具身智能学术之星|逐际动力 张巍团队2025工作盘点
在具身智能快速发展的浪潮中,中国科研人员正发挥着日益关键的作用。国内各大高校与实验室各有所长、各具特色——有的专注于感知技术,有的深耕端到端方案,也有的聚焦仿真平台与环境构建。
近期,不少计划申请硕博的同学向「具身智能之心」咨询,希望我们系统梳理国内具身智能领域的顶尖实验室,并介绍其核心研究方向。
为帮助大家更清晰地把握国内具身智能的学术格局,具身智能之心特别推出『学界之星』系列专题,带你走近那些默默推动行业进步的高校学者。无论你正在规划职业、确定研究方向,还是准备申请硕博深造,希望这些内容能为你提供有价值的参考。
今天要介绍的,是逐际动力创始人、南方科技大学长聘教授——张巍。

求学与创业历程中,张巍老师兼具顶尖学术积淀与前沿产业落地能力,是具身智能领域少有的兼具工程深度与产业视野的学者型创业者:本科毕业于中国科学技术大学自动化系,后于美国普渡大学电气与计算机工程系获博士学位。博士毕业后,他先后赴加州大学伯克利分校担任博士后研究员、斯坦福大学担任访问学者,奠定了扎实的国际化学术根基。
曾任职美国俄亥俄州立大学电气与计算机工程系并升任长聘副教授,2019 年回国任南方科技大学教授,深耕机器人领域科研与教学。2022 年,张巍老师创立逐际动力,率先发起对通用人形机器人的战略布局,成功搭建起学术研究与产业应用的深度融合桥梁。
作为全球足式人形机器人领域的早期核心领路人,张巍老师在技术研发上极具前瞻性:2018 年便发表全球首篇基于强化学习控制人形机器人的学术论文,技术探索早于行业主流;2021 年更实现全球首个端到端强化学习全尺寸人形机器人室外行走验证,为行业技术路线奠定重要理论与实践基础。
作为逐际动力创始人,他带领团队打造出LimX COSA具身智能体系统,构建了 “大小脑一体化” 的智能核心;推出全球首款多形态双足机器人TRON 1、高性价比全尺寸通用人形机器人LimX Oli及多构型切换机器人 TRON 2,产品已销往全球 80 余个国家和地区,成为具身智能产业化落地的标杆成果。
学术与行业贡献上,张巍老师成果斐然,认可度颇高:他长期深耕机器人运动控制、强化学习与具身智能方向,曾出任 IEEE Transactions on Control System Technology 等顶级期刊副主编,为领域学术发展搭建专业平台。其个人先后斩获美国国家科学基金职业奖(NSF CAREER Award)、国家特聘专家(青年)、36 氪科创家、福布斯青年海归菁英等多项重磅荣誉,学术与产业能力均获国内外高度认可。
如果你对足式人形机器人运动控制、具身智能大小脑融合、机器人通用基座设计及具身智能产业化落地感兴趣,张巍老师的研究与实践工作无疑是一个值得重点追踪的窗口。
更多细节,欢迎大家访问他的主页:https://faculty.sustech.edu.cn/?tagid=zhangw3&go=2。
本文将着重介绍张巍老师在2025 年至今的一些已发表至顶会的研究成果。
[RSS 2025] Debiasing 6-DOF IMU via Hierarchical Learning of Continuous Bias Dynamics
提出机构:南方科技大学、密歇根大学
