从零开始:用Python搭建真正的智能Web AI Agent系统
你是否曾遇到过这样的场景?
你是否曾感叹ChatGPT的强大,却又苦恼于它“说完就忘”、无法执行实际任务?比如,你想让AI帮你安排会议、查询数据并生成报告,它却只能给出文字建议,无法真正调用日历API或执行计算?
传统的LLM交互就像一次性的问答机器——你提问,它回答,对话结束。但现实世界的任务往往需要多步骤推理、工具调用和状态持久化。
今天,我们就来聊聊如何用Python搭建真正的智能Web AI Agent,它不仅能理解你的意图,还能调用工具、执行任务,就像一个真正的数字助手!
一、什么是AI Agent?为什么需要它?
想象一下:你让助理“帮我安排下周二的团队会议,并准备会议提纲”。一个优秀的助理会:
- 推理:理解这是多步骤任务
- 执行:查看日历、预订会议室、起草议程
- 反馈:告知你结果并询问是否需要调整
这就是AI Agent的核心能力!它不再是简单的“输入-输出”模型,而是具备:
- 状态记忆:记住对话上下文和任务进度
- 工具调用:能使用计算器、API、数据库等外部工具
- 自主决策:根据情况决定下一步做什么
- 多步骤执行:分解复杂任务并逐步完成
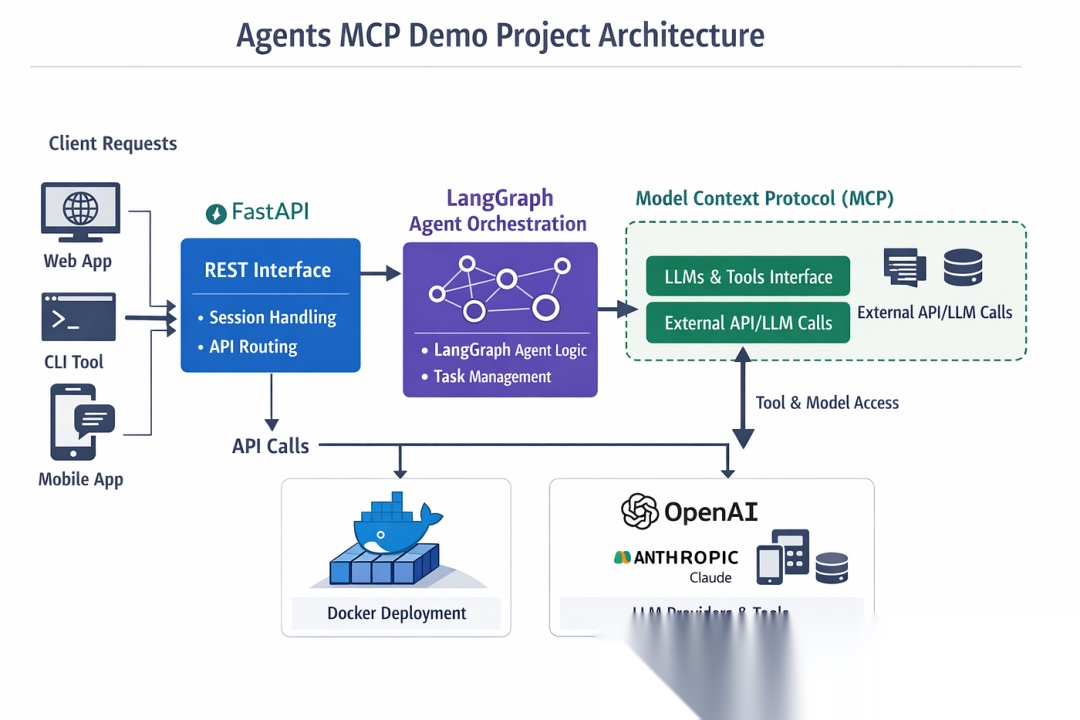
在本文中,我们将使用 FastAPI + LangGraph + MCP 三件套,构建一个完整的Web AI Agent系统。这个架构清晰、模块化、易于扩展,是当前构建生产级Agent的黄金组合。
二、项目架构全景图
我们先从整体上把握这个系统是如何工作的:
用户请求 → FastAPI(Web层) → LangGraph(Agent编排) → 工具执行 → LLM推理 ↑ ↑ ↑ ↑ HTTP接口 日志记录 状态管理 多LLM支持
这个分层架构确保了关注点分离,每层只做自己最擅长的事:
- FastAPI:处理HTTP请求/响应,提供RESTful API
- LangGraph:定义Agent的工作流程和决策逻辑
- MCP工具:提供外部能力(计算、时间查询等)
- LLM服务:负责核心推理能力
让我们深入每一层,看看代码如何实现。
三、FastAPI:Agent的Web入口
首先,我们需要一个Web接口让用户能与Agent交互。FastAPI以其高性能和易用性成为不二之选。
3.1 应用初始化与配置
打开main.py,看看如何设置一个现代的FastAPI应用:
# app/main.py""" FastAPI application entry point """import structlogfrom contextlib import asynccontextmanagerfrom fastapi import FastAPIfrom fastapi.middleware.cors import CORSMiddlewarefrom fastapi.responses import JSONResponsefrom app.api.v1.router import api_routerfrom app.core.config import settingsfrom app.core.logging import setup_loggingsetup_logging() # 初始化结构化日志logger = structlog.get_logger(__name__)# 生命周期管理:启动和关闭时的钩子@asynccontextmanagerasyncdef lifespan(app: FastAPI): logger.info("application_starting", environment=settings.ENVIRONMENT) yield# 应用运行中 logger.info("application_shutting_down")# 创建FastAPI应用实例app = FastAPI( title=settings.PROJECT_NAME, description="AI Agent with FastAPI, LangGraph, and MCP", version="0.1.0", lifespan=lifespan, # 绑定生命周期管理)# 配置CORS(跨域资源共享)app.add_middleware( CORSMiddleware, allow_origins=settings.ALLOWED_ORIGINS, # 允许的前端地址 allow_credentials=True, allow_methods=["*"], allow_headers=["*"],)# 