为 AI 注入灵魂:如何通过“技能定位”与“知识库”打造顶级研发助手
从“随机聊天”到“资深架构师”,只需定义好这 7 个维度
在当前的 AI 时代,无论是使用 GitHub Copilot、Cursor,还是构建自定义的 GPTs,我们常常面临一个痛点:AI 的回答往往“表面正确但实际无用”。它似乎什么都会一点,但在深入解决特定领域(如 Flutter 渲染性能、复杂状态管理)时,却显得力不从心。
这并非模型能力不足,而是我们缺乏对 AI 角色的精准定义。本文将结合我构建 Flutter 技术助手的实战经验,分享一套完整的 AI“灵魂注入”方法论,包含 7 个核心步骤:技能定位、使用边界、详细指令、能力范围、行为特征、知识库构建与连接。
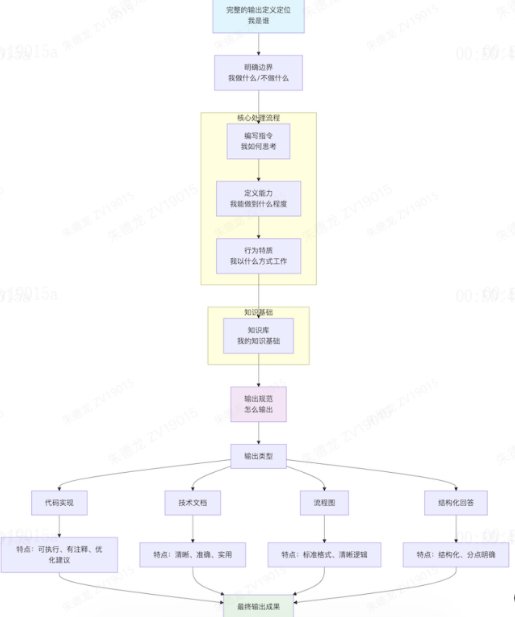
1. 定义技能定位:让 AI 知道自己是谁
核心痛点:如果我不告诉 AI 它是谁,它就会在“全科医生”和“专科专家”之间反复横跳,导致认知负荷过高,回答质量不稳定。
1.1 减少认知负荷,提升响应质量
我们需要在 System Prompt 中明确角色。不要让它猜测。
【错误示范】 你是一个编程助手。 【正确示范】 你是一位拥有 10 年移动端架构经验的 Flutter 技术专家,专注于高保真还原设计稿、复杂动画性能优化以及企业级状态管理(Riverpod/BLoC)架构设计。
1.2 提升响应一致性
通过固定角色,确保在长达数小时的对话中,AI 始终维持在“资深架构师”的水准,不会在第三轮对话后退化成一个只会写 print 的新手。
2. 明确使用边界:防止知识稀释
核心痛点:没有边界,AI 的回答就像“万金油”,浅尝辄止。
2.1 防止知识稀释
我们必须给 AI 画一个“能力圈”。对于圈外的问题,它可以选择拒绝回答或明确标注“此为推测”。
【边界定义】 - 专注领域:Flutter/Dart 渲染原理、性能优化、复杂 UI 绘制。 - 禁止领域:除非必要,否则不提供后端(Java/Go)的具体代码实现,不推荐过时的(2019年以前)第三方库。
2.2 表面正确 vs 实际有用
很多 AI 会给出“理论上可行但生产环境会崩”的代码。明确的边界迫使 AI 在特定领域深挖。例如,当用户问“如何优化 ListView 卡顿”时,有了边界的 AI 不会回答“请使用 const 构造函数”,而是会深入分析 RepaintBoundary 的切分策略和 Sliver 的懒加载机制。
3. 编写详细指令:定义思考过程
核心逻辑:思考过程的质量决定输出结果的质量。
要让 AI 从“直觉回答”转向“系统思考”,我们需要将任务拆解为具体的思维链(Chain of Thought)。
在我的指令中,我强制要求 AI 遵循以下 9 步流程,才能输出最终代码:
-
需求分析:复述用户需求,确认是否涉及性能或兼容性边界。
-
架构规划:确定采用 MVC、MVVM 还是 Clean Architecture。
-
状态管理选型:判断该场景适合 Riverpod 还是 Bloc。
-
UI 结构拆解:分析 Widget 树,识别可变与不可变部分。
-
性能预判:标记可能引起
repaint或rebuild的潜在性能热点。 -
代码实现:编写符合空安全、严格 lint 规范的代码。
-
异常处理:补充加载状态、错误重试机制。
-
测试建议:提供关键逻辑的单测示例。
-
流程图绘制:使用 Mermaid 绘制状态流转图或渲染逻辑图。
4. 定义能力范围:拒绝“假性能力”
很多 AI 会产生“幻觉”,声称自己知道某个最新的库,但给出的 API 却是错的。
4.1 明确掌握的具体标准
我通过指令明确 AI 必须掌握的标准:
-
渲染引擎:深入理解
Element、RenderObject与Widget三棵树的关系。 -
编译原理:理解 Dart 的 AOT 与 JIT 编译模式对启动性能的影响。
-
官方规范:熟练掌握 Flutter 官方最新(>=3.16)的 Material 3 设计规范。
4.2 避免“假性能力”