论文链接:https://arxiv.org/abs/2504.09495v2
项目主页:https://github.com/UMich-CURLY/Debias_IMU.git
研究背景:惯性测量单元(IMU)是机器人状态估计的核心传感器,为视觉-惯性里程计(VIO)等系统提供角速度和加速度测量,但低成本 IMU 存在显著的噪声和时变偏差,受温度、振动等因素影响,直接导致姿态、速度和位置估计误差累积,严重影响机器人导航和操作性能。现有 IMU 去偏方法存在局限:模型基方法采用线性模型或布朗运动建模偏差,难以捕捉复杂非线性动态;数据驱动方法或隐式学习修正项,易受运动模式干扰,泛化性差;显式建模偏差演化的方法则依赖难以获取的偏差真值数据,需通过多传感器融合估计,准确性受融合算法影响。如何在无需偏差真值的情况下,显式建模偏差的连续动力学,实现高效鲁棒的 IMU 去偏,成为提升机器人状态估计精度的关键。
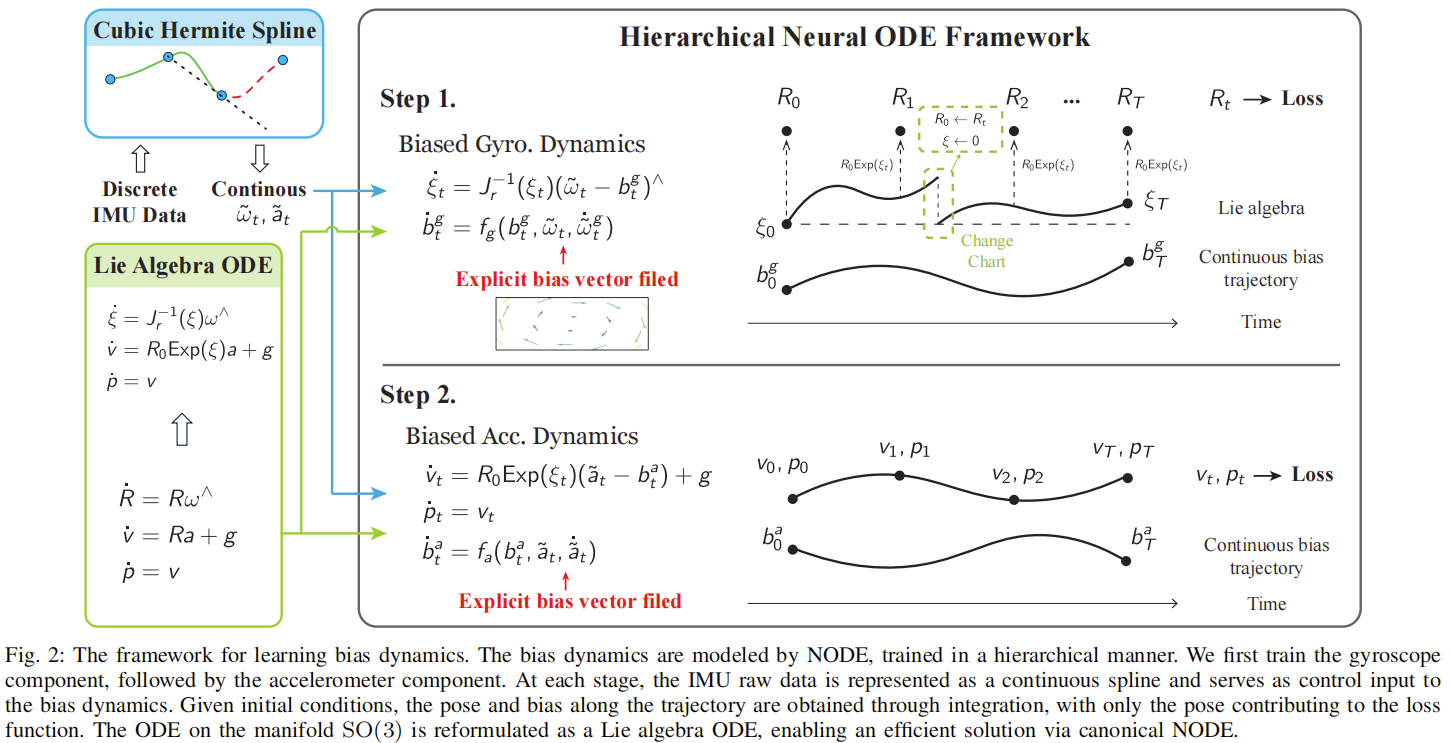
论文内容:为解决上述问题,本文提出一种基于神经常微分方程(NODE)的 IMU 去偏框架,通过分层学习偏差的连续动力学,仅需姿态真值即可实现 6 自由度 IMU(陀螺仪 + 加速度计)去偏。首先,建立 IMU 测量模型,将偏差建模为确定性非线性动态,而非传统的布朗运动,陀螺仪和加速度计偏差的导数由神经网络建模,输入包含原始 IMU 测量值及其导数,确保模型捕捉偏差与测量的依赖关系;其次,采用 NODE 框架实现偏差动力学建模,将离散 IMU 测量通过三次埃尔米特样条插值为连续控制输入,扩展状态包含时间和偏差,通过 ODE 求解器积分得到任意时刻的偏差估计,无需显式存储历史数据;再者,设计分层训练策略,利用 IMU 运动学中 “姿态与速度 / 位置解耦” 的特性,先训练陀螺仪偏差模型(仅优化姿态损失),再固定其参数训练加速度计偏差模型(优化速度和位置损失),降低训练复杂度;最后,通过李代数转换解决 SO (3) 流形上的 ODE 求解问题,将旋转动力学转换为欧氏空间中的 ξ 变量演化,避免流形优化的复杂性。
主要创新点:
- 提出无需偏差真值的损失构造方法,通过姿态、速度和位置的真值直接优化偏差动力学模型,规避了偏差真值难以获取的难题,降低了数据收集门槛;
- 将偏差动力学建模为 NODE 框架下的向量场,通过连续插值和 ODE 积分实现偏差的实时估计,模型轻量化且物理意义明确,优于传统离散时序模型;
- 设计分层训练策略,利用 IMU 运动学特性分离陀螺仪和加速度计的训练过程,提升了训练稳定性和收敛速度;
- 通过李代数转换解决了 SO (3) 流形上的 ODE 求解问题,确保了旋转动力学建模的准确性,为姿态估计精度提供了保障。
关键实验结果:EUROC 数据集上,纯 IMU 积分的绝对姿态误差(AOE)降至 2.40°,较原始 IMU 的 120.78° 和线性模型的 4.22° 显著降低,相对姿态误差(ROE)0.71°,优于 M.B. 方法的 0.89°;TUM-VI 数据集上,AOE 平均为 1.79°,远低于线性模型的 9.19° 和 M.B. 方法的 17.53°,VIO 系统集成去偏 IMU 后,绝对位置误差(APE)降至 0.17m,较原始 IMU 提升 60% 以上;真实世界 FETCH 数据集上,纯 IMU 积分的 AOE 为 1.96°,APE 为 132.57m,优于线性模型和 M.B. 