Transformer的自注意力机制原理
·
Transformer的自注意力机制(Self-Attention Mechanism)是模型的核心组件,它允许模型在处理序列数据时,动态地关注序列中不同位置的信息,从而捕捉序列内部的复杂依赖关系。以下是自注意力机制的详细原理:
一、自注意力机制的核心思想
自注意力机制的核心思想是让模型在处理序列中的每个元素时,能够“看到”并考虑序列中的其他所有元素。这种机制通过计算序列中每个元素与其他元素之间的相关性得分(注意力分数),动态地分配注意力权重,从而决定在生成当前元素的表示时,应该关注序列中的哪些部分。
二、自注意力机制的计算步骤
自注意力机制的计算步骤主要包括以下几个部分:
-
生成查询(Query)、键(Key)和值(Value)向量:
- 对于输入序列中的每个元素,通过线性变换将其转换为查询向量(Query)、键向量(Key)和值向量(Value)。这些变换通常通过可学习的权重矩阵实现。
- 查询向量表示当前元素“想要寻找什么信息”,键向量表示每个元素“可以提供什么信息”,值向量则存储着实际的特征表达。
-
计算注意力分数:
- 通过计算查询向量与所有键向量的点积相似度,得到注意力分数。这个分数反映了当前元素与其他元素之间的相关性。
- 为了防止点积结果过大导致梯度消失或爆炸,通常会除以一个缩放因子(通常是键向量维度的平方根)。
-
归一化注意力权重:
- 将注意力分数通过softmax函数进行归一化,得到注意力权重。这些权重表示了当前元素与其他元素之间的相对重要性,且所有权重之和为1。
-
加权求和:
- 使用注意力权重对值向量进行加权求和,得到当前元素的输出表示。这个输出表示融合了序列中其他元素的信息,从而捕捉到了元素之间的依赖关系。
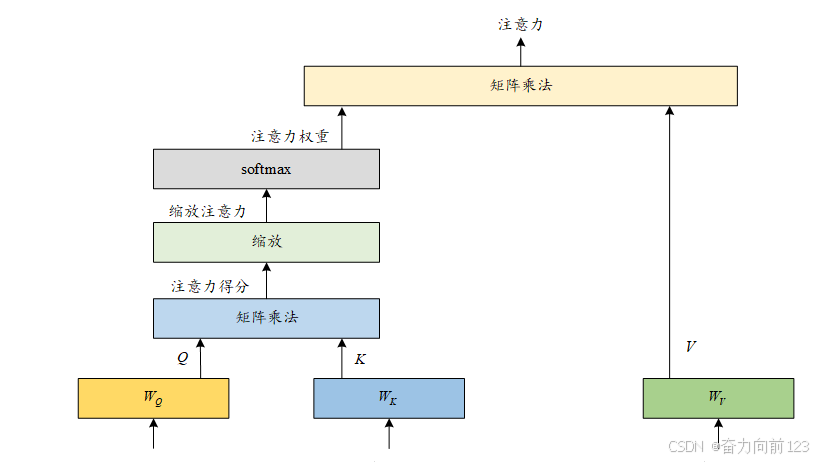
三、自注意力机制的数学表示
自注意力机制的数学表示可以形式化为以下步骤:
-
线性投影:
- 对于输入序列 X=[x1,x2,...,xn],其中 xi∈Rd,通过线性变换生成查询、键和值矩阵:
- Q=X⋅WQ,Q∈Rn×dk
- K=X⋅WK,K∈Rn×dk
- V=X⋅WV,V∈Rn×dv
- 其中 WQ,WK∈Rd×dk,WV∈Rd×dv 是可学习的权重矩阵。通常 dk=dv=d/h,其中 h 是多头数量。
- 对于输入序列 X=[x1,x2,...,xn],其中 xi∈Rd,通过线性变换生成查询、键和值矩阵:
-
计算注意力分数:
- S=Q⋅KT,S∈Rn×n
- Sij 表示第 i 个位置对第 j 个位置的关注程度。
-
缩放与归一化:
- A=softmax(S/dk),A∈Rn×n
- 除以 dk 是为了缩放点积,避免当 dk 很大时 softmax 进入饱和区。
- Aij 表示第 i 个位置分配给第 j 个位置的注意力权重。
-
加权求和:
- Z=A⋅V,Z∈Rn×dv
- Zi 是第 i 个位置经过自注意力后的新表示,融合了全序列的信息。
四、多头自注意力机制
为了捕捉序列中不同类型的依赖关系,Transformer引入了多头自注意力机制(Multi-Head Self-Attention)。多头自注意力机制通过并行计算多个自注意力,让模型同时关注不同位置的不同表示子空间。具体步骤如下:
-
多头投影:
- 将查询、键和值矩阵分别线性投影到 h 个不同的低维空间。
- headi=Attention(Q⋅WiQ,K⋅WiK,V⋅WiV)
- 其中 WiQ,WiK∈Rd×dk,WiV∈Rd×dv,dk=dv=d/h。
-
并行计算:
- h 个注意力头独立计算,互不干扰。
-
拼接融合:
- 将所有头的输出拼接,再经过一次线性投影。
- MultiHead(Q,K,V)=Concat(head1,...,headh)⋅WO
- 其中 WO∈Rh⋅dv×d。
五、自注意力机制的优势
- 并行计算:自注意力机制中的计算可以并行执行,这比传统的循环神经网络结构效率更高。
- 长距离依赖建模:自注意力机制允许序列中的每个元素直接与所有元素交互,从而捕捉长距离依赖关系。
- 灵活性:通过调整“头”的数量,可以灵活地控制模型的复杂度和能力。
- 可解释性:自注意力机制生成的注意力图可以帮助解释模型是如何关注输入序列的不同部分的。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 23
23 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)