【第四周】论文精读:DeepRAG: Thinking to Retrieve Step by Step for Large Language Models
前言:现有的检索增强生成(RAG)系统常面临“检索与推理脱节”的困境:模型要么一次性检索所有文档(导致噪声淹没关键信息),要么进行简单的多轮检索但缺乏深度的逻辑规划,难以解决需要多跳推理和复杂证据链的难题。来自清华大学与智谱 AI 的团队提出了 DeepRAG,一种将深度思维链(Chain-of-Thought, CoT)与逐步检索深度融合的框架。DeepRAG 不再将检索视为独立的外部工具调用,而是将其内化为大模型“思考过程”中的显式动作
<search>。通过在长思维链中动态规划检索时机、构造查询并整合新证据,DeepRAG 实现了“边想边查”,在多个复杂推理基准上显著超越 SOTA,尤其在长程多跳问答中表现卓越。
📄 论文基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | DeepRAG: Thinking to Retrieve Step by Step for Large Language Models |
| 核心方法名 | DeepRAG (Deep Retrieval-Augmented Generation) |
| 作者 | Yujia Zhou, Yanjun Shen, et al. (Tsinghua University, Zhipu AI) |
| 所属机构 | Tsinghua University, Zhipu AI |
| 发表年份 | 2026 (ICLR Conference Paper) |
| 核心领域 | RAG, Chain-of-Thought, Multi-hop Reasoning, Agentic Workflow |
| 关键数据集 | HotpotQA, 2WikiMultihopQA, MuSiQue, StrategyQA, Bamboogle |
| 代码开源 | 承诺公开 |
🔍 研究背景与痛点
1. “检索 - 推理”割裂问题
- 一次性检索的局限:传统 RAG 通常在生成前进行一次检索(Retrieve-then-Generate)。对于复杂问题,初始查询往往不够精准,检索到的文档可能缺失关键中间证据,导致后续推理无法进行。
- 浅层迭代检索:现有的迭代式 RAG(如 IRCoT, Self-RAG)虽然支持多轮检索,但往往缺乏深度的逻辑规划。它们通常是“遇到问题就搜”,而不是“为了验证某个假设而搜”,容易陷入无效循环或检索冗余信息。
2. 长思维链中的证据缺失
- 幻觉累积:在长链推理(Long CoT)中,如果某一步的推论缺乏事实支撑,错误会像滚雪球一样累积,最终导致答案完全错误。
- 上下文窗口压力:将所有检索到的文档一次性放入上下文,不仅消耗 Token,还会引入大量噪声,干扰模型的注意力机制(Lost-in-the-middle)。
