李宏毅:从零开始搞懂 AI Agent
引言:AI Agent 是什么?为什么它突然火了?
如果你最近刷过科技新闻或者 X 平台,可能会发现「AI Agent」这个词频频出现。它听起来很酷,像科幻电影里的智能助手,但它到底是什么?为什么 2023 年以后突然又火了起来?
想象一下,你有个超级聪明的助理。你不用告诉它每一步怎么做,只需要说:「帮我订一张去上海的机票,预算 2000 元。」它就会自己上网查航班、比价、填表单,最后把票订好。这样的「助理」就是 AI Agent 的核心想法——它不是等着你发号施令,而是自己想办法达成目标。这和我们平时用的 ChatGPT 有点不一样,对吧?ChatGPT 是你问一句,它答一句,而 AI Agent 更像一个「主动做事的小能手」。
一、AI Agent 的本质——从「听话」到「主动」
1.1 AI Agent 和普通 AI 的区别
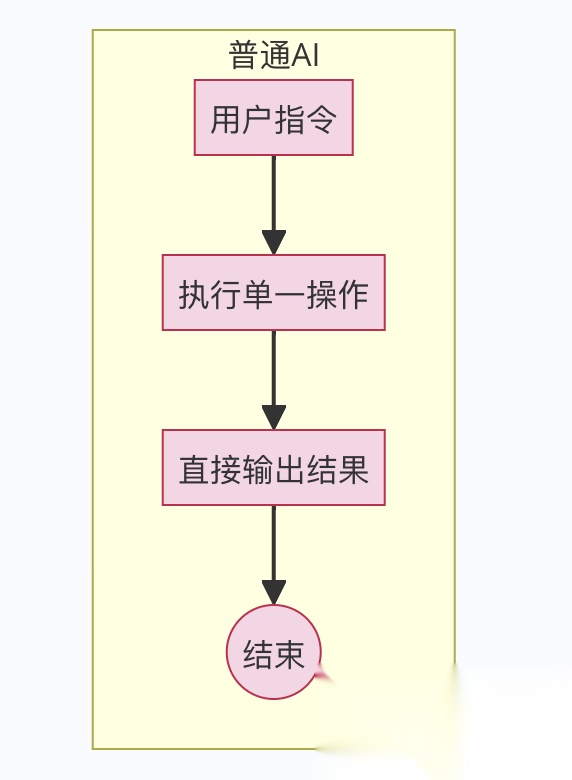
先搞清楚一个问题:AI Agent 到底跟我们常用的 AI 有什么不一样?假设你问 ChatGPT:「AI Agent 的中文是什么?」它会老老实实回答:「AI Agent 的中文是‘人工智能代理’。」这就是典型的 AI——你给指令,它执行,完事。但 AI Agent 不一样。你如果对它说:「帮我研究一下 AI Agent 的定义」,它不会只丢给你一个翻译,而是可能会自己去搜资料、分析不同观点,最后整理出一份报告。
简单来说:
- 普通 AI:像个听话的工具,你说「跳」,它就跳一下。
- AI Agent:像个有主动性的助手,你给个目标,它自己规划怎么跳、跳多高。
用课程里的比喻,普通 AI 是「一个口令一个动作」,而 AI Agent 是「人类只给目标,AI 自己找路」。
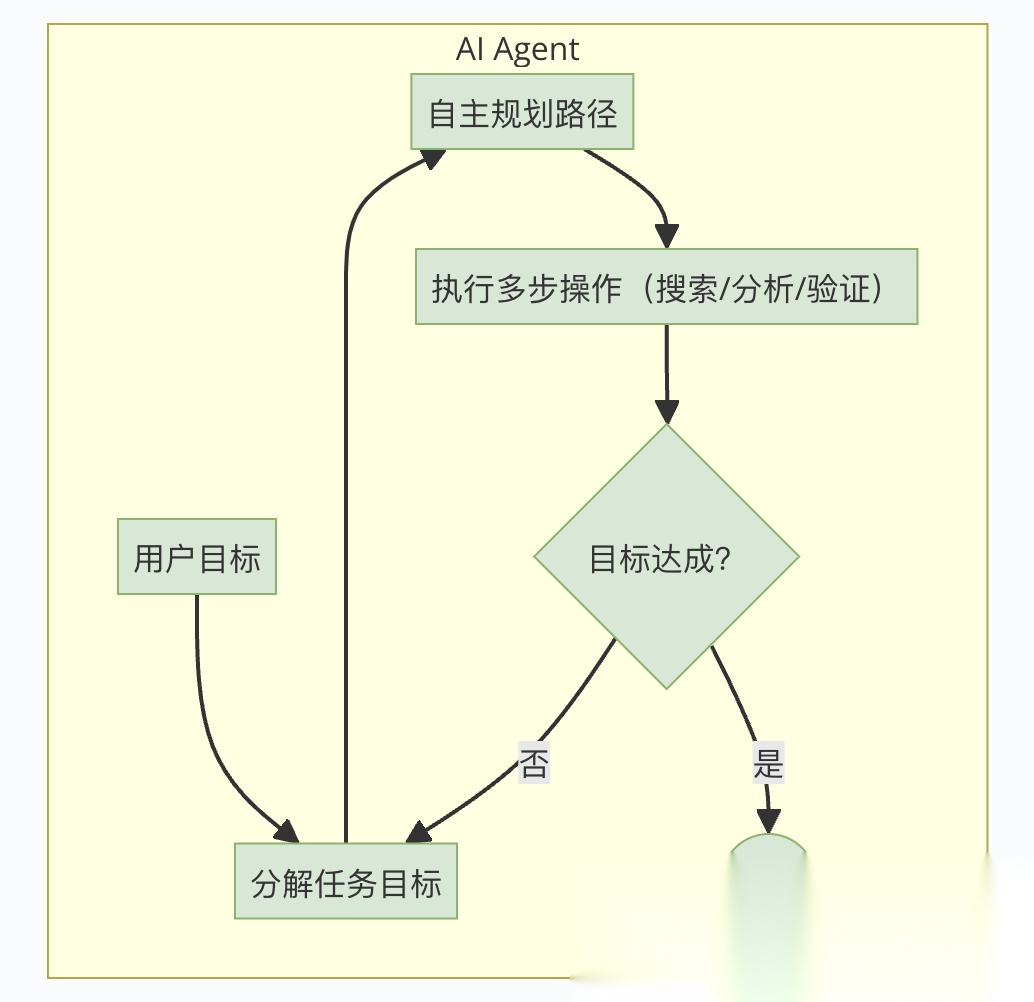
以一个「研究任务」为例,展示AI Agent如何工作:

1.2 AI Agent 的定义和工作循环