方法,验证了泛化能力;消融实验表明,分层训练使收敛速度提升 40%,李代数转换使姿态估计误差降低 35%,积分长度 N=16 时性能最优,平衡了精度与计算成本;计算效率方面,在 RTX4060 GPU 上每迭代训练时间约 573 秒,推理时可满足 200Hz IMU 数据处理需求,适用于实时状态估计系统。
[CoRL 2025] Multi-Loco: Unifying Multi-Embodiment Legged Locomotion via Reinforcement Learning Augmented Diffusion
提出机构:南方科技大学、圣母大学、浙江大学-伊利诺伊大学厄巴纳-香槟分校联合学院、LimX Dynamics
论文链接:https://arxiv.org/abs/2506.11470v1
项目主页:https://multi-loco.github.io
研究背景:腿式机器人的形态多样性(如双足、四足、人形、轮式双足)导致 locomotion 策略难以泛化,现有强化学习方法通常针对特定形态单独训练,不仅需要重复投入大量计算资源,还无法复用不同形态间的共性 locomotion 知识,造成策略和数据集的 “孤岛效应”。跨形态学习在机器人操作任务中已取得一定突破,但 locomotion 任务受机器人动力学特性和环境物理交互的影响更为显著,且不同形态机器人的观测 / 动作维度差异巨大,难以抽象出统一的特征表示,导致跨形态泛化面临独特挑战。现有跨形态 locomotion 方法或依赖显式形态描述符,或局限于固定自由度机器人, scalability 和灵活性不足,亟需一种无需形态特异性输入、能自适应不同观测 / 动作空间的统一框架。
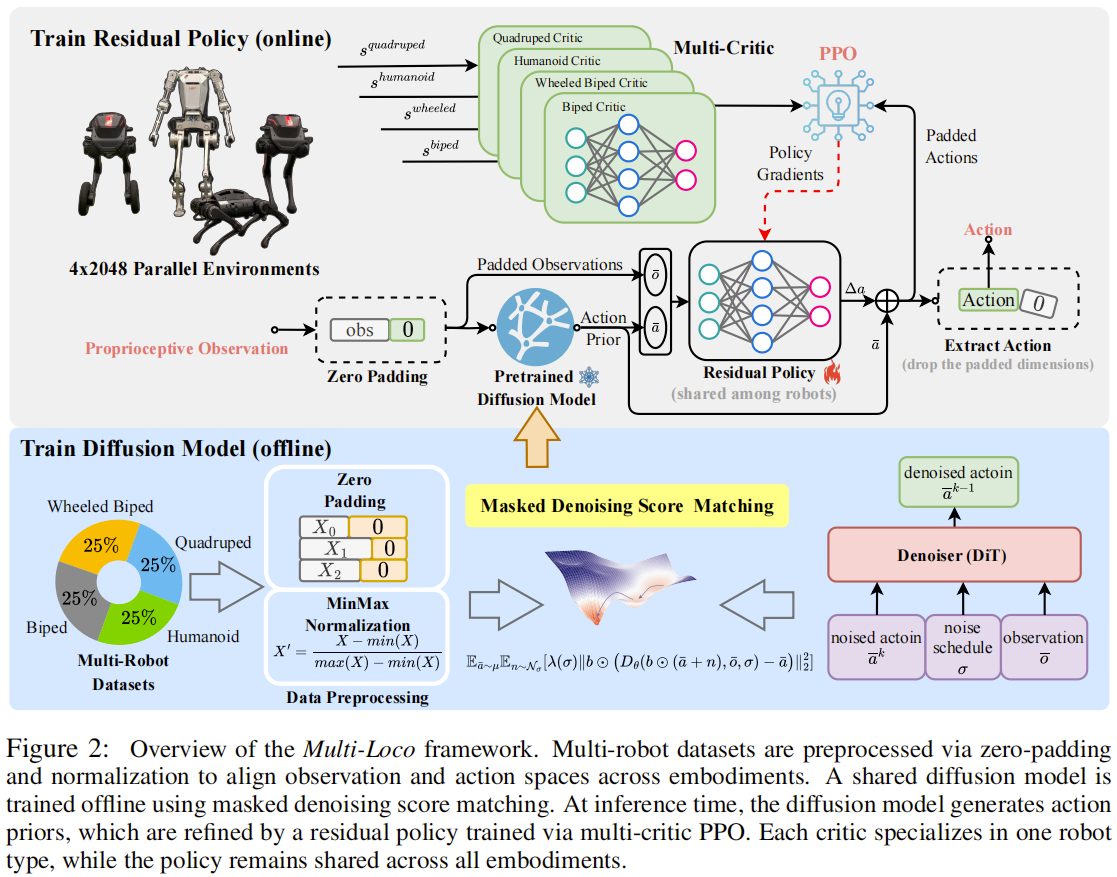
论文内容:为实现多形态腿式机器人的统一 locomotion 控制,本文提出 Multi-Loco 框架,整合形态无关的生成扩散模型与强化学习优化的共享残差策略。首先,通过零填充技术对齐不同形态机器人的观测和动作空间,将所有机器人的观测 / 动作向量填充至最大维度,同时引入二进制掩码标记有效维度,结合分位数归一化将特征映射至 [-1,1] 范围,确保数据分布一致性;其次,采用 Elucidated Diffusion Model(EDM)作为生成模型,以轻量级扩散 Transformer(DiT)为骨干网络,通过掩码去噪分数匹配训练,仅关注有效动作维度,捕捉跨形态的通用 locomotion 模式,实现快速推理(5 步采样即可生成动作先验);再者,设计共享残差策略,以扩散模型生成的动作先验为基础,预测动作修正量,采用多评论家 PPO 框架训练,为每种机器人形态配备专用评论家,共享演员网络参数,通过任务特定奖励、形态感知正则化项和残差惩罚项引导学习;最后,在四种代表性机器人(点足双足、轮式双足、人形、四足)上进行模拟和真实实验,验证框架的跨形态泛化能力和 sim-to-real 迁移性能。
主要创新点:
- 提出零填充 + 掩码去噪的统一表示方案,无需显式形态信息即可处理不同机器人的观测 / 动作维度差异,为跨形态策略学习提供了灵活的输入接口;