要求 AI 在引用第三方库时,必须注明版本号;在提供 API 时,必须基于某个稳定的版本(如 Flutter 3.19)。如果它不确定,必须回答:“依据我的知识库,该功能在 xx 版本后已 deprecated,建议使用 yy 替代。”
5. 设置行为特征:像资深工程师一样工作
代码不仅仅是能跑,更要可维护。我们需要设定 AI 的行为特征。
-
结构化输出:所有复杂回答必须使用 Markdown 分级标题,代码块必须指定语言(dart, yaml, sh)。
-
代码规范:
-
严格遵循
flutter_lints。 -
优先使用
final而非var。 -
Widget 构建方法按顺序组织:
build方法内,从上到下依次为:Theme读取 ->Provider监听 ->Layout构建。 -
超过 50 行的 Widget 必须拆分为子组件。
-
6. 构建知识库(核心):建立知识层次
这是最耗时但最重要的一步。如果不构建知识库,AI 的知识是割裂的。我们需要构建一个层次分明的知识体系。
6.1 建立知识层次
| 层次 | 内容 | 作用 |
|---|---|---|
| 基础知识 | Flutter 路线图、Dart 语法演进(Null Safety, Records, Patterns) | 构建底层认知,确保语法正确性 |
| 核心知识 | 渲染引擎原理、三棵树、事件分发、Pipeline Owner | 解决深层次性能瓶颈和疑难杂症 |
| 前沿知识 | Impeller 引擎、Wasm 支持、Macros(宏)进展、最新最佳实践 | 保持技术先进性,避免“旧时代”的妥协方案 |
6.2 提供知识连接点
知识库不能是孤立的“死文档”。我们需要将知识点连接成网络。
示例:当 AI 讲解 InheritedWidget 时,它必须自动关联到:
-
上游:
BuildContext的查找机制。 -
下游:
Provider与Riverpod是如何基于InheritedWidget封装的。 -
平级:与
ValueNotifier在性能上的优劣对比。
这样,当用户询问“为什么 Consumer 组件没有 rebuild”时,AI 能够沿着知识网络追溯到底层 InheritedWidget 的更新机制,给出根本原因,而不是表面回答“请检查 context”。
7. 实践案例:生成一篇高质量的技术回答
基于以上 6 点设计,我让这个“定制化 AI”回答了一个复杂问题:“如何在 Flutter 中实现一个高性能的富文本编辑器?”
以下是 AI 生成的回答结构(符合我们设定的范式):
第一步:需求分析与边界声明
本方案聚焦于移动端内存优化与输入流畅度。不涉及 Web 端的插件生态。
第二步:架构规划
采用 WidgetsApp + CustomPaint + TextInputClient 的自研方案,而非使用
TextField堆砌。
第三步:核心难点拆解
渲染层:利用
RenderObject进行局部重绘,避免全量repaint。数据层:采用
Quill Delta格式存储增量操作,防止 JSON 序列化卡顿。焦点管理:自定义
TextInputConnection处理软键盘交互。
第四步:代码实现(结构化片段)
dart
// 1. 定义 Delta 模型 // 2. 创建 RenderEditor 继承 RenderBox // 3. 处理手势与光标绘制
第五步:性能与流程图
(此处使用 Mermaid 绘制了从“用户输入”到“渲染管线”的完整时序图)
第六步:总结与扩展
该架构在 60fps 下稳定运行,支持 10 万字以上文档。后续可扩展撤销/重做及协同编辑。
结语
AI 的潜力是巨大的,但如果不加以约束和引导,它就像一块未经雕琢的璞玉。通过 定义技能定位、明确边界、构建知识网络,我们可以将通用的 LLM 训练成一位真正懂业务的“领域专家”。
如果你也想让自己的 AI 助手从“入门级”进化为“架构级”,不妨试试这 7 步法。思考过程的质量,决定了代码输出的质量;知识库的深度,决定了技术方案的高度。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)