部署不是终点,而是学习的起点:微软提出 OEL 框架,让大模型从真实交互中持续进化
部署不是终点,而是学习的起点:微软提出 OEL 框架,让大模型从真实交互中持续进化
论文标题:Online Experiential Learning for Language Models
作者:Tianzhu Ye, Li Dong, Qingxiu Dong, Xun Wu, Shaohan Huang, Furu Wei
机构:Microsoft Research
链接:https://arxiv.org/abs/2603.16856
日期:2026年3月17日
核心摘要
当前大语言模型的训练范式存在一个根本性矛盾:模型在部署后变成"静态制品",无法从海量的真实用户交互中获益。微软研究院提出 Online Experiential Learning(OEL) 框架,让模型在部署阶段像人类一样"从经验中学习"——无需人工标注、无需奖励模型、无需在服务器端访问用户环境。该方法通过"经验知识提取 + 在策略上下文蒸馏"的迭代循环,在文本游戏环境中实现了 pass rate 从 7.5% 到 21.4% 的跃升,同时推理效率提升约 30%,且不破坏模型的分布外泛化能力。
1. 问题:部署后的模型为何"不再成长"?
今天的 LLM 训练遵循一个封闭流程:在离线数据集上预训练、用人类标注做对齐、在模拟环境中做 RL,然后部署——从此冻结。
这带来了两个根本问题:
- 经验浪费:部署产生的丰富交互数据被直接丢弃,模型无法从中汲取教训
- 分布瓶颈:模型的能力上限被离线训练数据的覆盖范围所限定,无法超越预先策划的训练分布
传统强化学习方法理论上可以从在线交互中学习,但它们需要明确的奖励函数或环境访问权限——而在真实部署场景中,服务器端通常无法访问用户侧的环境。
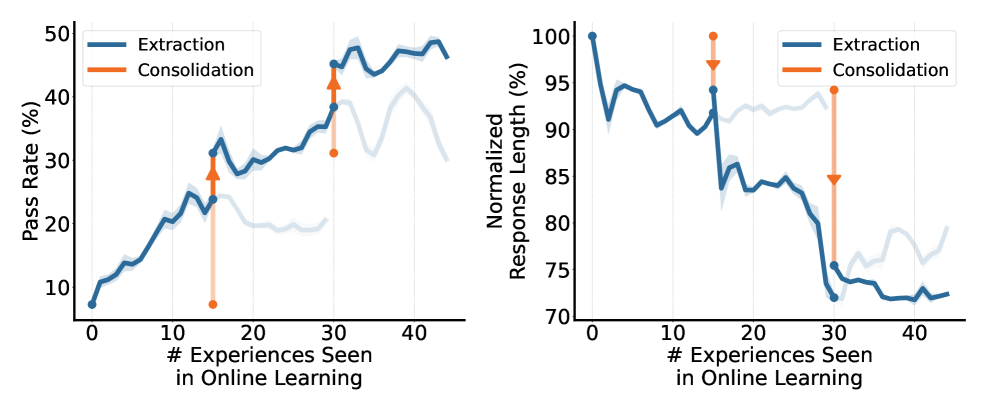
图:离线范式(左)vs OEL在线学习范式(右)。离线范式在封闭世界中训练,部署即终点;OEL 将部署视为持续进化的起点,形成"更好模型 → 更好轨迹 → 更好知识"的良性循环。
2. OEL 框架:两阶段迭代学习
OEL 的核心思路简洁而优雅:把"测试时经验"变成训练信号,且全程不依赖任何外部监督。整个框架由两个交替执行的阶段组成。
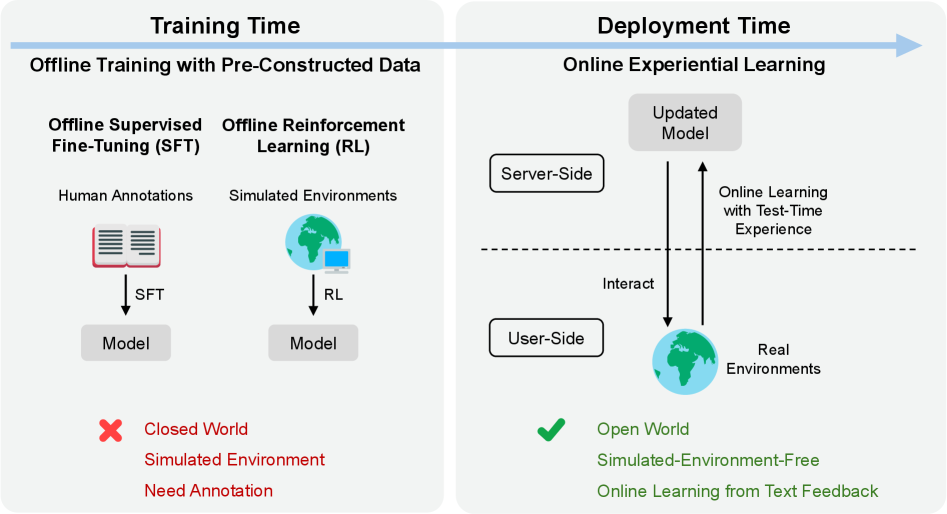
图:OEL 整体流程。用户侧收集多轮交互轨迹,服务器侧提取经验知识并通过在策略上下文蒸馏将其固化到模型参数中。
2.1 阶段一:经验知识提取
给定 nnn 条交互轨迹 τi=(fi1,ai1,fi2,ai2,…)\tau_i = (f_i^1, a_i^1, f_i^2, a_i^2, \ldots)τi=(fi1,ai1,fi2,ai2,…),模型以递归累积的方式提取可迁移的经验知识:
ei′∼πextract(⋅∣τi,ei−1),ei=[ei−1;ei′]e_i' \sim \pi_{\text{extract}}(\cdot \mid \tau_i, e_{i-1}), \quad e_i = [e_{i-1}; e_i']ei′∼πextract(⋅∣τi,ei−1),ei=[ei−1;ei′]