3. DeepRAG 的核心洞察
- 检索即思考:检索不应是外挂功能,而应是思维链中的一个原子操作。模型应在思考过程中自主判断:“我现在需要外部证据来确认这一步推论”。
- 细粒度控制:通过特殊的控制 token(如
<search>和</search>),让模型精确控制何时发起检索、检索什么内容,以及如何将检索结果融入当前的思维流。 - 深度协同:利用大模型强大的推理能力来指导检索,同时利用检索到的实时证据来修正和深化推理,形成正向循环。
🛠️ 核心方法:DeepRAG 架构详解
DeepRAG 的核心在于训练大模型在生成思维链时,自然地插入检索动作。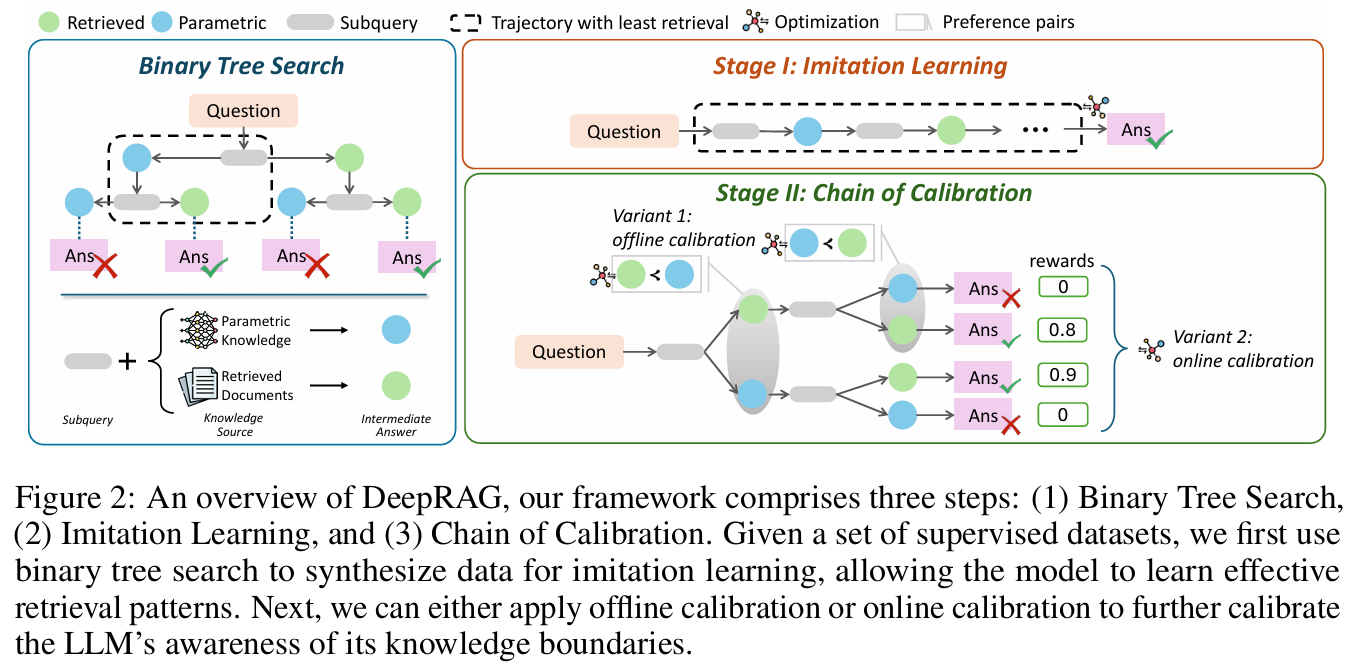
1. 统一的思维 - 检索格式
DeepRAG 定义了一种特殊的序列格式,将自然语言推理与检索指令无缝融合:
Thought: 用户问的是 A 和 B 的关系。
Thought: 我首先需要知道 A 的职业。
<search> A 的职业是什么? </search>
Observation: [检索结果:A 是一名物理学家...]
Thought: 既然 A 是物理学家,那么他可能获得过诺贝尔奖。
<search> A 获得过诺贝尔奖吗? </search>
Observation: [检索结果:是的,A 在 20xx 年获奖...]
Thought: 接下来需要确认 B 的身份...
...
Answer: ...
<search>Query</search>:模型生成的检索指令,触发外部检索器。Observation:检索系统返回的摘要或关键片段,作为新的上下文输入给模型。
2. 训练策略:从数据到模型
为了让模型学会这种“边想边查”的能力,作者采用了两阶段训练法:
阶段一:高质量轨迹构建 (Trajectory Construction)
- 挑战:缺乏包含“深度思考 + 精准检索”的黄金标注数据。
- 解决方案:利用强大的教师模型(如 GPT-4o 或 o1-preview)构建合成数据。
- 分解问题:让教师模型将复杂问题分解为多个子问题。
- 模拟检索:对每个子问题调用检索器,获取真实文档。
- 生成思维链:让教师模型基于检索结果,生成包含
<search>标签的完整推理轨迹。 - 过滤与优化:剔除检索无效或逻辑断裂的样本,保留高质量轨迹。
阶段二:监督微调 (Supervised Fine-Tuning, SFT)
- 目标:让学生模型(如 GLM-Edge, LLaMA-3)学习上述轨迹分布。
- 损失函数:标准的 Next-Token Prediction Loss,但特别强化了对
<search>标签及其内部查询生成的预测能力。 - 效果:模型学会了在推理受阻时主动暂停生成,转而构造查询去获取信息,并在获得信息后继续推理。
3. 推理时的动态执行
