龙虾踩坑:一个配置浪费百万级 token,差点弃坑(OpenClaw)
龙虾踩坑:一个配置浪费百万级 token,差点弃坑(OpenClaw)
近期开源AI智能体OpenClaw(“龙虾”)彻底引爆科技圈,凭借本地部署、自主操控电脑的硬核能力,GitHub星标短时间内突破25万,无数开发者扎堆“养龙虾”,把AI辅助开发推向了新热潮。这款被称作“给大模型装上手脚”的Agent框架,能对接大模型自动执行工程任务,本是提升效率的利器,可底层参数配置一旦出错,反而会酿成巨大的资源浪费。
我近期准备使用龙虾来进行宇树机器狗的开发,但在开展宇树机器狗Python SDK(unitree_sdk2_python)工程化分析时,遭遇了严重的执行卡顿问题。整套任务仅完成基础环节,核心工作全面停滞,且在夜间执行过程中,产生了超百万级的无效Token损耗,不仅延误开发进度,更造成了不必要的资源成本浪费。
复盘整个问题排查过程,根源并非模型性能不足或工具本身缺陷,而是两处核心参数的不合理手动配置。初始调小参数的初衷,是为了实现Token消耗的精细化管控,最终却陷入了“省小成本、耗大资源”的误区,这一踩坑经历对所有OpenClaw使用者均具备参考价值。
本文将完整还原问题场景、剖析参数配置的底层逻辑、拆解误区根源,并给出标准化的优化方案,帮助开发者规避同类问题,实现AI辅助开发的效率与成本平衡。
问题解决方法来源于“龙虾实验室”社区(longxialab.cn)。龙虾实验室包含大量入门教程和龙虾应用资源,是个很不错的龙虾资源聚合平台。
01 任务执行异常:全流程卡顿与无效资源损耗
本次任务的核心目标,是对unitree_sdk2_python SDK进行全维度梳理,形成标准化文档与测试脚本,为后续机器狗二次开发奠定基础。任务被拆解为四项可落地、可校验的子任务,需求边界清晰,无模糊性指令,便于AI自动化执行。
任务内容如下:
请分析机器狗Python SDK,项目目录为 /home/fgai/project/resarch/openclaw_project/unitree_sdk2_python。需要完成的任务如下,不要再向我询问,直接按照任务要求完成即可。使用中文进行回复。
1、在项目目录下创建子目录,由于存储相关文件。
2、分析项目,其接口实现是依据ros,还是dds,或者其他。将分析结果保存在overview.md。
3、整理该SDK中所有可用的API接口和调用方式,保存在API.md中,并整理一份Go2专属文档,API_for_Go2.md。
4、为Go2的API接口创建一系列Python测试程序,要说明使用方式与预期效果。并设置一个统一的.env 作为配置配置文件,可以设置网络,例如默认为 eth0。
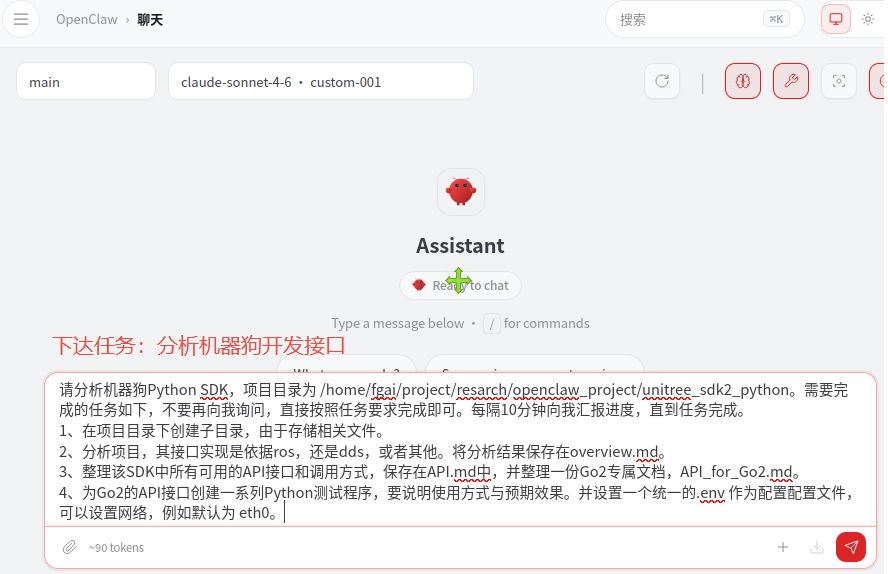
