智能体互评时代开启!PRDBench重塑代码智能体开发能力测评
传统代码基准已趋饱和,项目级工程能力才是 AI 助手的真正考场
首个面向代码智能体工程能力的项目级评测数据集 PRDBench 正式发布。该数据集包含 50 个真实 Python 项目,覆盖 20 个主流领域,共计 1258 个多样化评测点(单元测试 408、Shell 交互 732、文件比对 118)评测表明,当前最优代码智能体开发通过率可达 69.2%,主流模型开发通过率在 11% 到 69% 之间,代码智能体的工程能力仍有巨大提升空间。自动化评测工具 PRDJudge 平均每个项目耗时 7 分钟,API 成本 2.68 美元,其核心评估模型 PRDJudge 与人工评测一致率达 92.7%。
目前该研究论文《Automatically Benchmarking LLM Code Agents through Agent-driven Annotation and Evaluation》已被 AAMAS 2026 接收。

- 论文地址:
https://arxiv.org/abs/2510.24358
PRDBench 的评测榜单未来将由 AGI-Eval 评测社区长期维护更新,欢迎持续关注。榜单和论文地址如下:

01.背景:代码智能体需要更真实的评测基准
近年来,大语言模型驱动的代码智能体能力快速提升,从单文件代码生成向完整项目级软件开发迈进。然而,现有评测基准面临两大瓶颈:
- 传统基准趋于饱和:HumanEval、MBPP 等单文件、单元测试类基准已难以有效区分模型在复杂工程场景下的真实开发与调试能力。
- 项目级基准构建成本高:如 PaperBench 需招募领域专家人工标注,每个任务耗时数天;且评测方式单一(多依赖单元测试),无法覆盖集成测试、命令行交互、文件比对等工程实践中的多样化质量保障需求。
因此,业界亟需一种低成本、高逼真度的项目级评测方案。