那 AI Agent 具体是怎么工作的呢?课程里给了个清晰的框架,可以用一张图来概括:

- 目标:人类给的终点,比如「赢一盘围棋」。
- 观察:AI 感知到的当前情况,比如「棋盘上黑白子的位置」。
- 行动:AI 根据观察决定做啥,比如「在第 5 行第 7 列落子」。
- 环境变化:行动引发的结果,比如「对手回了一步」。
- 循环:不断观察、行动,直到目标达成。
举个例子,AlphaGo 就是个经典的 AI Agent。它的目标是「赢棋」,观察是「当前棋盘状态」,行动是「落子」,然后对手回应,它再观察、再行动。这个循环听起来是不是很像我们人类解决问题的方式?先看情况,想办法,试一下,再调整。

这个工作循环体现了 AI Agent 的自主性和反应式架构——像人类一样通过试错逼近目标,而非单纯执行预设指令。
1.3 为啥 AI Agent 跟强化学习(RL)有关?
如果你学过机器学习,可能会觉得这个循环很眼熟。它跟强化学习(Reinforcement Learning, RL)的思路很像。RL 的核心是让 AI 通过试错学会最大化「奖励」(Reward)。比如 AlphaGo,赢棋 Reward 是 +1,输棋是 -1,它通过无数次模拟对局,学会怎么下才能赢。
但传统的 AI Agent 多靠 RL 打造,比如 AlphaGo 得专门为围棋训练一个模型。可问题来了:换个任务,比如下象棋,它还得重头练。这就有点笨拙了。而现在,AI Agent 之所以又火起来,是因为我们有了新玩法——直接用大型语言模型(LLM)当 Agent,不用每次都重新训练。这是个大转折,后面会细讲。
二、AI Agent 的「新灵魂」——大型语言模型(LLM)
2.1 LLM 如何变身 AI Agent?
过去,RL 打造的 AI Agent 虽然强,但局限明显:一个模型只能干一件事。现在有了 LLM(像 ChatGPT、Grok 这样的语言模型),情况变了。LLM 的超能力在于通用性——它能理解文字、回答问题、写代码,甚至看图说话。那能不能直接让它当 AI Agent 呢?
