开源音视频同步SOTA基座:极简的单流架构,2秒出片
AI视频生成已经迈入音视频同步生成的新纪元。
闭源巨头如谷歌的Veo 3.1,OpenAI的Sora 2,快手的Kling 3.0以及字节Seedace 2.0已经于展现出惊人的实力。
而开源社区的步伐却稍显迟缓,开发者们一直在寻找一个既能保证卓越生成质量,又能支持多语言,同时还拥有简洁架构以实现高效推理的完美基座。
上海创智学院(SII)生成式人工智能研究实验室(GAIR)与Sand.ai联合发布的开源音视频生成基础模型daVinci-MagiHuman来了。

daVinci-MagiHuman系统凭借极简的单流架构,只需2秒就能在1张H100显卡上生成5秒钟的精准音视频同步的视频画面。
daVinci-MagiHuman抛弃了复杂的跨模块交织,把文本、视频和音频全部放入一个统一的序列中处理,赋予了虚拟人物生动自然的神态与精准的口型匹配,为整个开源生态提供了一个极速且易于扩展的创作底座。
化繁为简
近期的开源视频生成系统通常偏爱双流或者多流架构。
由于视频和音频信号在时间结构与语义模式上存在天然差异,比如1秒钟的视频可能包含24帧画面,而1秒钟的音频却可能包含上万个采样点,许多模型为它们安排了独立的传输路径,并辅以专门的跨注意力机制或融合模块来进行信息的对齐。
如同工厂里安排了两条各自为战的流水线,在产品出厂前必须依靠一位经验丰富的协调员将画面和声音强行拼凑在一起。
复杂的结构设计确实能解决部分对齐难题,由此带来的计算不规则性却让工程实现和底层优化变得异常艰难,开发者需要耗费巨大精力去调试不同模块之间的通信效率。
研究团队设计了一个参数量高达150亿的单流Transformer。海量的参数赋予了模型极强的学习与理解能力。
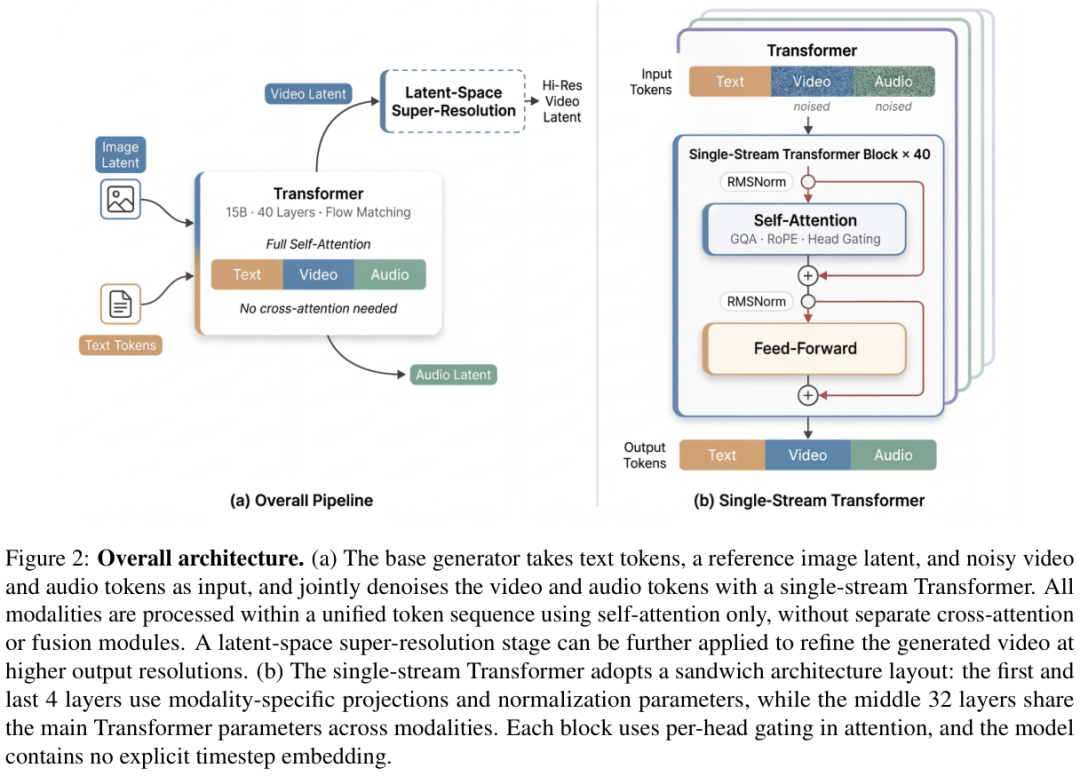
文本、视频和音频的Token被置于同一个共享权重的网络中,全过程仅依靠自注意力机制完成联合去噪。
没有任何独立的交叉注意力机制,没有任何外挂的融合模块,一切皆在基础的序列架构内自然发生。在自注意力机制的运转下,代表嘴唇动作的视频Token能够直接与代表发音的音频Token进行信息交换,无需绕道任何外部组件。
包含40层的网络深处,隐藏着几个精妙的设计巧思以应对多模态数据的冲击。
最外围的首尾各4层采用三明治架构布局,保留了特定模态的投影和归一化参数。如同三明治的两片面包,负责处理输入和输出边界的敏感信息,将外界千奇百怪的视听信号转化为模型能够理解的统一语言。
