必学干货!用LangGraph为AI助手添加知识库+长期记忆,小白也能学会,建议收藏!
你的AI助手总是“一问三不知”?今天,我们要给它装上知识库和长期记忆,让它真正成为你的得力伙伴!
你是否遇到过这样的尴尬场景:
- 向AI询问公司内部文档的内容,它却回答“我不知道”?
- 与AI进行多轮对话后重启程序,之前的对话历史全部丢失?
- 每次都要向AI重复背景信息,感觉像是在跟金鱼聊天?
如果你也有这些烦恼,那么今天这篇文章就是为你准备的!我们将基于LangGraph,为智能体添加两大核心能力:**检索增强生成(RAG)**和 长期记忆。学完本文,你的AI助手将能够:
- 从指定文档中查找答案,不再局限于预训练知识
- 记住跨会话的对话历史,实现真正的连续对话
推荐阅读:
使用 LangGraph 构建 AI Agent:基本聊天机器人
一、什么是RAG与长期记忆?
在深入代码之前,让我们快速理解这两个核心概念:
RAG(检索增强生成)
想象一下,你有一个超级聪明的助手,但它的知识只停留在某个时间点。RAG就像给了它一个智能书架:当用户提问时,助手先快速浏览书架上的相关书籍(检索),然后结合自己的知识回答问题(生成)。
传统AI的局限性:
# 传统方式:只依赖预训练知识user_question = "我们公司最新的报销政策是什么?"# AI: "抱歉,我不知道你们公司的具体政策..."
RAG的优势:
# RAG方式:结合文档知识user_question = "我们公司最新的报销政策是什么?"# 1. 从公司文档库中检索相关政策文档# 2. 基于检索到的文档生成答案# AI: "根据2024年3月发布的《费用报销管理办法》第5条..."
长期记忆
如果说短期记忆是对话中记住上下文,那么长期记忆就是记住不同会话间的对话历史。这就像给AI装了一个“记忆宫殿”,让它能记住昨天、上周甚至上个月的对话内容。
二、为LangGraph智能体添加RAG能力
让我们一步步构建一个能理解特定文档的智能助手。我们将以React Native ExecuTorch文档为例,让AI学会回答相关技术问题。
步骤1:加载和分割文档
首先,我们需要获取文档内容并将其分割成适合处理的“知识块”:
from langchain_community.document_loaders import WebBaseLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitter# 1. 加载文档 - 这里以React Native ExecuTorch文档为例loader = WebBaseLoader("https://docs.swmansion.com/react-native-executorch/")docs = loader.load()print(f"加载了 {len(docs)} 个文档,总字符数:{len(docs[0].page_content)}")# 2. 分割文档 - 就像把长文章切成便于查找的小卡片text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, # 每个块约1000字符 chunk_overlap=200 # 块之间重叠200字符,避免信息割裂)all_splits = text_splitter.split_documents(docs)print(f"分割成 {len(all_splits)} 个文本块")
关键点解释:
chunk_size=1000:每个文本块约1000字符,既不会太碎片化,也不会太冗长chunk_overlap=200:相邻块重叠200字符,确保相关信息不会因为恰好跨块而被割裂
步骤2:创建向量数据库
现在我们需要一个能快速查找相关文本的“书架”:
from langchain_core.vectorstores import InMemoryVectorStorefrom langchain_huggingface import HuggingFaceEmbeddings# 1. 选择嵌入模型 - 这相当于文档的"指纹生成器"# all-MiniLM-L6-v2是一个轻量级但效果不错的模型embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L6-v2")# 2. 创建向量存储 - 我们的"智能书架"vector_store = InMemoryVectorStore(embeddings)# 3. 将文本块添加到书架_ = vector_store.add_documents(documents=all_splits)print("向量数据库准备就绪!")