02.PRDBench:智能体驱动的项目级评测数据集
PRDBench 是一套面向大模型代码智能体工程能力的专业评测数据集,专注于项目级自动化开发与评测。其核心设计如下:
2.1 数据种子来源
项目需求来自 AI 产品开发平台的实际 prompt、CNKI 学术论文、大学课程作业项目,所有任务均可用 Python 实现。
2.2 智能体驱动的数据生产流程
PRDBench 采用智能体驱动的人工督导标注流程,大幅降低人工成本。仅需具备本科计算机基础知识的标注者,平均每个项目 8 小时即可完成,而传统方法需专家数天。
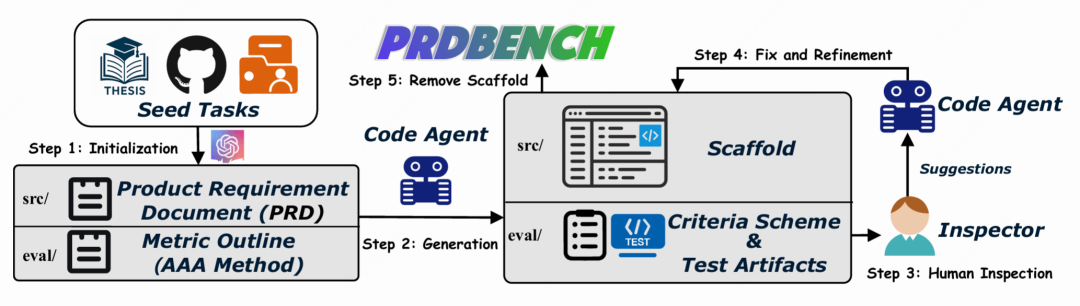
△图1:PRDBench数据生产流程概览
- Step1 PRD 与测试计划初始化:利用 SOTA 模型(如GPT-4.1、Claude Code)生成详细 PRD 及初步测试计划,采用 AAA(Arrange-Act-Assert)范式结构化测试点。
- Step2 代码脚手架与评测标准生成:由代码智能体自动生成项目结构和接口设计,并扩展测试计划为具体评测标准(criteria scheme)。
- Step3 人工验收:人工仅需验证评测标准与代码接口是否匹配、预期输出是否合理,无需手动编写测试用例或参考实现。
- Step4 智能体修正与迭代:对发现问题,人工反馈后由智能体自动修正,反复迭代直至通过验收。
- Step5 去除脚手架:仅保留评测标准与 PRD,确保待评测智能体从零实现项目,体现真实开发能力。
2.3 数据样例
以餐饮供应链智能分析与优化系统为例,下面这个PRD 详细描述了针对给定excel文件内 92 家麦当劳门店的配送网络规划需求。
Agent 需解决在复杂地理网络中通过多维加权分析与动态聚类寻找最优仓储位置的核心痛点。开发任务涵盖了数据标准化预处理、基于轮廓系数的 K-means 智能分区、重心法选址结果可视化等核心模块。