- 构建扩散模型与残差 RL 结合的混合架构,扩散模型捕捉通用 locomotion 先验,残差策略适配形态特异性动力学和实时环境反馈,兼顾泛化性与任务性能;
- 设计多评论家 PPO 训练机制,通过专用评论家解决不同形态的优化目标冲突,共享演员网络确保知识复用,避免形态特异性网络设计带来的 scalability 问题;
- 实现了真正意义上的 “一策多用”,无需针对新形态重新训练或大幅微调,仅需调整掩码即可适配,为大规模多机器人系统控制提供了高效解决方案。
关键实验结果:模拟实验中,相比形态特异性 PPO 基线,Multi-Loco(CR-DP+RA)平均回报提升 10.35%,其中轮式双足任务提升 13.57%,人形任务提升 10.97%;跨形态数据训练的 CR-DP 相比单形态训练的 SR-DP,平均性能提升 17.96%,在四足和人形机器人上提升尤为显著(分别为 20.47% 和 26.02%);真实世界部署中,统一策略成功控制四种机器人在草地、斜坡、楼梯、碎石等地形稳定 locomotion,实时控制频率达 50Hz;零-shot 迁移至未训练过的 Unitree Go2 机器人时,Mean Episode Length 和速度跟踪奖励与训练过的四足机器人差异小于 3.2%,验证了强大的泛化能力;消融实验表明,扩散模型先验和残差策略的结合是性能提升的关键,掩码机制有效避免了无效维度的干扰。
[CoRL 2025] Generative Visual Foresight Meets Task-Agnostic Pose Estimation in Robotic Table-Top Manipulation
提出机构:南方科技大学、LimX Dynamics、香港大学
论文链接:https://arxiv.org/abs/2509.00361v1
项目主页:https://clearlab-sustech.github.io/gvf-tape/
研究背景:非结构化环境中的机器人桌面操作需要系统具备跨任务泛化能力和实时响应性,但现有方法存在显著局限:依赖动作标签的视频预训练方法需大量人工标注演示,扩展性差;无动作标签方法或依赖复杂的逆动力学建模,或需要目标条件探索,存在数据收集效率低、真实部署安全性不足等问题;视觉预见方法虽能预测未来状态,但大多依赖任务特定动作映射,难以适配多样化操作任务。此外,现有方法往往需要专用硬件(如立体相机、机器人 CAD 模型)或复杂校准流程,实用性受限。如何构建一种无需动作标签、任务无关、部署简便的闭环操作框架,成为机器人桌面操作泛化的核心挑战。
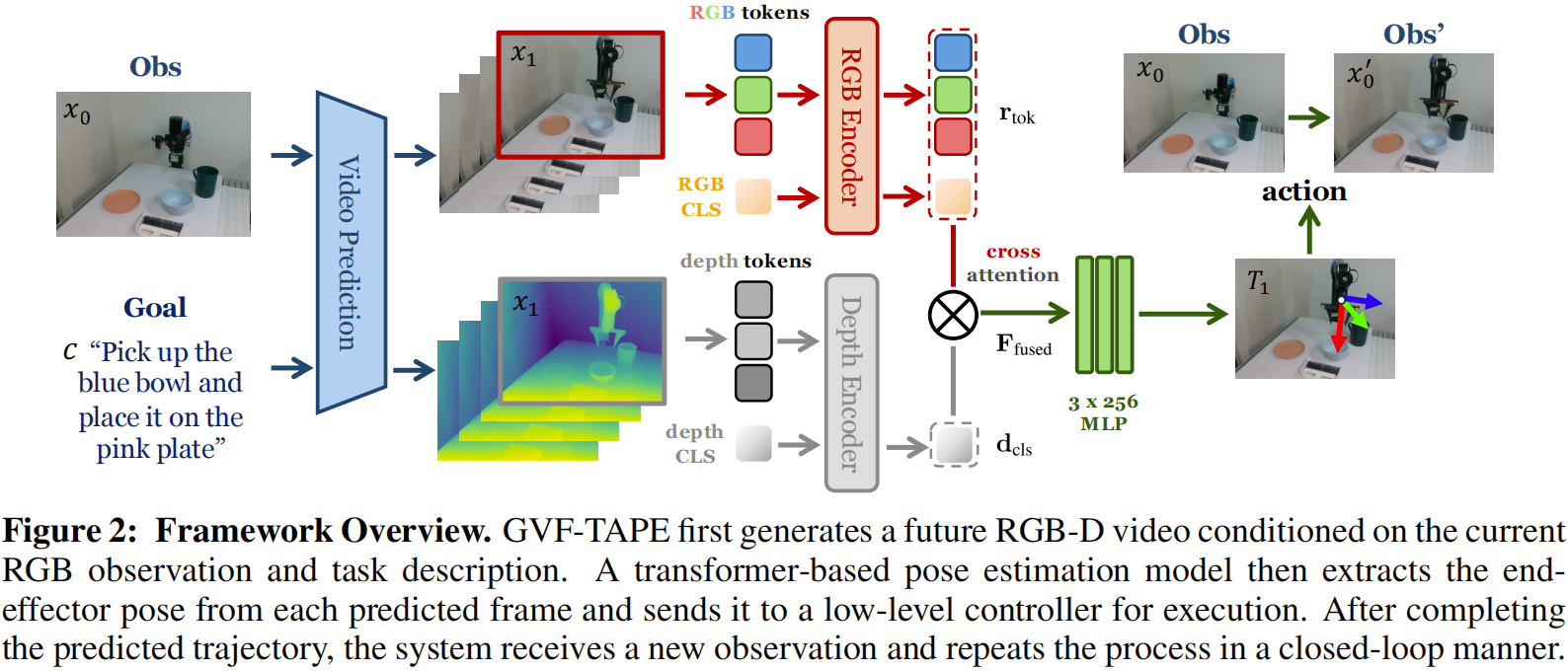
论文内容:为解决上述问题,本文提出 GVF-TAPE 框架,将生成视觉预见与任务无关姿态估计 decoupled,实现端到端的机器人桌面操作。