挂载API路由app.include_router(api_router, prefix="/api/v1")# 健康检查端点@app.get("/health")asyncdef health_check(): return JSONResponse( content={ "status": "healthy", "environment": settings.ENVIRONMENT, } )# 根端点@app.get("/")asyncdef root(): return { "message": "AI Agent API", "docs": "/docs", # 自动生成的API文档 "version": "0.1.0", }
关键点解析:
@asynccontextmanager:优雅管理应用生命周期,类似"开机自检"和"关机清理"- 结构化日志:使用
structlog而非普通print,便于生产环境调试 - 自动API文档:访问
http://localhost:8000/docs即可查看交互式文档
3.2 配置管理:集中式设置
所有配置都通过 Pydantic Settings 集中管理,告别散乱的环境变量:
# app/core/config.py""" Application configuration """from typing import Listfrom pydantic_settings import BaseSettings, SettingsConfigDictclass Settings(BaseSettings): model_config = SettingsConfigDict( env_file=".env", # 从.env文件读取配置 case_sensitive=True, extra="ignore", # 允许额外的环境变量而不报错 ) # 应用基础配置 PROJECT_NAME: str = "AI Agent API" ENVIRONMENT: str = "development" DEBUG: bool = True # API配置 ALLOWED_ORIGINS: List[str] = ["http://localhost:3000", "http://localhost:8000"] # LLM配置(支持多供应商) LLM_PROVIDER: str = "openai"# 或 "anthropic" OPENAI_API_KEY: str = "" ANTHROPIC_API_KEY: str = "" DEFAULT_LLM_MODEL: str = "gpt-4o" DEFAULT_TEMPERATURE: float = 0.7 # 日志配置 LOG_LEVEL: str = "INFO" LOG_FORMAT: str = "console"# 或 "json" # Database (optional) DATABASE_URL: str = "postgresql+asyncpg://postgres:postgres@localhost:5432/ai_agent" # Observability (optional) LANGSMITH_API_KEY: str = "" LANGSMITH_PROJECT: str = "ai-agent-project" ENABLE_TRACING: bool = Falsesettings = Settings() # 全局配置实例
四、Agent核心:LangGraph编排引擎
这是整个系统的"大脑",负责控制Agent的思考流程。LangGraph让我们能够可视化地定义Agent的工作流。
4.1 Agent状态定义:记忆的核心
Agent需要记住对话历史,这是通过状态管理实现的:
# app/agents/state.py""" Agent state definition """from typing import Annotated, TypedDictfrom langchain_core.messages import BaseMessagefrom langgraph.graph.message import add_messages # 关键:自动消息累加class AgentState(TypedDict): # 使用Annotated标注特殊处理逻辑 messages: Annotated[list[BaseMessage], add_messages]
这是什么魔法?
