DOLA: DECODING BY CONTRASTING LAYERS IMPROVESFACTUALITY IN LARGE LANGUAGE MODELS
ICLR 2024

摘要
尽管大语言模型(LLMs)具备出色的能力,但它们容易产生**幻觉**,即生成与预训练所见事实不符的内容。本文针对预训练大语言模型,提出一种简洁的解码策略以降低幻觉。该方法既不需要依托检索得到的外部知识,也无需额外微调。 利用“大语言模型中的事实知识通常集中分布在特定 Transformer 层”这一特性,我们将深层和浅层隐状态映射到词表空间,并对比两者的对数概率分布,从而得到下一词的输出分布。 我们发现,这种**层间对比解码方法(DoLa)**能够更好地激活模型中的事实知识,减少错误事实的生成。在多项选择题和开放式生成任务中,DoLa 均稳定提升了模型的事实保真度。例如,在 TruthfulQA 数据集上,该方法将 LLaMA 系列模型的性能**绝对提升了 12%–17%**,证明其能够有效提升大语言模型生成真实、可靠内容的能力。
1 引言
大语言模型(LLM)在众多自然语言处理(NLP)任务中展现出巨大潜力(Brown 等人,2020;OpenAI,2022、2023)。然而,尽管随着模型规模扩大,大语言模型的性能不断提升、能力持续增强(Wei 等人,2022a),但**幻觉问题**始终难以解决。所谓幻觉,是指模型生成与预训练阶段所见真实事实不符的内容(Ji 等人,2023)。这已成为模型落地应用的一大瓶颈,尤其在医疗、法律等高风险场景中,文本输出的真实性与可靠性至关重要。 目前,大语言模型产生幻觉的内在机理尚未被完全揭示。一种主流观点认为,根源在于**最大似然语言建模目标**:该目标最小化数据分布与模型分布之间的前向 KL 散度,容易使模型产生“聚集偏好”,导致模型会为不符合训练数据内置知识的语句分配非零概率。实验表明,在有限数据上基于预测下一词任务训练的语言模型,往往只会学习浅层语言模式,而非理解并生成训练语料中的真实事实(Ji 等人,2023)。 从模型可解释性角度来看,研究发现 Transformer 语言模型会分层编码信息:浅层主要存储词性等**底层基础信息**,深层则包含更多**语义信息**(Tenney 等人,2019)。后续研究中,Dai 等人(2022)发现预训练 BERT 模型的顶层分布着“知识神经元”;Meng 等人(2022)证明,通过修改自回归语言模型中部分前馈层,即可编辑模型中的事实知识。 基于上述分层编码特性,本文提出利用**对比解码**放大模型中的事实知识:通过计算模型深层与浅层输出对数概率的差值,得到最终下一词预测分布。侧重强化深层知识、弱化浅层信息,从而提升模型生成内容的事实性,降低幻觉概率。