框架分为两大核心模块:一是文本条件视觉预见模块,采用整流流(rectified flow)作为生成模型,以 3D U-Net 为骨干网络,结合 CLIP 文本编码器处理任务描述,基于单张侧视 RGB 图像预测未来 RGB-D 序列(6 帧),无需显式深度输入,可利用 Video Depth Anything 模型生成深度图,支持大规模 RGB 数据集预训练;二是任务无关姿态估计模块,采用双 ViT-Base 编码器分别处理 RGB 和深度图像,通过多头部交叉注意力机制融合特征(以深度 CLS token 为查询,RGB 补丁 token 为键值),输出末端执行器的 6-DoF 姿态(3D 位置、四元数姿态、夹爪状态),模型仅通过随机探索数据训练,无需专家演示,采样末端执行器姿态并由控制器驱动机器人移动,自动收集 400k+ RGBD / 姿态对。框架采用闭环执行模式:基于当前观测和任务描述生成未来视觉序列,提取姿态轨迹并由低级别控制器执行,完成后获取新观测重复流程,实现实时自适应操作。
主要创新点:
- 提出 “视觉预见 + 姿态提取” 的 decoupled 框架,首次实现无需动作标签的闭环机器人操作,通过生成模型预测视觉规划,姿态估计模型转换为可执行动作,规避了复杂的逆动力学建模;
- 设计任务无关的姿态估计方案,仅依赖随机探索数据训练,无需专家标注或机器人 CAD 模型,降低了数据收集成本,提升了跨机器人的适配性;
- 采用整流流实现高效 RGB-D 预测,仅需 3 步即可生成高质量未来帧,推理速度远超扩散模型,满足实时操作需求;
- 融合文本条件与多模态视觉特征,通过 CLIP 编码任务描述,增强了框架对自然语言指令的理解能力,支持多样化操作任务。
关键实验结果:LIBERO 基准测试中,GVF-TAPE 在 LIBERO-Spatial 和 LIBERO-Object 套件上的成功率分别达 95.50% 和 86.70%,较依赖动作标签的 SOTA 方法(如 ATM)分别提升 27.00% 和 18.70%,整体平均成功率 83.00%,超越所有基线 11.56%;8 个 LIBERO-100 生活场景任务中,平均成功率 79.4%,较次优方法 V2A 提升 26.9%;数据效率实验中,仅用 20% 任务数据(每任务 10 个演示)即可达到 68% 成功率,预训练后提升至 77%,超越 ATM 5.43%;真实世界实验中,5 个操作任务(含刚性、可变形物体)平均成功率 56%,经人类操作视频预训练后提升至 86%,其中 “碗放微波炉”“碗放盘子” 任务成功率达 100%;消融实验验证,整流流较扩散模型推理速度提升 3 倍以上,深度信息融合使整体性能提升 6.78%,跨注意力融合架构优于 ResNet50 和单一 ViT 编码器。
[Humanoids 2025] LIPM-Guided Reinforcement Learning for Stable and Perceptive Locomotion in Bipedal Robots
提出机构:南方科技大学、香港科技大学、香港大学、浙江大学-伊利诺伊大学厄巴纳-香槟分校联合学院、LimX Dynamics
论文链接:https://arxiv.org/abs/2509.09106v2
