RAG要被颠覆了?亚马逊最新研究:仅用关键词搜索+Agent,就能达到传统RAG 90%性能,还不用向量数据库
在大模型应用落地中,检索增强生成(RAG) 早已成为解决幻觉、接入私有知识库的标配方案。而提到RAG,大家的第一反应就是向量数据库、嵌入模型、分块策略——似乎这套复杂的链路,是实现高质量知识库问答的必经之路。
但亚马逊AWS的最新研究,直接打破了这个行业共识。在题为《Keyword search is all you need》的论文中,亚马逊团队提出了一个颠覆性结论:基于智能体(Agent)的关键词搜索,无需任何向量数据库和语义检索,就能达到传统RAG系统90%以上的性能表现,在复杂金融文档场景中甚至能反超RAG。
这篇论文不仅用详实的实验击穿了“向量检索是RAG核心”的固有认知,更为轻量化、低成本的大模型知识库落地,提供了一套全新的范式。
一、行业痛点:传统RAG,困在“向量数据库”的枷锁里
自从2020年RAG架构被提出以来,它就成了大模型落地的“事实标准”。通过将文档分块、向量化存入向量数据库,用户查询时先做语义检索匹配相关片段,再交给大模型生成答案,这套流程完美解决了大模型幻觉、知识更新滞后的问题。
但随着行业应用的深入,传统RAG的短板也暴露无遗:
- 集成与维护成本极高:一套完整的RAG系统需要搭配嵌入模型、向量数据库、分块策略调优,开发链路复杂;知识库每次更新,都需要重新执行分块、嵌入、索引入库的全流程,对于高频更新的场景极不友好。
- 检索质量强依赖人工调优:分块大小、重叠率、检索条数、嵌入模型选型,都会直接影响最终效果,很多时候RAG效果差,本质是人工调优没做到位。
- 复杂文档处理能力拉胯:面对带表格、长段落、复杂结构的PDF文档(如上市公司财报、技术白皮书),固定分块策略很容易把完整信息拆碎,导致语义检索根本找不到正确的上下文。
正是这些痛点,让研究者开始思考:语义检索和向量数据库,真的是RAG不可缺少的部分吗?有没有更简单、更低成本的方案?
二、破局方案:Agent+关键词搜索,扔掉向量数据库也能打
亚马逊团队给出的答案,是一套基于工具增强的Agentic关键词搜索框架。它的核心逻辑极其简单:不用分块、不用嵌入、不用向量数据库,直接让大模型通过ReAct推理框架,自主调用Linux命令行工具,在原始文档中做关键词/正则搜索,迭代获取上下文,最终生成答案。
两种方案的核心流程对比如下图所示:
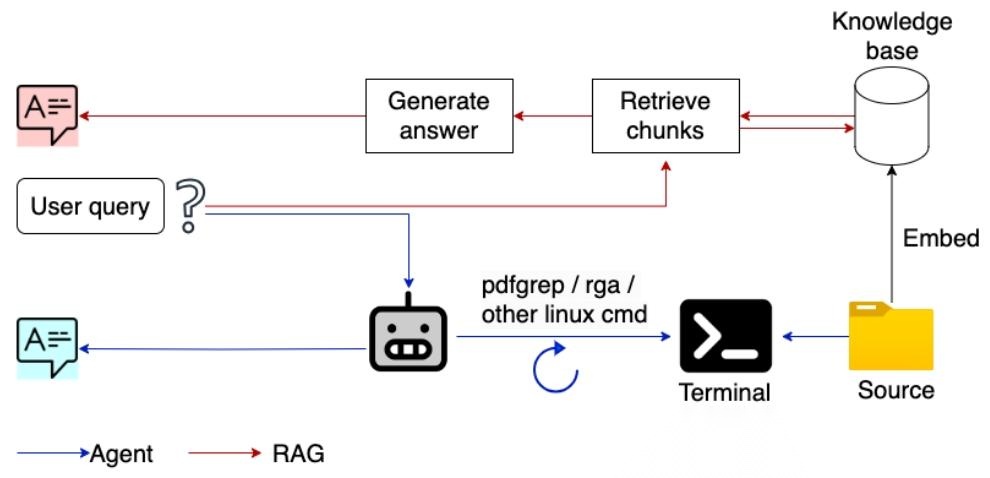
图1:RAG与Agent-based QnA管线对比,红色为传统RAG流程,蓝色为本文提出的Agent搜索流程*
整个Agent的工作流,被封装成了一套可迭代的搜索算法,核心步骤如下:
- 初始阶段,Agent先执行脚本读取目标文件夹内所有文档的元数据,先搞清楚“有哪些文档、分别是什么主题”;
- 基于用户查询,Agent自主生成rga/pdfgrep等Linux搜索命令,在Shell中执行,获取关键词匹配的原文上下文;
- 根据搜索结果,判断是否需要补充搜索、调整关键词/正则,还是已经获取了足够的信息生成答案;
- 迭代执行搜索-判断流程,直到达到最大迭代次数,或找到完整答案后停止搜索,输出最终结果。
这套方案最惊艳的地方,是它把“信息检索”的决策权完全交给了大模型的推理能力,而非固定的语义检索算法。Agent可以根据查询的复杂程度,自主决定做宽泛搜索还是精准定位,甚至可以通过多轮搜索补全上下文,彻底摆脱了传统RAG固定分块的限制。