相应地,验收规则严密覆盖了单元测试(算法精度)、Shell 交互(环境与数据校验)、代码静态分析(规范检查)及文件输出比对等多种类型,确保了从数学建模到代码实现的全链路可靠性。

△图2:PRDBench任务示例
2.4 数据集统计
PRDBench 包含 50 个真实 Python 项目,覆盖数据处理、机器学习、图像处理、文本分析等 20 个主流领域(图3)。

△图3:PRDBench领域分布
每个项目平均 PRD 描述长达 105 行,代码脚手架平均规模为 2583 行(最短 188 行,最长 9185 行)(图4),确保了任务的真实性与复杂度。
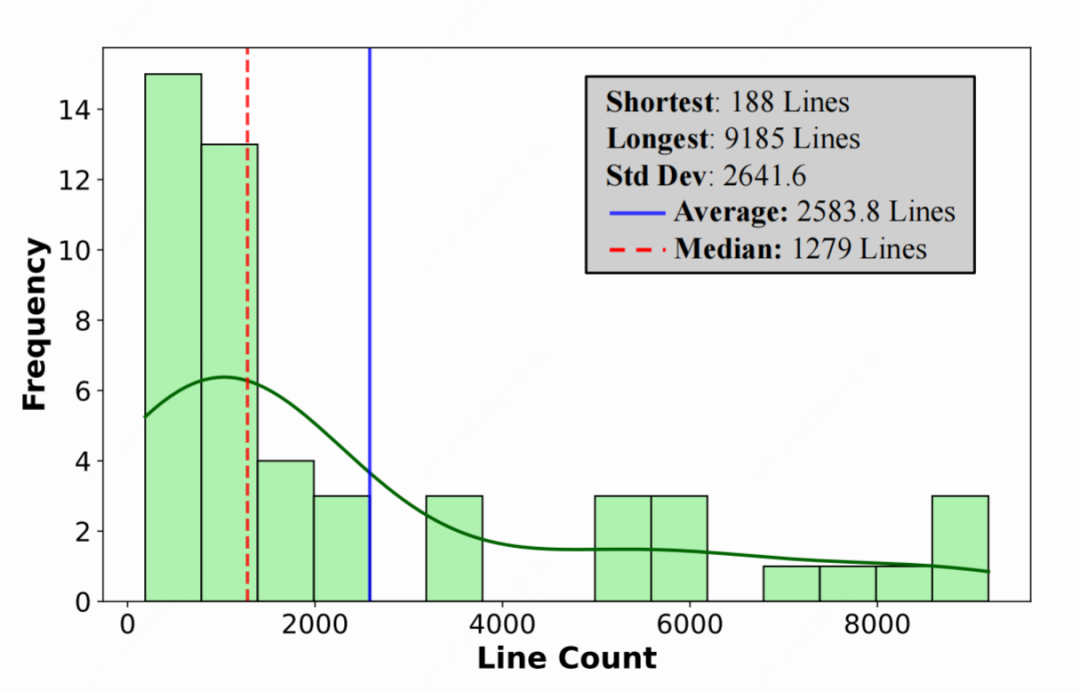
△图4:代码脚手架行数分布
与现有项目级基准相比(表1),PRDBench 在任务多样性、评测点数量和自动化程度上均有显著提升。
△表1:PRDBench与其他项目级代码智能体基准对比
03.项目级代码的“全能考官”:PRDJudge
为支撑大规模可靠评测,我们研发了专用评估模型 PRDJudge(基于 Qwen3-Coder-30B 微调)。PRDJudge 配备六大核心工具(文件读写、命令行执行、图像处理、系统命令、评测工具等),能够自动执行三类测试并生成详细报告(图5)。
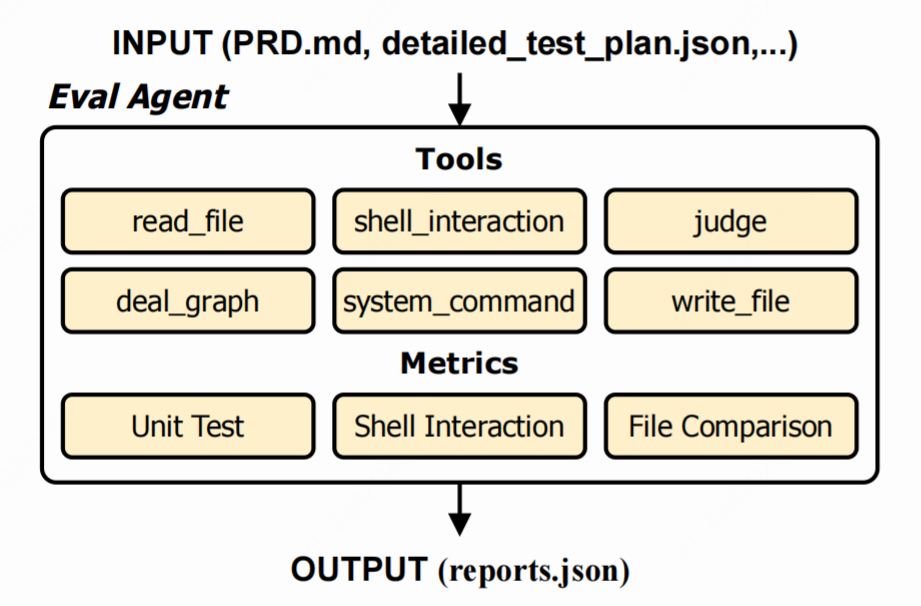
△图5:PRDJudge评测框架概览
- 单元测试:直接运行 pytest 脚本,验证模块功能。
- Shell 交互:模拟用户输入,执行程序并比对输出。
- 文件比对:检查生成文件的内容、格式与目录结构是否符合预期。
为了确保评测的准确性和可靠性,我们为 PRDJudge 制定了明确的评分标准:
- 2分(通过):代码完全执行,输出严格符合预期要求。