答案是可以的!LLM 驱动的 AI Agent 是这样工作的: 40. 目标用文字输入:比如「帮我下赢围棋」。 41. 环境转成文字或图片:棋盘状态可以用文字描述(「黑子在 A1,白子在 B2」),或者直接给图片。 42. 行动用文字输出:LLM 说「我要在 C3 落子」,然后有人或系统把这文字转成实际操作。 43. 循环直到成功:环境变了,LLM 再观察、再输出新行动。
这跟 RL 的区别是:LLM 不用专门训练,它靠已有的语言理解能力,直接「猜」下一步该干啥。是不是很省事?
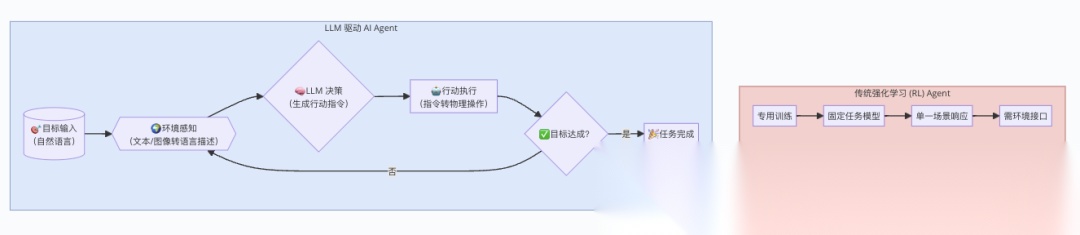
2.2 LLM 做 Agent 的优缺点
优点
- 灵活性:不像 AlphaGo 只能下围棋,LLM 能处理各种任务,只要你能用文字描述目标。
- 无需定义 Reward:RL 得手工设计奖励函数(比如「赢棋 +1」),但这很难调。LLM 直接读懂目标和反馈,比如给它个错误日志,它自己就能改代码,不用你说「错一次 -1」。
- 无限可能:LLM 能输出任何文字,行动空间几乎无限制,而 AlphaGo 只能在 19×19 的棋盘里挑一个点。
缺点
- 不靠谱:LLM 本质是「文字接龙机」,它可能瞎猜一步,而不是深思熟虑。
- 依赖描述:环境得转成文字或图片,如果描述不清楚,它就懵了。
前一段有一个新闻,有人让 ChatGPT 和 DeepSeek 下象棋,结果它们把「兵」当「马」跳,还凭空变出棋子,最后 DeepSeek 吃了自己一子宣布胜利,ChatGPT 还认输了……这说明,LLM 做 Agent 还得磨练。
三、AI Agent 的三大关键能力
课程里把 AI Agent 的能力拆成三块:根据经验调整行为、使用工具、做计划。这三点决定了它能不能从「听话工具」进化成「聪明助手」。
