零样本与少样本学习
零样本与少样本学习 | 大模型开发核心技术系列 1.3
一、引言
你是否想过,为什么有时候只需要简单地告诉模型“把这个句子翻译成法语”,它就能准确完成,而有的时候却需要给出好几个例子才能理解你的意图?这背后的关键技术就是零样本学习(Zero-shot Learning)和少样本学习(Few-shot Learning)。理解并灵活运用这两种学习范式,是提升 AI 应用效率的关键技能。本文将深入解析它们的原理、实现方法和最佳实践。
二、基本概念
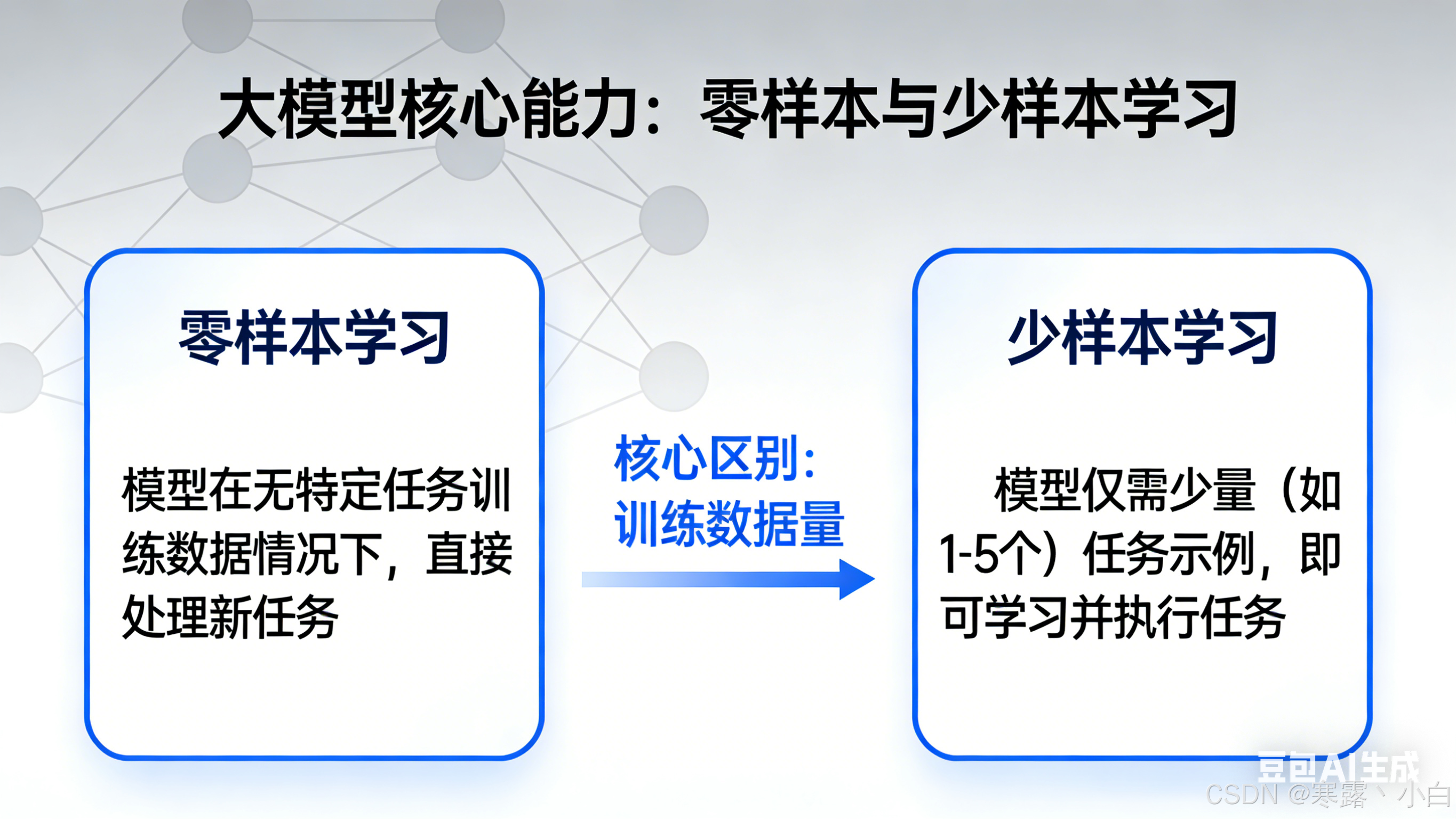
2.1 什么是零样本学习
零样本学习(Zero-shot Learning)是指模型在没有任何特定任务训练样本的情况下,仅凭对任务描述的理解来完成新任务的能力。这是大型语言模型最神奇的特性之一——模型通过预训练已经具备了广泛的知识和推理能力,可以泛化到从未见过的任务上。
# 零样本示例
# 任务:情感分类
# 没有提供任何训练示例
prompt = """
判断以下评论的情感是正面、负面还是中性:
"这个产品太棒了,超出预期!"
