大模型推理能力提升
·
文章目录
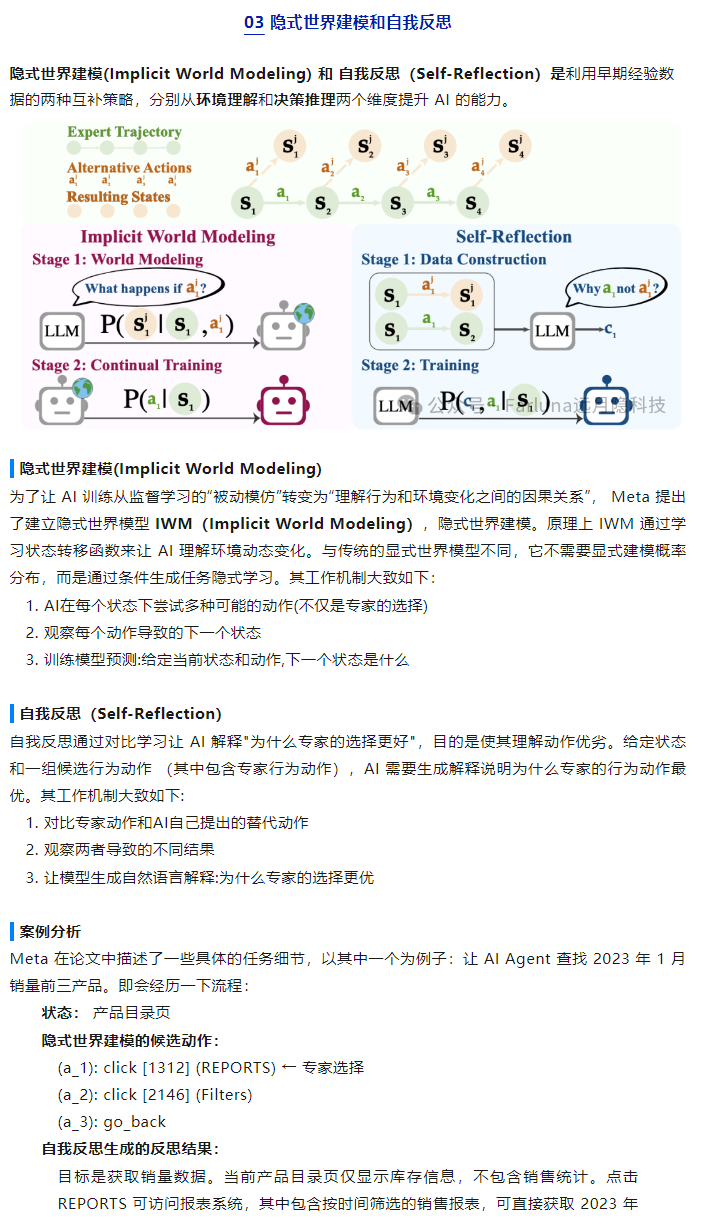
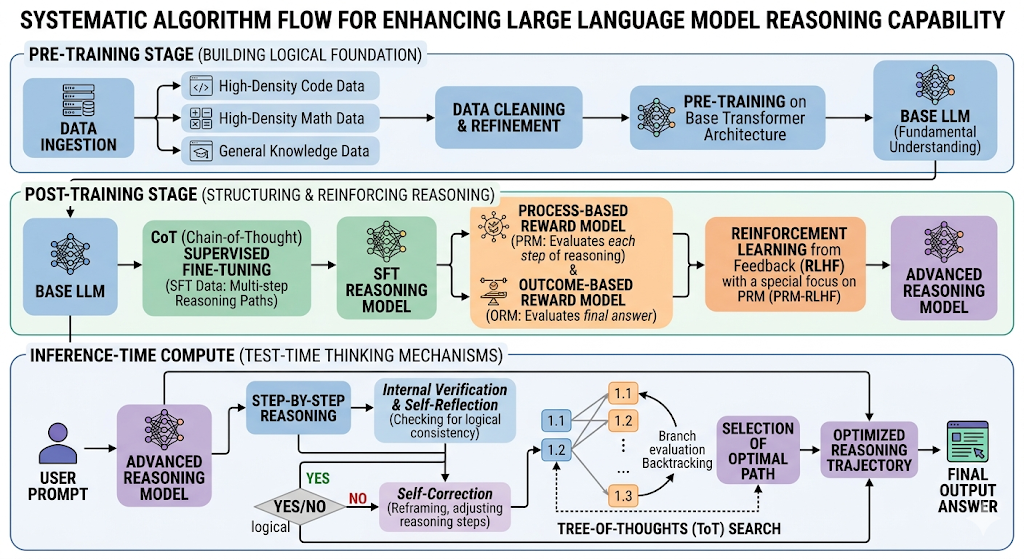
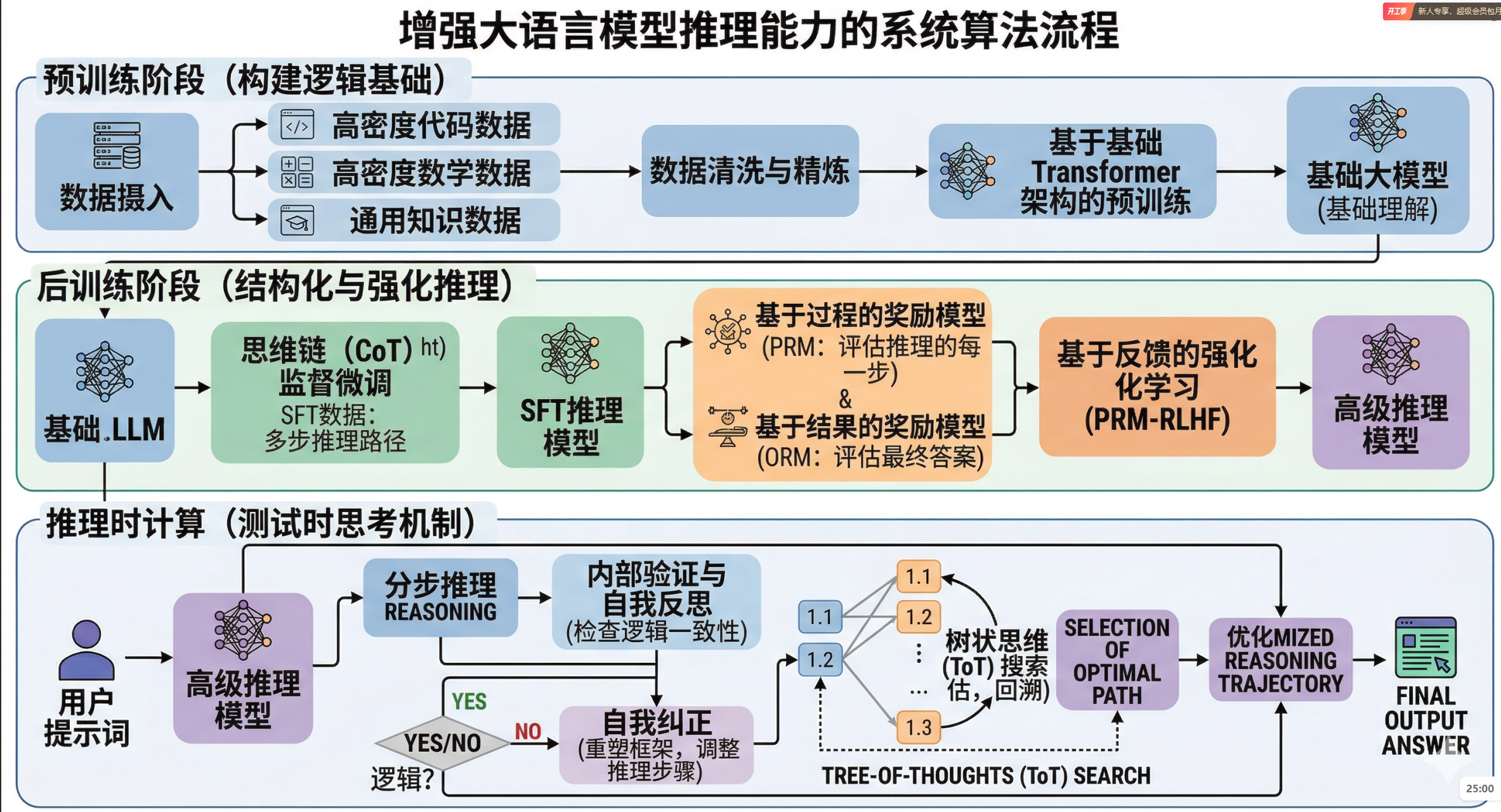
大模型(LLM)内部提升推理能力是目前人工智能领域最核心的突破方向。从早期的“概率性文字接龙”到如今展现出复杂的逻辑推演,这种能力的提升并不是依靠单一的魔法,而是在数据、训练范式和推理机制上的系统性工程。
以下是目前大模型内部提升推理能力的核心机制:
1. 预训练阶段:构建底层逻辑基础
预训练决定了模型的知识广度和基础逻辑。提升推理能力的关键在于数据飞轮。
- 高密度逻辑数据注入: 研究发现,单纯增加自然语言文本对推理能力的提升有上限。因此,现在的预训练会大幅增加**代码(Code)和数学推导(Math)**数据的比例。代码具有严格的语法和清晰的因果逻辑,这极大地训练了模型理解复杂结构和进行抽象思维的能力。
- 高质量知识提纯: 剔除低质量的互联网语料,使用合成数据或经过极其精细清洗的教科书级别数据,让模型在更“纯粹”的因果关系中建立参数连接。