3.1 根据经验调整行为
这个能力为什么重要?
人类做事靠经验,AI Agent 也一样。比如你写代码报错,编译器告诉你「缺个分号」,下次你就记得加分号。AI Agent 得有类似能力,看到反馈后调整下一步。
LLM 怎么做到?
LLM 不用调参数,直接把反馈塞进输入,它就变聪明了。比如:
- 输入:「写个加法函数。」
- 输出:「def add(a, b): return a + b」
- 反馈:「有错,b 没定义类型。」
- 新输入:「写个加法函数,反馈说 b 没定义类型。」
- 新输出:「def add(a: int, b: int) -> int: return a + b」
这靠的是 LLM 的「上下文学习」(In-Context Learning),不用训练,输入变了,输出就变。
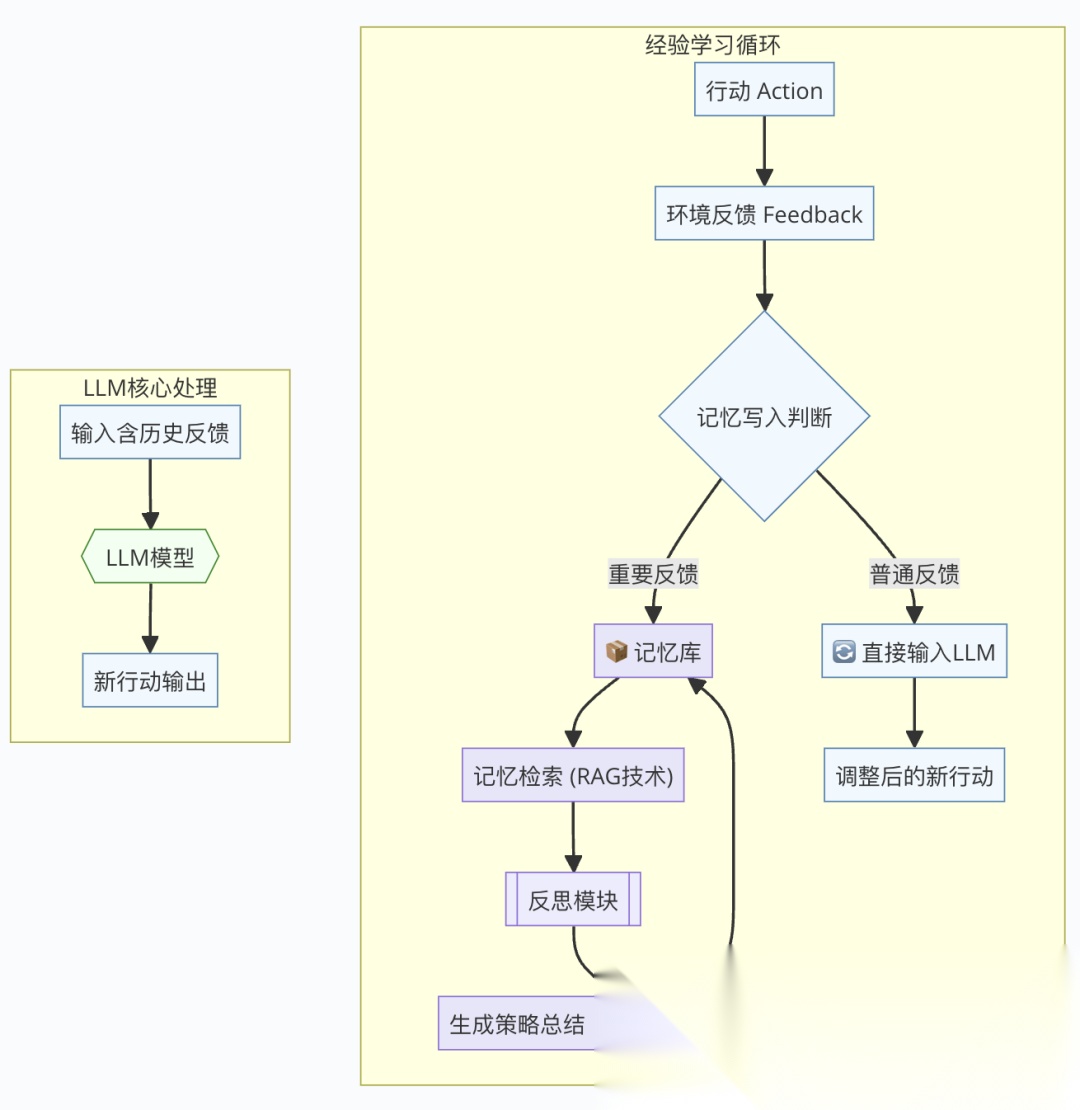
挑战:记忆爆炸
如果每次行动都把历史全塞给 LLM,步数一多(比如 1 万步),输入就太长,算力撑不住。怎么办?课程提了三个模块:
- Write(写入):决定啥值得记。比如「桌子在那儿」不重要,「对手下了关键一步」才记。
- Read(读取):从记忆里挑相关经验,像 RAG(检索增强生成)技术,从海量数据里找有用的。
- Reflection(反思):总结经验,比如「对手老爱走中间,我得防着点」。
实验发现,正面反馈(「这步对了」)比负面反馈(「这步错了」)更有效,因为 LLM 更擅长照着「好例子」学。
3.2 使用工具
为什么需要工具?
LLM 再强,也有短板。比如它不会直接查天气,得靠外部工具。工具就像 AI Agent 的「外挂」,让它能干更多事。
怎么用?