- 1分(部分通过):代码成功运行,但输出或行为与预期结果存在差异。
- 0分(失败):代码未能执行,通常由于语法错误、缺少依赖或运行时异常。
在模型训练过程中,我们采用了严格的人工标注和质量控制措施。从初步生成的 2147 条评测轨迹中,经过两轮质量筛选(包括结果匹配与轨迹有效性验证),最终保留了 911 条高质量的训练数据用于微调。这一过程确保了 PRDJudge 能够学习到与人类专家一致的评估标准。
微调后的 PRDJudge 在 PRDBench 上表现出高效、稳定、准确的评估能力(表2):
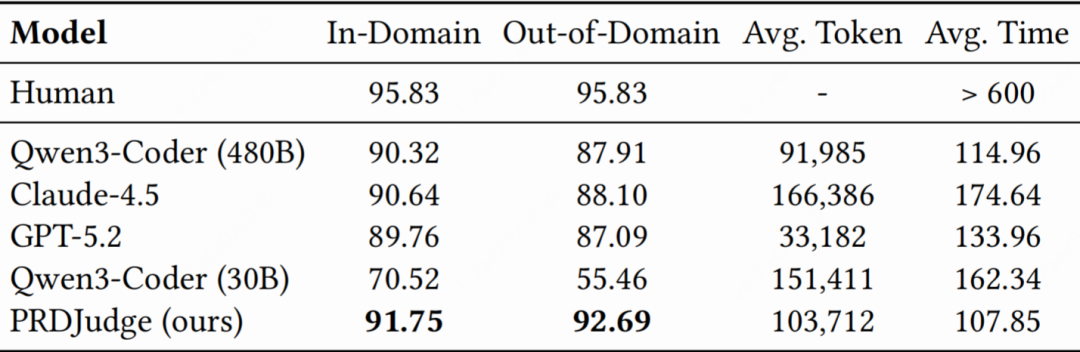
△表2:PRDJudge与基线模型性能对比
- 准确性:PRDJudge 在固定接口场景下与人工评测一致率达91.75%(In-Domain)和 92.69%(Out-of-Domain),大幅超越通用大模型 GPT-5.2 的 87.09%、Claude-4.5 的 88.10%。
- 高效率:PRDJudge 平均每个评估点耗时 107.85 秒,上下文 token 消耗 103,712,在保持高精度的同时实现了高效推理。
各智能体的规格与开源状态详见表3。
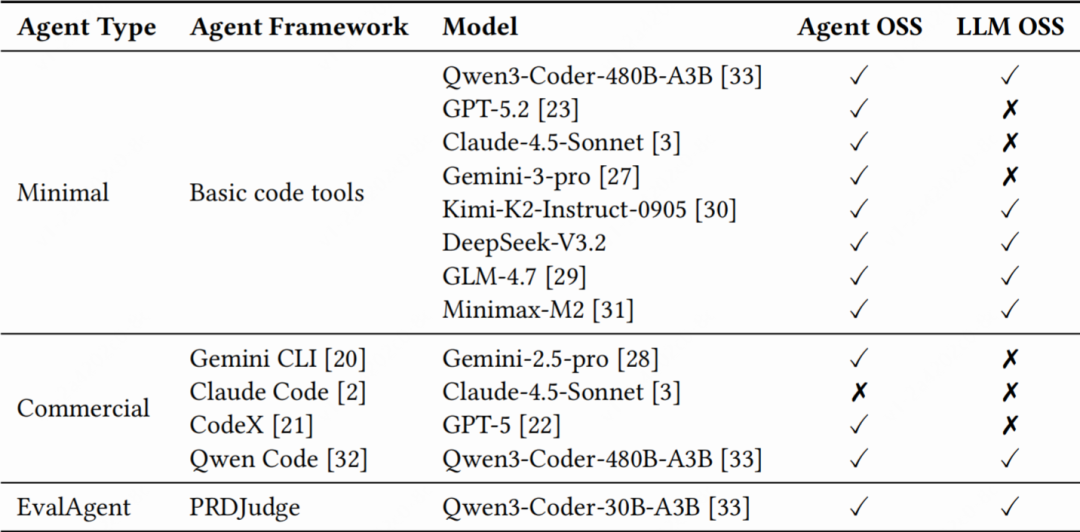
△表3:智能体规格与开源状态
04.评测结果与分析
4.1 任务难度与模型表现
我们在数据集上评测了当前主流代码智能体,包括商业版(Claude Code、Gemini CLI、CodeX、Qwen Code)和基于 ADK 的最小化智能体(使用 Claude-4.5-Sonnet、Gemini-3-Pro、GPT-5.2、Qwen3-Coder 等作为骨干模型)。各模型在开发和调试阶段的平均通过率如 表4 所示。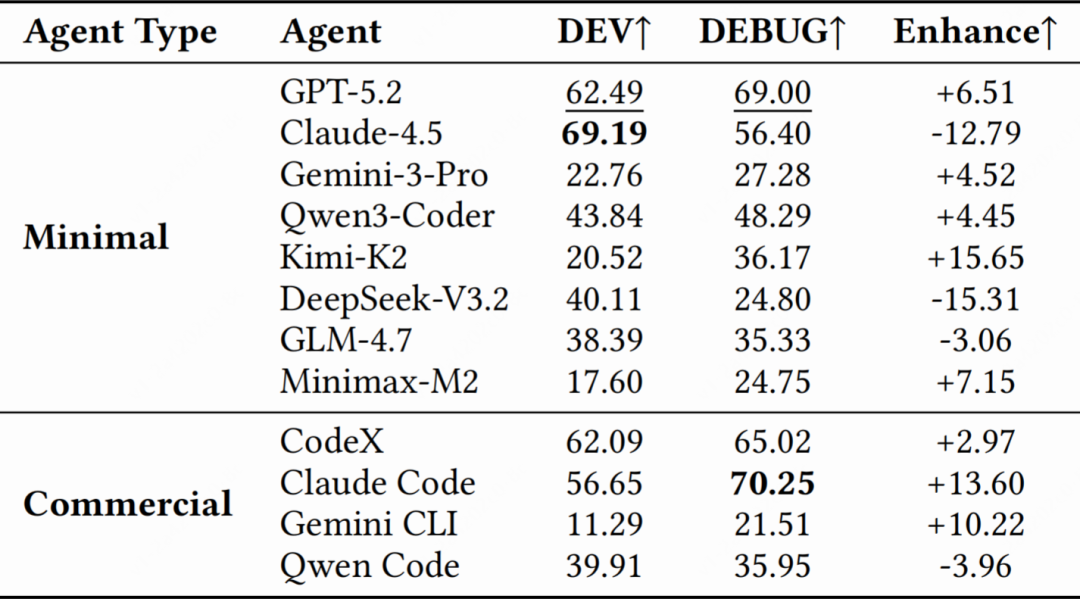
