第二章 部署与推理
CI/CD(持续集成和持续交付)
CI/CD 是一种软件开发实践,旨在通过自动化软件构建、测试和部署流程来提高开发团队的效率和质量。
持续集成(CI):
- 目的:频繁地将代码变更集成到主分支;
- 实践:开发者经常(通常是每天多次)将代码变更合并到共享仓库中。每次提交都通过自动化构建和自动化测试来验证,以确保变更不会破坏现有的功能;
- 工具:通常使用版本控制系统(如Git)、构建工具(如Maven、Gradle)、自动化测试工具(如JUnit、NUnit)和持续集成服务器(如Jenkins、Travis CI、GitLab CI)
持续交付/部署(CD):
- 目的:确保软件可以随时部署到生产环境中;
- 实践:在持续集成的基础上,持续交付增加了将软件自动部署到测试、暂存或生产环境的步骤。这包括自动化部署流程,但不一定意味着每次变更都会立即发布到生产环境;
- 工具:除了持续集成的工具外,还包括部署工具(如Ansible、Chef、Puppet)和配置管理工具(如Terraform、CloudFormation)
DevOps(运维和开发)
DevOps 是一种让开发和运维协同工作、通过自动化和持续交付来实现软件“快速且稳定”发布的方法论。
DevOps 的核心价值包括:
- 自动化:通过自动化工具和流程来减少手动操作,提高效率和减少错误。
- 持续集成/持续部署(CI/CD):频繁地将代码变更集成到主分支,并通过自动化测试和部署流程快速发布到生产环境。
- 敏捷开发:采用敏捷方法论,如Scrum或Kanban,以快速响应变化和持续交付价值。
- 监控和反馈:实时监控系统性能和用户反馈,以便快速识别和解决问题。
- 文化和沟通:鼓励团队成员之间的开放沟通和协作,打破传统的部门壁垒。
传统开发:开发写完,扔给测试——测试测完,扔给运维——运维上线——出事再找开发
DecOps模式:开发、测试、运维共同参与交付—— 自动化减少人工交接——上线后持续监控和反馈——大家共同对结果负责
常见的DevOps工作流:开发写代码——提交到代码仓库——CI自动执行——CD自动部署——线上监控
AIOps
AIOps 是人工智能运维(Artificial Intelligence for IT Operations)的缩写,是一种利用人工智能和机器学习技术来改进 IT 运维的实践。AIOps 旨在通过自动化和智能化来提高 IT 运维的效率和质量。
AIOps的核心目标是从海量的运维数据中提取有价值的信息,实现故障的快速发现、准确诊断和自动修复,从而提高IT系统的可靠性和运维效率。
AIOps的关键组成部分包括数据收集、存储和分析,以及基于这些数据的智能决策和自动化响应。它通常涉及到以下几个方面:
-
数据源:AIOps平台需要从各种IT基础设施组件、应用程序、性能监控工具和服务凭单系统中收集数据。包括各种指标(CPU利用率、内存使用、接口延迟、QPS、错误率、磁盘IO);日志、事件(机器重启、服务更新、配置变更);告警(CPU超过90%、接口超时、服务不可用)
-
大数据分析:利用大数据技术处理和分析收集到的海量数据,以识别和预测潜在的问题;
-
机器学习:应用机器学习算法来提高对数据的理解和分析能力,从而实现更准确的故障预测和根因分析;
-
自动化:可以被系统中的各种信号自动触发,自动分析,然后基于分析结果自动触发响应措施,减少人工干预,提高问题处理的速度和效率;
-
可视化和报告:通过可视化工具展示分析结果和运维状态,帮助IT团队更好地理解系统性能和做出决策。
与传统运维监控的区别:
传统监控
-
主要依赖人工设规则
-
看到异常就报警
-
人再去看日志、排查原因
-
告警容易很多、很乱
AIOps
-
不只是规则,还用算法识别模式
-
能做异常检测、关联分析、根因定位
-
能减少无效告警
-
更进一步还能辅助决策甚至自动处理
MLOps
Machine Learning Operations,机器学习运维。指的是对机器学习模型从数据准备、特征工程、训练评估、模型注册、部署上线到监控迭代的全生命周期进行工程化管理。它本质上是 DevOps 在机器学习场景中的延伸,但相比普通软件工程,MLOps 还要额外处理数据版本、特征一致性、模型漂移和持续训练等问题,目标是让模型能够稳定、可复现地落地到生产环境。
tips:在工业界,人们先想到AI可以辅助运维,然后才意识到AI本身也需要运维,所以‘AIOps’的名称被先指代为AI运维,而后来AI模型的运维只能使用‘MLOps’这个名字了。
作用是什么,解决什么问题,取代的是什么?