Annotated:告诉LangGraph如何自动更新messages字段add_messages:自动将新消息追加到历史中,无需手动操作- 这就像给Agent配备了一个自动记录的对话本
4.2 构建Agent工作流图
现在来看最核心的部分——定义Agent如何思考和工作:
# app/agents/graph.py""" LangGraph agent definition """import structlogfrom langchain_core.messages import HumanMessage, AIMessagefrom langgraph.graph import StateGraph, START, ENDfrom langgraph.prebuilt import ToolNodefrom app.agents.state import AgentStatefrom app.agents.tools import get_toolsfrom app.services.llm import get_llmlogger = structlog.get_logger(__name__)def create_agent_graph(): """创建Agent工作流图""" # 1. 获取LLM和工具 llm = get_llm() tools = get_tools() llm_with_tools = llm.bind_tools(tools) # 让LLM知道它能使用哪些工具 # 2. 创建状态图 workflow = StateGraph(AgentState) # 3. 定义Agent节点(思考) asyncdef call_model(state: AgentState) -> dict: """LLM推理节点:分析当前状态并决定下一步""" logger.info("calling_model") # LLM基于当前对话历史进行推理 response = await llm_with_tools.ainvoke(state["messages"]) return {"messages": [response]} # 返回的消息会自动添加到状态中 # 4. 定义工具节点(执行) tool_node = ToolNode(tools) # 预建的ToolNode自动处理工具调用 # 5. 添加节点到图中 workflow.add_node("agent", call_model) # 思考节点 workflow.add_node("tools", tool_node) # 执行节点 # 6. 设置起始边 workflow.add_edge(START, "agent") # 从开始直接到agent思考 # 7. 定义条件边:Agent思考后该做什么? def should_continue(state: AgentState) -> str: """判断是否需要调用工具""" last_message = state["messages"][-1] # 如果LLM返回了工具调用请求,则执行工具 if hasattr(last_message, "tool_calls") and last_message.tool_calls: return"tools" return END # 否则结束 # 8. 添加条件边 workflow.add_conditional_edges( "agent", should_continue, ["tools", END] # 可能的两条路径 ) # 9. 工具执行后回到Agent继续思考 workflow.add_edge("tools", "agent") # 10. 编译图为可执行对象 return workflow.compile()# Agent单例模式,避免重复创建_agent = Nonedef get_agent(): """获取Agent实例(单例)""" global _agent if _agent isNone: _agent = create_agent_graph() return _agent
工作流可视化理解:
开始 → [Agent思考] → 需要工具? → 是 → [工具执行] → 返回思考 ↓否 ↑ 结束 ←--------------←
这就是经典的 ReAct模式(Reasoning-Acting):
- Reason:LLM分析当前情况,决定下一步
- Act:如果需要,调用工具执行
- Observe:获取工具结果,继续思考
- 重复直到任务完成
4.3 Agent调用入口
如何启动这个Agent工作流?