△表4:PRDBench上代码智能体平均通过率(%)
主要发现:
- 开发阶段:最小化智能体中 Claude-4.5 表现最佳,开发通过率达 69.19%;商业智能体中 CodeX 最优,达 62.09%。整体开发通过率范围从 11.29%(Gemini CLI)到 69.19%(Claude-4.5)。
- 调试阶段:提供首轮评测报告后,多数模型通过率有所提升,其中 Claude Code 提升显著,从 56.65% 升至 70.25%;GPT-5.2 从 62.49% 升至 69.00%;但 Claude-4.5 和 DeepSeek-V3.2 出现下降,分别降至 56.40% 和 24.80%,表明调试可能引入回归,模型需要在修复错误的同时保持代码结构稳定。
从测试类型看(图6),三类测试的错误率分布较为均衡,单元测试的调试难度最高(需理解测试代码逻辑),而 Shell 交互和文件比对相对容易(仅需比对输入输出)。
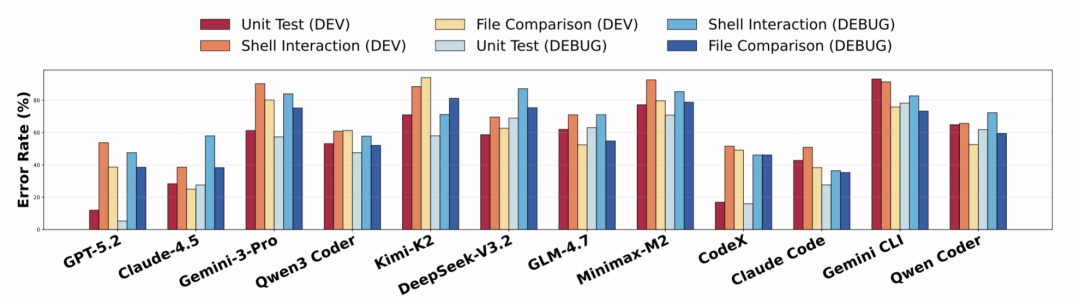
△图6:不同测试类型下代码智能体错误率
4.2 成本分析与自由开发模式
在资源消耗上,商业智能体普遍比最小化智能体耗费更多时间和 token。例如,Gemini CLI 在开发阶段耗时 2740 秒,而最小化 Gemini-3-Pro 耗时 1838 秒。调试阶段,Gemini 的输入 token 消耗是其他模型的 2 倍以上。代码修改量方面,GPT-5.2 和 Gemini-3-Pro 改动较大(约 1500 行),而 Claude Code 和 Qwen Code 仅做微调(约 100 行),体现出不同的调试策略(详见论文表8)。
此外,PRDBench 支持自由开发模式(仅提供 PRD,不固定接口),以模拟真实开发场景。实验显示(图7),自由开发模式下模型得分普遍下降,但相对排名保持稳定,方差更小(0.011 vs 0.028),说明 PRDBench 在两种模式下均能有效区分模型能力。
