MetaClaw:让部署后的 AI 智能体在失败中持续进化——UNC联合UC Berkeley提出双时间尺度元学习框架
MetaClaw:让部署后的 AI 智能体在失败中持续进化——UNC联合UC Berkeley提出双时间尺度元学习框架
一句话总结:MetaClaw 将"从失败中提炼技能"和"趁空闲优化策略"两个不同时间尺度的自适应机制耦合在一起,让已部署的 LLM 智能体无需停机、无需人工干预,就能随着使用不断变强。在 934 道任务的 44 天模拟实验中,该框架将 Kimi-K2.5 的准确率从 21.4% 拉升到 40.6%,几乎追平 GPT-5.2 的基线水平。
论文信息
- 标题:MetaClaw: Just Talk — An Agent That Meta-Learns and Evolves in the Wild
- 作者:Peng Xia, Jianwen Chen, Xinyu Yang, Haoqin Tu, Jiaqi Liu, Kaiwen Xiong, Siwei Han, Shi Qiu, Haonian Ji, Yuyin Zhou, Zeyu Zheng, Cihang Xie, Huaxiu Yao
- 机构:UNC-Chapel Hill、UC Berkeley、Carnegie Mellon University、UC Santa Cruz
- 提交日期:2026年3月17日
- 论文链接:https://arxiv.org/abs/2603.17187
- 代码:https://github.com/aiming-lab/MetaClaw
一、问题:部署即固化,智能体为什么越用越"笨"?
当前 LLM 智能体面临一个尴尬的现实:训练结束的那一刻就是能力冻结的起点。用户的需求在变化,工作流规则在更新,领域知识在迭代——但智能体的策略却纹丝不动。
已有的三类解决方案各有硬伤:
| 方案类型 | 代表方法 | 核心局限 |
|---|---|---|
| 记忆增强 | 存储原始轨迹供检索 | 无法提取可迁移的知识,记忆膨胀后检索质量下降 |
| 技能库 | 压缩经验为指令 | 技能库是静态的,与模型权重优化完全脱节 |
| RL微调 | 梯度更新模型权重 | 忽略行为上下文变化导致的数据有效性问题 |
MetaClaw 的核心洞察在于:行为层面的快速适应和参数层面的慢速优化天然互补。技能可以在几秒内从失败轨迹中蒸馏出来,而策略改进则需要数小时的梯度优化。更关键的是,这两者形成正反馈循环——更好的策略产生更有信息量的失败;更丰富的技能生成更高奖励的训练轨迹。
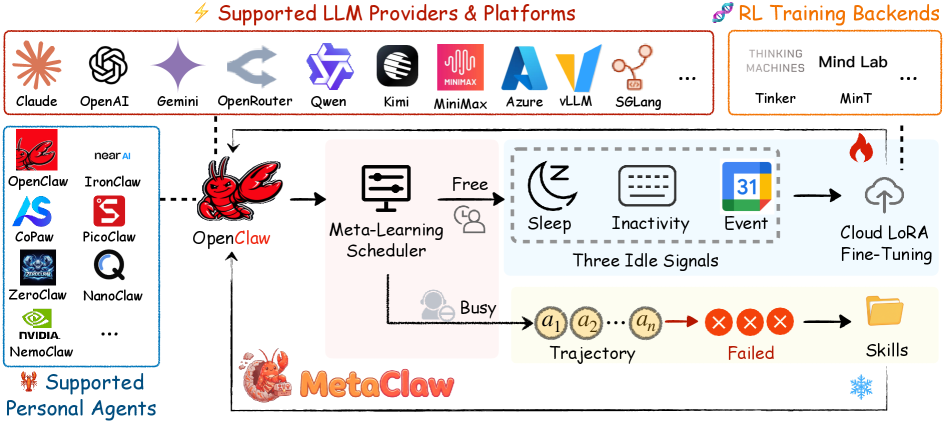
图1:MetaClaw 框架总览。左侧是技能驱动的快速适应——分析失败轨迹后即时扩展技能库,无需修改模型参数;右侧是机会主义策略优化——利用三种空闲信号(睡眠、键盘不活跃、日历事件)触发云端 LoRA 微调。
二、方法:双循环驱动的持续元学习
MetaClaw 维护一个元模型 M=(θ,S)\mathcal{M} = (\theta, \mathcal{S})M=(θ,S),其中 θ\thetaθ 是基础 LLM 策略参数,S={s1,s2,…,sK}\mathcal{S} = \{s_1, s_2, \ldots, s_K\}S={s1,s2,…,sK} 是可复用的行为技能库。智能体在执行任务时,动作采样遵循:
a∼πθ(⋅∣τ,Retrieve(S,τ))a \sim \pi_\theta(\cdot \mid \tau, \text{Retrieve}(\mathcal{S}, \tau))a∼πθ(⋅∣τ,Retrieve(S,τ))