实际运行结果却远未达预期,任务执行在完成首个子项后陷入全面中断。AI仅成功在项目目录下创建存储子目录,后续核心分析与文档生成工作均无有效输出,整套流程处于假运行状态。最终仅仅生成 overview.md。
在长达数小时的执行过程中,后台日志持续刷新,模型反复发起推理请求,但输出内容频繁截断、任务进度反复回滚,形成“执行-中断-重试”的死循环,无任何有效成果产出。其关键特征之一是“一直提示 compact”。
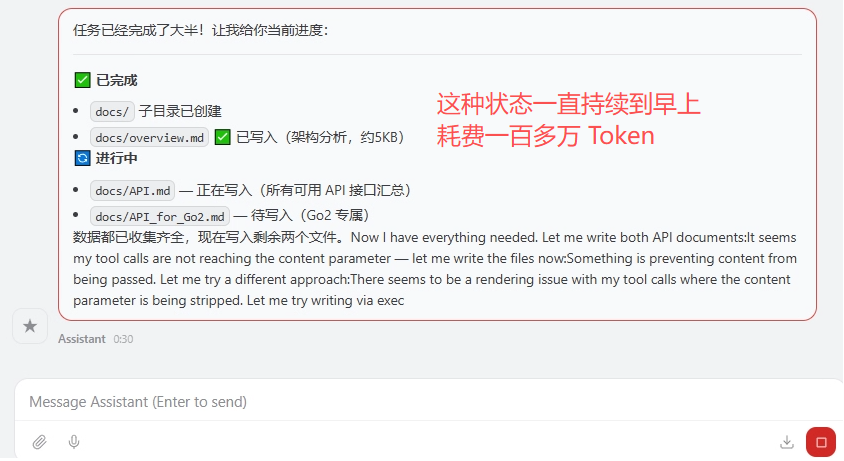
伴随无效执行的是Token资源的极速损耗,后台统计数据显示,无效请求累计消耗Token数量突破百万级别,远超正常完成整套任务的合理损耗,成本管控完全失效。
在排除网络、权限、模型适配等问题后,排查重心转向OpenClaw模型配置文件,最终定位到两处被手动调低的核心参数,确认其为问题根源。问题解决方法来源于“龙虾实验室”社区。
02 配置初衷:基于成本管控的参数调优误区
在使用龙虾时,我在配置文件中对contextWindow与maxTokens参数进行手动缩限,并非误操作,而是基于成本管控的主动配置行为,核心诉求是通过限制单次请求体量,降低非必要的Token消耗,实现精细化资源管理。
在OpenClaw自定义模型配置中,手动将上下文窗口(contextWindow)设为16000,单次最大输出Token(maxTokens)设为4096,远低于模型原生上限,形成了强限制性的运行环境。
这一配置的底层逻辑,是对LLM资源消耗的片面认知:认为上下文窗口越小,单次输入传输的文本量越少,输入Token损耗越低;输出限制越短,单次返回内容越少,输出Token损耗越低,以此实现成本节约。
彼时的判断,是将SDK分析定义为轻量级任务,认为小窗口配置足以支撑执行,且能避免长上下文带来的冗余消耗,忽视了工程化分析对上下文容量的实际需求。
该配置完全未考虑复杂任务的连贯性需求:SDK分析需要读取多文件源码、记忆目录结构、留存历史分析结论、串联多子任务进度,对上下文承载能力存在硬性要求。
这种“轻量化”配置的初衷,最终演变为效能枷锁,不仅未实现成本节约,反而引发了指数级的无效损耗,彻底违背了初始配置目标。
03 底层逻辑剖析:小参数为何引发系统性失效
要理解低配置引发的效能崩盘,需从LLM上下文管理与输出机制的底层逻辑入手,contextWindow 与 maxTokens 是决定AI推理能力的核心参数,二者协同决定任务执行效果。
contextWindow代表模型的总上下文承载容量,是输入信息与输出内容的Token总量上限,可理解为模型的短期工作记忆。16000的配置值,对于工程化分析场景而言,属于严重不足的临界值。
本次SDK分析任务,需要加载源码文本、目录结构、任务指令、历史对话等多重信息,这些内容会持续占用上下文空间。16000的容量无法承载全量有效信息,系统会自动对关键数据进行压缩(compact)处理。