其中 e0=∅e_0 = \varnothinge0=∅,πextract\pi_{\text{extract}}πextract 就是当前部署的模型本身。
这一过程有三个关键特征:
- 无需标签:完全依赖交互轨迹本身,不需要 ground-truth
- 累积式学习:后续提取会基于已积累的知识进行,避免重复发现
- 无选择过滤:不依赖奖励信号筛选,直接使用所有提取结果
2.2 阶段二:通过在策略上下文蒸馏固化知识
提取的经验知识需要从"上下文提示"转化为"模型参数"。OEL 使用 On-Policy Context Distillation 来完成这一步:
L(θ)=Ex∼D,e∼C,y∼πθ(⋅∣x)[1∣y∣∑tDKL(πθ(⋅∣x,y<t)∥πteacher(⋅∣e,x,y<t))]\mathcal{L}(\theta) = \mathbb{E}_{x \sim \mathcal{D}, e \sim \mathcal{C}, y \sim \pi_\theta(\cdot|x)} \left[ \frac{1}{|y|} \sum_t D_{\text{KL}}\left(\pi_\theta(\cdot|x, y_{\lt t}) \| \pi_{\text{teacher}}(\cdot|e, x, y_{\lt t})\right) \right]L(θ)=Ex∼D,e∼C,y∼πθ(⋅∣x)[∣y∣1t∑DKL(πθ(⋅∣x,y<t)∥πteacher(⋅∣e,x,y<t))]
这个训练目标有几个精妙的设计:
- 学生模型 πθ\pi_\thetaπθ 只看任务输入 xxx,不看经验知识
- 教师模型 πteacher\pi_{\text{teacher}}πteacher(冻结的初始模型)同时看经验知识 eee 和任务输入
- 使用 reverse KL 散度,让学生产生 mode-seeking 行为,聚焦于教师分布的高概率区域
- 学生在自己的策略分布上采样——这就是"在策略"的含义
一个极其重要的工程优势:由于模型在每个响应位置做的是单轮 rollout,整个训练过程可以在服务器端完成,无需访问用户侧环境。
2.3 在线迭代循环
两个阶段交替进行,形成闭环:
- 部署更新后的模型,收集新的交互轨迹
- 从新轨迹中提取经验知识
- 通过在策略上下文蒸馏固化知识
- 回到第1步
这构成了一个良性循环:更好的模型产生更好的轨迹,更好的轨迹产出更高质量的经验知识,更好的知识又训练出更好的模型。
3. 实验设计与核心结果
3.1 实验环境
OEL 在两个文本游戏环境上验证:
| 环境 | 规模 | 任务 |
|---|---|---|
| Frozen Lake | 3×3 网格,含2个洞 | 导航到目标位置 |
| Sokoban | 6×6 网格 | 推箱子到目标位置 |
测试模型覆盖多个规模:Qwen3-1.7B、Qwen3-4B、Qwen3-8B(thinking 模式)以及 Qwen3-4B-Instruct-2507(non-thinking 模式)。
3.2 经验知识 vs 原始轨迹
一个核心问题是:经验知识提取这一步到底有没有必要?直接拿原始轨迹做上下文蒸馏行不行?