# app/agents/graph.py(续)asyncdef invoke_agent(query: str, session_id: str | None = None) -> dict: """调用Agent处理查询""" logger.info("invoking_agent", query=query) # 获取Agent实例 agent = get_agent() # 初始化状态:用户消息作为起点 initial_state = {"messages": [HumanMessage(content=query)]} # 执行Agent工作流 result = await agent.ainvoke(initial_state) # 提取最终回复 final_message = result["messages"][-1] response = { "response": final_message.content if isinstance(final_message, AIMessage) else str(final_message), "message_count": len(result["messages"]), # 总共的消息轮数 "session_id": session_id, # 会话ID,支持多轮对话 } return response
五、Agent的能力扩展:工具系统
Agent的强大之处在于能调用工具。我们使用MCP(Model Context Protocol) 风格的工具定义。
5.1 定义工具:让Agent"有手有脚"
# app/agents/tools.py""" Custom tools for the agent """import structlogfrom typing import Listfrom langchain_core.tools import tool # 关键装饰器from datetime import datetimelogger = structlog.get_logger(__name__)@tooldef calculator(expression: str) -> str: """Evaluate a mathematical expression""" try: # 安全地计算数学表达式 result = eval(expression, {"__builtins__": {}}) logger.info("calculator_used", expression=expression, result=result) return str(result) except Exception as e: returnf"Error: {str(e)}"@tooldef get_current_time() -> str: """Get the current time in ISO format""" return datetime.now().isoformat()def get_tools() -> List: """获取所有可用工具""" return [calculator, get_current_time]
工具系统亮点:
@tool装饰器:自动生成工具描述,LLM能理解其功能- 类型提示:Python的类型提示被转换为工具schema
- 文档字符串:就是工具的"说明书",LLM靠它理解工具用途
5.2 MCP服务器:专业化的工具服务
对于更复杂的工具,我们可以创建独立的MCP服务器:
# mcp_servers/math_server.py""" Example MCP server for math operations """from fastmcp import FastMCP# 创建MCP服务器实例mcp = FastMCP("Math Server")@mcp.tool()def add(a: int, b: int) -> int: """Add two numbers""" return a + b@mcp.tool()def multiply(a: int, b: int) -> int: """Multiply two numbers""" return a * bif __name__ == "__main__": # 以标准输入输出方式运行(便于集成) mcp.run(transport="stdio")
MCP的优势:
- 标准化:统一的工具协议
- 独立部署:工具服务与Agent解耦
- 热插拔:动态添加/移除工具不影响Agent运行
六、多模型支持:不绑定特定LLM
一个好的Agent架构应该支持多种LLM供应商:
# app/services/llm.py""" LLM service - 多供应商支持 """import structlogfrom langchain_openai import ChatOpenAIfrom langchain_anthropic import ChatAnthropicfrom app.core.config import settingslogger = structlog.get_logger(__name__)def get_llm(): """获取配置的LLM实例""" if settings.LLM_PROVIDER == "openai": logger.info("initializing_openai", model=settings.DEFAULT_LLM_MODEL) return ChatOpenAI( api_key=settings.OPENAI_API_KEY, model=settings.DEFAULT_LLM_MODEL, temperature=settings.DEFAULT_TEMPERATURE, ) elif settings.LLM_PROVIDER == "anthropic": logger.info("initializing_anthropic", model=settings.DEFAULT_LLM_MODEL) return ChatAnthropic( api_key=settings.ANTHROPIC_API_KEY, model=settings.DEFAULT_LLM_MODEL, temperature=settings.DEFAULT_TEMPERATURE, ) else: raise ValueError(f"Unsupported LLM provider: {settings.LLM_PROVIDER}")
设计哲学:通过抽象层隔离具体实现,未来添加新的LLM只需修改这个文件。
七、API端点:连接用户与Agent
最后,我们需要提供HTTP接口供用户调用:
7.1 路由定义
# app/api/v1/router.py""" Main API router """from fastapi import APIRouterfrom app.api.v1 import agentapi_router = APIRouter()api_router.include_router(agent.router, prefix="/agent", tags=["Agent"])
7.2 Agent端点实现