"""
# 模型直接输出:正面
零样本学习的本质是语言模型的推理能力。模型不需要针对每个任务进行专门的训练,而是理解了任务的语义和目标后,利用预训练过程中学到的知识来完成推理。这种能力随着模型规模的增大而显著增强,这也是为什么 GPT-4 等大型模型在零样本任务上表现优异的原因。
2.2 什么是有样本学习
有样本学习(In-context Learning)是指在提示词中提供少量任务示例,让模型通过这些示例理解任务要求和期望的输入输出模式。少样本学习(Few-shot Learning)是有样本学习的一种,特指提供 1-10 个示例的情况。
# 少样本示例
# 提供 3 个示例
prompt = """
把以下中文翻译成英文:
你好吗? -> How are you?
今天天气很好。 -> The weather is nice today.
我想吃饭。 -> I want to eat.
我爱你。 ->
"""
# 模型输出:I love you.
少样本学习利用了大型语言模型强大的模式识别能力。通过观察输入-输出对,模型能够推断出任务的规则,并将其应用到新的输入上。这种学习方式不需要模型参数的更新,是一种高效的即时学习范式。
2.3 零样本与少样本对比
| 特性 | 零样本 | 少样本 |
|---|---|---|
| 示例数量 | 0 | 1-10 |
| 任务理解 | 纯语义理解 | 语义+示例模式 |
| 适用场景 | 简单明确的任务 | 复杂或特殊格式任务 |
| 模型依赖 | 高 | 中 |
| 提示词长度 | 短 | 较长 |
三、零样本提示技术
3.1 指令提示
最简单的零样本方法就是直接给出任务指令。
# 基础指令
prompt = "把下面这句话翻译成法语:我爱你"
# 详细指令
prompt = """
作为翻译专家,请把用户提供的句子翻译成法语。
要求:
- 保持原文的语气
- 使用自然的表达
- 翻译:你好,很高兴认识你
"""
3.2 思维链提示
思维链(Chain of Thought,CoT)是一种零样本提示技术,它要求模型展示推理过程。
# 零样本 CoT 提示
prompt = """
一个水池有进水管和出水管。进水管8小时可以注满,
出水管12小时可以放完。
如果两管同时打开,需要多少小时才能注满?
请分步骤思考,最后给出答案。
"""
# 模型会展示:
# 1. 进水管每小时注入 1/8
# 2. 出水管每小时放出 1/12
# 3. 净注入 = 1/8 - 1/12 = 1/24
# 4. 需要 24 小时
3.3 角色设定
通过设定角色可以引导模型以特定方式完成任务。
# 角色设定示例
prompt = """
你是一位经验丰富的数学老师,擅长用简单易懂的方式解释数学概念。
请解释什么是导数,要求:
- 用生活中的例子引入
- 给出数学定义
- 举一个实际应用的例子
"""
四、少样本提示技术
4.1 标准少样本
提供几个完整的输入-输出示例,让模型理解任务模式。
# 标准少样本示例
prompt = """
将以下词语分类为食物、动物或交通工具:
苹果 -> 食物
狗 -> 动物
汽车 -> 交通工具
猫 ->
"""
# 输出:动物
4.2 格式规范化
使用统一的示例格式,让模型更容易识别输入输出模式。
# 规范化格式
prompt = """
按指定格式分类:
输入:苹果,分类:食物
输入:老虎,分类:动物
输入:飞机,分类:交通工具
输入:香蕉,分类:
"""
4.3 逐步引导
如果任务复杂,可以提供逐步引导的示例。
# 逐步引导示例
prompt = """
分步骤解决问题:
问题:5 个朋友去旅游,每人费用是 800 元,另外租车花费 300 元,请问人均多少钱?
步骤:
1. 计算总费用:5 × 800 + 300 = 4300
2. 计算人均:4300 ÷ 5 = 860
3. 答案:860 元
问题:小明有 50 元,买了 3 本书每本 12 元,还剩多少?