研究背景:双足机器人凭借类人形态和运动模式,在人机交互、复杂环境作业等场景中具有独特优势,受到机器人领域的广泛关注。然而,与四足机器人相比,双足机器人存在固有的欠驱动动力学特性,且地面接触点少,导致稳定 locomotion 控制面临更大挑战。近年来,强化学习已在腿式机器人 locomotion 领域取得显著进展,实现了不平坦地形行走、视觉感知导航等功能,但这些成果大多局限于结构化的实验室环境。当机器人部署到户外非结构化环境时,会遭遇外感受传感器噪声、地面滑动、意外地形突变等问题,现有方法往往因过度优先速度跟踪而牺牲稳定性,难以实现可靠的感知 locomotion。线性倒立摆模型(LIPM)为双足机器人动态平衡提供了坚实的理论基础,但其简化假设与真实环境的复杂性存在差距,如何将其理论 insights 有效融入强化学习框架,平衡速度跟踪与稳定性,成为实现户外稳定 locomotion 的关键。
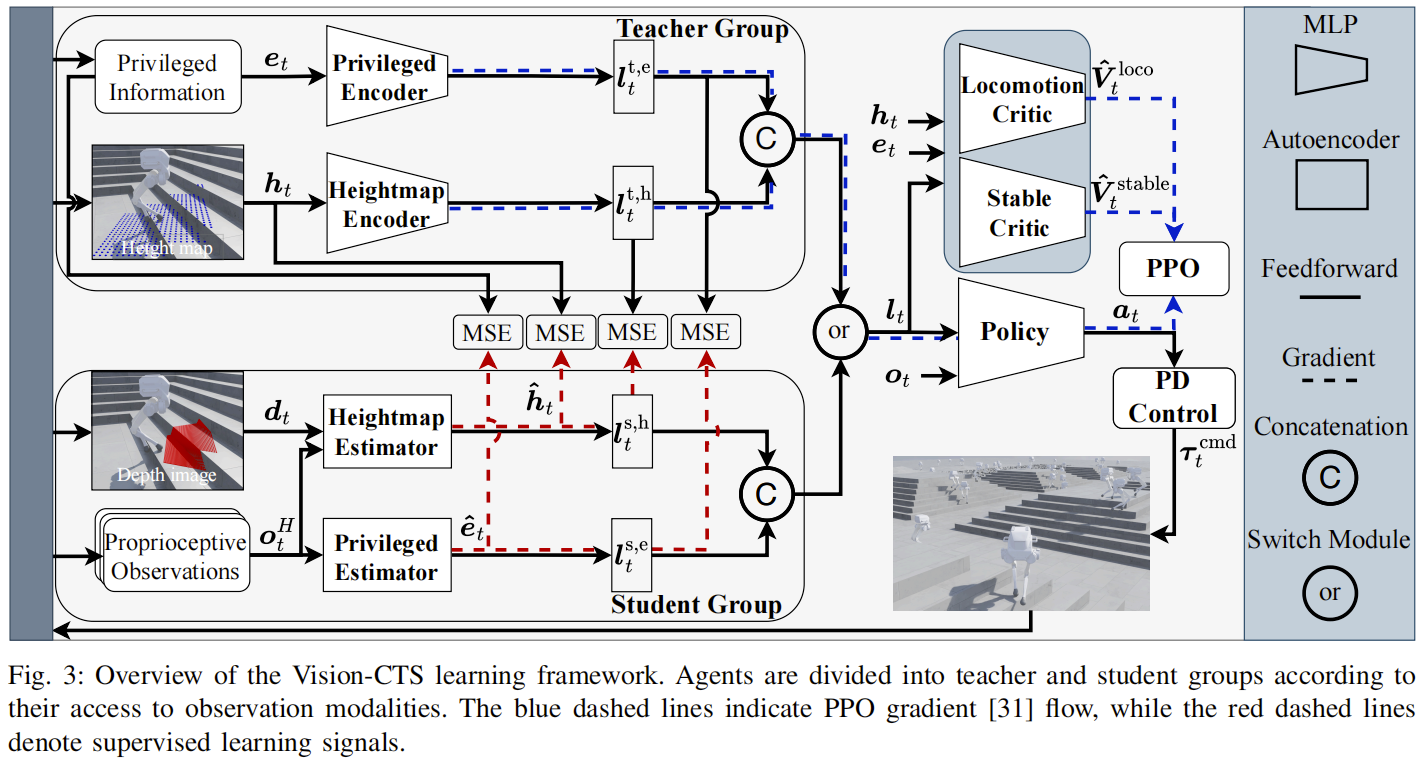
论文内容:为解决上述问题,本文提出一种基于 LIPM 引导的强化学习方法,结合视觉并发师生(Vision-CTS)学习框架,实现点足双足机器人的稳定感知 locomotion。首先,设计 LIPM 启发的稳定奖励函数,通过约束质心(CoM)运动约束平面的截距与机器人直立高度一致,同时强制执行质心周围零角动量假设,最小化 CoM 跟踪误差、截距误差及滚转 / 俯仰角速度,保障动态平衡;其次,基于奖励融合模块(RFM)提出稳定性感知速度跟踪机制,将稳定奖励与速度跟踪奖励进行非线性融合,确保稳定性优先于速度跟踪,当机器人稳定性不足时自动减速或停止调整;再者,将速度跟踪解耦为方向跟踪(采用余弦相似度度量)和幅值跟踪(采用ℓ2 范数差异度量),避免低稳定性下速度跟踪性能退化;最后,采用双评论家架构,分别评估稳定性奖励和 locomotion 奖励的期望回报,提升训练效率和鲁棒性。训练在 IsaacLab 环境中进行,采用 2048 个并行环境和领域随机化技术,部署于 LimX Dynamic TRON1 机器人,通过前端 Intel RealSense D435i 相机获取深度图像,实现 50Hz 的实时控制。
主要创新点:
- 首次将 LIPM 理论与强化学习深度融合,设计了兼顾动态平衡与地形适应性的稳定奖励函数,将抽象的平衡准则转化为可优化的奖励信号,为双足机器人户外 locomotion 提供理论引导;
- 提出基于 RFM 的优先级融合机制和 decoupled 速度跟踪策略,解决了传统加权求和奖励中稳定性与速度跟踪的冲突问题,实现 “稳定优先、灵活跟踪” 的 locomotion 模式;
- 采用双评论家架构分离稳定性与 locomotion 目标的价值评估,避免单一评论家因目标冲突导致的训练低效,提升了政策学习的针对性和鲁棒性;
- 扩展 Vision-CTS 框架融入视觉感知输入,通过特权估计器和高度图估计器实现多模态信息融合,增强了机器人对复杂户外地形的感知能力。
关键实验结果:模拟实验中,在楼梯、斜坡、离散障碍和粗糙地形四种场景下,该方法的成功率均高于去除稳定奖励、去除稳定评论家及去除 RFM 的消融版本,其中楼梯场景成功率达 80.30%,显著优于无稳定奖励版本的 41.43%;方向误差、角速度误差和高度图重建误差均低于基线,展现出更优的动态平衡和地形感知能力;不同速度指令下,在重力主导地形(如楼梯、斜坡)中成功率优势尤为明显,极端扰动实验中生存概率最高;真实世界实验中,机器人成功遍历草地、斜坡、碎石、台阶等多种户外地形,面对落叶打滑、地形边界感知干扰等突发情况时能快速调整姿态维持稳定,平均任务成功率达 85% 以上。