中间的核心32层完全抹平了模态间的壁垒,让绝大部分计算都在共通的表征空间内进行深度多模态融合,各种模态的数据于此处水乳交融,共同勾勒出最终的视听幻梦。
彻底摆脱时间步嵌入是另一项大胆的尝试。
早期的扩散模型在生成画面时,通常需要通过显式的时间步信息来指引去噪进程,仿佛在网络内部安装了一个倒计时的时钟。
daVinci-MagiHuman直接接收带噪的视频和音频潜变量,仅凭输入信号本身就能自主推断出当前的去噪状态。系统去掉了专门的时间步处理路径,让网络的注意力完全集中在数据本身的形态变化上。
在每一个注意力模块中,模型借鉴了大语言模型的最新实践,引入了逐头门控机制。每个注意力头配备了一个额外的标量门控,利用S型函数对注意力输出进行精细调节。如同为每一把乐器配备了专属的音量旋钮,在几乎不增加架构负担的前提下,提升了训练过程中的数值稳定性与模型的表达能力。
条件注入过程同样被精简到了极致。
带噪的视听Token、文本与图像提示,全部映射到同一个潜变量空间内交由单一模型处理。无论是根据一段文字描述凭空生成画面,还是提供1张静态照片让其开口说话,底层调用的皆是同一个极其纯粹的神经网络,彻底告别了繁冗的特定任务融合模块。
视听交融
聚焦于以人为中心的生成场景,虚拟角色不仅需要拥有逼真的肢体动作与面部细节,声音与神态的协同配合更是决定观感真实度的核心要素。
人类对于同类的面部表情极其敏感,哪怕是嘴角微微抽动与发音有半秒钟的错位,都会瞬间打破沉浸感。
模型在处理极具表现力的人物表演时,展现出了令人信服的自然度。情感饱满的面部微表情,以及随着语调起伏的肢体律动,都与生成的语音严丝合缝。
舞蹈动作拿捏也非常精准。
系统原生支持多语言口语生成,涵盖中文,包含普通话与粤语,英文,日文,韩文,德文以及法文,并具备向更广泛语种扩展的潜力。
发音规则截然不同的各种语言都在模型掌控之中。普通话的四声调转折,粤语复杂的声调变化,日语特有的连读与停顿,亦或是法语独有的发音习惯,模型都能根据文本内容精准还原出符合母语者习惯的自然发音,并同时匹配上最为合理的口型变化。
为了在提升画质的同时守住视听同步的底线,系统在推理阶段引入了潜空间超分辨率技术。直接从头生成高分辨率视频会因空间维度的剧增而消耗海量算力。
基础模型采取两步走的策略,在较低的分辨率下初步生成视频和音频的潜变量,随后由超分辨率阶段接手进行细节放大。