什么是嵌入(Embedding)?简单来说,嵌入就是将文本转换成数学向量的过程。相似的文本会有相似的向量表示,这样我们就能通过数学计算找到语义上相关的文档。
步骤3:改造提问函数,集成RAG
现在让我们的智能体学会先查资料再回答:
from langchain_core.messages import HumanMessage, AIMessagedef ask_llm_with_rag(state): """增强版提问函数:先检索,后生成""" user_query = input("请输入您的问题: ") # 1. 检索相关文档 - 从书架上找到最相关的卡片 retrieved_docs = vector_store.similarity_search(user_query, k=3) print(f"检索到 {len(retrieved_docs)} 个相关文档片段") # 2. 构建上下文 context = "\n\n---\n\n".join([doc.page_content for doc in retrieved_docs]) # 3. 构建增强提示 user_message = HumanMessage( f"""请基于以下上下文回答问题。如果上下文不包含相关信息,请诚实地说不知道。上下文:{context}用户问题:{user_query}请提供准确、有用的回答:""" ) # 4. 调用模型生成回答 answer_message = model.invoke( state["messages"] + [user_message] ) # 5. 打印并保存结果 print(f"\n🤖 AI回答: {answer_message.content}\n") return { "messages": [user_message, answer_message], }# 小练习:尝试添加一个中间步骤,让AI先根据查询和上下文生成优化的提示,再回答
步骤4:完整代码示例
让我们看看完整的RAG集成代码:
# 完整代码:带RAG的LangGraph智能体from typing import TypedDict, Listfrom langchain_core.messages import BaseMessagefrom langgraph.graph import StateGraph, ENDfrom langchain_openai import ChatOpenAIimport os# 设置OpenAI API密钥(请替换为你的密钥)os.environ["OPENAI_API_KEY"] = "your-api-key-here"# 定义状态结构class State(TypedDict): messages: List[BaseMessage] iteration: int# 初始化模型model = ChatOpenAI(model="gpt-3.5-turbo")# 构建图graph_builder = StateGraph(State)# 添加节点graph_builder.add_node("ask", ask_llm_with_rag)# 设置入口点graph_builder.set_entry_point("ask")graph_builder.add_edge("ask", END)# 编译图graph = graph_builder.compile()# 测试RAG功能initial_state = {"messages": [], "iteration": 0}result = graph.invoke(initial_state)print("=" * 50)print("测试问题1: React Native ExecuTorch是什么?")print("=" * 50)
实际运行效果:
请输入您的问题: React Native ExecuTorch是什么?检索到 3 个相关文档片段🤖 AI回答: React Native ExecuTorch是一个为React Native生态系统量身定制的设备端AI和大语言模型工具包。它基于Meta的ExecuTorch AI框架,允许开发者在移动设备上本地运行AI模型和LLM。主要特点包括:1. 设备端模型执行:AI模型直接在设备上运行,保护用户隐私,无需外部API调用2. 成本效益:减少对云基础设施的依赖,降低服务器成本和延迟3. 隐私优先:数据完全保留在设备上4. 开发者友好:提供声明式API,无需深厚的AI专业知识5. 属于PyTorch Edge生态系统
三、为智能体添加长期记忆
现在,让我们解决第二个痛点:如何让AI记住跨会话的对话?
步骤1:设置记忆存储系统
from langgraph.checkpoint.memory import InMemorySaverfrom langgraph.store.memory import InMemoryStore# 1. 创建检查点保存器 - 保存单个对话状态checkpointer = InMemorySaver()# 2. 创建存储 - 跨线程/会话存储状态store = InMemoryStore()# 3. 编译时集成记忆系统workflow = graph.compile( checkpointer=checkpointer, # 记住每次对话的状态 store=store # 跨会话记忆)
步骤2:使用会话ID管理对话
# 为每个对话会话设置唯一IDconfig = { "recursion_limit": 100, "configurable": { "thread_id": "user_123_session_1"# 实际中可以使用用户ID+时间戳 }}# 第一次对话print("=== 第一次对话 ===")workflow.invoke( {"messages": [], "iteration": 0}, config=config,)# 获取当前对话状态current_state = workflow.get_state(config)print(f"当前对话轮次: {current_state.values['iteration']}")# 第二次对话(延续上次)print("\n=== 第二次对话(延续上次)===")workflow.invoke( current_state, config=config, # 相同的thread_id,AI会记得上次对话)
步骤3:实现真正的长期记忆
在实际应用中,我们通常需要更复杂的记忆管理。这里是一个增强版示例:
import jsonfrom datetime import datetimeclass LongTermMemoryManager: """长期记忆管理器""" def __init__(self, storage_path="memory_storage.json"): self.storage_path = storage_path self.memories = self.load_memories() def load_memories(self): """加载历史记忆""" try: with open(self.storage_path, 'r', encoding='utf-8') as f: return json.load(f) except FileNotFoundError: return {} def save_memory(self, user_id, conversation_summary, key_points): """保存重要对话记忆""" if user_id notin self.memories: self.memories[user_id] = [] memory_entry = { "timestamp": datetime.now().isoformat(), "summary": conversation_summary, "key_points": key_points } self.memories[user_id].append(memory_entry) # 保持最近50条记忆 if len(self.memories[user_id]) > 50: self.memories[user_id] = self.memories[user_id][-50:] self.save_to_disk() def save_to_disk(self): """保存到文件""" with open(self.storage_path, 'w', encoding='utf-8') as f: json.dump(self.memories, f, ensure_ascii=False, indent=2) def get_user_memories(self, user_id, limit=5): """获取用户最近记忆""" return self.memories.get(user_id, [])[-limit:]# 使用示例memory_manager = LongTermMemoryManager()# 对话结束时保存记忆def end_conversation_and_save(user_id, messages): """结束对话并保存重要信息""" # 让AI总结对话要点 summary_prompt = f"""请总结以下对话的要点: 对话记录: {messages} 请提取: 1. 讨论的核心话题 2. 重要的决策或结论 3. 需要后续跟进的事项 总结:""" # 调用AI生成总结 summary = model.invoke(summary_prompt) # 保存到长期记忆 memory_manager.save_memory( user_id=user_id, conversation_summary=summary.content, key_points=["技术讨论", "React Native ExecuTorch"] # 实际中可以让AI提取 ) return summary.content