LLMOps
LLMOps 是 Large Language Model Operations,指的是围绕大语言模型生产落地的一整套工程体系。它关注的不只是模型部署,还包括基座模型选择、Prompt 管理、RAG 检索链路、推理服务、成本控制、安全治理、效果评测和持续优化。它可以看作是 MLOps 在大模型场景下的延伸,但因为大模型应用对 Prompt、上下文、知识增强和输出安全高度敏感,所以 LLMOps 的重点比传统 MLOps 更偏向推理阶段和应用链路治理。
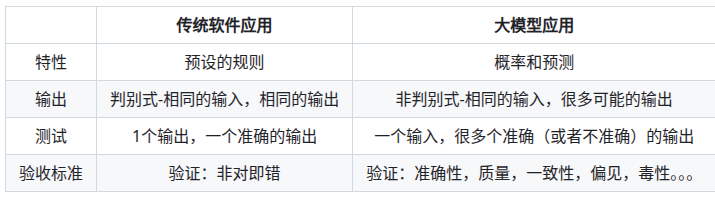

LLMOps,一般指的是大模型应用的运维,而不是大模型的训练,因为大模型的训练是一个离线的过程,而大模型的应用是一个在线的过程。
Output-Token与Input Token谁更贵
首Token延迟与其余Token延迟
-
首token延迟,Time To First Token (TTFT), prefill, Prefilling
指的都是从输入到输出第一个token 的延迟;
-
每个输出 token 的延迟(不含首个Token),Time Per Output Token (TPOT)
指的是第二个token开始的吐出速度;
-
延迟Lantency
理论上即从输入到输出最后一个 token 的时间,原则上的计算公式是:Latency = (TTFT) + (TPOT) * (the number of tokens to be generated);
-
Tokens Per Second (TPS):
模型每秒吐字多少。
估算理论的大模型推理速度TPS
prefill更偏算力瓶颈
先估算总的FLOPs(处理整段Prompt需要的总计算量):FLOPsprefill≈L⋅2P+Attention(L**2)。L是prompt的长度,P是模型的参数量,粗略看成每个参数大致参与两次计算(一次乘法,一次加法),另外还要加上注意力额外需要的算力。
除以有效算力:Latencyprefill(prefill阶段的耗时)≈总的FLOPs/有效算力
Decode更偏显存带宽瓶颈
TPS≈有效显存带宽/模型权重大小
有效显存带宽:BWeff,注意与峰值带宽区分。如果给的是峰值,那么需要乘以一个效率系数(0.3-0.8),才得到有效显存带宽。
模型权重大小:Wbytes,模型权重总字节数,等于模型参数量乘以每个参数占用字节。
(KV cache可以用来提速,采用空间换时间的思想)
大模型的推理框架
为什么需要推理框架?
