递归不是长上下文的解药,自反思才是:SRLM 用不确定性信号让 LLM 超越 RLM 22%
递归不是长上下文的解药,自反思才是:SRLM 用不确定性信号让 LLM 超越 RLM 22%
论文标题:Recursive Language Models Meet Uncertainty: The Surprising Effectiveness of Self-Reflective Program Search for Long Context
作者:Keivan Alizadeh, Parshin Shojaee, Minsik Cho, Mehrdad Farajtabar(Apple)
机构:Apple
论文链接:https://arxiv.org/abs/2603.15653
发布日期:2026年3月7日
一句话摘要:当语言模型面对超长文本时,我们习惯性地认为"递归分解"是正确答案——把长文本切碎、递归调用自身来处理。但 Apple 的这篇论文给出了反直觉的结论:递归并不是 RLM 性能提升的主要驱动力。真正起作用的,是基于不确定性信号的自反思程序搜索。SRLM 通过融合自一致性、推理长度和模型自述置信度三个互补信号,在 BrowseComp+ 数据集上较 RLM 提升高达 22.6%,且在短上下文场景中也保持了一致增益——而 RLM 在短上下文下甚至会拖累基线模型的表现。
1. 问题背景:长上下文推理为什么这么难?
大模型的上下文窗口不断扩大——从 4K 到 128K 再到百万级 token。但"窗口大"并不等于"推理强"。多项研究表明,随着上下文长度增长,模型在检索和推理任务上的准确率会显著下降。
针对这一问题,Recursive Language Models(RLM,arXiv: 2512.24601)提出了一条新思路:将长上下文作为外部环境变量,让 LLM 通过编写程序来切片、查询、聚合上下文,并递归调用自身处理子任务。RLM 展示了处理超出原生窗口两个数量级输入的能力。
但问题来了:递归分解真的是核心贡献吗?还是说,程序化的上下文交互本身就已经足够好了?
SRLM 的回答是:递归只是锦上添花。真正让程序搜索变得可靠的,是不确定性感知的自反思机制。
图1:SRLM 框架总览。模型生成 K 个候选程序轨迹,通过自一致性筛选答案集合,再用语义不确定性和行为不确定性联合打分选出最优程序。
2. 方法设计:三重不确定性信号驱动的程序选择
2.1 程序化上下文交互
给定查询 qqq 和长上下文 C=(c1,c2,…,cN)\mathcal{C} = (c_1, c_2, \ldots, c_N)C=(c1,c2,…,cN),其中 N≫LN \gg LN≫L(LLL 为模型有效上下文窗口),SRLM 不直接将完整上下文喂给模型,而是将其暴露为沙盒编程环境中的外部变量。模型自回归地生成可执行程序 p=(p1,p2,…,pT)p = (p_1, p_2, \ldots, p_T)p=(p1,p2,…,pT),包含切片、查询、聚合等操作,每一步在 REPL 中执行:
et=Exec(pt,et−1,C)e_t = \text{Exec}(p_t, e_{t-1}, \mathcal{C})et=Exec(pt,et−1,C)
关键区别在于:SRLM 不要求显式的递归子调用。它不依赖模型递归调用自身作为工具,而是通过更智能的程序选择来弥补。
2.2 三重不确定性信号
SRLM 独立采样 KKK 个候选程序:p(k)∼πθ(⋅∣q,C),k=1,…,Kp^{(k)} \sim \pi_\theta(\cdot | q, \mathcal{C}), \quad k = 1, \ldots, Kp(k)∼πθ(⋅∣q,C),k=1,…,K,然后通过三个互补信号联合评估:
信号一:采样不确定性——自一致性
统计 KKK 个候选答案的经验频率:
prob(a)=1K∑k=1K1[out(p(k))=a]\text{prob}(a) = \frac{1}{K} \sum_{k=1}^{K} \mathbb{1}[\text{out}(p^{(k)}) = a]prob(a)=K1k=1∑K1[out(p(k))=a]
选出多数票答案 a^=argmaxa∈Aprob(a)\hat{a} = \arg\max_{a \in \mathcal{A}} \text{prob}(a)a^=argmaxa∈Aprob(a),构建一致性候选集 S={p(k):out(p(k))=a^}\mathcal{S} = \{p^{(k)} : \text{out}(p^{(k)}) = \hat{a}\}S={p(k):out(p(k))=a^}。
信号二:语义不确定性——自述置信度
在每个中间生成步骤 ttt,模型输出结构化置信度分数 νt(k)∈(0,100]\nu_t^{(k)} \in (0, 100]νt(k)∈(0,100],在对数空间聚合:
VC(p(k))=∑t=1T(k)log(νt(k)100)≤0\text{VC}(p^{(k)}) = \sum_{t=1}^{T^{(k)}} \log\left(\frac{\nu_t^{(k)}}{100}\right) \leq 0VC(p(k))=t=1∑T(k)log(100νt(k))≤0
越接近 0 表示越有信心。
信号三:行为不确定性——推理长度
总 token 长度 Len(p(k))=∑t=1T(k)ℓt(k)\text{Len}(p^{(k)}) = \sum_{t=1}^{T^{(k)}} \ell_t^{(k)}Len(p(k))=∑t=1T(k)ℓt(k) 作为认知努力的代理指标——已有研究发现,错误的推理轨迹往往比正确的更长、更纠结。
2.3 联合打分与选择
在一致性集合 S\mathcal{S}S 内,对候选程序联合打分:
s(p)=VC(p)⋅Len(p)s(p) = \text{VC}(p) \cdot \text{Len}(p)s(p)=VC(p)⋅Len(p)
由于 VC(p)≤0\text{VC}(p) \leq 0VC(p)≤0 且 Len(p)>0\text{Len}(p) > 0Len(p)>0,乘积越大(越接近0)说明置信度越高、推理越简洁。最终选择:
p∗=argmaxp∈Ss(p),y^=out(p∗)p^* = \arg\max_{p \in \mathcal{S}} s(p), \quad \hat{y} = \text{out}(p^*)p∗=argp∈Smaxs(p),y^=out(p∗)
这一设计优雅且高效——不需要额外的奖励模型或验证器,完全基于模型自身的不确定性信号。
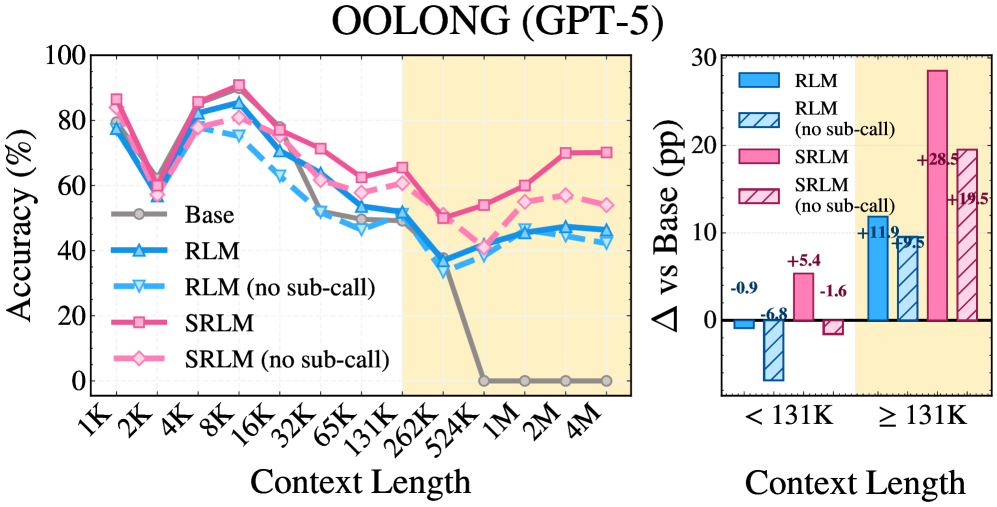
图2:不同上下文长度下的准确率对比。RLM 在短上下文场景中反而拖累基线表现,而 SRLM 在短、长上下文中均保持稳定增益。
3. 实验结果:全面超越 RLM
3.1 实验配置
- 骨干模型:Qwen3-Coder-480B-A35B、GPT-5(中等推理强度)
- 候选数量:K=8K = 8K=8
- 执行时限:每步 600 秒
- 最大交互步数:30 步
- 评估方式:LLM-as-Judge 语义等价判定
基准数据集:
| 数据集 | 规模 | 上下文范围 |
|---|---|---|
| BrowseComp+(1K文档) | 150 实例 | ~1K 文档 |
| OOLONG trec_coarse | 650 任务 | 1K-8M tokens |
| LongBench-v2 CodeQA | 503 实例 | 8K-4M tokens |
3.2 主实验结果
以下是核心性能对比(精度 %):
| 方法 | LongBench-v2 CodeQA | BrowseComp+ 1K | OOLONG 131K |
|---|---|---|---|
| Qwen3-Coder-480B | |||
| Base Model | 20.0 | 0.0 | 36.0 |
| CodeAct + BM25 | 24.0 | 12.7 | 38.0 |
| CodeAct + sub-calls | 26.0 | 0.0 | 32.0 |
| Summary Agent | 50.0 | 38.0 | 44.1 |
| RLM | 59.8 | 37.1 | 45.7 |
| RLM(无子调用) | 53.8 | 36.3 | 39.1 |
| SRLM | 64.9(↑5.1) | 59.7(↑22.6) | 51.8(↑6.1) |
| SRLM(无子调用) | 59.0(↑5.2) | 50.1(↑13.8) | 45.9(↑6.8) |
| GPT-5 | |||
| Base Model | 24.0 | 0.0 | 44.0 |