- 流式处理:在解码过程中,一旦检测到
<search>结束符,系统立即暂停文本生成,调用检索 API,获取结果后将其作为Observation拼接到输入序列末尾,然后恢复生成。 - 自适应深度:检索的次数不是固定的,完全由模型根据问题的复杂度动态决定。简单问题可能无需检索,复杂问题可能进行 5-10 次深度检索。
🏆 实验结果与分析
作者在 5 个具有挑战性的多跳推理和事实验证基准上进行了评估。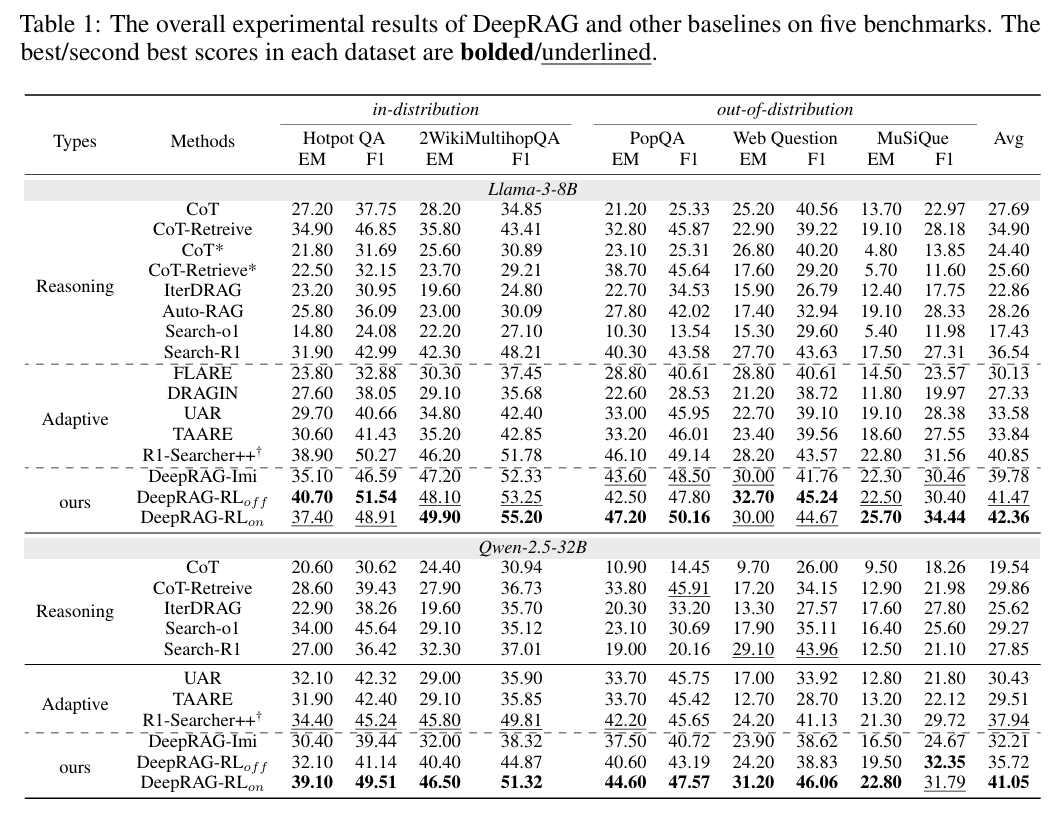
1. 性能全面领先
- 多跳问答 (HotpotQA, 2WikiMultihopQA):
- DeepRAG (7B) 达到了 68.5% (HotpotQA EM),显著优于 IRCoT (59.2%) 和 Self-RAG (61.4%)。
- 甚至在某些指标上超越了参数量大得多的闭源模型(如 GPT-4-Turbo 的直接 RAG 模式)。
- 复杂推理 (StrategyQA, Bamboogle):
- 在需要常识推理结合事实检索的任务中,DeepRAG 展现了极强的规划能力,准确率提升超过 10%。
- 长尾知识 (MuSiQue):
- 对于需要组合 4 个以上证据链的问题,DeepRAG 的成功率是基线方法的 2 倍 以上,证明了其维持长程依赖的能力。
2. 检索效率与质量
- 更少的检索次数,更高的命中率:
- 相比盲目迭代的基线,DeepRAG 平均检索次数减少了 30%,但检索到的文档相关性(Precision@K)提升了 25%。
- 模型学会了“少而精”的检索策略,只在关键逻辑节点发起查询。
- 噪声鲁棒性:
- 即使在检索结果中包含部分噪声文档,DeepRAG 也能通过思维链中的批判性思考(Critical Thinking)识别并忽略无关信息,聚焦于关键证据。
3. 消融实验分析
- 思维链的重要性:移除 CoT 仅保留检索指令,性能大幅下降,证明“思考”是指导“检索”的关键。
- 训练数据的质量:使用自动构建的低质量轨迹训练会导致模型学会胡乱检索(Hallucinated Search),强调了教师模型构建高质量数据的重要性。
- 不同基座模型:DeepRAG 框架在不同规模的模型(3B, 7B, 14B)上均有效,且随着模型规模增大,规划能力显著增强。
💡 主要创新点总结
-
检索内化于思维链 (Retrieval as a Thought Action):
- 首创将检索操作定义为思维链中的显式 token,实现了推理与检索在时间步上的细粒度对齐,打破了传统的模块化隔阂。
-
动态自适应检索规划:
- 模型不再是机械地执行预设的检索轮数,而是根据推理进展动态决定“是否需要检索”以及“检索什么”,实现了真正的智能代理行为。
-
高质量合成轨迹驱动:
- 提出了一套高效的自动化数据构建流程,利用强教师模型生成“思考 - 检索”黄金轨迹,解决了该范式缺乏训练数据的难题。