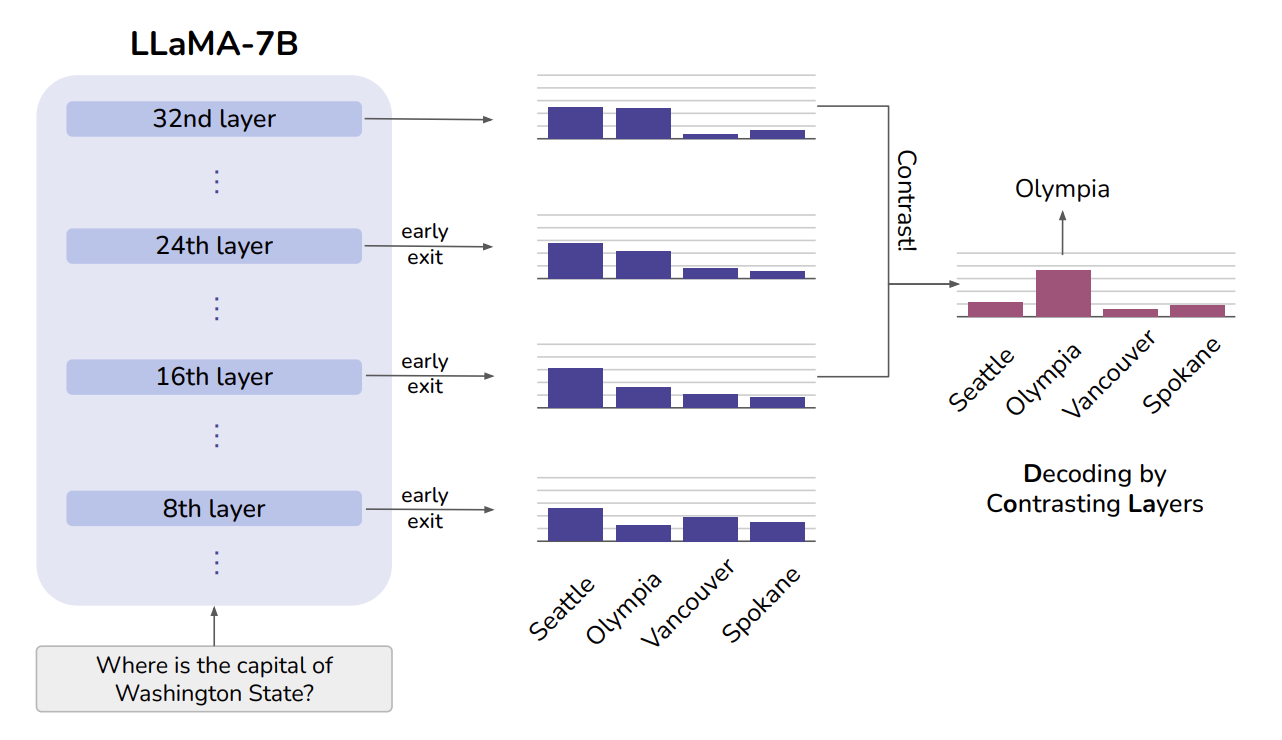
图 1 给出了直观示例:候选词“西雅图”在所有网络层中都保持较高概率(语法合理);而正确答案“奥林匹亚”的概率,会随着层数加深、事实知识注入而逐步升高。因此,通过对比不同层的概率差异,能够筛选出符合事实的正确答案。基于该思路,本文提出**层间对比解码方法(DoLa)**。该方法无需检索外部知识、无需额外微调,即可激活大语言模型内置的事实知识。 在 TruthfulQA(Lin 等人,2022)和 FACTOR(Muhlgay 等人,2023)数据集上的实验表明,DoLa 能够显著提升 LLaMA 系列模型的事实保真度。在 StrategyQA(Geva 等人,2021)和 GSM8K(Cobbe 等人,2021)的思维链推理任务中,DoLa 也能生成更贴合事实的推理过程。此外,基于 GPT-4 的开放式对话评测(Chiang 等人,2023)显示,相较于原始解码方法,DoLa 生成的回复信息丰富、事实性更强,评测得分更高。在效率方面,DoLa 仅会带来少量解码延迟,实用性强,是一种高效提升大语言模型事实性的解码策略。
2 方法
现有大语言模型由嵌入层、N 层堆叠的 Transformer 层以及一个用于预测下一词分布的仿射层 构成。给定词元序列 $\{x_1,x_2,\dots,x_{t-1}\}$,嵌入层首先将词元映射为向量序列
。随后,$H^0$ 依次经过每一层 Transformer 处理,记第 $j$ 层的输出为 $H^j$。最后,词表投影头 $\phi(\cdot)$ 根据最终隐状态预测下一个词元 $x_t$ 在词表 $\mathcal{X}$ 上的概率:
本文不只用最后一层做预测,而是**对比高层与低层信息**得到下一词概率。
具体来说,对若干浅层候选层 ,同样用
计算输出分布:
将分类头直接作用于中间层隐状态,这一做法称为**早退出(early exit)**(Teerapittayanon 等人,2016;Elbayad 等人,2020;Schuster 等人,2022)。由于 Transformer 中的残差连接(He 等人,2016)使得隐表示平滑演化、不会突变,即使不额外训练,早退出也具备良好效果(Kao 等人,2020)。 为简化记号,记
。最终下一词概率表示为:
其中 这里,第M 层称为**浅层(早熟层,premature layer)**,最后一层 $N$ 称为**深层(成熟层,mature layer)**。算子
详见 2.3 节:它在对数空间对两层分布做差值,实现浅层与深层分布的对比。 在每一步解码中,利用成熟层与候选层之间的分布距离度量
(本文使用 JS 散度)**动态选出浅层**。距离越大,说明该层到最后一层的预测变化越大,意味着最后一层补入了更多浅层不具备的事实知识,更适合用来做对比抑制幻觉。
2.1 事实知识在网络层中逐层演化 本文基于 **32 层 LLaMA-7B**(Touvron 等人,2023)展开前置分析。计算各早退出分布 与最后一层分布
之间的 JS 散度,观察两层差异规律,结果见图 2,可以总结出两种现象:
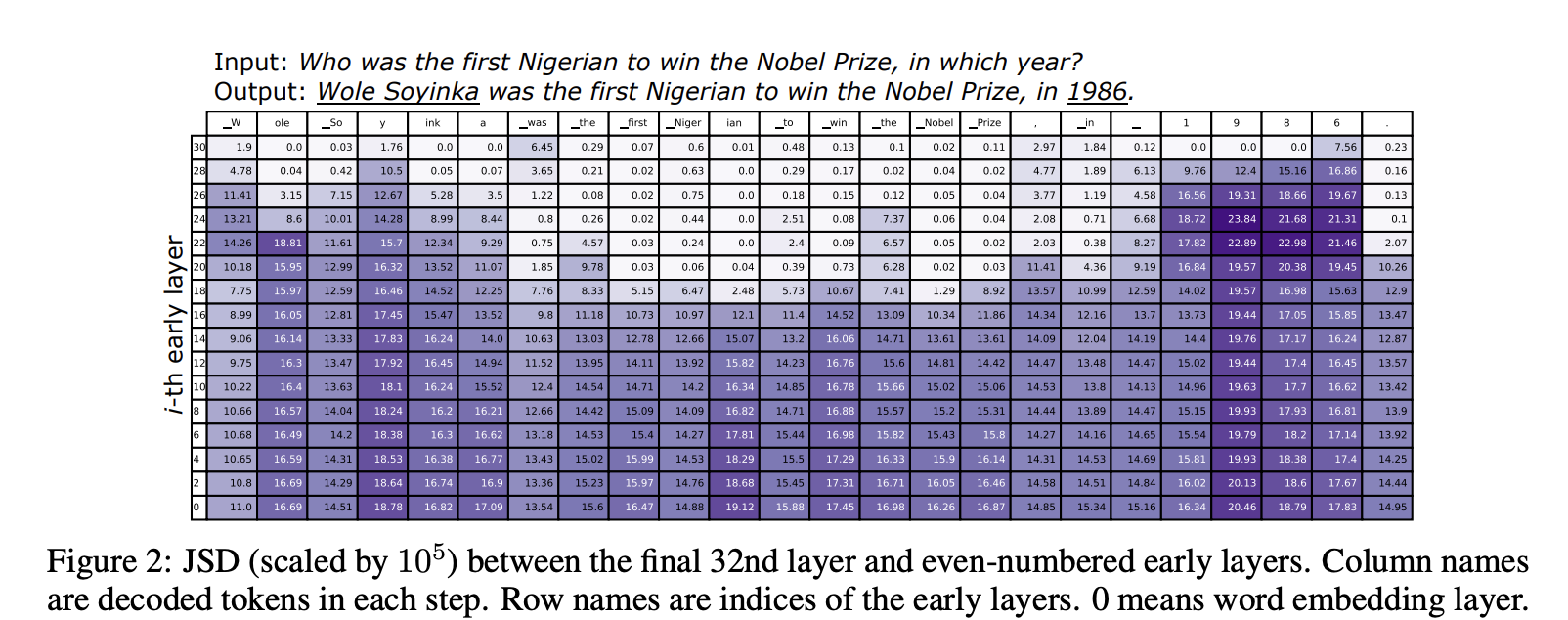
1)**预测实体、年份等依赖事实的词元**(如图中的 Wole Soyinka、1986):高层之间 JS 散度仍然很大。说明模型在后几层仍在修正预测、持续注入事实知识。
2)**预测虚词、模板词、输入复用词**(如 was、the、to、in,以及 first Nigerian、Nobel Prize):从中层开始 JS 散度就很小。说明这类简单词在中层就已确定,高层几乎不再改变分布,与早退出语言模型结论一致(Schuster 等人,2022)。补充定量实验见附录 A。
定性来看:**需要事实的预测,会在高层持续迭代修正**。对比“发生突变前后两层”,可以放大高层新增事实、让模型更依赖内部真实知识。同时,这种逐层信息变化**逐词不同**,固定浅层效果不稳。因此本文提出**动态浅层选取策略**(见图 3)。
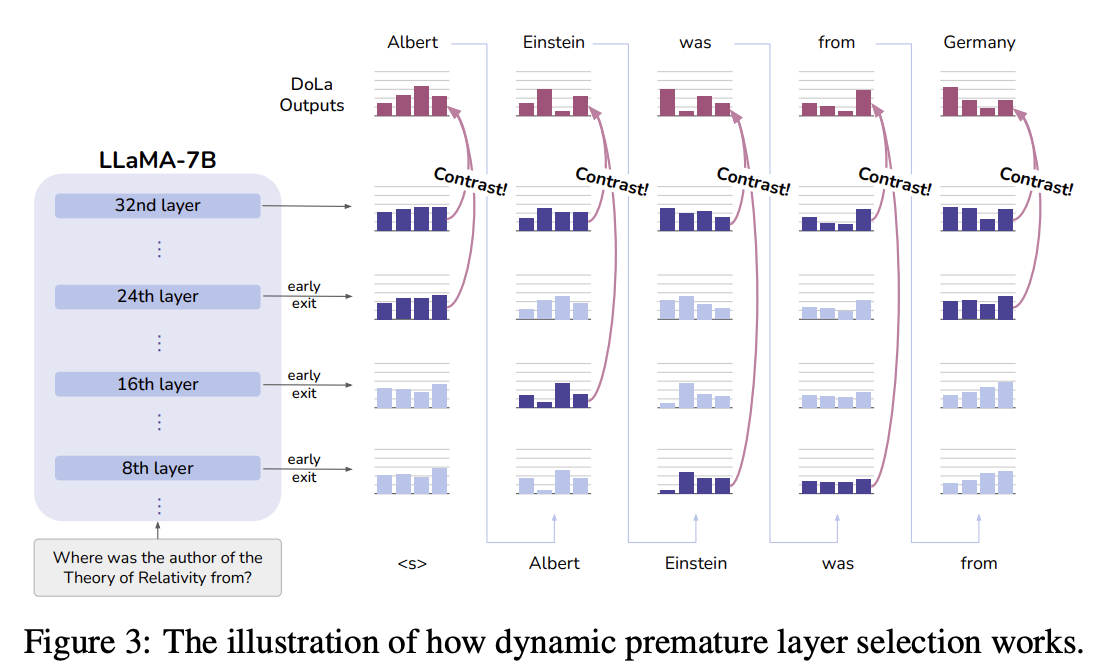
2.2 动态浅层选取 想要最大化对比解码效果,最优浅层应与最后一层分布差异最大。每一步解码,两层分布之间距离定义为: 其中 JSD 为 JS 散度。在候选集合J 中,选出散度最大一层作为浅层:
针对不同层数的 LLaMA,按照总层数把层划分为 2~4 组候选区间 J,只在区间内对比;每组最优区间由验证集选出,详见 3.1 节。该策略可以根据词元难易自适应选层,更好利用分层知识。 对照基线还有一种**静态 DoLa(DoLa-static)**:遍历所有浅层,在验证集上选出固定最优一层。但静态方法存在两点缺陷:① 需要大范围调参搜索层数;② 最优层依赖数据分布,必须要有同源验证集。本文动态选层压缩搜索空间、降低分布依赖、鲁棒性更强。两种策略对比实验见 4.1 节。
2.3 预测结果对比