在 Sokoban 环境下使用 Qwen3-4B-Instruct-2507 的结果给出了明确答案:
| 经验类型 | In-Context 准确率 | 蒸馏后准确率 |
|---|---|---|
| 无经验 | 7.5% | — |
| 原始轨迹 | 10.9% | 7.8% |
| 提取的经验知识 | 18.2% | 21.4% |
经验知识在 in-context 场景下比原始轨迹高出 67%,蒸馏后更是达到了 21.4% vs 7.8% 的碾压性差距。原始轨迹做蒸馏甚至不如不用任何经验(7.8% vs 7.5%),说明未经提炼的噪声信息反而会伤害模型。
3.3 在策略一致性至关重要
另一个重要发现是知识来源与模型策略的匹配问题。在 Frozen Lake 环境下:
| 知识来源 | In-Context 准确率 | 蒸馏后准确率 |
|---|---|---|
| 无经验 | 7.3% | — |
| Qwen3-4B 的轨迹 | 18.0% | 22.7% |
| Qwen3-1.7B 自身轨迹 | 23.8% | 31.1% |
小模型从自己的经验中学到的东西,比从更大模型的经验中学到的更多。 Qwen3-1.7B 使用自身轨迹提取的知识达到 31.1%,而使用 Qwen3-4B 的轨迹只有 22.7%——差距达到 37%。这揭示了一个深刻的道理:经验知识必须与策略模型的行为分布保持一致,否则会产生分布错配。
3.4 迭代带来持续增长
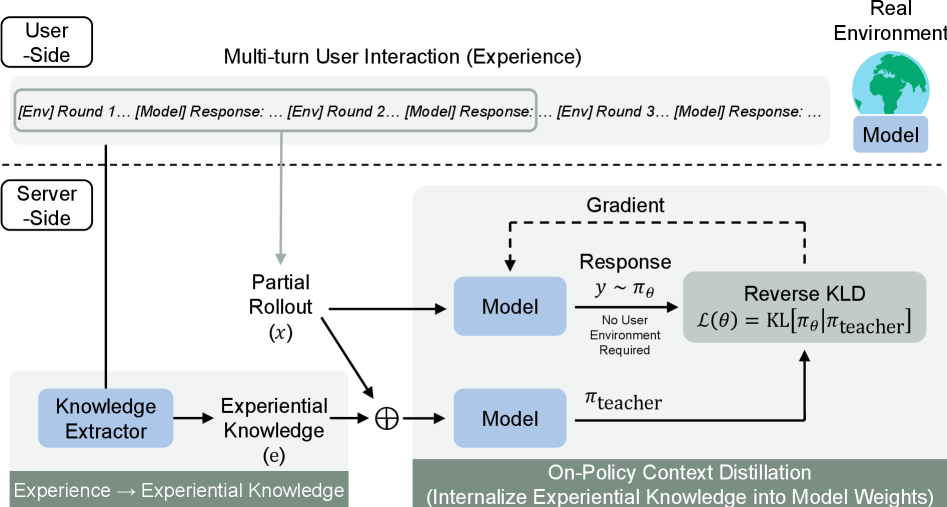
图:OEL 多轮迭代中 pass rate 的持续提升。每一轮的积累阶段会饱和,但蒸馏后的性能超越前一轮起点,形成阶梯式上升。
在 Frozen Lake 和 Sokoban 两个环境中,OEL 展现出一致的"阶梯式增长"模式:
- 每一轮的知识积累阶段会逐渐饱和
- 蒸馏将积累的知识固化后,性能突破前一轮的上限
- 下一轮从更高的基线开始,继续积累和突破
3.5 推理效率同步提升
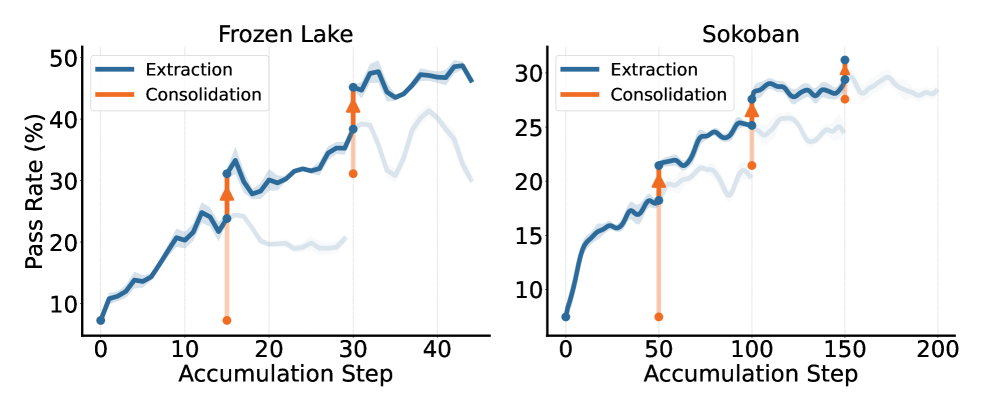
图:归一化响应长度随迭代轮次递减。到第3轮,平均响应长度缩短至初始值的约 70%。
OEL 不仅提升准确率,还显著改善推理效率。随着经验知识逐步内化到模型参数中,模型的平均每轮响应长度持续下降,到第3轮缩减约 30%。这说明模型学会了更简洁高效的推理路径,而不是依赖冗长的思考链。