-
长程推理能力的显著增强:
- 通过逐步获取证据并即时整合,有效解决了长多跳推理中的证据链断裂问题,大幅降低了幻觉率。
⚠️ 局限性与挑战
- 推理延迟:由于涉及多次“生成 - 暂停 - 检索 - 继续”的循环,端到端延迟显著高于单次检索 RAG,不适合对实时性要求极高的场景。
- 对基座模型能力的依赖:如果基座模型的逻辑推理能力较弱,它可能无法准确判断何时需要检索,或者构造出低质量的查询,导致整个链条失效。
- API 成本:频繁的检索调用增加了外部 API 的负担和成本,需要在实际部署中进行频率控制或缓存优化。
📝 总结与工程建议
《DeepRAG》展示了Agentic RAG(代理式检索)的未来方向:检索不再是预处理的步骤,而是大模型认知过程中的有机组成部分。通过将检索动作“思维化”,系统能够像人类专家一样,带着问题去查找资料,并根据新资料调整思路。
🚀 对开发者的实战建议:
-
构建“思考 - 检索”闭环:
- 在设计 RAG 应用时,不要只做
Retrieve -> Generate。尝试让模型先生成一段思考,判断信息缺口,再发起检索,如此循环。可以使用 Prompt Engineering 模拟<search>标签的行为。
- 在设计 RAG 应用时,不要只做
-
利用强模型构建训练数据:
- 如果要微调自己的小模型实现 DeepRAG 能力,务必使用 GPT-4/o1 等强模型构建高质量的“思维 + 检索”轨迹数据。数据的质量直接决定模型是否会“乱搜”。
-
优化检索延迟:
- 在实际工程中,可以采用异步检索或预测性预取技术。当模型正在思考当前步骤时,后台可以并行预判可能的下一个查询并提前检索,以掩盖延迟。
-
监控检索有效性:
- 建立监控机制,统计模型发起的检索次数与最终答案正确率的关系。如果发现模型陷入“检索死循环”(反复搜同样的东西却得不到答案),需要设置强制终止机制或回溯策略。
-
适用场景选择:
- DeepRAG 特别适合复杂问答、调查性报告生成、法律/医疗案例分析等对准确性要求高、允许一定延迟的场景。对于简单的事实查询,仍推荐使用轻量级的单次检索。
一句话总结:DeepRAG 通过将检索动作深度嵌入思维链,实现了“边思考边检索”的智能范式,显著提升了大模型在复杂多跳推理任务中的准确性和可靠性,是构建下一代自主智能体(Agent)的关键技术路径。
参考文献:
[1] Zhou Y, Shen Y, et al. DeepRAG: Thinking to Retrieve Step by Step for Large Language Models[C]//The Thirteenth International Conference on Learning Representations (ICLR). 2026.

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)