步骤:
"""
4.4 反面示例
有时候展示“什么不该做”也很有效。
# 包含反面示例
prompt = """
判断句子是否有礼貌,用"礼貌"或"不礼貌"标记:
大声说"这是我的!"-> 不礼貌
轻声说"请帮帮我"-> 礼貌
直接说"滚开"->
"""
五、示例选择策略
5.1 相关性原则
选择的示例应该与当前任务尽可能相关。
# 相关示例
# 当前任务:英文邮件写作
# 好的示例:不同场景的英文邮件
# 不好的示例:中文邮件、诗歌、新闻报道
5.2 多样性原则
示例应该覆盖任务的不同方面。
# 多样性示例
# 任务:情感分类
# 正面示例:积极的评论
# 负面示例:消极的评论
# 中性示例:事实陈述
5.3 数量平衡
示例数量不是越多越好,通常 3-5 个就能达到很好的效果。
# 建议数量
- 简单任务:1-2 个示例
- 中等任务:3-5 个示例
- 复杂任务:5-10 个示例
# 超过 10 个示例通常收益递减
六、实践案例
6.1 文本分类
# 零样本分类
prompt_zero = """
判断以下新闻标题属于哪个类别(科技/娱乐/体育/财经):
"苹果发布新一代 iPhone"
"""
# 少样本分类
prompt_few = """
分类新闻标题:
"科学家发现新粒子" -> 科技
"明星结婚引发关注" -> 娱乐
"C罗进球破纪录" -> 体育
"股市大涨 5%" ->
"""
6.2 数据提取
# 零样本提取
prompt_zero = """
从以下文本中提取人名和时间:
"2024年1月15日,李明参加了在北京举办的AI大会。"
"""
# 少样本提取
prompt_few = """
提取文本中的信息:
文本:"张三,男,1985年3月生,现任某互联网公司CTO"
提取:{"姓名":"张三","性别":"男","出生年份":"1985"}
文本:"李华2024年毕业于清华大学计算机系"
提取:
"""
6.3 格式转换
# 零样本转换
prompt_zero = """
把以下 JSON 转为 YAML 格式:
{"name": "张三", "age": 30, "city": "北京"}
"""
# 少样本转换
prompt_few = """
把 JSON 转为 YAML:
{"name": "张三", "age": 30} ->
name: 张三
age: 30
{"city": "上海", "score": 95} ->
"""
七、混合策略
7.1 零样本 + 少样本
可以先给出指令(零样本),再提供示例(少样本)作为补充。
# 混合策略
prompt = """
把中文翻译成英文。
示例:
我爱你 -> I love you
他很好 -> He is fine
她是老师 ->
要求:保持原文的语气
"""
7.2 角色 + 示例 + 格式
组合多种技巧以获得最佳效果。
# 组合策略
prompt = """
你是一位法律助手,帮助理解法律条款。
示例:
条款:"合同一方违约时,另一方有权解除合同并要求赔偿"
解读:这是一条关于违约责任的条款,违约方需要承担赔偿
条款:"债权人有权要求债务人按照约定的方式和时间履行债务"
解读:
"""
八、性能优化
8.1 提示词顺序
最新的研究表明,示例的顺序也可能影响结果。把最典型的示例放在前面可能效果更好。
# 推荐的示例顺序
# 典型 -> 边界/复杂 -> 待完成任务
8.2 示例格式一致性
确保所有示例的格式完全一致,减少模型的理解负担。
# ✅ 一致的格式
输入:xxx -> 输出:yyy
输入:zzz -> 输出:
# ❌ 不一致的格式
输入:xxx,输出:yyy
输入:zzz -> 输出:
8.3 动态选择
对于复杂系统,可以根据任务类型动态选择使用零样本还是少样本。
# 动态选择逻辑
def choose_prompt_strategy(task):
if task.is_simple():
return zero_shot_prompt
elif task.has_examples():
return few_shot_prompt
else:
return hybrid_prompt
九、适用场景分析
9.1 零样本适用场景
零样本适合以下场景:任务简单明确、任务类型常见(翻译、总结等)、无法提供示例、提示词长度受限。
# 零样本最佳场景
- 翻译
- 总结
- 分类(常见类型)
- 基本数学计算
- 常见格式转换
9.2 少样本适用场景
少样本适合以下场景:任务复杂或特殊、有特定输出格式要求、零样本效果不佳、需要排除特定模式。
# 少样本最佳场景
- 特定领域分类
- 结构化数据提取
- 自定义格式转换
- 排除特定回答模式
- 复杂推理任务
9.3 何时使用哪种
| 因素 | 零样本 | 少样本 |
|---|---|---|
| 任务复杂度 | 简单 | 复杂 |
| 任务常见度 | 常见 | 罕见 |
| 可用示例 | 无 | 有 |
| 精确度要求 | 一般 | 高 |
| 提示词长度 | 受限 | 充足 |
十、总结
零样本学习和少样本学习是大型语言模型的两大核心能力,它们让我们能够灵活地完成各种任务而无需额外训练。零样本学习简洁高效,适合简单直接的任务;少样本学习提供示例引导,适合复杂或特殊格式的任务。
在实际应用中,零样本和少样本并非互斥,而是可以灵活组合使用的。掌握这两种技术的原理和技巧,能够显著提升你与 AI 协作的效率和效果。记住,最好的提示词往往是在实践中不断迭代优化出来的。
参考资料
- OpenAI Few-shot Learning 指南
- Language Models are Few-Shot Learners(论文)
- Prompt Engineering 最佳实践

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)