四、完整项目:智能文档助手
让我们把RAG和长期记忆结合起来,创建一个真正的智能文档助手:
class SmartDocumentAssistant: """智能文档助手:RAG + 长期记忆""" def __init__(self, document_url): # 初始化组件 self.vector_store = self.setup_rag(document_url) self.memory_manager = LongTermMemoryManager() self.model = ChatOpenAI(model="gpt-3.5-turbo") # 构建对话图 self.workflow = self.build_workflow() def setup_rag(self, document_url): """设置RAG系统""" # 加载和分割文档 loader = WebBaseLoader(document_url) docs = loader.load() text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, chunk_overlap=200 ) all_splits = text_splitter.split_documents(docs) # 创建向量存储 embeddings = HuggingFaceEmbeddings( model_name="sentence-transformers/all-MiniLM-L6-v2" ) vector_store = InMemoryVectorStore(embeddings) vector_store.add_documents(documents=all_splits) return vector_store def build_workflow(self): """构建工作流""" graph_builder = StateGraph(State) # 添加增强的提问节点 graph_builder.add_node("smart_ask", self.smart_ask_with_memory) graph_builder.set_entry_point("smart_ask") graph_builder.add_edge("smart_ask", END) # 编译带记忆的工作流 return graph_builder.compile( checkpointer=InMemorySaver(), store=InMemoryStore() ) def smart_ask_with_memory(self, state: State) -> State: """智能提问:RAG + 记忆""" user_id = "current_user"# 实际中从用户登录获取 # 1. 获取用户历史记忆 past_memories = self.memory_manager.get_user_memories(user_id) memory_context = "" if past_memories: memory_context = "\n\n之前的对话要点:\n" for mem in past_memories: memory_context += f"- {mem['summary'][:100]}...\n" # 2. 获取用户问题 user_query = input("\n💬 你的问题: ") # 3. RAG检索 retrieved_docs = self.vector_store.similarity_search(user_query, k=3) rag_context = "\n\n".join([doc.page_content for doc in retrieved_docs]) # 4. 构建综合提示 prompt = f"""{memory_context}相关文档内容:{rag_context}用户当前问题:{user_query}请基于以上信息回答问题。如果文档中没有相关信息,请说明。""" # 5. 调用AI response = self.model.invoke(prompt) print(f"\n🤖 助手: {response.content}") # 6. 检查是否需要保存到长期记忆 if "重要"in user_query or "记住" in user_query: print("(已将此对话标记为重要,会长期记住)") # 实际中可以让AI判断重要性 return {"messages": [{"role": "user", "content": user_query}, {"role": "assistant", "content": response.content}]} def chat(self, user_id="default_user"): """启动对话""" config = { "recursion_limit": 50, "configurable": {"thread_id": user_id} } print("=" * 60) print("智能文档助手已启动!") print("我可以:1. 回答文档相关问题 2. 记住我们的重要对话") print("输入 '退出' 结束对话") print("=" * 60) # 开始对话 self.workflow.invoke( {"messages": [], "iteration": 0}, config=config )# 使用示例if __name__ == "__main__": # 创建助手(基于React Native ExecuTorch文档) assistant = SmartDocumentAssistant( "https://docs.swmansion.com/react-native-execuTorch/" ) # 开始对话 assistant.chat("user_001")
五、避坑指南与最佳实践
在实现RAG和长期记忆时,注意以下常见问题:
RAG常见问题
- 检索不准确
- ❌ 问题:返回无关文档片段
- ✅ 解决:调整
chunk_size,优化嵌入模型,添加元数据过滤
- 上下文过长
- ❌ 问题:提示超过token限制
- ✅ 解决:使用摘要、选择性检索或分页检索
长期记忆最佳实践
- 记忆总结策略
- 定期总结对话,而不是存储所有消息
- 按话题分类存储记忆
- 隐私考虑
- 明确告知用户什么信息会被记住
- 提供清除记忆的选项
写在最后
通过今天的学习,我们已经成功为LangGraph智能体装上了两大"超能力":RAG让它能够从特定文档中查找答案,长期记忆让它能够记住跨会话的对话历史。
关键收获:
- RAG不是替换,而是增强:它让AI在自身知识基础上,增加了查阅外部文档的能力
- 记忆需要管理:不是所有对话都值得记住,智能的记忆总结比存储原始对话更重要
- LangGraph提供了优雅的架构:通过状态图和检查点机制,我们能轻松实现复杂的多轮对话管理
动手挑战:
- 尝试为你的AI添加多个文档来源的RAG支持
- 实现一个记忆重要性评分系统,让AI自动判断哪些对话值得长期记忆
- 探索将记忆存储到数据库中,实现真正的持久化
你在实际项目中是如何处理AI的记忆和知识库问题的?有没有遇到什么有趣的挑战或独特的解决方案?欢迎在评论区分享你的经验!
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
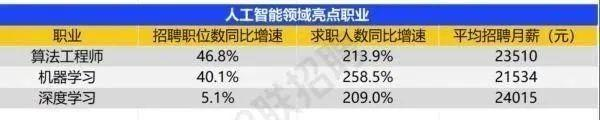
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)