即策略不仅依赖任务上下文 τ\tauτ,还依赖从技能库中检索到的相关技能指令。
2.1 快循环:技能驱动的即时适应
当智能体在任务中失败,这条失败轨迹被归入"支撑数据" Dsupg\mathcal{D}^g_{\text{sup}}Dsupg。一个 LLM 进化器分析这些失败模式,合成新的行为指令:
Sg+1=Sg∪E(Sg,Dsupg)\mathcal{S}_{g+1} = \mathcal{S}_g \cup \mathcal{E}(\mathcal{S}_g, \mathcal{D}^g_{\text{sup}})Sg+1=Sg∪E(Sg,Dsupg)
这里 ggg 是技能代际索引,E\mathcal{E}E 是进化函数。这个过程零停机——新技能通过注入系统提示词立即生效,不需要修改任何模型参数。
在实验中,三类反复出现的失败模式驱动了技能进化:
- 时间格式合规:ISO 8601 格式,包含时区偏移
- 修改前备份协议:自动创建
.bak文件 - 命名约定遵循:日期前缀模式
2.2 慢循环:机会主义策略优化
当用户不活跃时,系统启动基于强化学习的权重更新:
θt+1=θt+α∇θE(τ,ξ,g′)∼B[R(πθ(⋅∣τ,Sg′))]\theta_{t+1} = \theta_t + \alpha \nabla_\theta \mathbb{E}_{(\tau, \xi, g') \sim \mathcal{B}} [R(\pi_\theta(\cdot \mid \tau, \mathcal{S}_{g'}))]θt+1=θt+α∇θE(τ,ξ,g′)∼B[R(πθ(⋅∣τ,Sg′))]
其中 RRR 是过程奖励模型,B\mathcal{B}B 是经验缓冲池。训练通过云端 LoRA 微调完成,更新后的权重通过热替换加载,整个过程对用户透明。
2.3 关键设计:技能代际版本控制
这是 MetaClaw 最精巧的工程设计之一。系统为每条轨迹打上技能代际标签 gig_igi:
- 技能进化前采集的失败轨迹属于支撑数据
- 技能进化后采集的成功轨迹属于查询数据
当技能从 ggg 进化到 g+1g+1g+1 时,训练器会清除所有版本 ≤g\leq g≤g 的样本。这防止了过时奖励信号污染策略更新——一个在旧技能下获得低奖励的轨迹,在新技能下可能已经不再代表真实的策略表现。
2.4 机会主义元学习调度器
OMLS 监控三种空闲信号来决定何时触发训练:
- 可配置的睡眠时段(如 23:00–07:00)
- 系统键盘不活跃(默认阈值:30分钟)
- Google Calendar 事件占用
任一信号指示用户缺席,训练窗口即刻打开。这种"见缝插针"的策略确保了智能体进化不会干扰正常使用。
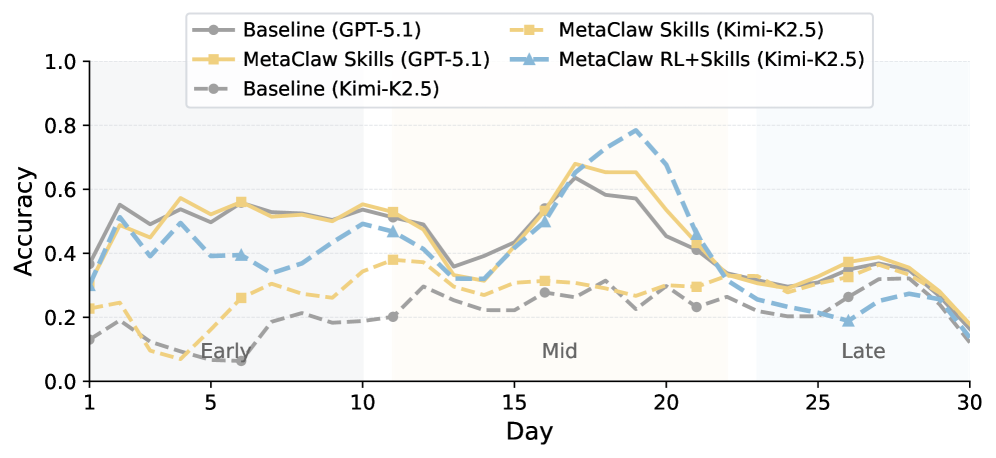
图2:30 天模拟工作日的逐日准确率(3天滚动均值)。实线为 GPT-5.1,虚线为 Kimi-K2.5。MetaClaw(Full)在中期(第 11-22 天)优势最为明显,后期任务难度超出累积知识时各方法趋于收敛。
三、MetaClaw-Bench:44 天模拟工作流基准测试
论文设计了一个精细的评估基准,模拟真实办公环境中的持续任务流。
基准结构
| 部分 | 模拟天数 | 题目数 | 每日题量 | 特点 |
|---|---|---|---|---|
| Part I | 30 天 | 346 | 10–15 | 持久化工作区状态,任务难度递增 |
| Part II | 14 天 | 588 | 42 | 基于规则的合规任务,渐进引入 5 条隐式偏好规则 |
任务分为两种类型:
- 文件检查型:结构化编辑/转换,产出文件由自动检查器验证
- 多选题型:领域特定规则的概念性程序问题
