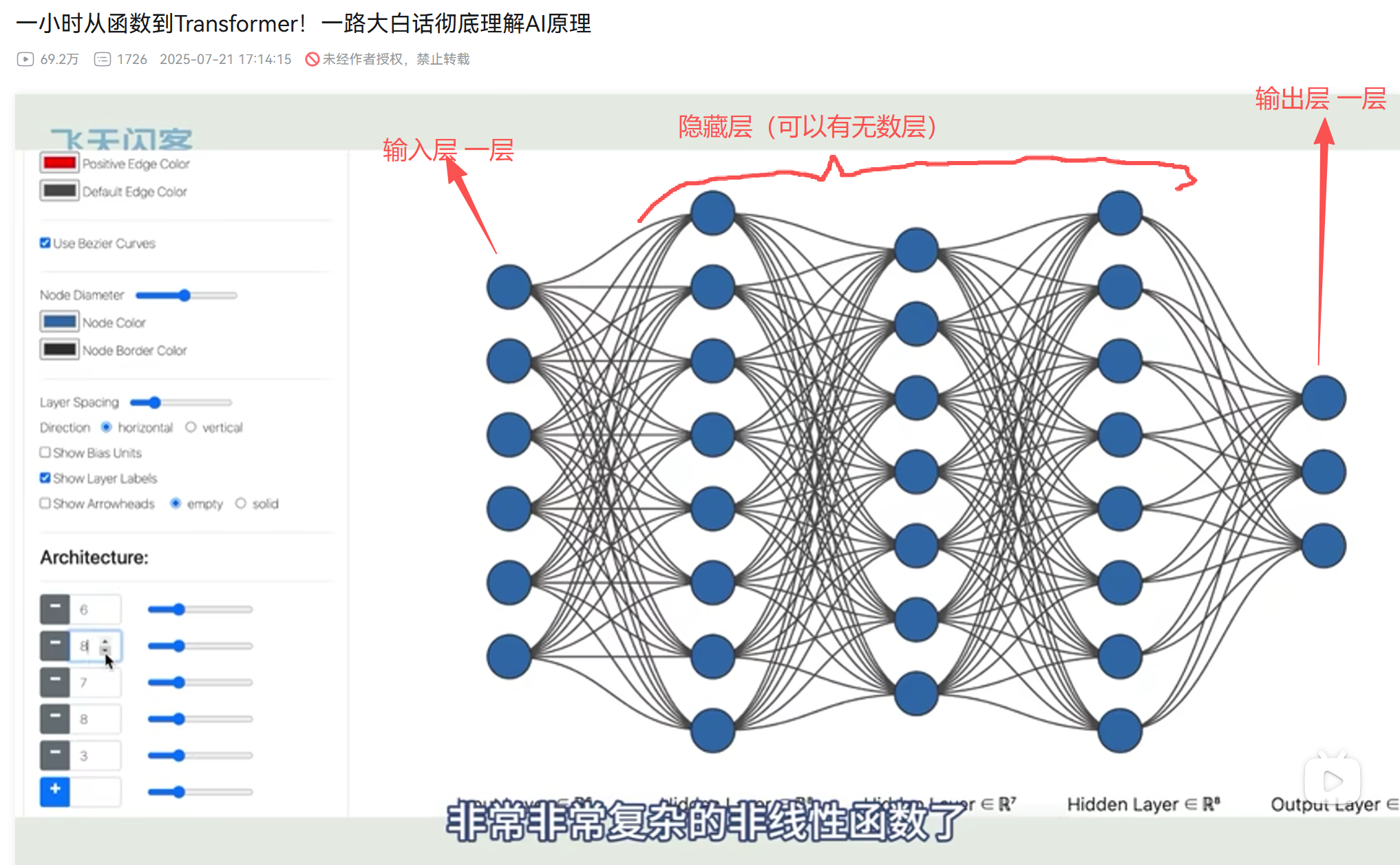
多层感知机,就是神经网络!!