# app/api/v1/agent.py""" Agent API endpoints """import structlogfrom fastapi import APIRouter, HTTPExceptionfrom pydantic import BaseModel, Fieldfrom app.agents.graph import invoke_agentlogger = structlog.get_logger(__name__)router = APIRouter()# 请求模型(Pydantic验证)class AgentRequest(BaseModel): query: str = Field(..., min_length=1, description="用户查询") session_id: str | None = Field(None, description="会话ID(用于多轮对话)")# 响应模型class AgentResponse(BaseModel): response: str = Field(..., description="Agent回复") message_count: int = Field(..., description="总消息轮数") session_id: str | None = Field(None, description="会话ID")@router.post("/invoke", response_model=AgentResponse)asyncdef invoke_agent_endpoint(request: AgentRequest) -> AgentResponse: """调用Agent处理查询""" try: logger.info("agent_invoked", query=request.query) result = await invoke_agent(request.query, request.session_id) return AgentResponse(**result) except Exception as e: logger.error("agent_error", error=str(e)) raise HTTPException(status_code=500, detail=str(e))@router.get("/status")asyncdef agent_status(): """获取Agent状态""" from app.core.config import settings from app.agents.tools import get_tools tools = get_tools() return { "status": "operational", "llm_provider": settings.LLM_PROVIDER, "tool_count": len(tools), "available_tools": [tool.name for tool in tools], }
八、实战演示:看Agent如何工作
8.1 启动项目
uvicorn app.main:app --reload
8.2 测试Agent能力
场景1:简单计算
curl -X POST "http://localhost:8000/api/v1/agent/invoke" \ -H "Content-Type: application/json" \ -d '{"query": "计算一下 15 * (23 + 17) 等于多少?"}'
Agent的思考过程:
- 用户问数学问题 → 需要计算器工具
- LLM识别出需要调用
calculator("15*(23+17)") - 工具执行:
15 * (23 + 17) = 600 - LLM整理答案返回
场景2:复合任务
curl -X POST "http://localhost:8000/api/v1/agent/invoke" \ -H "Content-Type: application/json" \ -d '{"query": "现在几点了?然后告诉我这个时间加上2小时30分钟是什么时间?"}'
Agent的思考过程:
- 获取当前时间 → 调用
get_current_time() - 需要计算未来时间 → 需要数学计算
- 可能需要转换时间格式进行计算
- 整合所有信息给出完整回答
8.3 运行测试
项目包含完整的测试套件:
# tests/test_agent.py"""Agent API tests."""import pytest@pytest.mark.asyncioasyncdef test_agent_invoke(client): """测试Agent调用""" response = await client.post( "/api/v1/agent/invoke", json={"query": "What is 2+2?"} ) assert response.status_code == 200 data = response.json() assert"response"in data assert"message_count"in data@pytest.mark.asyncioasyncdef test_agent_status(client): """测试Agent状态端点""" response = await client.get("/api/v1/agent/status") assert response.status_code == 200 data = response.json() assert data["status"] == "operational"
运行测试:
pytest tests/ # 或 make test
九、生产级增强建议
这个Demo项目已经具备了核心架构,要用于生产环境还可以:
9.1 添加持久化存储
# 添加对话历史存储from langchain.memory import PostgresChatMessageHistoryasyncdef invoke_agent_with_memory(query: str, session_id: str): ifnot session_id: session_id = generate_session_id() # 从数据库加载历史 memory = PostgresChatMessageHistory( session_id=session_id, connection_string=settings.DATABASE_URL ) # 合并历史消息和当前查询 messages = memory.messages + [HumanMessage(content=query)] # ... 后续处理
9.2 添加速率限制
# 使用FastAPI中间件from slowapi import Limiter, _rate_limit_exceeded_handlerfrom slowapi.util import get_remote_addresslimiter = Limiter(key_func=get_remote_address)app.state.limiter = limiterapp.add_exception_handler(RateLimitExceeded, _rate_limit_exceeded_handler)@app.post("/invoke")@limiter.limit("10/minute") # 每分钟10次async def invoke_agent_endpoint(request: AgentRequest): # ...