四、实验结果
4.1 主实验:MetaClaw-Bench
Part I(30 天,346 道题)
| 模型 | 配置 | 准确率 | 文件完成率 |
|---|---|---|---|
| GPT-5.2 | Baseline | 41.1% | 14.7% |
| GPT-5.2 | +Skills | 44.0% | 17.1% |
| Kimi-K2.5 | Baseline | 21.4% | 2.0% |
| Kimi-K2.5 | +Skills | 28.3% | 2.0% |
| Kimi-K2.5 | +Full MetaClaw | 40.6% | 16.5% |
Part II(14 天,588 道题)
| 模型 | 配置 | 准确率 | 文件完成率 |
|---|---|---|---|
| GPT-5.2 | Baseline | 44.9% | 58.4% |
| GPT-5.2 | +Skills | 49.1% | 67.5% |
| Kimi-K2.5 | Baseline | 21.1% | 18.2% |
| Kimi-K2.5 | +Skills | 26.9% | 33.8% |
| Kimi-K2.5 | +Full MetaClaw | 39.6% | 51.9% |
几个关键数据值得关注:
- Kimi-K2.5 在 Full MetaClaw 加持下,Part I 准确率提升了 89.7%(从 21.4% → 40.6%),几乎追平 GPT-5.2 的基线 41.1%
- 单看技能注入就让 Kimi-K2.5 准确率相对提升 32.2%
- Part I 文件完成率跳升了 8.25 倍(从 2.0% → 16.5%)
- Part II 文件完成率相对提升 185%(从 18.2% → 51.9%)
一个有意思的发现是:仅注入技能对文件检查型任务几乎无效(Part I 中 Kimi-K2.5 +Skills 的完成率仍是 2.0%),但加入 RL 策略优化后立刻飙升到 16.5%。这说明程序性的文件操作能力确实需要参数层面的更新,光靠提示词层面的技能注入不够。
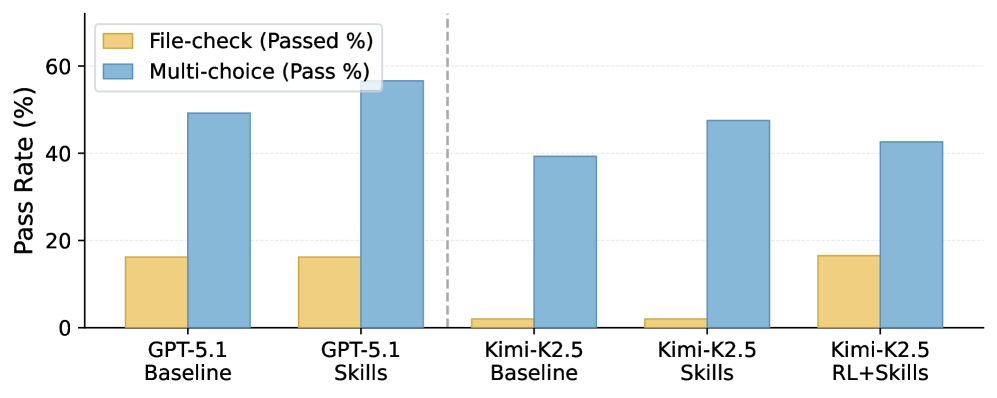
图3:按任务类型分解的通过率。文件检查型(黄色)仅靠技能注入几乎不变,但 MetaClaw(Full)下跳升 8.25 倍;多选题型(蓝色)靠技能提升明显,但 Full 模式下略有下降——策略向文件执行方向偏移。
4.2 RL 训练动态:清晰的拐点效应
Part II 的训练过程展示了一条教科书级的学习曲线:
| 训练阶段 | 文件完成率 |
|---|---|
| Days 1–4 | ~9% |
| Days 5–8 | 27–36% |
| Days 9–10 | 55–64% |
| Days 12–14 | 100% |
第 8 天出现了明显的拐点,此后文件完成率加速攀升。这意味着策略优化存在一个"量变到质变"的过程——前期积累的技能和少量梯度更新在某个临界点形成了协同效应。
4.3 跨领域验证:AutoResearchClaw
MetaClaw 在一个 23 阶段的自主科研流水线上也验证了效果:
| 指标 | Baseline | +MetaClaw | 变化 |
|---|---|---|---|
| 阶段重试率 | 10.5% | 7.9% | ↓24.8% |
| 精修循环次数 | 2.0 | 1.2 | ↓40.0% |
| 流水线完成率 | 18/19 | 19/19 | ↑5.3% |
| 综合鲁棒性评分 | 0.714 | 0.845 | ↑18.3% |
精修循环次数下降 40% 意味着智能体从失败中学到的技能显著减少了"试错—返工"的成本。