除了分布式推理和支持量化之外,大模型推理框架最大的用处是加速推理。加速推理的主要目的是提高推理效率,减少计算和内存需求,满足实时性要求,降低部署成本:
计算和内存:大模型通常需要大量的计算资源和内存来处理复杂的任务。这在资源受限的场景中,如移动设备或边缘计算环境中,会造成推理效率低下的问题。为了解决这一问题,需要通过优化技术提高推理效率,减少计算和内存需求;
实时性:在许多应用场景中,如语音助手、实时翻译等,用户期望能够获得即时的反馈。大模型的推理速度直接影响到用户体验。因此,加速推理可以减少延迟,提供更流畅的交互体验;
部署成本:大模型的部署需要昂贵的硬件支持,如高性能GPU。通过推理加速,可以在较低成本的硬件上部署大模型,降低部署成本,使得大模型的应用更加广泛;
系统性能优化:在实际部署中,大模型的推理性能受到系统层面因素的影响,如内存带宽、计算单元的利用率等。通过系统级别的优化,可以提高大模型的推理速度和效率。
加速推理的技术
提高计算效率
算子融合和定制 Kernel。最经典的是 FlashAttention,Flash Attention通过减少注意力计算的复杂度来提高计算效率。
减少计算量
量化,例如从 FP16/BF16 降到 INT8、FP8、INT4。还有蒸馏和结构化剪枝。
降低复杂度
MQA、GQA、MLA
减少重复计算
KV Cache(键值缓存)通过缓存注意力计算中的键值对,减少重复计算量,从而提高推理效率。
提高吞吐量
Continuous Batching(连续批处理)通过连续处理多个输入样本,提高了计算效率和吞吐量。
常用推理框架
vLLM
vLLM是一种基于PagedAttention的推理框架,通过分页处理注意力计算,实现了高效、快速和廉价的LLM服务。vLLM在推理过程中,将注意力计算分为多个页面,每个页面只计算一部分的注意力分布,从而减少了计算量和内存需求,提高了推理效率.
主要掌握pagedAttention
一种面向推理阶段的 KV Cache 内存管理 + attention 计算方式,用来解决长上下文和高并发场景下 KV Cache 占用大、碎片多、批处理难做 的问题。通过这种方式把 KV cache 的浪费降到接近 0,并让吞吐相对当时方案提升 2 到 4 倍。
PagedAttention = 把每个请求的 KV Cache 不再要求连续存放,而是像操作系统分页一样,拆成很多固定大小的 block/page,再用一个映射表去找到这些 block。
与FlashAttention相比
- FlashAttention:更偏向怎么把 attention 算得更快、更省中间显存
- PagedAttention:更偏向怎么把 KV Cache 存得更合理、取得更高效
vLLM特性
-
PagedAttention算法:vLLM利用了全新的注意力算法「PagedAttention」,有效管理注意力机制中的键(key)和值(value)内存,减少了显存占用,并提升了模型的吞吐量。
-
多GPU支持:vLLM支持多GPU系统,可以有效地分布工作负载,减少瓶颈,增加系统的整体吞吐量。
-
连续批处理:vLLM支持连续批处理,允许动态任务分配,这对于处理工作负载波动的环境非常有用,可以减少空闲时间,提高资源管理效率。
-
推测性解码:vLLM通过预先生成并验证潜在的未来标记来优化Chatbots和实时文本生成器的延迟,减少LLM的推理时间。
-
优化的内存使用:vLLM的嵌入层针对内存效率进行了高度优化,确保LLM平衡有效地利用GPU内存,解决了大多数LLM(如ChatGPT)的内存资源问题而不牺牲性能。
-
LLM适配器:vLLM支持集成LLM适配器,允许开发者在不重新训练整个系统的情况下微调和定制LLM,提供了灵活性。
-
与HuggingFace模型的无缝集成:用户可以直接在HuggingFace平台上使用vLLM进行模型推理和服务,无需额外的开发工作。
-
支持分布式推理:vLLM支持张量并行和流水线并行,为用户提供了灵活且高效的解决方案。
-
与OpenAI API服务的兼容性:vLLM提供了与OpenAI接口服务的兼容性,使得用户能够更容易地将vLLM集成到现有系统中。
-
支持量化技术:vLLM支持int8量化技术,减小模型大小,提高推理速度,有助于在资源有限的设备上部署大型语言模型。
SGLang
Text Generation inference
Text Generation Inference是一个由Hugging Face开发的用于部署和提供大型语言模型(LLMs)的框架。它是一个生产级别的工具包,专门设计用于在本地机器上以服务的形式运行大型语言模型。TGI使用Rust和Python编写,提供了一个端点来调用模型,使得文本生成任务更加高效和灵活。
TGI的特性
Text Generation Inference(TGI)1是一个由Hugging Face开发的用于部署和提供大型语言模型(LLMs)的框架。它是一个生产级别的工具包,专门设计用于在本地机器上以服务的形式运行大型语言模型。TGI使用Rust和Python编写,提供了一个端点来调用模型,使得文本生成任务更加高效和灵活.