| CodeAct + BM25 | 22.0 | 51.0 | 38.0 |
| CodeAct + sub-calls | 24.0 | 0.0 | 40.0 |
| Summary Agent | 58.0 | 70.5 | 46.0 |
| RLM | 59.5 | 86.0 | 53.0 |
| RLM(无子调用) | 65.2 | 89.7 | 50.5 |
| SRLM | 68.9(↑9.4) | 92.4(↑6.4) | 65.5(↑12.5) |
| SRLM(无子调用) | 74.1(↑8.9) | 94.6(↑4.9) | 60.7(↑10.2) |
几个关键发现值得深挖:
发现一:SRLM 全面碾压 RLM。 在 Qwen3 + BrowseComp+ 上,从 37.1% 跃升至 59.7%,绝对提升 22.6 个百分点。GPT-5 在 OOLONG 上从 53.0% 提升至 65.5%,绝对提升 12.5 个百分点。
发现二:"无子调用"版本同样强劲。 SRLM(无子调用)在多个设置中甚至超过了带递归子调用的 RLM——GPT-5 在 BrowseComp+ 上 SRLM(无子调用)达到 94.6%,超过 RLM 的 86.0%。这直接证明:递归不是性能的核心来源。
发现三:RLM 在短上下文中"帮倒忙"。 在低于 131K tokens 的场景中,RLM 的表现显著低于基线模型,而 SRLM 在短上下文中也能保持正向增益。
3.3 任务类型分析
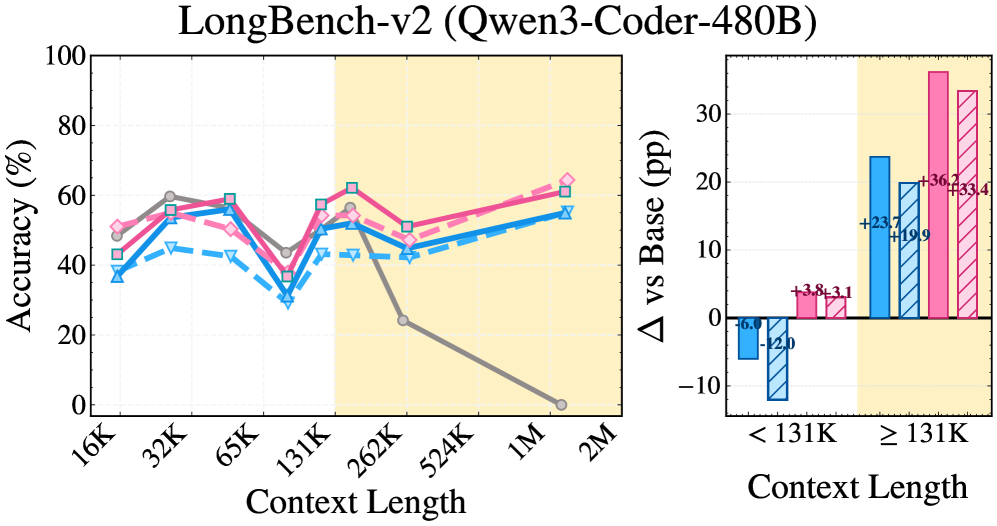
图4:不同任务类型下 SRLM 相对 RLM 的增益。在语义密集型任务上优势尤为突出。
递归分解在结构化、搜索导向型任务(代码问答、结构化数据问答)上表现相对较好,这些任务可以通过启发式搜索定位答案。但在语义密集型任务——对话历史问答、文档问答——递归分解力不从心,而 SRLM 的自反思机制在这类任务上展现出更大优势。
这揭示了一个深层逻辑:递归分解本质上是"分而治之"的结构化策略,适合可切分的信息检索;但当答案需要跨段落的语义综合理解时,不确定性引导的程序选择比递归拆解更有效。
3.4 效率对比
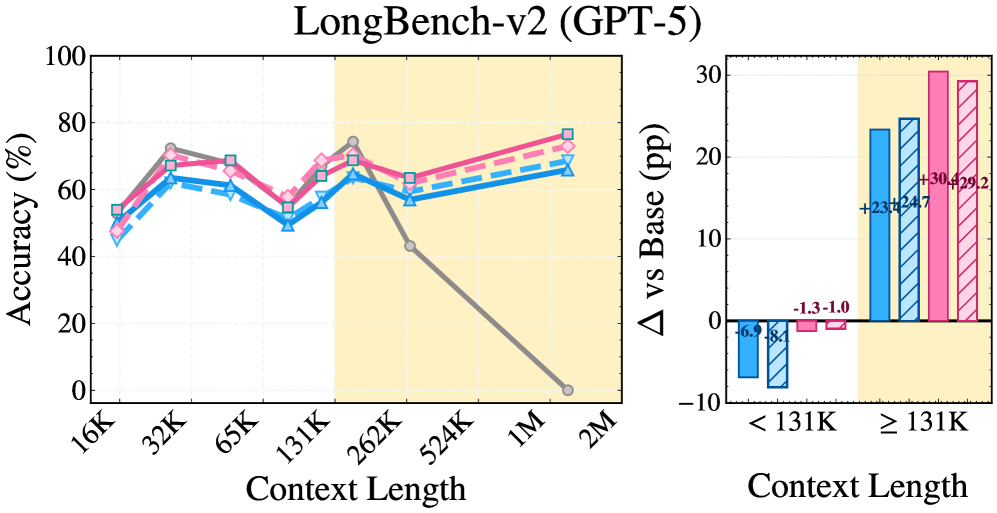
图3:准确率 vs. 时间成本的 Pareto 对比。SRLM(无子调用)在准确率和时间效率上同时优于 RLM。
SRLM(无子调用)在准确率-时间成本的 Pareto 前沿上全面优于 RLM。这意味着自反思不仅提升了精度,还避免了递归子调用带来的额外计算开销。
3.5 消融实验
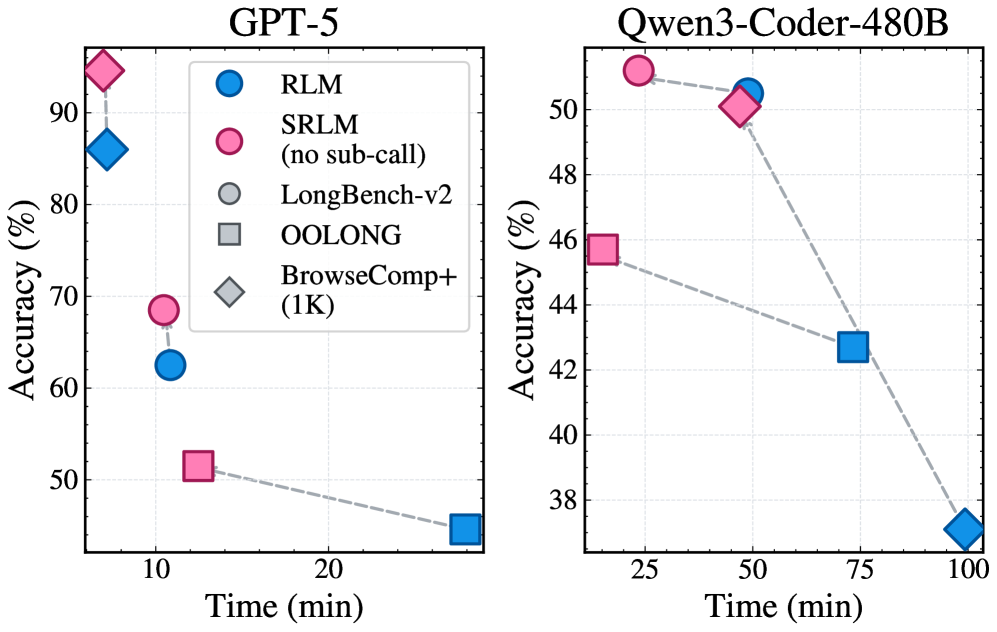
图5:三个不确定性信号的消融分析。完整三信号组合一致优于任何单信号变体。
三个不确定性信号的消融分析表明:
- 单独使用任一信号都能带来提升,但效果有限
- 语义不确定性和行为不确定性的互补性尤为显著