3.6 分布外性能保持完好
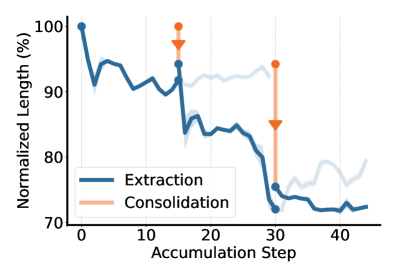
图:在策略上下文蒸馏(OEL)在保持分布外性能方面显著优于离策略蒸馏。
这或许是最出人意料的结果。使用 IF-Eval 基准测试评估分布外泛化能力:
- OEL 的在策略蒸馏:分布外准确率基本保持在初始模型水平
- 离策略蒸馏:分布外性能出现明显退化
在策略训练的优势在于学生模型在自己的分布上采样,避免了离策略方法中强行模仿教师高概率区域导致的模式崩塌问题。
3.7 跨模型规模的一致增益
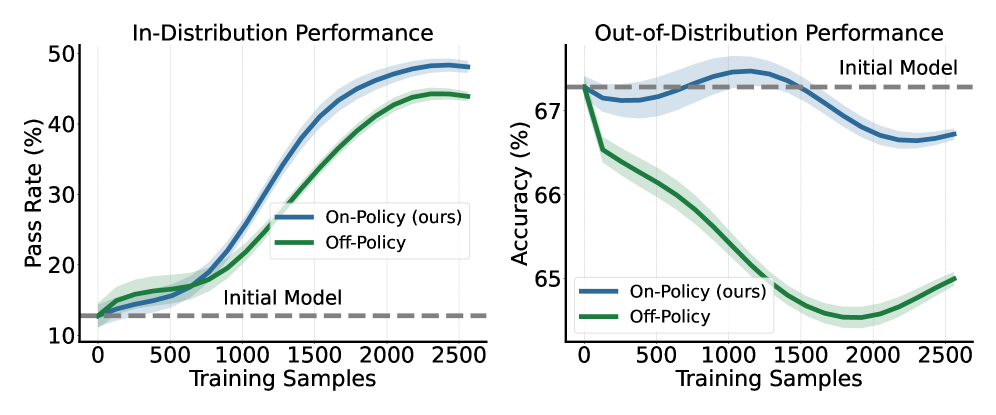
图:OEL 在 Qwen3-1.7B、4B、8B 三个规模上都带来显著提升,且增益随规模增大而增大。
在 Frozen Lake 上测试三种规模的 Qwen3 模型:
- 初始模型性能在不同规模间差异很小
- OEL 为所有规模都带来了实质性提升
- 更大模型的绝对增益更高,因为它们能生成更高质量的交互轨迹
- 从第1轮到第2轮的改进在所有规模上保持一致
4. 关键超参数配置
论文提供了不同模型和环境的最优配置,具有实际复现价值:
| 配置项 | Qwen3-1.7B / Frozen Lake | Qwen3-4B / Frozen Lake | Qwen3-8B / Frozen Lake | Qwen3-4B-Instruct / Sokoban |
|---|---|---|---|---|
| 知识格式 | 非结构化 | 结构化 | 结构化 | 结构化 |
| 积累轨迹数 nnn | 15 | 25 | 50 | 50 |
| 最大长度 LmaxL_{\max}Lmax | 2,048 | 8,192 | 8,192 | 8,192 |
| 学习率 | 5e-6 | 1e-6 | 1e-6 | 1e-6 |
| 训练步数 | 20 | 20 | 100 | 100 |
一个有趣的细节:较小的 1.7B 模型更适合非结构化的知识格式,而较大模型则受益于结构化格式。这可能与小模型在结构化提示下的遵循能力较弱有关。
计算效率方面,KL 散度的计算使用了 top-256 token 近似,即只对学生概率排名前 256 的词汇计算 KL 散度,大幅降低了训练开销。
5. 与相关工作的联系
OEL 并非凭空出现,它站在几个重要研究方向的交汇处:
- On-Policy Distillation:MiniLLM 等工作证明了在策略训练 + reverse KL 的有效性,OEL 将这一思路扩展到了上下文蒸馏场景
- Context Distillation:传统的上下文蒸馏都是离策略的,OEL 团队同期提出的 OPCD 论文(arXiv:2602.12275)为在策略上下文蒸馏奠定了理论基础
- 从经验中学习:Reflexion、EXPEL 等工作探索了基于轨迹的反思和记忆机制,但它们要么依赖外部记忆,要么需要奖励信号,而 OEL 将经验直接固化到参数中
6. 局限性与批判性思考
虽然 OEL 的理念令人兴奋,但我们需要冷静审视几个关键问题:
实验覆盖面有限:仅在 Frozen Lake 和 Sokoban 两个文本游戏上验证。这些环境的状态空间小、反馈结构清晰,与真实部署场景(如开放域对话、复杂推理)的差距巨大。经验知识在开放域场景中是否仍能有效提取和迁移,尚未可知。
计算成本未分析:论文没有报告经验知识提取阶段的计算开销。考虑到需要将多达 50 条完整轨迹作为上下文输入(LmaxL_{\max}Lmax 高达 8,192),这在生产环境中的可行性存疑。
迭代轮数的天花板:论文展示了2-3轮迭代的效果,但没有探索更多轮次下是否会出现性能饱和或退化。
缺少强基线对比:论文没有与 RLHF、DPO 或近期的 RL-based agent 训练方法进行横向对比,难以判断 OEL 在绝对性能上处于什么水平。
在策略一致性的两面性:"自己的经验最有用"这一发现虽然有趣,但也意味着模型可能陷入自我强化的信息茧房——只能从自己已经擅长的领域中学习,无法通过借鉴更强模型的经验来突破自身能力上限。
安全性考量缺失:在真实部署中持续从用户交互中学习,可能引入有害内容或偏见。论文未讨论任何安全防护机制。
7. 总结
OEL 提出了一个颇具前瞻性的愿景:大模型的训练不应在部署时画上句号,而应以部署为起点开启持续进化。通过"经验知识提取 + 在策略上下文蒸馏"的两阶段循环,OEL 在不依赖任何外部监督的前提下实现了模型的渐进式改善。
在策略一致性、知识提取优于原始轨迹、分布外性能保持等发现,为 LLM 的在线学习提供了有价值的设计原则。但该工作目前仍处于概念验证阶段,距离在复杂真实场景中落地还有相当距离。
最值得关注的后续问题是:当环境从3×3的格子游戏换成真实世界的开放域交互时,OEL 的良性循环是否还能转起来?
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)