整个放大过程始终保持在潜空间内进行,避免了多余的解码与重新编码耗时。
系统利用三线性插值对视频潜变量进行上采样,注入少量噪声后,仅用5个去噪步即可完成画质蜕变。
在挑战1080p高清画质时,超分辨率模型还会在多个网络层中开启局部注意力机制,以此控制庞大的计算开销,确保计算资源得到合理分配。
最关键的细节在于,即使超分辨率阶段的核心任务是优化画面,网络依然会将基础阶段生成的音频潜变量作为辅助输入一并处理。
深度的视听绑定机制,使得系统即便在基础分辨率较低且画面极为粗糙的情况下,也能牢牢锁定唇形与语音的精准契合度。
在进行像素填充与细节刻画时,每一帧画面的口型边缘都在监听着潜藏在深处的音频波动,确保高清放大后的唇部肌肉运动依然严格遵从发音规律。
极致提速
天下武功唯快不破。
除了单流架构本身自带的硬件友好属性,团队在推理效率的打磨上倾注了大量心血,构建起一套全方位的加速体系。
解码环节往往是拖慢整体生成节奏的隐形负担。系统在编码阶段采用具备极高时空压缩比的Wan2.2变分自编码器(VAE),在推理端巧妙地将其替换为经过重新训练的轻量级涡轮解码器(Turbo VAE Decoder)。
此举大幅度削减了基础生成器与超分辨率管道关键路径上的解码开销。仿佛把异常复杂的压缩包交给了专门定制的极速解压软件,在保证文件内容完好无损的前提下将耗时压缩到了极致。
软件层面的深度优化同样功不可没。
团队将自研的全图PyTorch编译器无缝接入推理栈。通过跨越网络层边界融合计算算子,并把分散的分布式通信整合为更少的高效调用,编译器在1张H100显卡上压榨出了额外的1.2倍速度提升。
模型蒸馏技术的应用补齐了效率拼图的最后一块。
借助DMD-2分布匹配蒸馏算法,基础生成器被高度浓缩。经过蒸馏的网络在剥离无分类器引导(CFG)的情况下,仅需8个去噪步就能输出极具质感的视听画面。
数据说话
研究人员挑选了当前开源领域最具竞争力的Ovi 1.1与LTX 2.3作为对标参照系,从自动评测指标、人类偏好对比以及推理耗时三个维度展开了全面剖析。
在视觉质量的考量上,评测框架基于VerseBench基准库,并引入VideoScore2来衡量画面的视觉质感、文本对齐精度以及物理一致性。
音频质量的验证交给了TalkVid-Bench平台,使用智谱AI的语音识别模型对生成的音频进行转录,最终计算出词错误率(WER)。
针对中日韩等语言,系统采用字符级别的错误率计算方式,排除了分词标准不一带来的干扰。