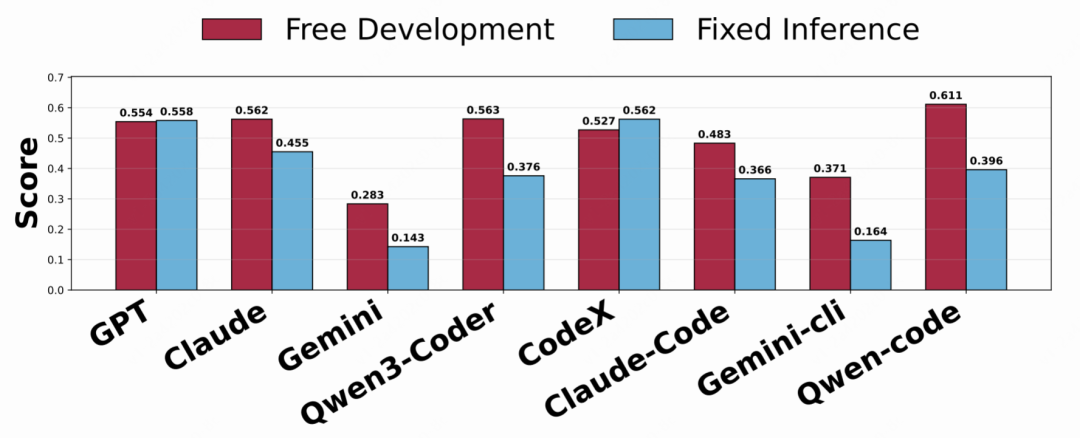
△图7:PRDBench上固定接口与自由开发模式下代码智能体得分对比
在现实的生产力场景下,我们进一步分析了各智能体的性能与成本关系。如图8所示,Qwen3模型、GPT5模型驱动的简易智能体和Claude Code组成了当前code agent的帕累托前沿曲线,分别在各个性能区间段达成了最优的性价比。
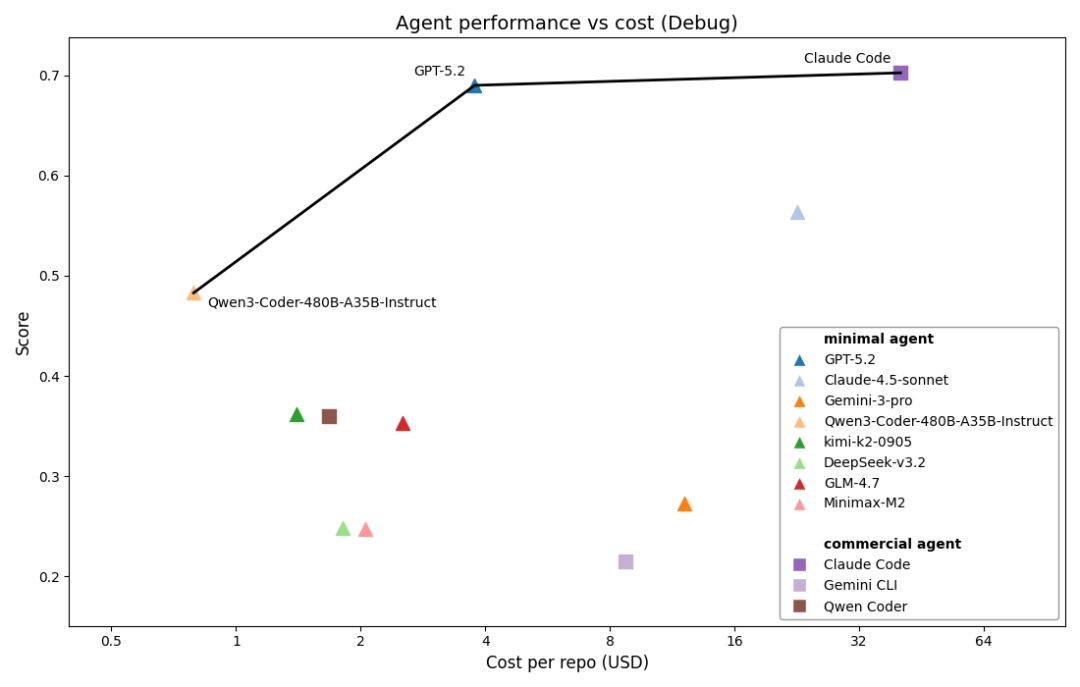
△图8:PRDBench代码智能体得分与花销费用(以官方API价格计算),x轴为对数坐标
05.离线评测与开源
数据集与评测代码已开放:
- 代码仓库:https://github.com/AGI-Eval-Official/PRDBench
- 数据集:https://huggingface.co/datasets/AGI-Eval/PRDbench
- AGI-Eval:https://agi-eval.cn/evaluation/detail?id=126
离线评测脚本正在整理中,预计近期完成。
06.结论与展望
PRDBench 通过智能体驱动的构建与评测,大幅降低了项目级基准的构建成本,同时提供了更贴近工程实践的多样化评测。实验表明,当前最优代码智能体在工程级任务上开发通过率可达 69.2%,但整体平均水平仍待提升,特别是在调试能力上仍有巨大改进空间。
未来,我们将进一步优化 PRDJudge 的稳定性,探索通过 SFT 和强化学习提升其评测准确性,并扩展更多编程语言和工程场景。欢迎广大研究者与开发者使用、贡献,共同推动代码智能体迈向真正的工程级智能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)