一个通用方法:
- 告诉它工具咋用:比如
用 Temperature(地点, 时间) 查温度。 - 输入问题:
今天台北多热? - 输出指令:
[Tool] Temperature(台北, 现在) [Tool] - 执行并反馈:
[Output] 28°C [Output] - 最终回答:
台北现在 28°C。
常用工具包括:
- 搜索引擎:查资料(RAG)。
- 代码执行器:写程序并运行。
- 其他 AI:比如让语音 AI 帮它听音频。
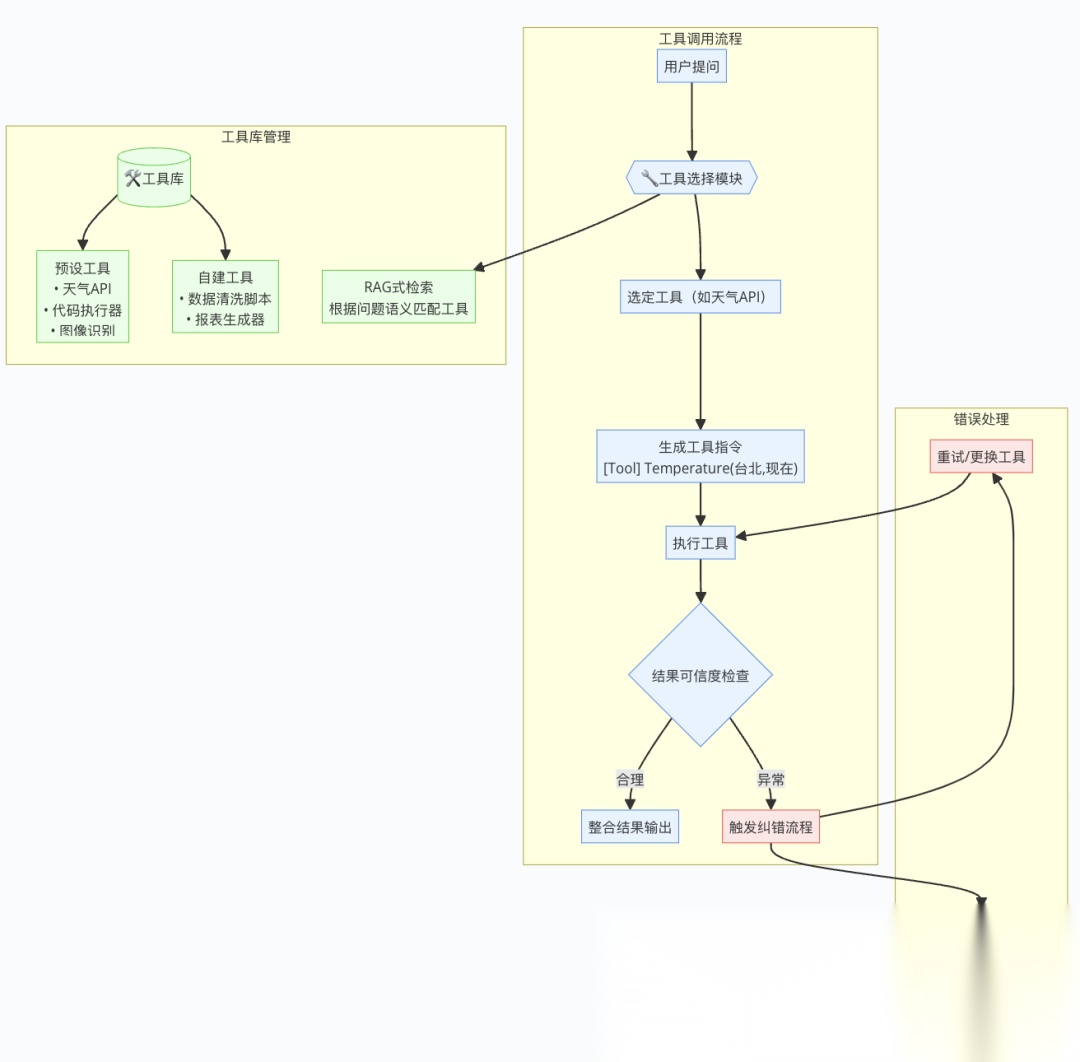
挑战:工具多了咋办?