-
简单的启动器:TGI提供了一个简单的启动器,可以轻松服务最流行的LLMs。
-
生产就绪:TGI集成了分布式追踪(使用Open Telemetry)和Prometheus指标,满足生产环境的需求。
-
张量并行:通过在多个GPU上进行张量并行计算,TGI能够显著加快推理速度。
-
令牌流式传输:使用服务器发送事件(SSE)实现令牌的流式传输。
-
连续批处理:对传入请求进行连续批处理,提高总体吞吐量。
-
优化的推理代码:针对最流行的架构,TGI使用Flash Attention和Paged Attention等技术优化了Transformers代码。
-
多种量化支持:支持bitsandbytes、GPT-Q、EETQ、AWQ、Marlin和fp8等多种量化方法。
-
安全加载权重:使用Safetensors进行权重加载,提高安全性。
-
水印技术:集成了"A Watermark for Large Language Models"的水印技术。
-
灵活的生成控制:支持logits warper(温度缩放、top-p、top-k、重复惩罚等)、停止序列和对数概率输出。
-
推测生成:实现了约2倍的延迟优化。
-
引导/JSON输出:支持指定输出格式,加速推理并确保输出符合特定规范。
-
自定义提示生成:通过提供自定义提示来指导模型的输出,从而轻松生成文本。
-
微调支持:利用微调模型执行特定任务,以实现更高的精度和性能。
-
硬件支持:除了NVIDIA GPU,TGI还支持AMD GPU、Intel GPU、Inferentia、Gaudi和Google TPU等多种硬件。
vLLM、SGLang和TGI都属于把模型高效挂成服务的框架。
TensorRT-LLM
TensorRT-LLM 是 NVIDIA 提供的一个用于优化大型语言模型(LLMs)在 NVIDIA GPU 上的推理性能的开源库。它通过一系列先进的优化技术,如量化、内核融合、动态批处理和多 GPU 支持,显著提高了 LLMs 的推理速度,与传统的基于 CPU 的方法相比,推理速度可提高多达 8 倍。
特性
-
模型优化:TensorRT可以导入从主要深度学习框架训练好的模型,并生成优化的运行时引擎,这些引擎可以部署在数据中心、汽车和嵌入式环境中。
-
高性能推理优化:TensorRT通过层融合、精度校准、内核自动调优等技术,大幅提升推理速度。
-
低延迟:TensorRT优化计算图和内存使用,从而显著降低推理延迟,适用于实时AI应用。
-
多精度支持:TensorRT支持FP32、FP16、INT8等多种精度,允许在精度和性能之间进行平衡。
TenorRT-LLM关注如何优化GPU算模型,更偏底层。
Ollama
Ollama是一个开源的大型语言模型(LLM)服务工具,它旨在简化在本地运行大语言模型的过程,降低使用大语言模型的门槛。它允许开发者、研究人员和爱好者在本地环境中快速实验、管理和部署最新的大语言模型,包括但不限于Qwen2、Llama3、Phi3、Gemma2等开源的大型语言模型。Ollama通过提供一个简单而高效的接口,使用户能够轻松地创建、运行和管理这些模型,同时还提供了丰富的预构建模型库,方便集成到各种应用程序中。
Ollama实现本地一键把模型跑起来。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)