五、技术亮点与批判性分析
亮点
-
设计哲学的优雅性:快慢双循环不是简单的"既要又要",而是建立在两个机制的信息流互补上——技能为 RL 提供更好的探索空间,RL 为技能进化提供更有信息量的失败样本。
-
工程可行性高:不需要本地 GPU,LoRA 微调在云端完成,技能注入通过提示词实现,OMLS 利用自然空闲窗口——整个架构可以透明地集成到现有 Agent 平台中。
-
版本控制机制:技能代际标签 + 过时样本清除,用简洁的方案解决了在线学习中数据分布漂移的问题。
局限性与疑问
-
基准的代表性:934 道题的模拟工作流毕竟不是真实用户会话。论文也承认"绝对性能增益可能无法直接迁移到生产工作负载"。模拟中任务的分布、难度曲线、偏好规则都是人为设定的,真实场景的混乱程度远超预期。
-
GPT-5.2 上为什么没跑 Full MetaClaw? 论文只展示了 Kimi-K2.5 的完整流水线结果,GPT-5.2 仅到 Skills 层。这是因为 GPT-5.2 作为闭源模型无法进行 LoRA 微调。但这也暴露了一个现实问题——完整的 MetaClaw 框架只适用于可微调的开源/半开源模型。
-
空闲窗口检测的鲁棒性:依赖键盘不活跃、睡眠时段、Google Calendar 三个信号,在多设备使用、远程办公、团队共享等场景下可能频繁误判。如果训练窗口不足,慢循环的收益将大打折扣。
-
技能库的规模治理:随着使用时间增长,技能库会持续膨胀。论文未详细讨论技能的淘汰机制、冲突解决策略和检索效率退化问题。
-
32% 的相对提升 vs. 绝对水平:Kimi-K2.5 从 21.4% 到 28.3% 的"32% 相对提升"听起来很亮眼,但 28.3% 的绝对准确率在实际部署中仍然难以接受。完整流水线的 40.6% 更有说服力,不过这需要可微调模型 + 充足的空闲训练时间。
六、与相关工作的定位
MetaClaw 处于三个研究方向的交汇处:
- 技能/记忆增强智能体:与 Voyager、JARVIS 等方法不同,MetaClaw 将技能库视为可进化的元参数,而非静态资产
- LLM 的强化学习:引入了"何时训练"(机会主义调度)和"用什么数据训练"(版本化样本管理)两个维度,而非仅关注"怎么训练"
- 持续/元学习:将传统的离线元学习扩展到在线、异步、离散空间的 LLM 场景
这项工作与近期 OpenClaw 生态中的 self-improving-agent 技能形成了有趣的呼应——后者在工程层面实现了类似的"从错误中学习"机制,而 MetaClaw 则在算法层面给出了更严谨的框架。
七、总结与展望
MetaClaw 提出的核心命题值得整个 Agent 社区认真对待:部署不是终点,而是学习的起点。技能注入实现了秒级的行为适应,机会主义 RL 完成了小时级的能力升级,两者通过版本控制机制紧密协同。
从实用角度看,这个框架的轻量级代理架构(无需本地 GPU、透明集成现有平台)降低了实际部署的门槛。但从批判角度看,它仍然面临着基准与真实场景的差距、闭源模型不适用、技能库长期治理等挑战。
未来值得关注的方向包括:
- 技能的自动淘汰与合并机制
- 跨用户、跨实例的技能共享与迁移
- 在完全闭源模型上实现类似效果的纯提示词层自适应方案
论文链接:https://arxiv.org/abs/2603.17187
代码仓库:https://github.com/aiming-lab/MetaClaw
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 16
16 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)