2. 后训练阶段:规范与强化推理过程 (Post-Training)
在这个阶段,模型学习如何将内在的逻辑能力转化为结构化的解答。
-
思维链微调 (Chain-of-Thought SFT): 传统的监督微调只给模型看“问题”和“最终答案”。现在,研究人员会构建包含详细推导过程的数据集(即“分布思考”的轨迹)。模型通过学习这些轨迹,学会了如何拆解问题。
-
从结果奖励到过程奖励 (PRM vs. ORM): 在强化学习阶段(如 RLHF 及其变体),早期的结果奖励模型(Outcome Reward Model)只对最终答案的对错进行打分。而现在前沿的做法是使用过程奖励模型(Process Reward Model, PRM)。系统会对推理路径中的每一步进行打分和反馈。这能有效惩罚逻辑跳跃,鼓励严密的因果推导,大大降低了模型在复杂推理中的“幻觉”。
3. 推理生成阶段:用算力换取思考深度 (Inference-time Compute)
这是近期(如 OpenAI o1 模型)最大的范式转变:在模型生成最终答案前,给予其更多的“内部思考时间”。
- 隐式自我反思 (Self-Reflection & Self-Correction): 模型在内部生成一个初步的解答路径后,会被引导去审视和检验自己的中间结论。如果发现逻辑不自洽,模型会退回上一步重新推导。
- 树状搜索 (Tree of Thoughts, ToT): 面对复杂问题时,模型不再是一条道走到黑,而是在内部并行生成多个不同的解题分支,并评估每个分支的可行性,最终选择最合理的路径输出。
- 多智能体协作与辩论 (Multi-Agent Debate): 在处理复杂的非标准化任务(例如动态的场景诊断或深度的行为模式评估)时,系统内部可以实例化多个 Agent 扮演不同角色。通过让它们相互质询、辩论和交叉验证,可以显著打破单一线性生成的盲点,从而涌现出更强的系统级推理能力。
4. 架构优化:保持专注度
- 混合专家架构 (MoE): 随着参数量的极速膨胀,MoE 架构允许模型在面对特定领域的推理问题时,只激活相关的“专家”网络。这不仅提高了计算效率,也避免了不同领域知识在推理时的相互干扰,使得专业推理更加精准。
总的来说,大模型的推理能力正在从“依靠海量数据碰运气”转向“通过精细的步骤拆解和过程强化来保证逻辑的必然性”。




AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)