神经网络的前向传播
知道了感知机的基本概念和原理,下面一图即可解释。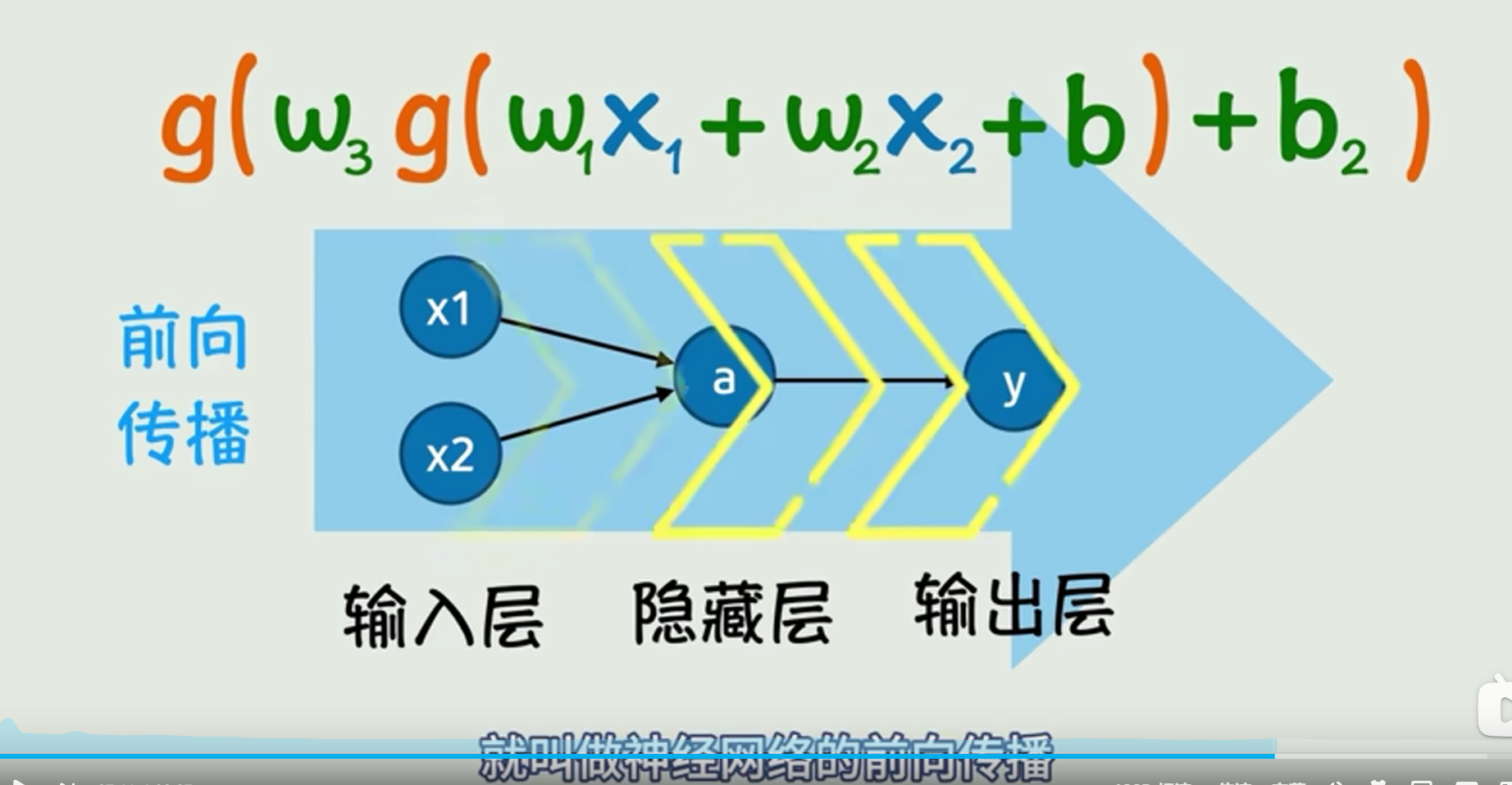
神经网络的反向传播
神经网络和Transformer的关系。这说明神经网络必学

CNN和RNN也是神经网络。


神经网络是一个广阔的领域,而 Transformer 是这个领域里为解决序列问题而设计的一座里程碑。