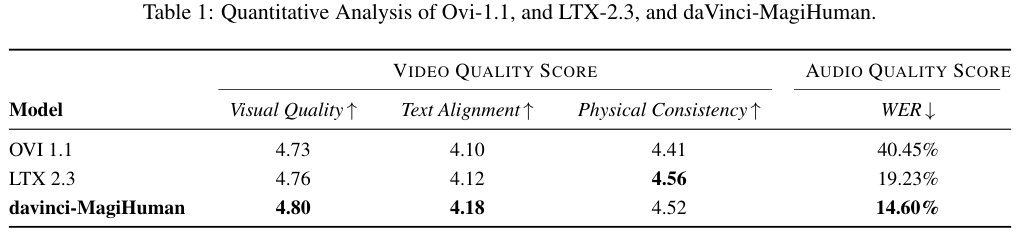
如上方表1的数据对比所展示的,daVinci-MagiHuman在视觉质量与文本对齐两项关键指标上均拔得头筹,分别拿下了4.80与4.18的高分。
最令人瞩目的成绩出现在语音清晰度测试中,词错误率被压低至14.60%,大幅超越了Ovi 1.1的40.45%以及LTX 2.3的19.23%。
为了进一步探究模型在真实观影视角下的表现,团队邀请了10位评估人员,对2000组随机分配的视频对进行盲测。
每位评委需要完成200组打分,其中包括对各个竞争对手的100次横向对比。评判标准涵盖了整体视听质量、同步精度以及自然度。
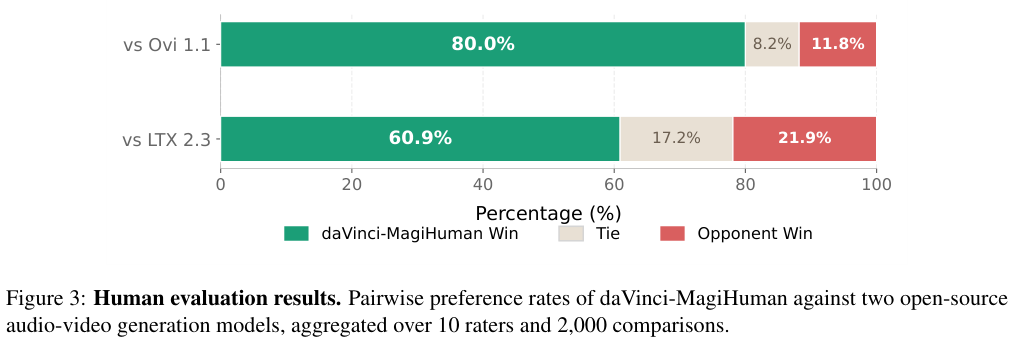
在与Ovi 1.1的直接较量中,daVinci-MagiHuman取得了80.0%的胜率,对手仅有11.8%的获胜空间,另有8.2%为平局。
面对同样实力强劲的LTX 2.3时,模型依然保持着60.9%的高胜率,将对手的胜率牢牢压制在21.9%,平局占比17.2%。
端到端推理延迟同样表现优异。
所有的测试均在1张H100显卡上完成,基础阶段统一采用蒸馏后的模型生成256p画面,更高清的输出交由超分辨率阶段与涡轮解码器接力完成。
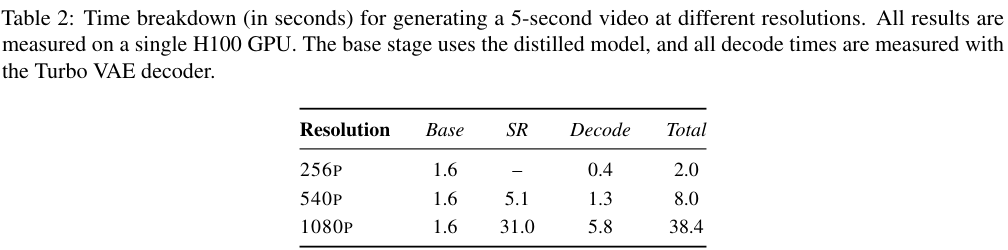
表2清晰地记录了生成1段5秒钟视频的耗时拆解。
在基础的256p分辨率下,整个流水线运转高效,仅仅耗去1.6秒的基础推理时间与0.4秒的解码时间,总共仅需2秒即可交卷。
由于基础阶段的耗时被锁定在1.6秒,向更高分辨率冲击时所增加的时间成本主要源自超分辨率处理与解码过程。在处理540p画质时,耗时温和地上升至8.0秒。即便将画质飙升至极致的1080p,超分辨率耗时增加到31.0秒,解码耗时5.8秒,全套流程跑完只需短短的38.4秒。
从繁复交错的多流组装,回归到纯粹极简的单流网络,daVinci-MagiHuman为整个行业的开源生态点亮了一盏新的明灯。
参考资料:
https://github.com/GAIR-NLP/daVinci-MagiHuman
https://huggingface.co/GAIR/daVinci-MagiHuman

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献157条内容
已为社区贡献157条内容

所有评论(0)