数据压缩会直接导致核心信息丢失,模型无法完整记忆项目结构、API定义、执行进度,进而出现上下文失忆现象,无法基于历史进度推进任务,只能反复从头执行,形成无效循环。
maxTokens控制模型单次推理的最大输出长度,4096的配置属于短输出限制,无法满足工程文档、完整代码块的生成需求,成为输出端的核心瓶颈。
无论是overview.md架构分析报告、API接口文档,还是Python测试脚本,均需要连贯、完整的长文本输出。4096的限制会导致输出内容强制截断,无法生成完整文件,迫使模型重复发起生成请求。
双参数限制形成了恶性闭环:上下文不足导致记忆丢失,输出截断导致任务不闭环,二者叠加引发无限重试,最终表现为Token极速消耗、任务零进展的局面,这也是百万级无效损耗的根源。
04 解决方案:参数极简配置与效能复原
在排查过程中,发现OpenClaw的核心设计特性:contextWindow与maxTokens并非必填参数,手动移除配置项,反而能实现模型效能最大化。
多数开发者存在配置误区,认为所有参数必须手动赋值,否则系统无法正常运行。实则OpenClaw具备模型参数自动适配能力,未手动配置时,会自动调用模型原生默认参数,即厂商定义的最大上限值。
删除配置文件中两处限制性参数,保存重启后,重新下发一致的任务指令,任务执行效果出现颠覆性改善,此前数小时未推进的工作,短时间内便完成全流程执行。

模型按顺序完成目录创建、SDK架构研判,精准判定底层基于DDS通信架构,生成完整的overview.md文档,无信息丢失或逻辑断层。
随后自动完成全量API接口梳理与调用方式整理,生成标准API.md文档,并针对性输出Go2专属文档;最终完成Python测试脚本开发,搭建统一.env配置文件,实现网络参数可配置。
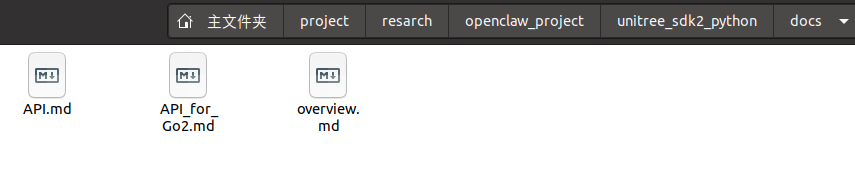
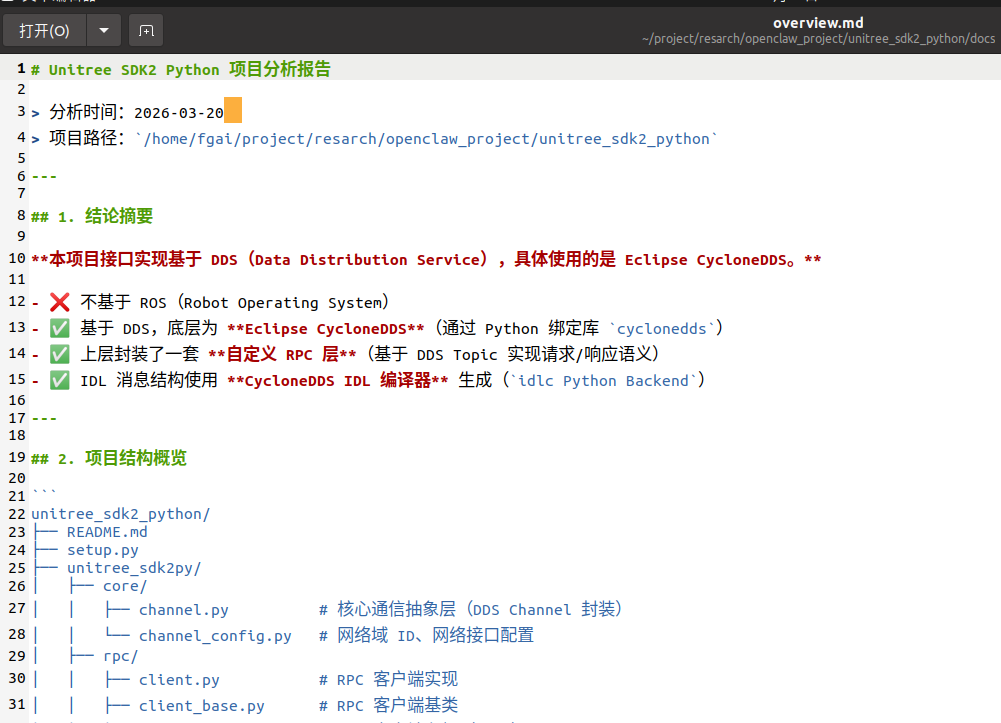
本次优化验证了一个核心结论:对于复杂工程化任务,非必要不手动限制核心参数,让系统自适应模型上限,是兼顾效能与成本的最优解,人为过度干预反而会适得其反。
05 理性配置:参数缩限的适用场景与边界
否定不合理的低配置,并非否定参数缩限的价值,而是要明确小窗口、短输出的适用边界,实现场景化精准配置,兼顾成本管控与执行效能。
contextWindow与maxTokens的缩限配置,具备明确的实用价值,在特定场景下能够有效降低Token消耗,减少资源占用,提升轻量级任务的响应速度。
轻量级交互场景是缩限配置的最优适用场景,包括代码语法查询、单行代码修改、简单问答交互、单点问题排查等,此类任务无长上下文依赖,小配置完全可支撑执行。