三、核心实验:90%性能追平RAG,复杂场景直接反超
为了验证这套方案的有效性,亚马逊团队做了全面的对照实验,用标准RAG系统作为基线,在6个覆盖不同领域、不同难度的数据集上做了横向对比,最终用RAGAS框架做了全维度评估。
实验设置
- • 基线RAG方案:亚马逊Bedrock平台,Titan Text V2嵌入模型(1024维),300token分块+20%重叠,OpenSearch无服务向量索引,Anthropic Claude 3 Sonnet生成答案。
- • Agent搜索方案:同样基于Claude 3 Sonnet模型,LangChain ReAct框架,可调用pdfmetadata、rga、pdfgrep三款Shell工具,温度设置为0.001保证结果稳定。
- • 评估指标:忠实度(Faithfulness)、上下文召回率(Context Recall)、答案正确率(Answer Correctness),均为RAG领域的核心评估标准。
核心结果:全维度追平传统RAG
实验结果如下表所示,其中Attainment(达成率)代表Agent方案达到传统RAG基线的性能百分比:
| 数据集名称 | 忠实度 | 上下文召回率 | 答案正确率 | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Agent | RAG | 达成率(%) | Agent | RAG | 达成率(%) | Agent | RAG | 达成率(%) | |
| PaulGrahamEssay | 0.8662 | 0.9056 | 95.65 | 0.7527 | 0.8583 | 87.70 | 0.5808 | 0.7268 | 79.91 |
| Llama2Paper | 0.7252 | 0.8199 | 88.45 | 0.6148 | 0.8713 | 70.56 | 0.5823 | 0.6661 | 87.42 |
| HistoryOfAlexnet | 0.7280 | 0.7657 | 95.08 | 0.6968 | 0.8330 | 83.65 | 0.6406 | 0.7073 | 90.57 |
| BlockchainSolana | 0.8122 | 0.8627 | 94.15 | 0.7422 | 0.7450 | 99.62 | 0.5870 | 0.5872 | 99.97 |
| LLM Survey paper | 0.8061 | 0.8121 | 99.26 | 0.6355 | 0.6438 | 98.71 | 0.5123 | 0.5148 | 99.51 |
| 平均 | 94.52 | 88.05 | 91.48 |
表1:Agent与RAG在各数据集上的指标对比,平均达成率超90%
从结果可以看到,这套无向量数据库的Agent方案,实现了极其亮眼的表现:
- • 平均忠实度达到RAG的94.52%,保证了生成答案的事实一致性,有效抑制幻觉;
- • 平均上下文召回率达到88.05%,在技术文档场景中几乎与RAG持平;
- • 平均答案正确率达到91.48%,其中Solana区块链、LLM综述两个数据集,正确率达成率分别达到99.97%和99.51%,与传统RAG几乎没有差距。