它不仅是神经网络的一种,更是通过其独特的“自注意力”机制,极大地推动了自然语言处理乃至整个AI领域的发展,成为了当今最主流的模型架构基石。
什么是Dify,defy和工作流
https://legacy-docs.dify.ai/zh-hans
大模型开发会到的东西能有多少
QKV的公式,以及咋来的 ,注意力的公式,你得会。
Transformer这个图,你就是死记硬背也得给背下来
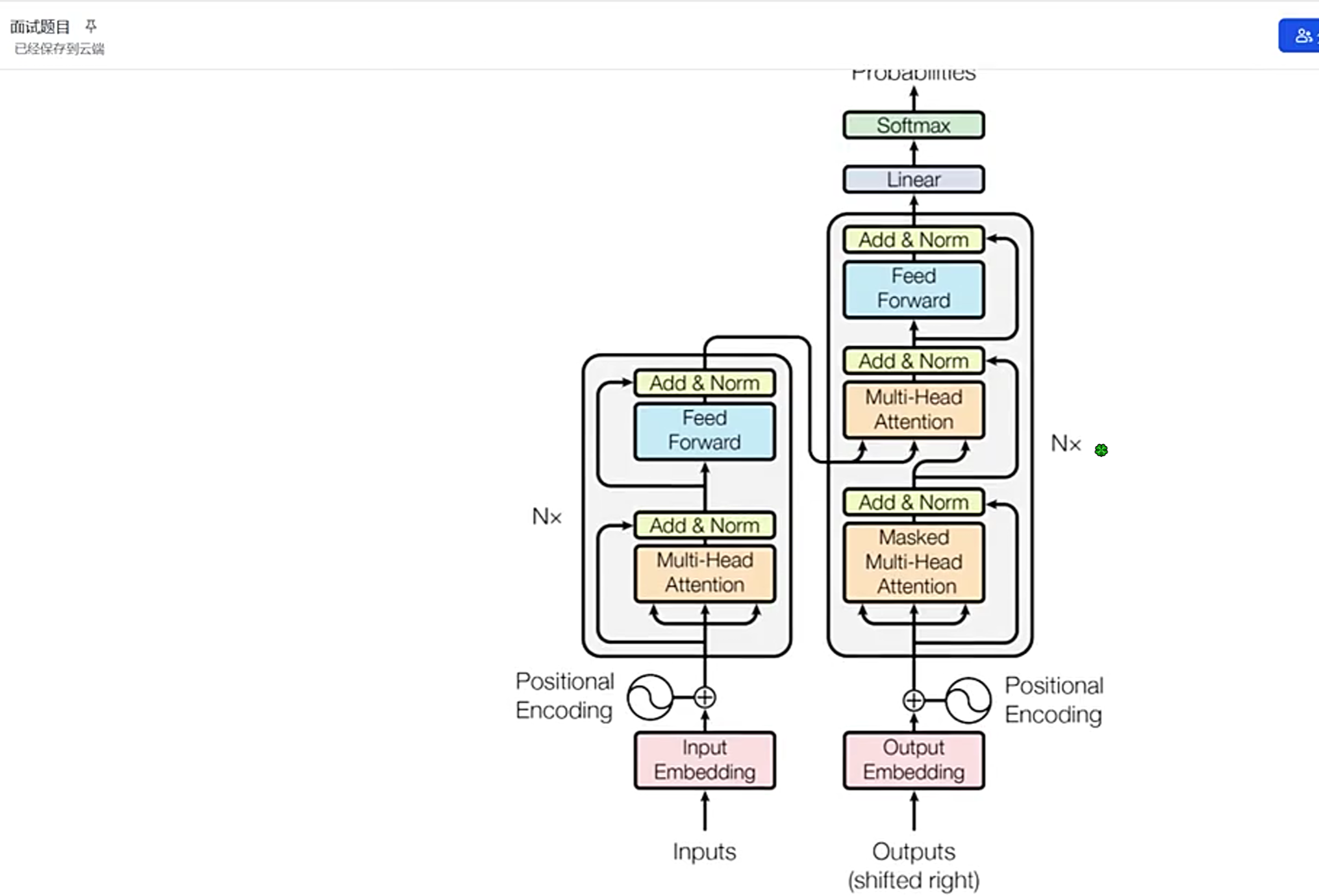
这个公式必须得会

下面这俩公式注意:
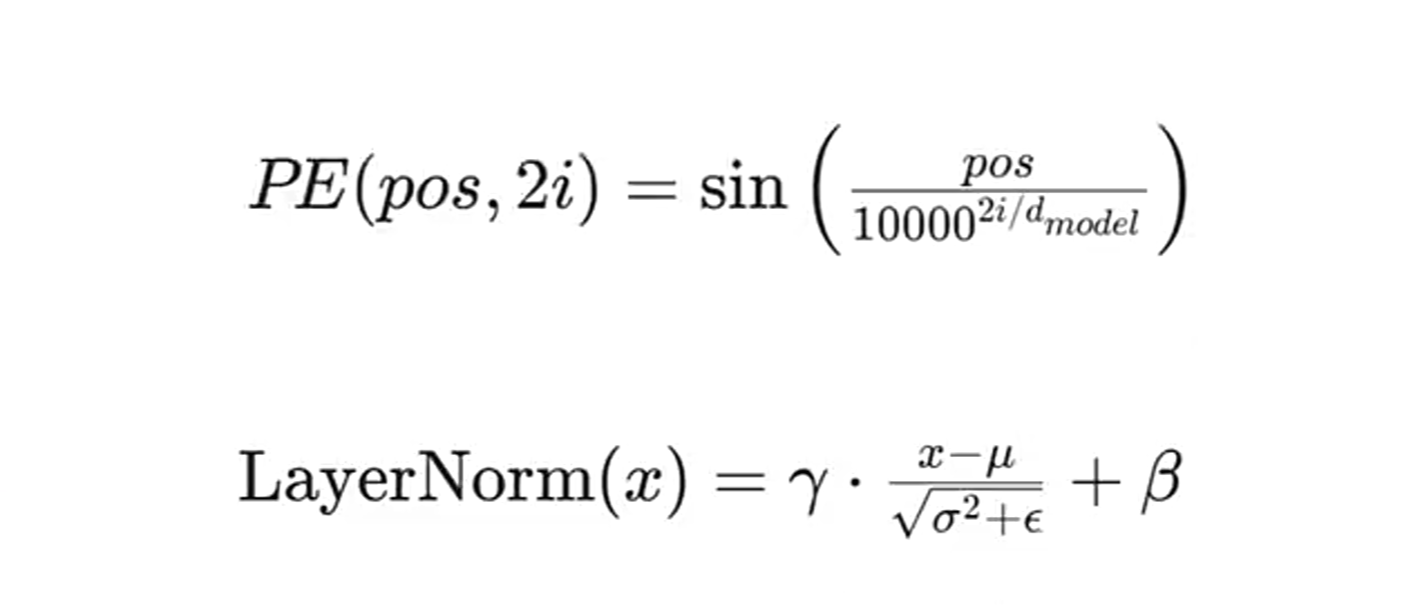
公式1,除了有带sin的,还有一个cos的。
公式2:LayerNorm和BatchNorm有何区别。
CNN 卷积神经网络
图像识别领域的神经网络。