9.3 添加监控和追踪
# LangSmith集成import osos.environ["LANGSMITH_API_KEY"] = settings.LANGSMITH_API_KEYos.environ["LANGSMITH_PROJECT"] = settings.LANGSMITH_PROJECTos.environ["LANGSMITH_TRACING"] = "true"
常见问题与调试技巧
Q1:代理陷入死循环怎么办?
# 在create_agent_graph中添加最大迭代限制def create_agent_graph(max_iterations: int = 10): workflow = StateGraph(AgentState) # ... 其他代码 ... # 添加迭代计数器 workflow.add_node("check_iterations", check_iteration_count) # 设置检查逻辑 def check_iteration_count(state: AgentState, iteration: int): if iteration >= max_iterations: return {"messages": [AIMessage( content="已达到最大思考次数,请简化您的问题" )]} return state
Q2:如何记录代理的思考过程?
# 添加详细的日志记录import loggingfrom langchain_core.callbacks import BaseCallbackHandlerclass AgentCallbackHandler(BaseCallbackHandler): """自定义回调处理器,记录每一步""" def on_llm_start(self, serialized, prompts, **kwargs): logging.info(f"LLM开始思考,输入: {prompts[0][:100]}...") def on_tool_start(self, serialized, input_str, **kwargs): logging.info(f"工具开始执行: {serialized['name']}, 输入: {input_str}") def on_tool_end(self, output, **kwargs): logging.info(f"工具执行完成,输出: {str(output)[:200]}...")# 在LLM初始化时添加llm = ChatOpenAI( model="gpt-4", temperature=0, callbacks=[AgentCallbackHandler()])
Q3:如何提高工具调用的准确性?
# 1. 提供更详细的工具描述@tooldef calculator(expression: str) -> str: """ 计算数学表达式。支持加减乘除(+ - * /)、括号、常用函数。 示例: - "2 + 3 * 4" 返回 "14" - "(2 + 3) * 4" 返回 "20" - "sqrt(16)" 返回 "4" 注意:表达式必须是纯数学表达式,不能包含文字。 """ pass# 2. 添加工具使用示例llm_with_tools = llm.bind_tools( tools, tool_choice="auto", # 让LLM自己决定是否使用工具 tool_examples=[ { "input": "计算25乘以4", "tool_call": {"name": "calculator", "args": {"expression": "25 * 4"}} } ])
写在最后
通过这个项目,我们看到了现代AI代理架构的核心要素:
- 状态化管理:代理需要记住对话历史
- 工具调用:代理需要“手和脚”来执行任务
- 条件循环:代理需要能够自主决定下一步
- 模块化设计:各层职责清晰,易于扩展
这个demo的价值不仅在于代码,更在于它展示了一种架构范式。你可以:
- 基于它快速搭建业务原型
- 学习LangGraph的状态管理
- 理解MCP协议的实际应用
- 构建真正能“执行任务”的AI系统
技术的魅力在于,今天的demo可能就是你明天产品的基石。这个项目的架构设计非常清晰,每个模块都有明确的职责,这正是生产级AI应用所需要的。
你在实际项目中遇到过哪些AI应用的痛点? 是工具调用的不准确,还是状态管理的复杂性?或者你有更好的代理架构设计思路?
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
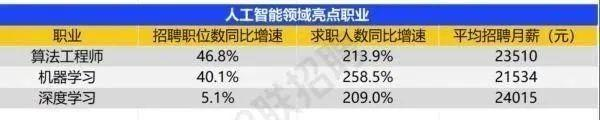
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 8
8 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)