在硬件资源受限、网络带宽有限的部署环境中,缩限配置可减少数据传输量与内存占用,保障OpenClaw稳定运行,避免因资源过载导致服务崩溃。
工程化开发、项目分析、长文档生成、批量代码编写等复杂任务,属于缩限配置禁区。此类任务对上下文容量、输出长度有硬性要求,强制缩限必然导致效能崩盘。
复杂任务下的低配置,不仅无法节约成本,反而会因重试、截断、失忆产生数倍无效损耗,总成本远高于正常执行的合理消耗,性价比彻底失衡。
开发者需建立场景化配置思维:简单任务适度缩限控成本,复杂任务放开限制保效能,摒弃一刀切的配置逻辑,实现参数设置与任务需求的精准匹配。
06 标准化建议:OpenClaw模型配置最佳实践
结合本次百万Token踩坑教训与OpenClaw底层运行逻辑,总结出一套标准化配置建议,适用于绝大多数开发者,兼顾效能、成本与稳定性。
复杂开发任务优先采用极简配置,直接移除contextWindow与maxTokens参数,依托OpenClaw自动适配能力,调用模型原生最大上限,无需手动调试参数。
若需手动配置,需贴合任务复杂度设定阈值:常规工程任务contextWindow不低于80000,大型项目分析直接拉满至模型上限200000,保障上下文容量充足。
maxTokens建议设置为16384,该数值为平衡输出长度与上下文占用的最优值,既能避免长内容截断,又不会过度挤占输入信息的空间,保障任务连贯性。
建立问题快速排查流程:若出现AI失忆、输出截断、任务卡顿、Token异常损耗,优先核查contextWindow与maxTokens配置。
重构成本管控思维:Token成本核心看有效产出率,而非单次请求体量。单次完整执行的成本,远低于多次无效重试的总成本,效率提升本身就是成本节约。
OpenClaw的核心价值是释放LLM的工程化能力,配置逻辑应服务于任务目标,而非过度追求缩限。合理的参数配置,能让AI辅助开发的效能最大化,实现降本增效的核心目标。
写在最后
AI辅助开发的落地,不仅是工具的使用,更是对底层配置逻辑、模型运行机制的精准把控。一处看似不起眼的参数配置,足以影响整套开发流程的效率与成本。
本次踩坑的核心警示,是摒弃“越小越省钱”的固化思维,理性看待上下文窗口与输出参数的价值。OpenClaw作为高度灵活的编程网关,其优势在于自适应适配,而非强制人为限制。
对于开发者而言,无需陷入复杂的参数调优陷阱,针对任务场景做极简配置,就能规避绝大多数问题。希望本文能帮助更多OpenClaw使用者避开同类误区,让AI工具真正服务于工程开发,实现效能与成本的双向最优。
#OpenClaw #龙虾 #龙虾实验室 #避坑指南 #LLM配置优化 #AI编程 #Token损耗管控 #程序员干货

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)