下图直观展示了这两个核心数据集上,Agent与RAG的指标覆盖度对比,二者的柱子几乎完全重合:
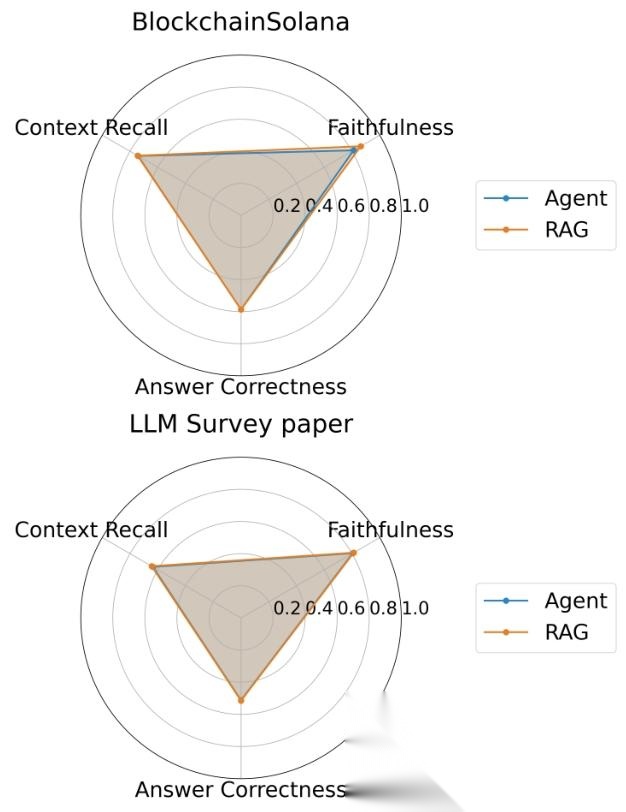
图2:BlockchainSolana与LLM Survey Paper数据集上,Agent与RAG的指标覆盖对比*
炸裂发现:复杂金融文档,Agent反超RAG6个百分点
如果说常规数据集上Agent是“追平RAG”,那在高难度的FinanceBench金融财报数据集上,Agent方案实现了对传统RAG的全面反超。
这个数据集包含上市公司10-K、10-Q财报、业绩公告等,充斥着大量表格、交叉引用和专业术语,是传统RAG的“老大难”场景。实验结果如下表所示:
| 系统配置 | 答案正确率(%) |
|---|---|
| 传统RAG | 24.24 |
| Agent(3轮平均) | 32.71 |
| Agent(第4轮) | 39.64 |
表2:FinanceBench数据集上,Agent与RAG的答案正确率对比
传统RAG的正确率仅为24.24%,而Agent方案平均正确率达到32.71%,最高达到39.64%,相对提升超60%,绝对提升近16个百分点。
背后的核心原因,是传统RAG的固定分块会把财报中的表格、跨页数据拆得支离破碎,语义检索根本无法获取完整的上下文;而Agent可以通过关键词精准定位到相关表格和段落,自主获取完整的上下文信息,完美解决了复杂结构文档的检索难题。
四、方案优势与局限:什么时候该扔掉向量数据库?
核心优势
- 极致的低成本与易用性:无需维护向量数据库,省去嵌入模型调用、分块调优、索引更新的所有成本,新增文档直接丢入文件夹即可,零成本更新知识库。
- 复杂文档处理能力更强:对于带表格、跨页引用、复杂结构的PDF文档,效果远超固定分块的传统RAG。
- 极高的可复现性:纯命令行工具实现,无需复杂的环境配置,比Claude Computer Use等GUI操作方案更稳定、更易复现。
- 完美适配高频更新场景:对于政策、财报、新闻等需要频繁更新知识库的场景,彻底摆脱了传统RAG“更新一次就要重跑一次全流程”的痛点。
客观局限
论文中也明确提到了这套方案的短板:在长文档、模糊语义查询、跨段落多跳推理的场景中,性能会有明显下降;对于需要深度语义理解的议论文、散文类文本,效果不如传统RAG;同时也受限于大模型的上下文窗口,无法处理超大规模文档。
五、写在最后
这篇论文的价值,从来不是“彻底干掉RAG和向量数据库”,而是给整个行业提供了一个全新的思路:RAG的核心是“检索增强生成”,而不是“向量检索增强生成”。
在很多实际落地场景中,开发者们过度神化了向量数据库和语义检索,把RAG系统做得越来越复杂,却忽略了“让大模型找到正确信息”这个最本质的目标。而亚马逊的这项研究证明,很多时候,一个简单的Agent+关键词搜索,就足以满足绝大多数场景的需求,还能省去90%的开发和维护成本。
对于行业而言,这篇论文也预示着RAG的发展方向:未来的检索增强,一定是“大模型推理主导、检索工具为辅”的Agentic RAG范式,让大模型自主决定“找什么、去哪找、怎么找”,而非被固定的检索算法束缚住手脚。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)