[ICLR 2026] PolicyFlow: Policy Optimization with Continuous Normalizing Flow in Reinforcement Learning
提出机构:香港科技大学、南方科技大学、浙江大学-伊利诺伊大学厄巴纳-香槟分校联合学院、LimX Dynamics
论文链接:https://arxiv.org/abs/2602.01156v1
项目主页:https://policyflow2026.github.io/
研究背景:在强化学习领域,策略梯度方法已在机器人控制、大语言模型对齐等复杂序贯决策任务中取得显著成功,其中近端策略优化(PPO)凭借简洁性、数值稳定性和优异的实证性能,成为行业标准,广泛应用于复杂机器人控制和生成式策略微调。然而,标准 PPO 依赖基于重要性比率的替代目标,这要求对策略似然进行评估,而现有 PPO 通常采用高斯分布建模策略,虽计算简便,但难以表示复杂、多模态或高度倾斜的动作分布,限制了其在更复杂场景中的应用。近年来,连续归一化流(CNF,又称流匹配模型)等生成模型展现出捕捉复杂多模态分布的强大能力,已成功应用于模仿学习等领域,但这类模型计算重要性比率或似然时,需进行迭代 ODE/SDE 模拟和路径反向传播,不仅计算成本高昂,还容易出现梯度爆炸或消失问题,导致直接应用于 PPO 风格更新时,训练速度慢、内存消耗大且稳定性差,严重限制了其在高效在线强化学习中的实用性。
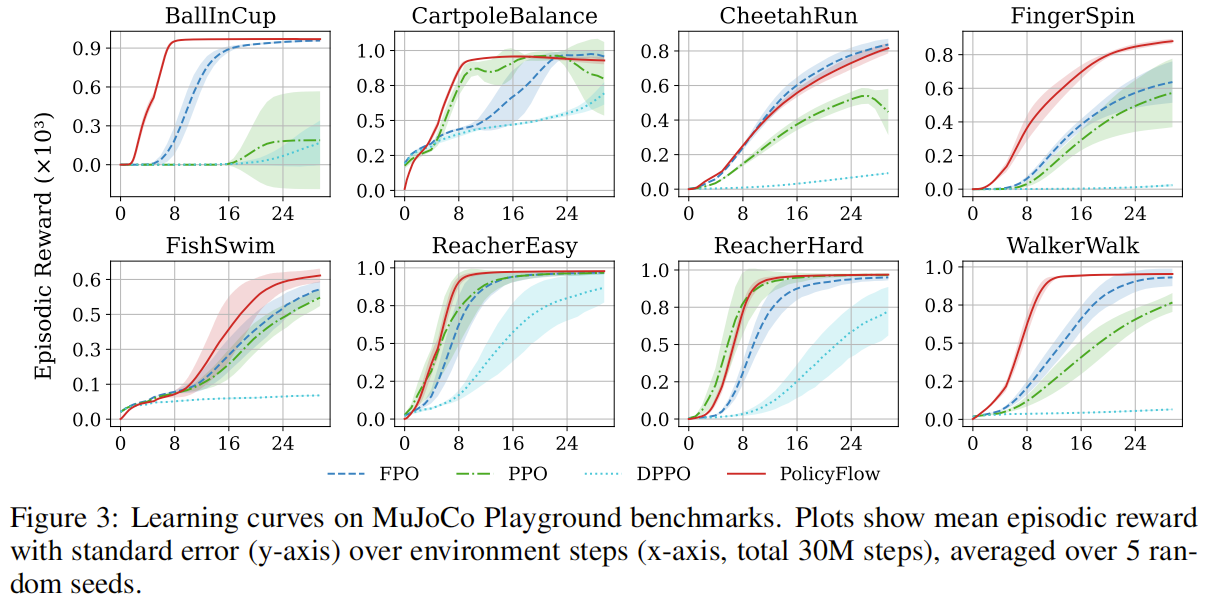
论文内容:为解决上述挑战,本文提出 PolicyFlow,一种新型在线强化学习算法,将连续归一化流的表达能力与 PPO 风格的裁剪目标相结合,实现高效稳定的策略优化。算法核心设计包括两部分:一是 CNF 策略的重要性比率近似方法,通过评估插值路径上 CNF 速度场的变化来近似重要性比率,避免了昂贵的路径反向传播,在不影响训练稳定性的前提下降低了计算开销;二是布朗熵正则化器,受布朗运动启发,提出一种轻量级熵正则化器,无需显式计算 CNF 策略的熵,即可促进熵的单调增长,有效缓解模式崩溃问题,鼓励多样化的动作行为。为验证算法性能,研究团队在 MultiGoal、PointMaze、IsaacLab 和 MuJoCo Playground 等多种环境的不同任务中进行了全面实验,对比了采用高斯策略的 PPO 以及 FPO、DPPO 等基于流的基线方法。实验结果表明,PolicyFlow 在多数任务中取得了具有竞争力或更优的性能,尤其在 MultiGoal 任务中,充分展现了其捕捉丰富多模态动作分布的能力,能够实现更均衡的目标达成行为。
主要创新点:
- 提出了一种针对 CNF 策略的重要性比率近似方案,通过插值路径上的速度场变化替代完整流路径的似然评估,既保持了 PPO 的训练稳定性,又将计算效率维持在与高斯策略 PPO 相当的水平,解决了生成模型在 PPO 中应用的计算瓶颈;
- 设计了布朗正则化器这一隐式熵正则化机制,区别于传统显式计算熵或启发式注入噪声的方法,该正则化器直接通过塑造速度场引导熵增长,原理简洁且计算轻量化,有效解决了流基策略熵正则化困难的问题;