工具一多(比如上千个),LLM 不可能全记住。解决办法是用「工具选择模块」,像 RAG 一样,从工具库里挑合适的。更有趣的是,LLM 还能自己写代码造工具,存起来复用。
小心工具出错
工具可能给错信息,比如搜索引擎搜到恶搞贴说「披萨起司用胶水粘」。LLM 有一定判断力(比如「1 万度太离谱」),但有时也会被忽悠,得教它别太信工具。
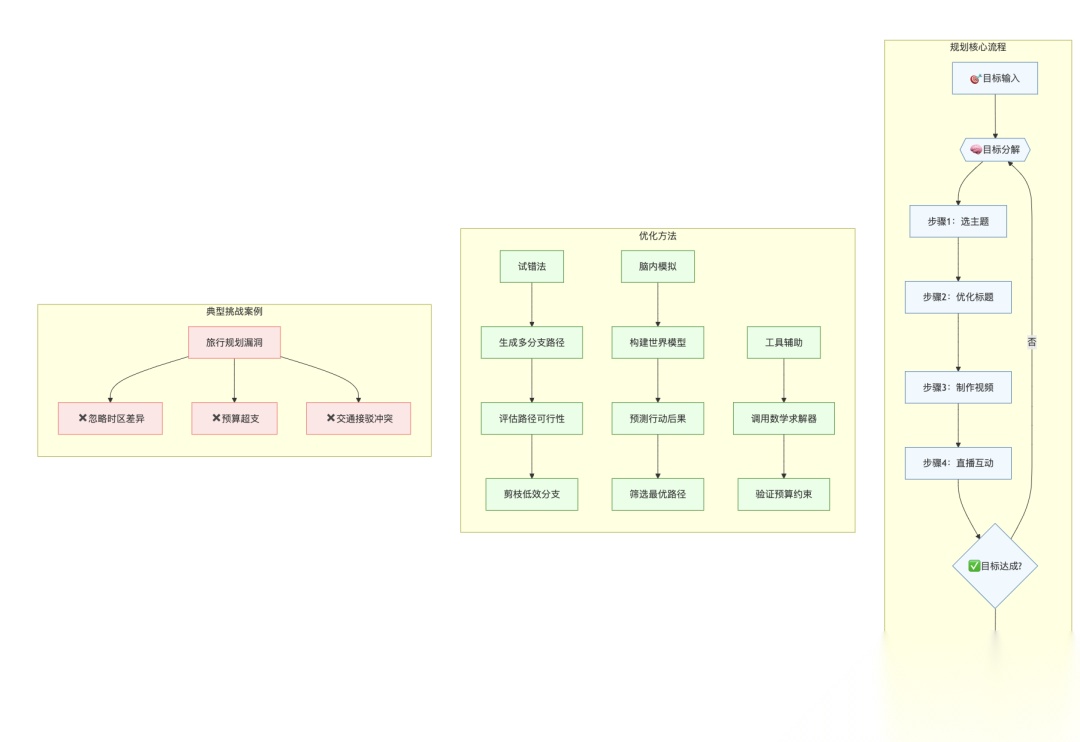
3.3 做计划
什么是计划?
计划就是先想好步骤再行动。比如刷牙:找牙刷 → 挤牙膏 → 刷 → 漱口。AI Agent 也得会规划,不然每步都随机试,太笨了。
LLM 能规划吗?
能,但不完美。给它说「做百万订阅 YouTuber」,它能列个计划:选主题 → 优化标题 → 做直播……听起来不错,但细节常出错。比如安排旅行,它可能忘了预算限制,或者行程撞车。
怎么提升?
有几个思路: 44. 试错法(Tree Search):每步都试试,挑最好的。但算力成本高,得剪掉没希望的路。 45. 脑内模拟(World Model):让 LLM 自己猜下一步会咋样,像做梦一样规划。比如网页买东西,它先想象「点这个会跳到哪」。 46. 用工具帮忙:复杂限制(像预算)交给专门的求解器,LLM 只管写代码调用。
实验显示,新模型(如 o1)在「神秘方块世界」这种怪题上表现更好,说明推理能力帮了大忙。但有时它们也「想太多」,光模拟不行动。
四、未来展望
4.1 AI Agent能干啥?
- 游戏:AI NPC自己聊天、办派对,甚至建社区。
- 用电脑:订 Pizza、买票,像人类一样操作屏幕。
- 科研:提研究提案、做实验。
- 训练 AI:写代码跑模型,调参数,比 baseline。
4.2 短板在哪?
- 不稳定:下棋能胡来,旅行计划超预算。
- 依赖环境描述:描述不清就抓瞎。
- 想太多或太少:要么卡在脑内模拟,要么直接放弃。
4.3 AI Agent 离「全能助手」还有多远?
- 实时互动:像语音对话,得随时调整,不能一问一答。
- 更好记忆:挑重要经验,别记鸡毛蒜皮。
- 更强规划:结合推理和工具,少想多做。
结语
AI Agent 是 AI 从「工具」到「伙伴」的进化。它用 LLM 的通用性,摆脱了 RL 的局限,虽然还不完美,但潜力巨大。未来,LLM 可能不仅是 Agent 的「大脑」,还能模拟环境、造工具,甚至自己进化。到那时,你说「帮我赚一百万」,它真能自己开公司也说不定。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 3
3 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)