基于 2.2 节得到的早熟层(浅层)与成熟层(深层),本节旨在**放大深层输出、抑制浅层输出**。参照对比解码方法(Li 等人,2022),将深层对数概率减去浅层对数概率,得到最终的下一词预测分布,如图 1 所示: 其中
沿用 Li 等人(2022)的定义,候选子集 由深层概率足够高的词元构成:
如果某个词元在深层中的原始概率过低,基本不可能是合理结果,因此将其概率置为 0,减少**误增(假阳性)**和**误减(假阴性)问题。 -
**假阳性**:有些本身不合理、原始概率很低的词,由于不同浅层/深层在低概率区间波动较大,经过比值放大后反而变高,被错误选中。
- **假阴性**:对于简单词,各层概率差别不大,对比之后分数变低,容易被漏掉。 为此需要限制只能从高概率候选中采样。该做法即为 Li 等人(2022)提出的**自适应合理性约束(APC)**。 **重复惩罚**。DoLa 的初衷是压低浅层语法信息、突出真实事实信息。理论上可能导致语句语法变差,但实验中并未观察到该问题。不过我们发现,DoLa 更容易出现**生成重复语句**的现象(Xu 等人,2022),尤其是在长思维链推理中。因此,解码时加入 Keskar 等人(2019)提出的重复惩罚,设置系数 $\theta=1.2$。关于重复惩罚的消融分析见附录 K
3 实验设置
3.1 实验配置 **数据集**。本文同时考察选择题和开放式生成任务: - 选择题:使用 TruthfulQA(短答案事实性)、FACTOR(新闻/维基,长段落事实性)评测模型事实保真度; - 开放式生成:TruthfulQA(由微调 GPT-3 打分)、含思维链推理的 StrategyQA、GSM8K; - 对话评测:Vicuna QA,由 GPT-4 评测模型作为对话助手的指令跟随能力。 **实验模型与基线方法**。测试四种规模的 LLaMA(7B、13B、33B、65B),对比三组基线: 1)原始解码(根据任务使用贪心解码或采样); 2)对比解码 CD:7B 作为弱模型,13B/33B/65B 作为强模型; 3)推理干预 ITI:基于 LLaMA-7B 和在 TruthfulQA 上训练的线性分类器。 为保证实验干净可控,本文只对比 DoLa 的**层间差异**和 CD 的**模型差异**,不额外限制浅层/弱模型上下文长度等技巧。参照已有工作,自适应合理性约束参数 $\alpha$ 设为 0.1,重复惩罚系数 $\theta$ 设为 1.2。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)