- 在多环境、多任务的全面实验验证中,PolicyFlow 展现出优于现有基线的泛化能力和性能表现,尤其在多模态动作分布建模上的优势显著,为强化学习与生成模型的融合提供了兼具实用性和表达力的统一框架;
- 理论分析证明,插值路径近似带来的误差为一阶,且可通过 PPO 的裁剪机制自然限制,为算法的稳定性提供了坚实的理论支撑。
关键实验结果:在 MultiGoal 任务中,PolicyFlow 结合布朗正则化器实现了对所有 6 个目标的均衡覆盖,成功率和目标多样性显著优于仅用高斯熵正则化的版本及 FPO、DPPO 等基线;MuJoCo Playground 环境中,其收敛速度更快、样本效率更高,多数任务性能超越 FPO 和 DPPO,与 PPO 持平或更优;IsaacLab 机器人基准测试中,所有任务的渐近性能均匹配或超越 PPO,且在 Navigation 等任务中统计显著优于基线;计算效率方面,PolicyFlow 每迭代训练时间仅比 PPO 增加不到 50%,即使嵌入维度提升 8 倍,计算成本仍控制在 PPO 的 2 倍以内,验证了其实际部署可行性。
写在最后
若想深入了解更多研究细节或加入团队,欢迎访问张巍教授个人主页(https://faculty.sustech.edu.cn/?tagid=zhangw3&go=2)及相关项目主页,持续追踪团队的最新动态。
回望 2025 年至今的科研征程,张巍教授团队以 “学术深耕 + 产业落地” 双轮驱动,交出了一份兼具理论深度与实践价值的答卷。从 IMU 传感器去偏的底层技术突破,到多形态机器人的统一 locomotion 框架构建,再到机器人桌面操作的无标签泛化方案,以及强化学习与生成模型融合的策略优化创新,团队的研究覆盖了具身智能从感知、决策到控制的完整链路,既聚焦核心技术瓶颈,又紧扣产业实际需求。
这些成果的背后,是团队 “理论创新与工程实践并重” 的鲜明特色:每一项算法突破都经过仿真与真实场景的双重验证,既在 RSS、CoRL、ICLR 等顶会展现学术影响力,又能快速落地到逐际动力的机器人产品中,形成 “科研反哺产业、产业滋养科研” 的良性循环。这种 “从实验室到市场” 的闭环能力,正是具身智能领域最稀缺的核心竞争力。
对于正在关注具身智能领域的学习者、科研爱好者,以及计划申请硕博深造的同学而言,张巍教授团队的研究方向兼具前沿性与实用性——**无论是足式机器人运动控制、多模态感知融合,还是强化学习与生成模型的跨领域应用,**都是当前行业的核心赛道。而团队依托南方科技大学 CLEAR 实验室的完备平台(自研双足 / 四足机器人、机械臂等)与逐际动力的产业资源,更能为研究者提供 “将想法变为现实” 的绝佳土壤。在具身智能从技术探索走向规模化应用的关键阶段,相信这样一支兼具学术高度与产业视野的团队,未来还将持续产出更多引领行业发展的突破性成果,为全球通用人形机器人的进步注入中国力量。
重磅!
VLA+RL方向首个系统教程来啦!Online RL/Offline RL/test time RL等~
推荐阅读
我们用低成本的机械臂完成pi0/pi0.5/GR00T/世界模型等VLA任务~
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)