- 完整的三信号组合始终是最优配置
这说明模型的"自我感知"是多维度的——答案的一致性、生成时的自述信心、以及推理过程的纠结程度,分别捕捉了不同层面的不确定性。
4. 核心洞见:重新定位递归的角色
这篇论文最有价值的贡献不在于方法设计本身,而在于它对 RLM 范式的解构性分析。
RLM 的成功曾被归因于"递归分解"——一个直觉上很有吸引力的解释。但 SRLM 的实验表明,RLM 性能提升中,递归子调用的贡献仅约 6%。真正的增益来源于:
- 程序化上下文交互:将长上下文作为外部变量通过代码操作,而非直接喂入模型
- 多轨迹采样与选择:生成多个候选方案并择优,而非一次性生成
递归只是在这个框架中增加了一层"分治"结构,对于某些结构化任务有边际收益,但不是通用的性能驱动力。
5. 局限性与批判性思考
局限一:自反思信号的简单性。 论文使用的三个不确定性信号都是"内省式"的——来自模型自身的采样一致性、自述置信度和推理长度。这些信号在模型校准良好时有效,但当模型"自信地犯错"时可能失效。论文没有探讨外部验证信号(如代码执行结果的正确性检查)的潜力。
局限二:计算开销未被充分讨论。 K=8K=8K=8 的采样意味着 8 倍的推理计算量。虽然论文展示了 Pareto 前沿上的优势,但绝对成本(8 次独立采样 × 每步 600 秒时限 × 最多 30 步)在实际部署中是否可接受,需要更多讨论。
局限三:骨干模型的选择偏差。 实验仅使用了 Qwen3-Coder-480B 和 GPT-5,都是顶级大模型。对于更小规模的模型,自述置信度信号是否同样可靠?推理长度与准确率的负相关假设是否成立?这些都缺乏验证。
局限四:自一致性的语义等价判定。 论文使用 LLM-as-Judge 来判定两个答案是否语义等价,这本身引入了另一层不确定性。在数值型或精确匹配型任务中这可能问题不大,但在开放式问答中,这一环节的准确性直接影响自一致性信号的质量。
局限五:与测试时计算扩展方法的对比缺失。 Best-of-N 采样、多数投票等推理时扩展策略与 SRLM 有天然的相似性,但论文没有与这些更通用的方法进行直接对比。
6. 总结与展望
SRLM 提出了一个既简洁又实用的框架:通过三重不确定性信号引导程序选择,在不依赖递归子调用的情况下,实现了对 RLM 高达 22% 的性能提升。
更重要的是,这项工作揭示了一个被忽视的事实:在长上下文推理中,"如何选择程序"比"如何分解问题"更关键。递归分解是一种特定的问题分解策略,而不确定性感知的程序选择是一种通用的质量保障机制——后者的适用范围更广、鲁棒性更强。
未来方向可能包括:
- 将自反思信号与推理过程动态结合,实现提前终止以节省 token 预算
- 探索更丰富的外部验证信号(代码执行测试、事实核查等)
- 将 SRLM 的不确定性框架推广到其他推理时扩展场景
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)