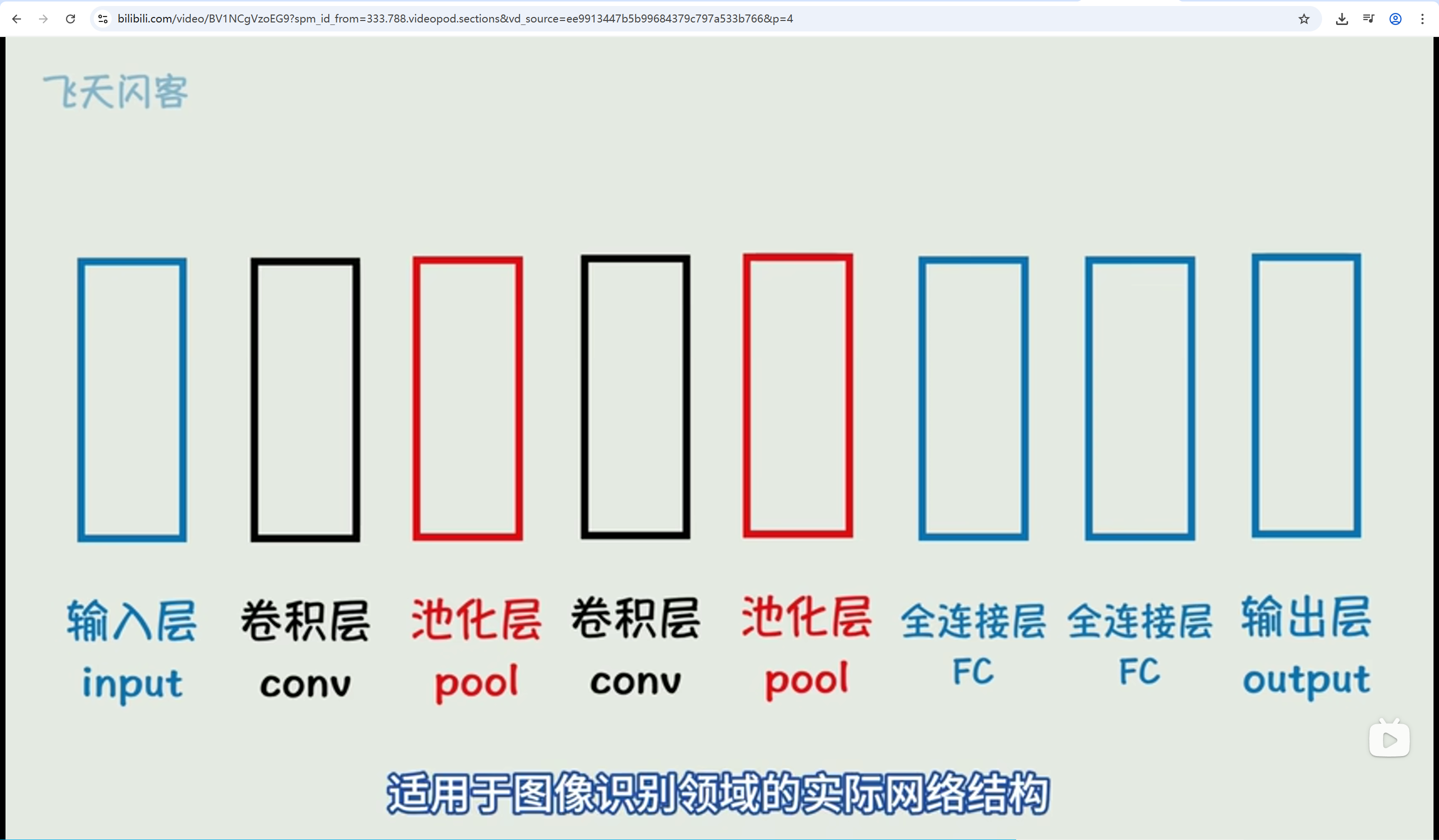
致命缺点:只能处理静态数据,如果要处理时间序列、文本、语音、视频,就需要RNN了
Transformer的代码细节问题
用python大致看一下看明白就行了,别纠结具体细节了
Transformer的更深层次的论文

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)